 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes language matter for spoken word classification? A multilingual generative meta-learning approach
May 14, 2026Meta-learning has been shown to have better performance than supervised learning for few-shot monolingual spoken word classification. However, the meta-learning approach remains under-explored in multilingual spoken word classification. In this paper, we apply the Generative Meta-Continual Learning algorithm to spoken word classification. The generative nature of this algorithm makes it viable for use in application, and the meta-learning aspect promotes generalisation, which is crucial in a multilingual setting. We train monolingual models on English, German, French, and Catalan, a bilingual model on English and German, and a multilingual model on all four languages. We find that although the multilingual model performs best, the differences between model performance is unexpectedly low. We also find that the hours of unique data seen during training seems to be a stronger performance indicator than the number of languages included in the training data.
Scaling few-shot spoken word classification with generative meta-continual learning
May 14, 2026Few-shot spoken word classification has largely been developed for applications where a small number of classes is considered, and so the potential of larger-scale few-shot spoken word classification remains untapped. This paper investigates the potential of a spoken word classifier to sequentially learn to distinguish between 1000 classes when it is given only five shots per class. We demonstrate that this scaling capability exists by training a model using the Generative Meta-Continual Learning (GeMCL) algorithm and comparing it to repeatedly trained or finetuned baselines. We find that GeMCL produces exceptionally stable performance, and although it does not always outperform a repeatedly fully-finetuned HuBERT model nor a frozen HuBERT model with a repeatedly trained classifier head, it produces comparable performance to the latter while adapting 2000 times faster, having been trained less than half of the data for two orders of magnitude less time.
Mitigating Catastrophic Forgetting for Few-Shot Spoken Word Classification Through Meta-Learning
May 22, 2023We consider the problem of few-shot spoken word classification in a setting where a model is incrementally introduced to new word classes. This would occur in a user-defined keyword system where new words can be added as the system is used. In such a continual learning scenario, a model might start to misclassify earlier words as newer classes are added, i.e. catastrophic forgetting. To address this, we propose an extension to model-agnostic meta-learning (MAML): each inner learning loop, where a model "learns how to learn'' new classes, ends with a single gradient update using stored templates from all the classes that the model has already seen (one template per class). We compare this method to OML (another extension of MAML) in few-shot isolated-word classification experiments on Google Commands and FACC. Our method consistently outperforms OML in experiments where the number of shots and the final number of classes are varied.
Manifold Characteristics That Predict Downstream Task Performance
May 16, 2022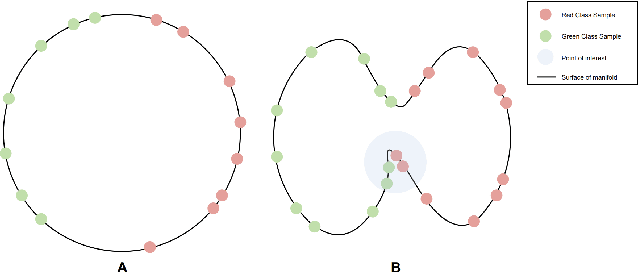
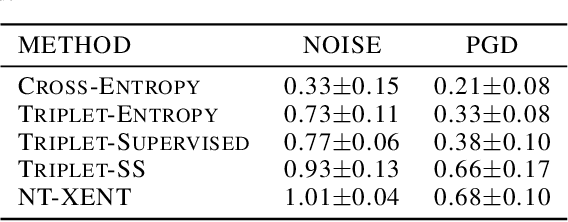
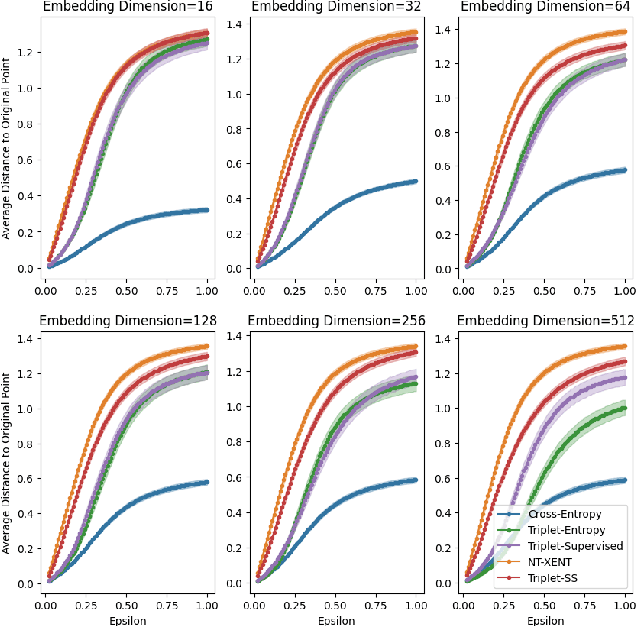
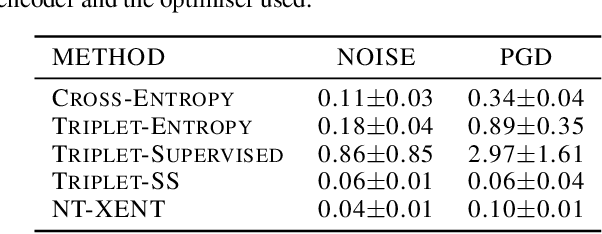
Pretraining methods are typically compared by evaluating the accuracy of linear classifiers, transfer learning performance, or visually inspecting the representation manifold's (RM) lower-dimensional projections. We show that the differences between methods can be understood more clearly by investigating the RM directly, which allows for a more detailed comparison. To this end, we propose a framework and new metric to measure and compare different RMs. We also investigate and report on the RM characteristics for various pretraining methods. These characteristics are measured by applying sequentially larger local alterations to the input data, using white noise injections and Projected Gradient Descent (PGD) adversarial attacks, and then tracking each datapoint. We calculate the total distance moved for each datapoint and the relative change in distance between successive alterations. We show that self-supervised methods learn an RM where alterations lead to large but constant size changes, indicating a smoother RM than fully supervised methods. We then combine these measurements into one metric, the Representation Manifold Quality Metric (RMQM), where larger values indicate larger and less variable step sizes, and show that RMQM correlates positively with performance on downstream tasks.
Triplet Entropy Loss: Improving The Generalisation of Short Speech Language Identification Systems
Dec 03, 2020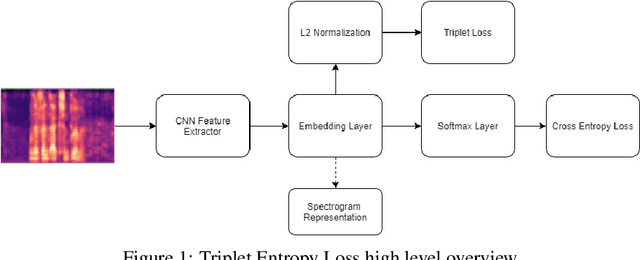
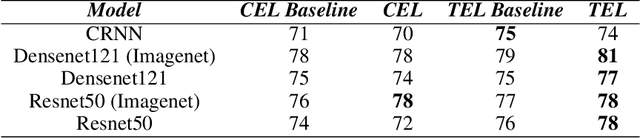
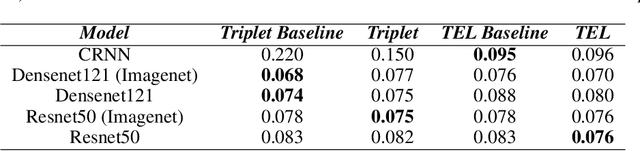
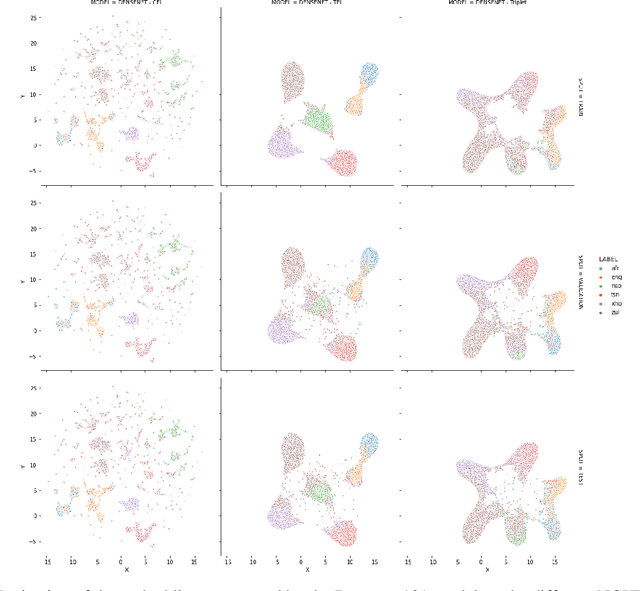
We present several methods to improve the generalisation of language identification (LID) systems to new speakers and to new domains. These methods involve Spectral augmentation, where spectrograms are masked in the frequency or time bands during training and CNN architectures that are pre-trained on the Imagenet dataset. The paper also introduces the novel Triplet Entropy Loss training method, which involves training a network simultaneously using Cross Entropy and Triplet loss. It was found that all three methods improved the generalisation of the models, though not significantly. Even though the models trained using Triplet Entropy Loss showed a better understanding of the languages and higher accuracies, it appears as though the models still memorise word patterns present in the spectrograms rather than learning the finer nuances of a language. The research shows that Triplet Entropy Loss has great potential and should be investigated further, not only in language identification tasks but any classification task.