 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Read through Machine Teaching
Jul 02, 2020
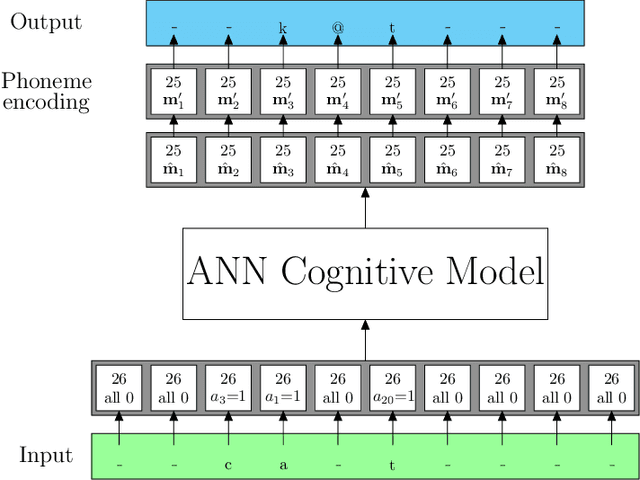

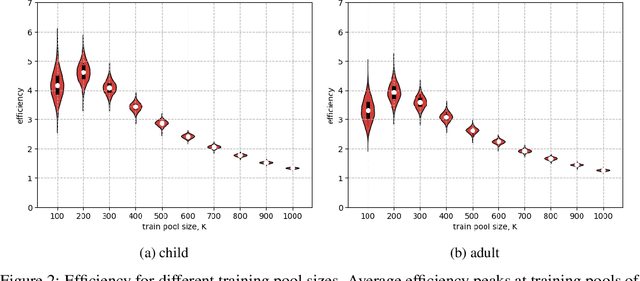
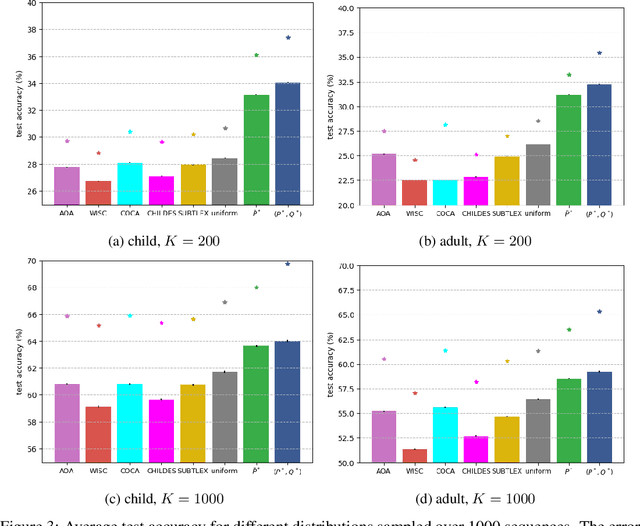
Learning to read words aloud is a major step towards becoming a reader. Many children struggle with the task because of the inconsistencies of English spelling-sound correspondences. Curricula vary enormously in how these patterns are taught. Children are nonetheless expected to master the system in limited time (by grade 4). We used a cognitively interesting neural network architecture to examine whether the sequence of learning trials could be structured to facilitate learning. This is a hard combinatorial optimization problem even for a modest number of learning trials (e.g., 10K). We show how this sequence optimization problem can be posed as optimizing over a time varying distribution i.e., defining probability distributions over words at different steps in training. We then use stochastic gradient descent to find an optimal time-varying distribution and a corresponding optimal training sequence. We observed significant improvement on generalization accuracy compared to baseline conditions (random sequences; sequences biased by word frequency). These findings suggest an approach to improving learning outcomes in domains where performance depends on ability to generalize beyond limited training experience.
GnetSeg: Semantic Segmentation Model Optimized on a 224mW CNN Accelerator Chip at the Speed of 318FPS
Jan 09, 2021

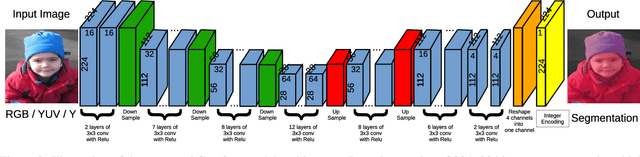
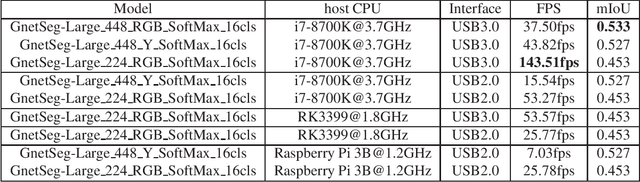
Semantic segmentation is the task to cluster pixels on an image belonging to the same class. It is widely used in the real-world applications including autonomous driving, medical imaging analysis, industrial inspection, smartphone camera for person segmentation and so on. Accelerating the semantic segmentation models on the mobile and edge devices are practical needs for the industry. Recent years have witnessed the wide availability of CNN (Convolutional Neural Networks) accelerators. They have the advantages on power efficiency, inference speed, which are ideal for accelerating the semantic segmentation models on the edge devices. However, the CNN accelerator chips also have the limitations on flexibility and memory. In addition, the CPU load is very critical because the CNN accelerator chip works as a co-processor with a host CPU. In this paper, we optimize the semantic segmentation model in order to fully utilize the limited memory and the supported operators on the CNN accelerator chips, and at the same time reduce the CPU load of the CNN model to zero. The resulting model is called GnetSeg. Furthermore, we propose the integer encoding for the mask of the GnetSeg model, which minimizes the latency of data transfer between the CNN accelerator and the host CPU. The experimental result shows that the model running on the 224mW chip achieves the speed of 318FPS with excellent accuracy for applications such as person segmentation.
TP-LSD: Tri-Points Based Line Segment Detector
Sep 11, 2020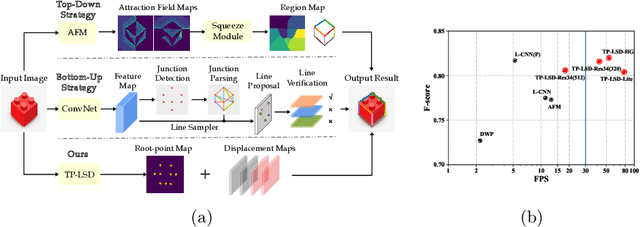
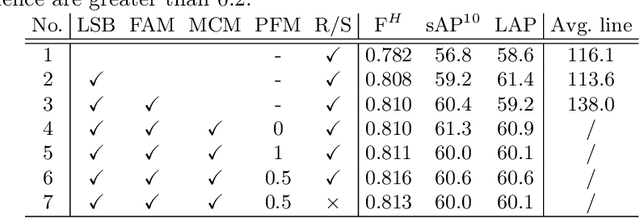

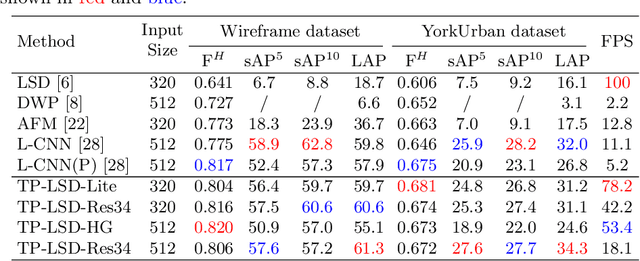
This paper proposes a novel deep convolutional model, Tri-Points Based Line Segment Detector (TP-LSD), to detect line segments in an image at real-time speed. The previous related methods typically use the two-step strategy, relying on either heuristic post-process or extra classifier. To realize one-step detection with a faster and more compact model, we introduce the tri-points representation, converting the line segment detection to the end-to-end prediction of a root-point and two endpoints for each line segment. TP-LSD has two branches: tri-points extraction branch and line segmentation branch. The former predicts the heat map of root-points and the two displacement maps of endpoints. The latter segments the pixels on straight lines out from background. Moreover, the line segmentation map is reused in the first branch as structural prior. We propose an additional novel evaluation metric and evaluate our method on Wireframe and YorkUrban datasets, demonstrating not only the competitive accuracy compared to the most recent methods, but also the real-time run speed up to 78 FPS with the $320\times 320$ input.
* Accepted by ECCV 2020
LRC-BERT: Latent-representation Contrastive Knowledge Distillation for Natural Language Understanding
Dec 14, 2020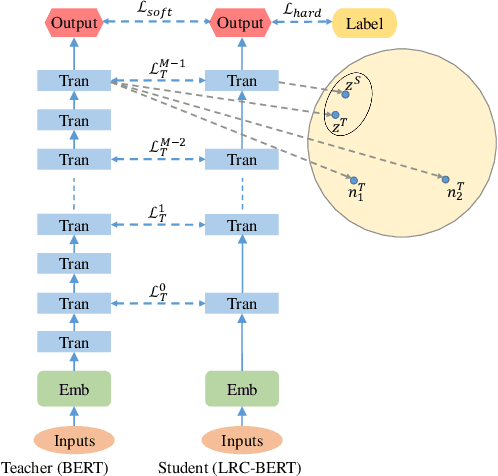

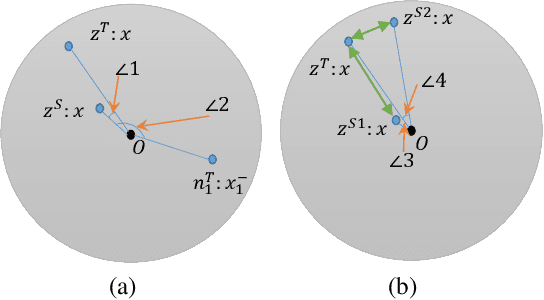

The pre-training models such as BERT have achieved great results in various natural language processing problems. However, a large number of parameters need significant amounts of memory and the consumption of inference time, which makes it difficult to deploy them on edge devices. In this work, we propose a knowledge distillation method LRC-BERT based on contrastive learning to fit the output of the intermediate layer from the angular distance aspect, which is not considered by the existing distillation methods. Furthermore, we introduce a gradient perturbation-based training architecture in the training phase to increase the robustness of LRC-BERT, which is the first attempt in knowledge distillation. Additionally, in order to better capture the distribution characteristics of the intermediate layer, we design a two-stage training method for the total distillation loss. Finally, by verifying 8 datasets on the General Language Understanding Evaluation (GLUE) benchmark, the performance of the proposed LRC-BERT exceeds the existing state-of-the-art methods, which proves the effectiveness of our method.
It Takes Two to Tango: Combining Visual and Textual Information for Detecting Duplicate Video-Based Bug Reports
Feb 05, 2021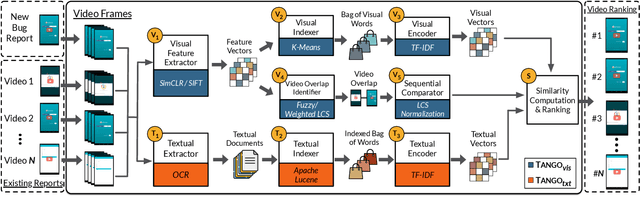
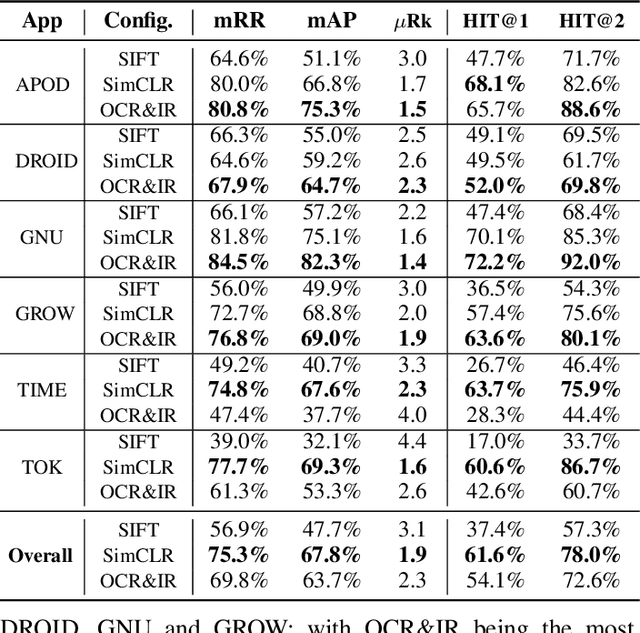
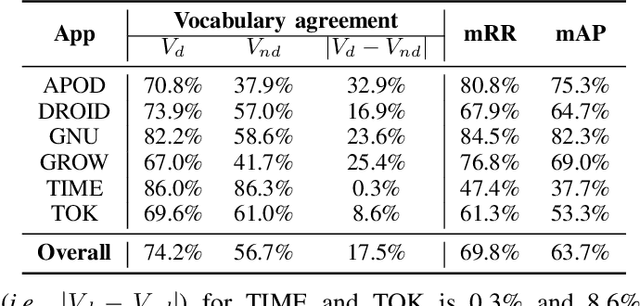
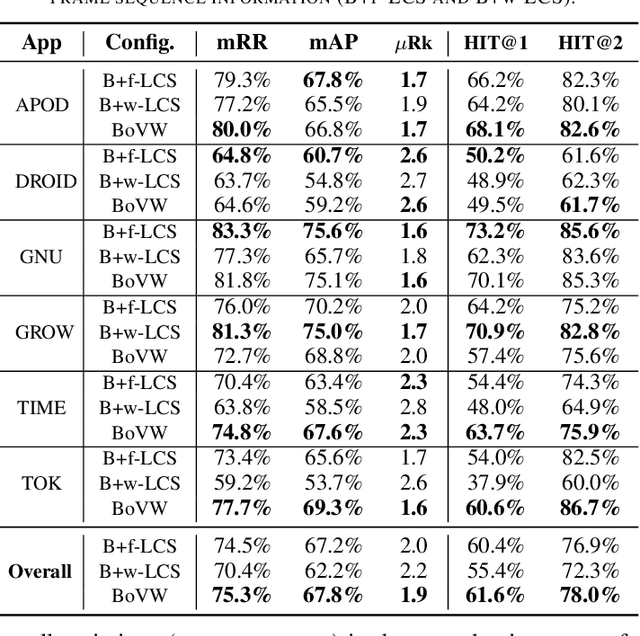
When a bug manifests in a user-facing application, it is likely to be exposed through the graphical user interface (GUI). Given the importance of visual information to the process of identifying and understanding such bugs, users are increasingly making use of screenshots and screen-recordings as a means to report issues to developers. However, when such information is reported en masse, such as during crowd-sourced testing, managing these artifacts can be a time-consuming process. As the reporting of screen-recordings in particular becomes more popular, developers are likely to face challenges related to manually identifying videos that depict duplicate bugs. Due to their graphical nature, screen-recordings present challenges for automated analysis that preclude the use of current duplicate bug report detection techniques. To overcome these challenges and aid developers in this task, this paper presents Tango, a duplicate detection technique that operates purely on video-based bug reports by leveraging both visual and textual information. Tango combines tailored computer vision techniques, optical character recognition, and text retrieval. We evaluated multiple configurations of Tango in a comprehensive empirical evaluation on 4,860 duplicate detection tasks that involved a total of 180 screen-recordings from six Android apps. Additionally, we conducted a user study investigating the effort required for developers to manually detect duplicate video-based bug reports and compared this to the effort required to use Tango. The results reveal that Tango's optimal configuration is highly effective at detecting duplicate video-based bug reports, accurately ranking target duplicate videos in the top-2 returned results in 83% of the tasks. Additionally, our user study shows that, on average, Tango can reduce developer effort by over 60%, illustrating its practicality.
EVRNet: Efficient Video Restoration on Edge Devices
Dec 03, 2020
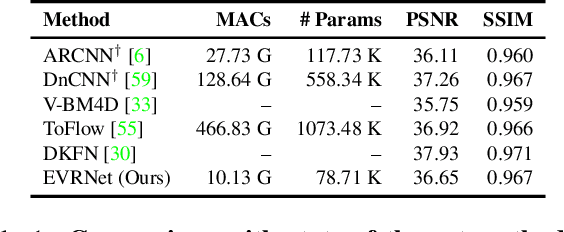
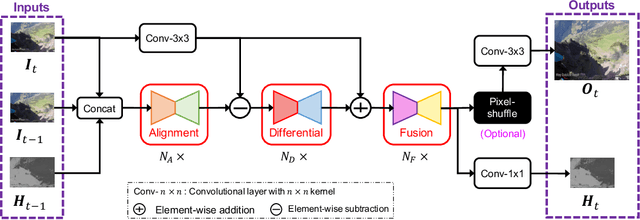
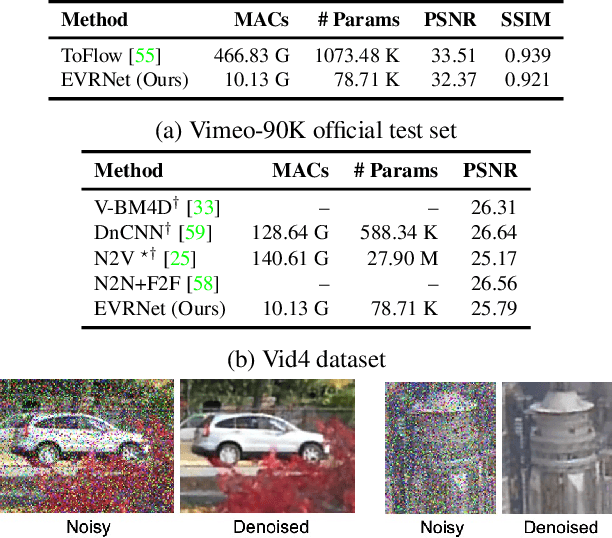
Video transmission applications (e.g., conferencing) are gaining momentum, especially in times of global health pandemic. Video signals are transmitted over lossy channels, resulting in low-quality received signals. To restore videos on recipient edge devices in real-time, we introduce an efficient video restoration network, EVRNet. EVRNet efficiently allocates parameters inside the network using alignment, differential, and fusion modules. With extensive experiments on video restoration tasks (deblocking, denoising, and super-resolution), we demonstrate that EVRNet delivers competitive performance to existing methods with significantly fewer parameters and MACs. For example, EVRNet has 260 times fewer parameters and 958 times fewer MACs than enhanced deformable convolution-based video restoration network (EDVR) for 4 times video super-resolution while its SSIM score is 0.018 less than EDVR. We also evaluated the performance of EVRNet under multiple distortions on unseen dataset to demonstrate its ability in modeling variable-length sequences under both camera and object motion.
Cyber Threat Intelligence for Secure Smart City
Jul 26, 2020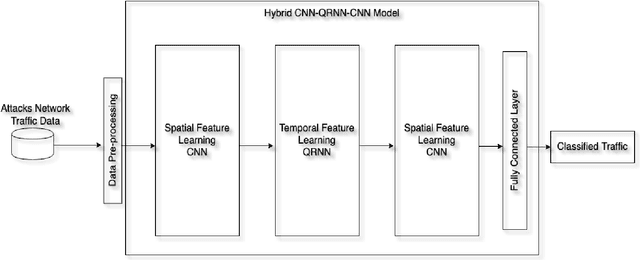

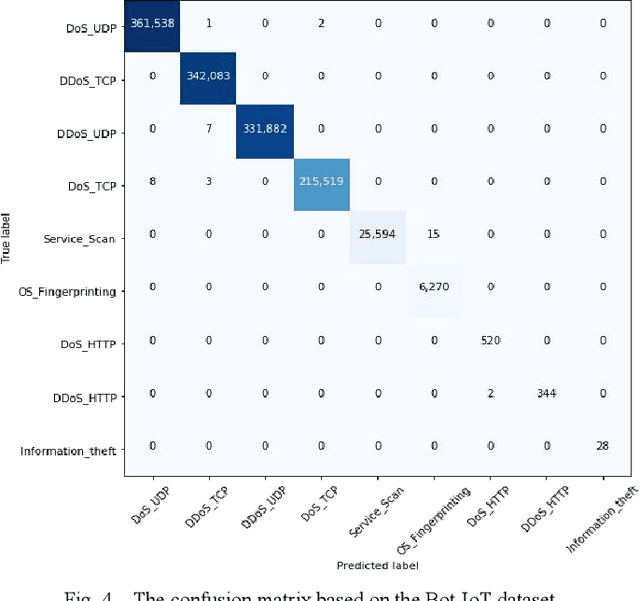
Smart city improved the quality of life for the citizens by implementing information communication technology (ICT) such as the internet of things (IoT). Nevertheless, the smart city is a critical environment that needs to secure it is network and data from intrusions and attacks. This work proposes a hybrid deep learning (DL) model for cyber threat intelligence (CTI) to improve threats classification performance based on convolutional neural network (CNN) and quasi-recurrent neural network (QRNN). We use QRNN to provide a real-time threat classification model. The evaluation results of the proposed model compared to the state-of-the-art models show that the proposed model outperformed the other models. Therefore, it will help in classifying the smart city threats in a reasonable time.
Nanopore Base Calling on the Edge
Nov 09, 2020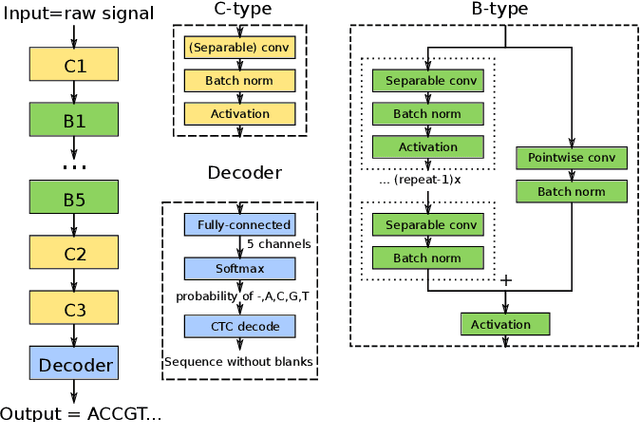

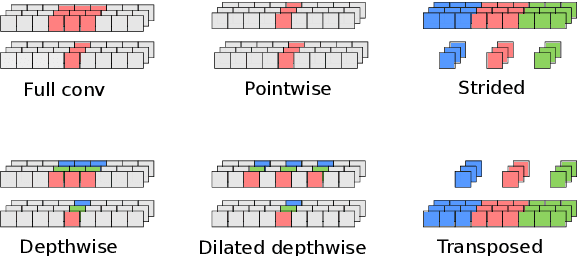
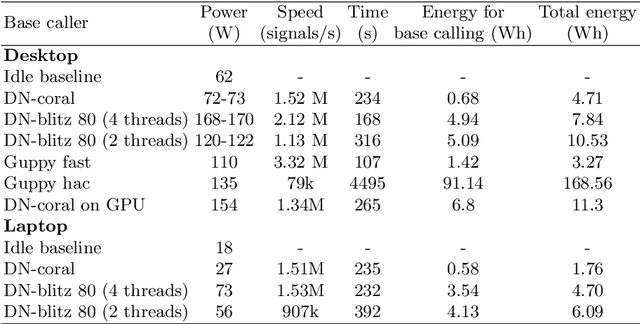
We developed a new base caller DeepNano-coral for nanopore sequencing, which is optimized to run on the Coral Edge Tensor Processing Unit, a small USB-attached hardware accelerator. To achieve this goal, we have designed new versions of two key components used in convolutional neural networks for speech recognition and base calling. In our components, we propose a new way of factorization of a full convolution into smaller operations, which decreases memory access operations, memory access being a bottleneck on this device. DeepNano-coral achieves real-time base calling during sequencing with the accuracy slightly better than the fast mode of the Guppy base caller and is extremely energy efficient, using only 10W of power. Availability: https://github.com/fmfi-compbio/coral-basecaller
Extracting quantitative biological information from brightfield cell images using deep learning
Dec 23, 2020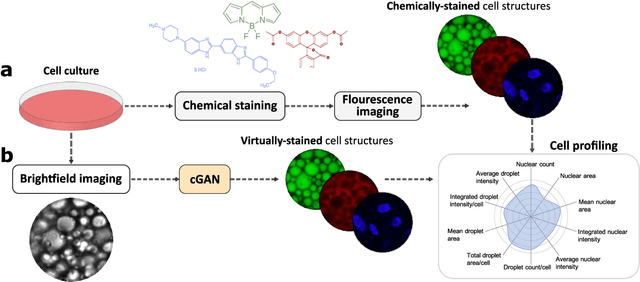
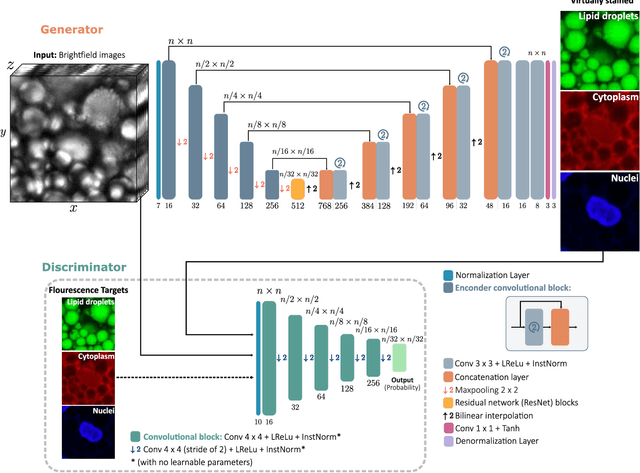
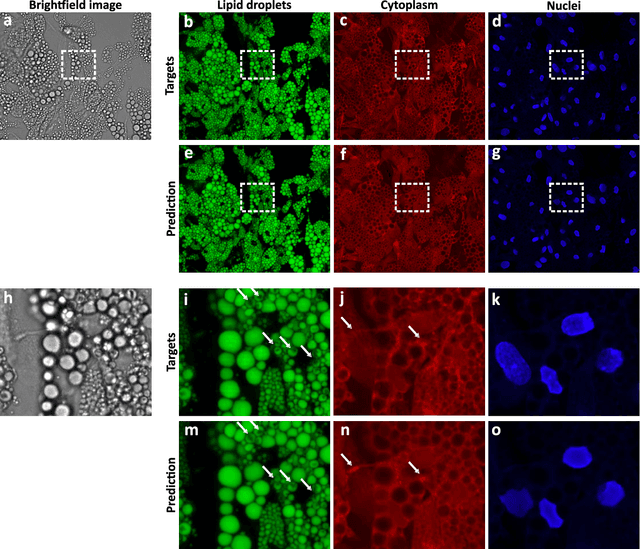
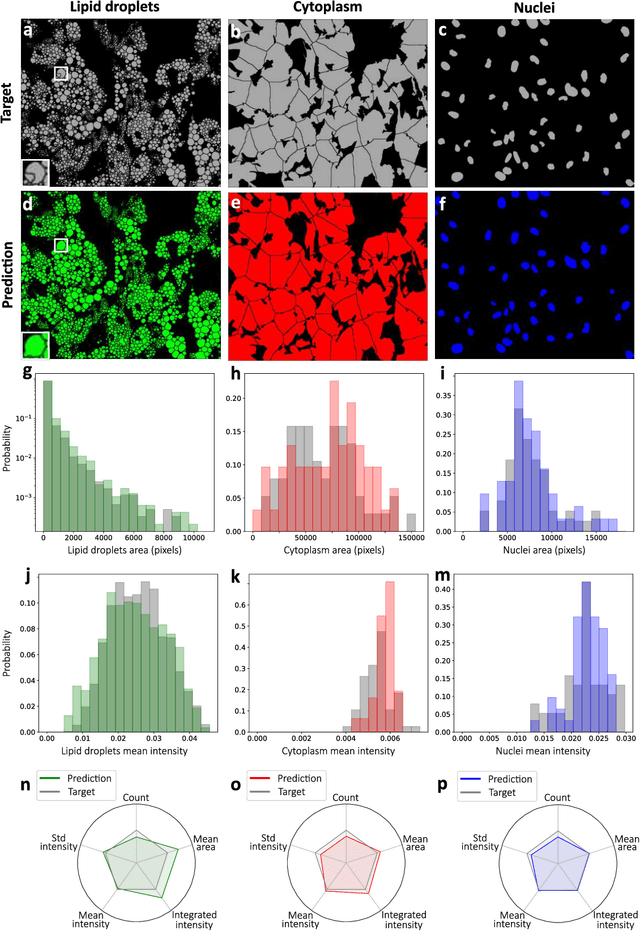
Quantitative analysis of cell structures is essential for biomedical and pharmaceutical research. The standard imaging approach relies on fluorescence microscopy, where cell structures of interest are labeled by chemical staining techniques. However, these techniques are often invasive and sometimes even toxic to the cells, in addition to being time-consuming, labor-intensive, and expensive. Here, we introduce an alternative deep-learning-powered approach based on the analysis of brightfield images by a conditional generative adversarial neural network (cGAN). We show that this approach can extract information from the brightfield images to generate virtually-stained images, which can be used in subsequent downstream quantitative analyses of cell structures. Specifically, we train a cGAN to virtually stain lipid droplets, cytoplasm, and nuclei using brightfield images of human stem-cell-derived fat cells (adipocytes), which are of particular interest for nanomedicine and vaccine development. Subsequently, we use these virtually-stained images to extract quantitative measures about these cell structures. Generating virtually-stained fluorescence images is less invasive, less expensive, and more reproducible than standard chemical staining; furthermore, it frees up the fluorescence microscopy channels for other analytical probes, thus increasing the amount of information that can be extracted from each cell.
Efficient Learning-based Scheduling for Information Freshness in Wireless Networks
Jan 01, 2021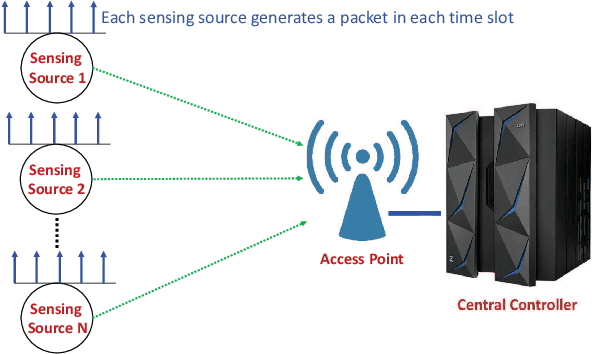
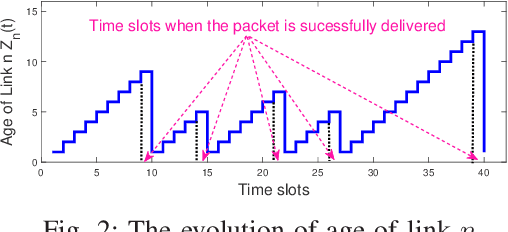
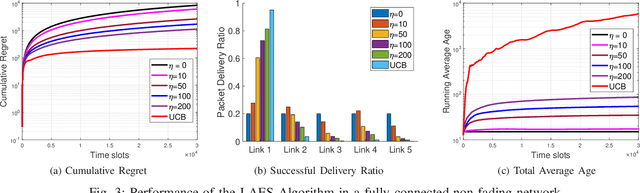
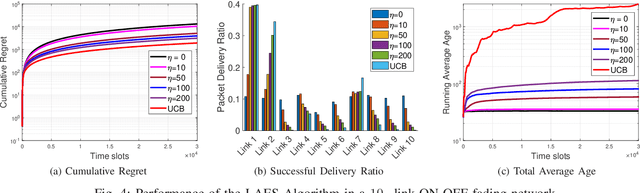
Motivated by the recent trend of integrating artificial intelligence into the Internet-of-Things (IoT), we consider the problem of scheduling packets from multiple sensing sources to a central controller over a wireless network. Here, packets from different sensing sources have different values or degrees of importance to the central controller for intelligent decision making. In such a setup, it is critical to provide timely and valuable information for the central controller. In this paper, we develop a parameterized maximum-weight type scheduling policy that combines both the AoI metrics and Upper Confidence Bound (UCB) estimates in its weight measure with parameter $\eta$. Here, UCB estimates balance the tradeoff between exploration and exploitation in learning and are critical for yielding a small cumulative regret. We show that our proposed algorithm yields the running average total age at most by $O(N^2\eta)$. We also prove that our proposed algorithm achieves the cumulative regret over time horizon $T$ at most by $O(NT/\eta+\sqrt{NT\log T})$. This reveals a tradeoff between the cumulative regret and the running average total age: when increasing $\eta$, the cumulative regret becomes smaller, but is at the cost of increasing running average total age. Simulation results are provided to evaluate the efficiency of our proposed algorithm.