 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Read through Machine Teaching
Jul 02, 2020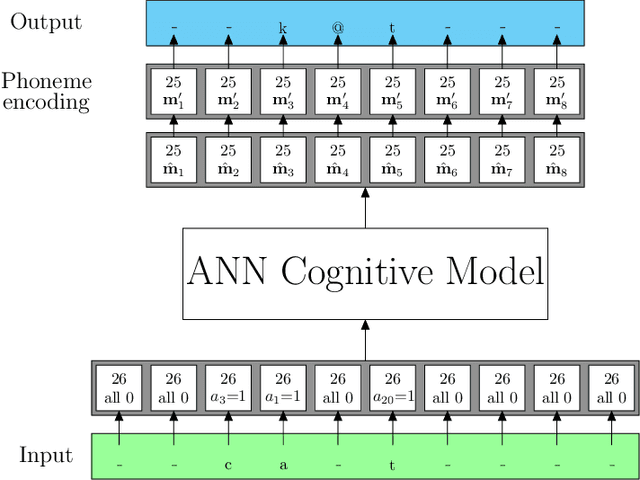

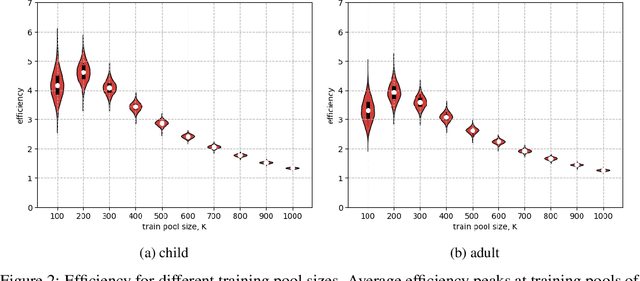
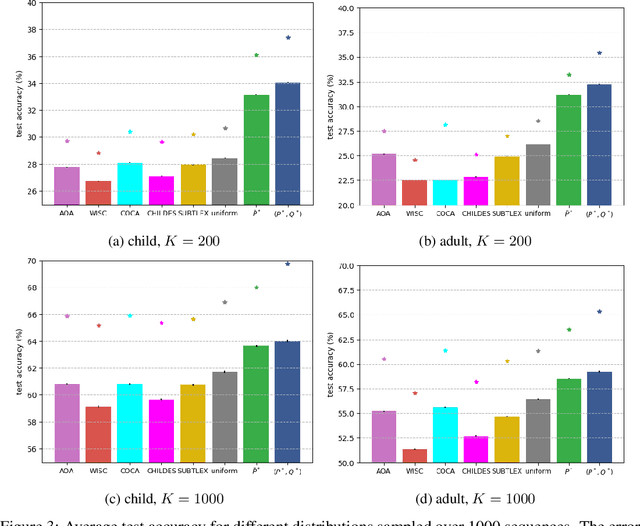
Learning to read words aloud is a major step towards becoming a reader. Many children struggle with the task because of the inconsistencies of English spelling-sound correspondences. Curricula vary enormously in how these patterns are taught. Children are nonetheless expected to master the system in limited time (by grade 4). We used a cognitively interesting neural network architecture to examine whether the sequence of learning trials could be structured to facilitate learning. This is a hard combinatorial optimization problem even for a modest number of learning trials (e.g., 10K). We show how this sequence optimization problem can be posed as optimizing over a time varying distribution i.e., defining probability distributions over words at different steps in training. We then use stochastic gradient descent to find an optimal time-varying distribution and a corresponding optimal training sequence. We observed significant improvement on generalization accuracy compared to baseline conditions (random sequences; sequences biased by word frequency). These findings suggest an approach to improving learning outcomes in domains where performance depends on ability to generalize beyond limited training experience.
Domain Independent SVM for Transfer Learning in Brain Decoding
Mar 26, 2019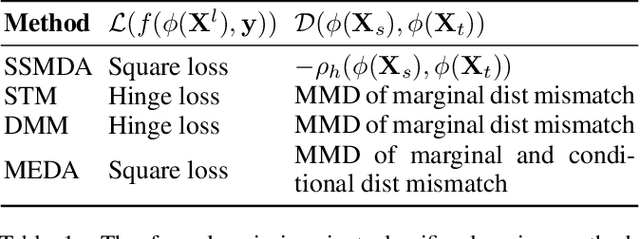
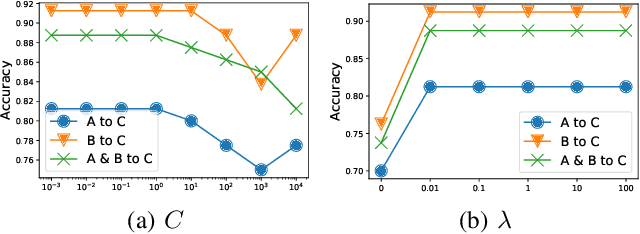


Brain imaging data are important in brain sciences yet expensive to obtain, with big volume (i.e., large p) but small sample size (i.e., small n). To tackle this problem, transfer learning is a promising direction that leverages source data to improve performance on related, target data. Most transfer learning methods focus on minimizing data distribution mismatch. However, a big challenge in brain imaging is the large domain discrepancies in cognitive experiment designs and subject-specific structures and functions. A recent transfer learning approach minimizes domain dependence to learn common features across domains, via the Hilbert-Schmidt Independence Criterion (HSIC). Inspired by this method, we propose a new Domain Independent Support Vector Machine (DI-SVM) for transfer learning in brain condition decoding. Specifically, DI-SVM simultaneously minimizes the SVM empirical risk and the dependence on domain information via a simplified HSIC. We use public data to construct 13 transfer learning tasks in brain decoding, including three interesting multi-source transfer tasks. Experiments show that DI-SVM's superior performance over eight competing methods on these tasks, particularly an improvement of more than 24% on multi-source transfer tasks.