 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Model Accuracy for Imbalanced Image Classification Tasks by Adding a Final Batch Normalization Layer: An Empirical Study
Nov 12, 2020
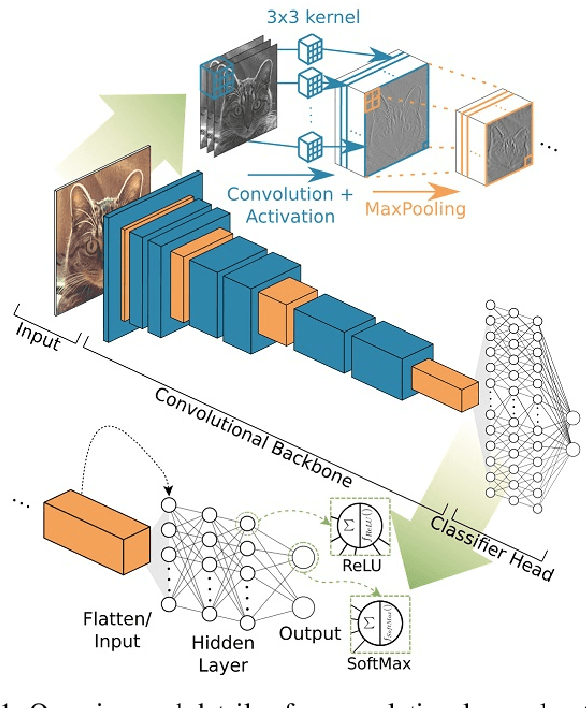
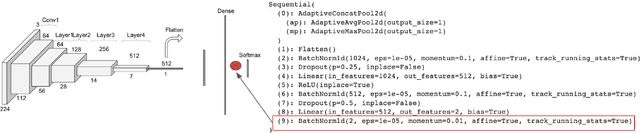
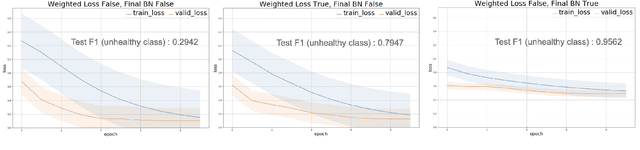
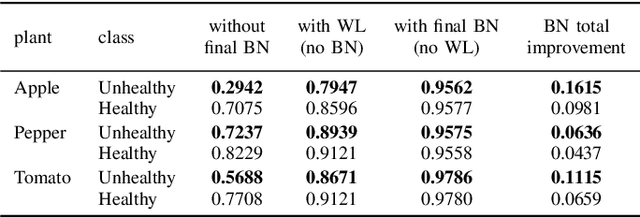
Some real-world domains, such as Agriculture and Healthcare, comprise early-stage disease indications whose recording constitutes a rare event, and yet, whose precise detection at that stage is critical. In this type of highly imbalanced classification problems, which encompass complex features, deep learning (DL) is much needed because of its strong detection capabilities. At the same time, DL is observed in practice to favor majority over minority classes and consequently suffer from inaccurate detection of the targeted early-stage indications. To simulate such scenarios, we artificially generate skewness (99% vs. 1%) for certain plant types out of the PlantVillage dataset as a basis for classification of scarce visual cues through transfer learning. By randomly and unevenly picking healthy and unhealthy samples from certain plant types to form a training set, we consider a base experiment as fine-tuning ResNet34 and VGG19 architectures and then testing the model performance on a balanced dataset of healthy and unhealthy images. We empirically observe that the initial F1 test score jumps from 0.29 to 0.95 for the minority class upon adding a final Batch Normalization (BN) layer just before the output layer in VGG19. We demonstrate that utilizing an additional BN layer before the output layer in modern CNN architectures has a considerable impact in terms of minimizing the training time and testing error for minority classes in highly imbalanced data sets. Moreover, when the final BN is employed, minimizing the loss function may not be the best way to assure a high F1 test score for minority classes in such problems. That is, the network might perform better even if it is not confident enough while making a prediction; leading to another discussion about why softmax output is not a good uncertainty measure for DL models.
Preference-based performance measures for Time-Domain Global Similarity method
Nov 08, 2017
For Time-Domain Global Similarity (TDGS) method, which transforms the data cleaning problem into a binary classification problem about the physical similarity between channels, directly adopting common performance measures could only guarantee the performance for physical similarity. Nevertheless, practical data cleaning tasks have preferences for the correctness of original data sequences. To obtain the general expressions of performance measures based on the preferences of tasks, the mapping relations between performance of TDGS method about physical similarity and correctness of data sequences are investigated by probability theory in this paper. Performance measures for TDGS method in several common data cleaning tasks are set. Cases when these preference-based performance measures could be simplified are introduced.
A Hysteretic Q-learning Coordination Framework for Emerging Mobility Systems in Smart Cities
Nov 05, 2020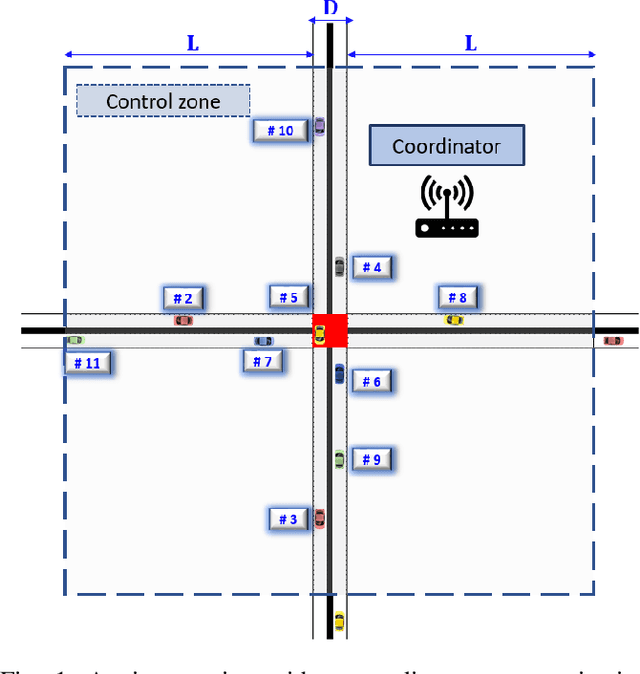
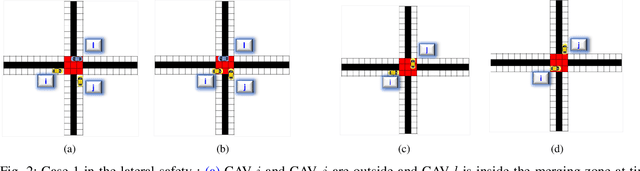
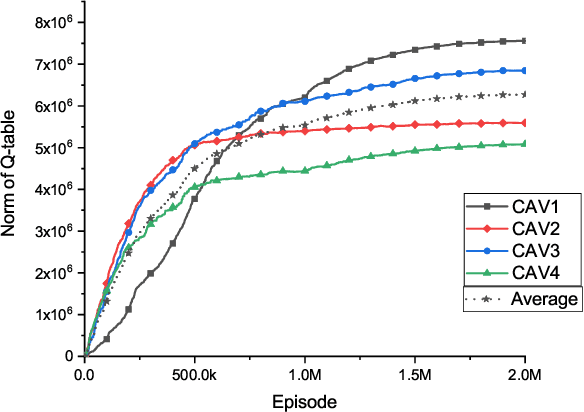
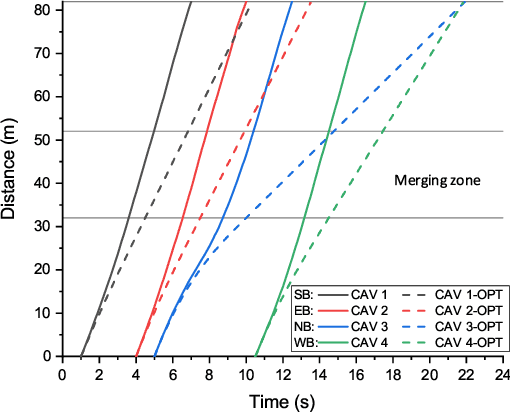
Connected and automated vehicles (CAVs) can alleviate traffic congestion, air pollution, and improve safety. In this paper, we provide a decentralized coordination framework for CAVs at a signal-free intersection to minimize travel time and improve fuel efficiency. We employ a simple yet powerful reinforcement learning approach, an off-policy temporal difference learning called Q-learning, enhanced with a coordination mechanism to address this problem. Then, we integrate a first-in-first-out queuing policy to improve the performance of our system. We demonstrate the efficacy of our proposed approach through simulation and comparison with the classical optimal control method based on Pontryagin's minimum principle.
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Oct 20, 2020
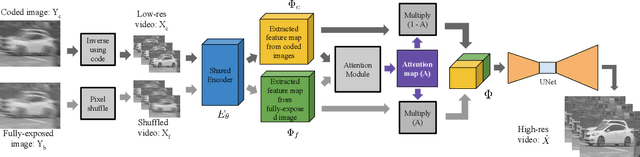
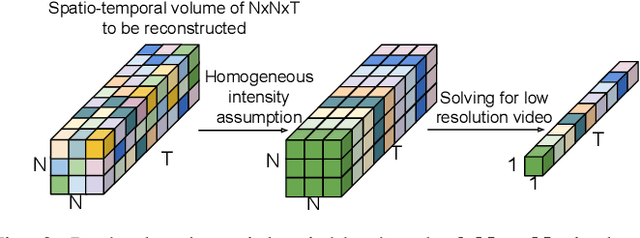

Learning-based methods have enabled the recovery of a video sequence from a single motion-blurred image or a single coded exposure image. Recovering video from a single motion-blurred image is a very ill-posed problem and the recovered video usually has many artifacts. In addition to this, the direction of motion is lost and it results in motion ambiguity. However, it has the advantage of fully preserving the information in the static parts of the scene. The traditional coded exposure framework is better-posed but it only samples a fraction of the space-time volume, which is at best 50% of the space-time volume. Here, we propose to use the complementary information present in the fully-exposed (blurred) image along with the coded exposure image to recover a high fidelity video without any motion ambiguity. Our framework consists of a shared encoder followed by an attention module to selectively combine the spatial information from the fully-exposed image with the temporal information from the coded image, which is then super-resolved to recover a non-ambiguous high-quality video. The input to our algorithm is a fully-exposed and coded image pair. Such an acquisition system already exists in the form of a Coded-two-bucket (C2B) camera. We demonstrate that our proposed deep learning approach using blurred-coded image pair produces much better results than those from just a blurred image or just a coded image.
Better Knowledge Retention through Metric Learning
Nov 26, 2020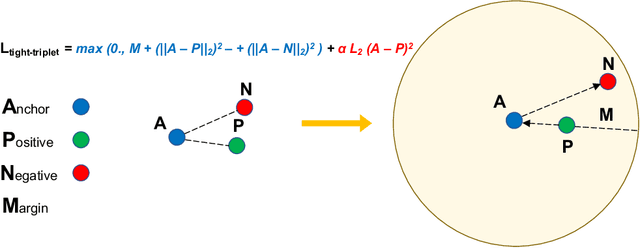
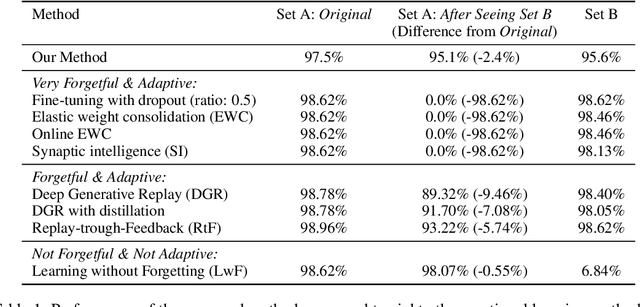
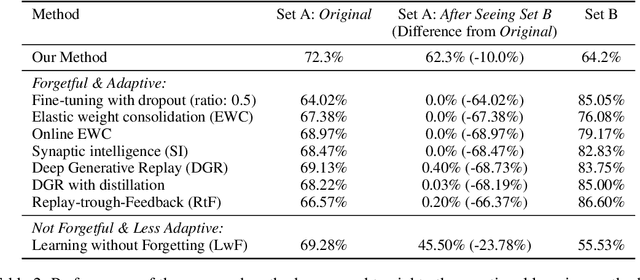
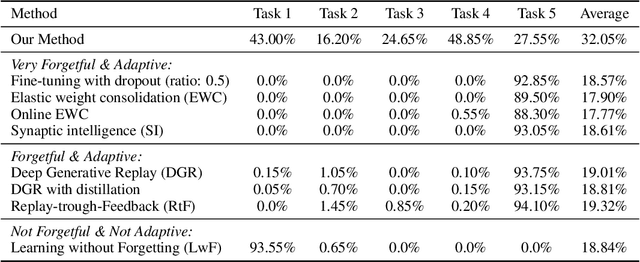
In continual learning, new categories may be introduced over time, and an ideal learning system should perform well on both the original categories and the new categories. While deep neural nets have achieved resounding success in the classical supervised setting, they are known to forget about knowledge acquired in prior episodes of learning if the examples encountered in the current episode of learning are drastically different from those encountered in prior episodes. In this paper, we propose a new method that can both leverage the expressive power of deep neural nets and is resilient to forgetting when new categories are introduced. We found the proposed method can reduce forgetting by 2.3x to 6.9x on CIFAR-10 compared to existing methods and by 1.8x to 2.7x on ImageNet compared to an oracle baseline.
A Two-Stage Metaheuristic Algorithm for the Dynamic Vehicle Routing Problem in Industry 4.0 approach
Aug 26, 2020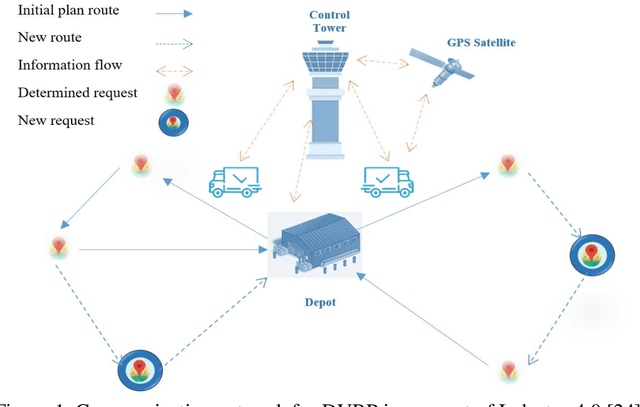

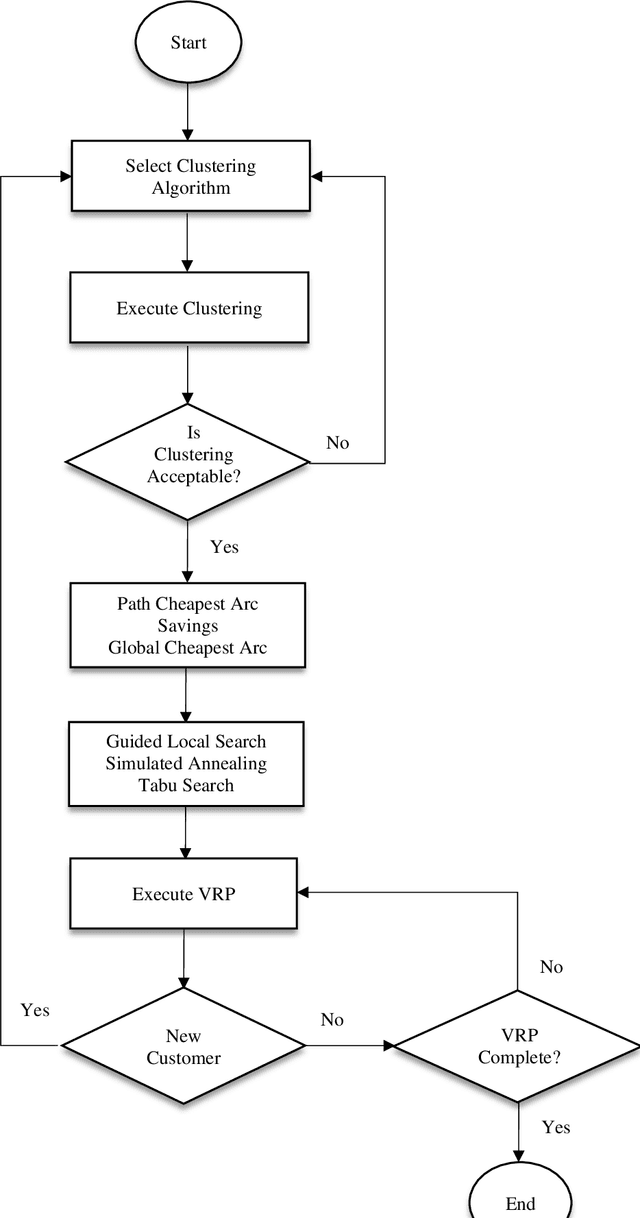
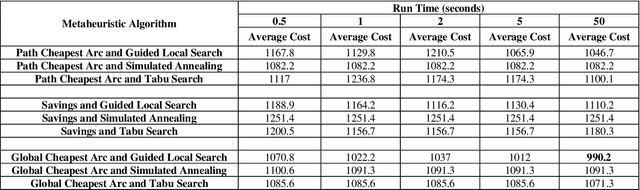
Industry 4.0 is a concept that assists companies in developing a modern supply chain (MSC) system when they are faced with a dynamic process. Because Industry 4.0 focuses on mobility and real-time integration, it is a good framework for a dynamic vehicle routing problem (DVRP). This research works on DVRP. The aim of this research is to minimize transportation cost without exceeding the capacity constraint of each vehicle while serving customer demands from a common depot. Meanwhile, new orders arrive at a specific time into the system while the vehicles are executing the delivery of existing orders. This paper presents a two-stage hybrid algorithm for solving the DVRP. In the first stage, construction algorithms are applied to develop the initial route. In the second stage, improvement algorithms are applied. Experimental results were designed for different sizes of problems. Analysis results show the effectiveness of the proposed algorithm.
Robust Semantic Segmentation in Adverse Weather Conditions by means of Fast Video-Sequence Segmentation
Jul 01, 2020
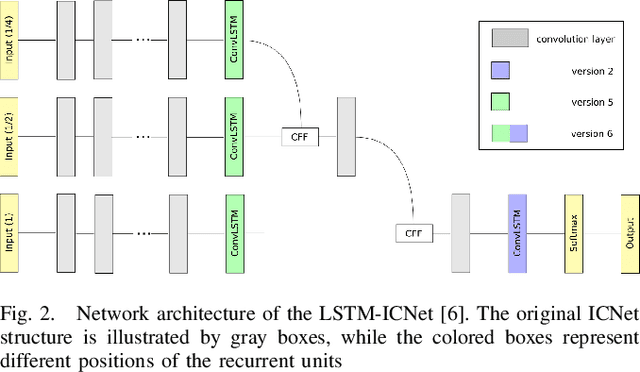
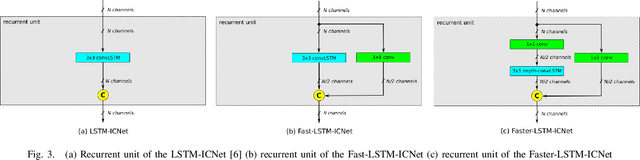
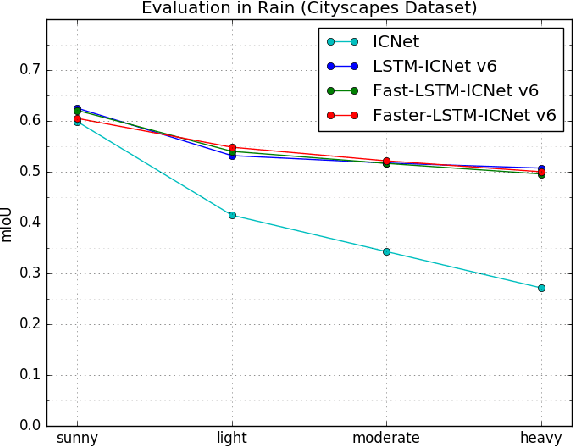
Computer vision tasks such as semantic segmentation perform very well in good weather conditions, but if the weather turns bad, they have problems to achieve this performance in these conditions. One possibility to obtain more robust and reliable results in adverse weather conditions is to use video-segmentation approaches instead of commonly used single-image segmentation methods. Video-segmentation approaches capture temporal information of the previous video-frames in addition to current image information, and hence, they are more robust against disturbances, especially if they occur in only a few frames of the video-sequence. However, video-segmentation approaches, which are often based on recurrent neural networks, cannot be applied in real-time applications anymore, since their recurrent structures in the network are computational expensive. For instance, the inference time of the LSTM-ICNet, in which recurrent units are placed at proper positions in the single-segmentation approach ICNet, increases up to 61 percent compared to the basic ICNet. Hence, in this work, the LSTM-ICNet is sped up by modifying the recurrent units of the network so that it becomes real-time capable again. Experiments on different datasets and various weather conditions show that the inference time can be decreased by about 23 percent by these modifications, while they achieve similar performance than the LSTM-ICNet and outperform the single-segmentation approach enormously in adverse weather conditions.
The Road Towards 6G: A Comprehensive Survey
Feb 02, 2021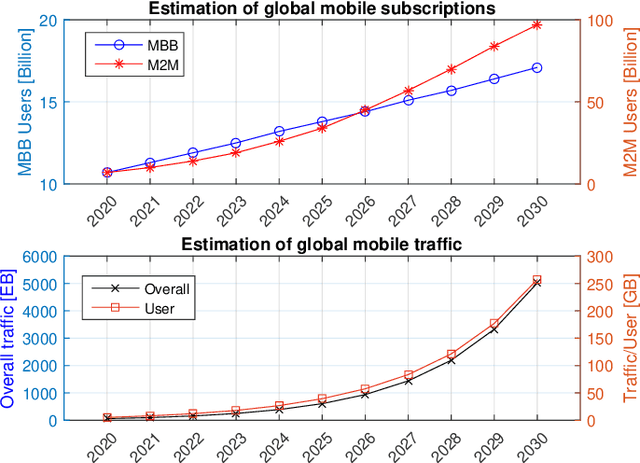
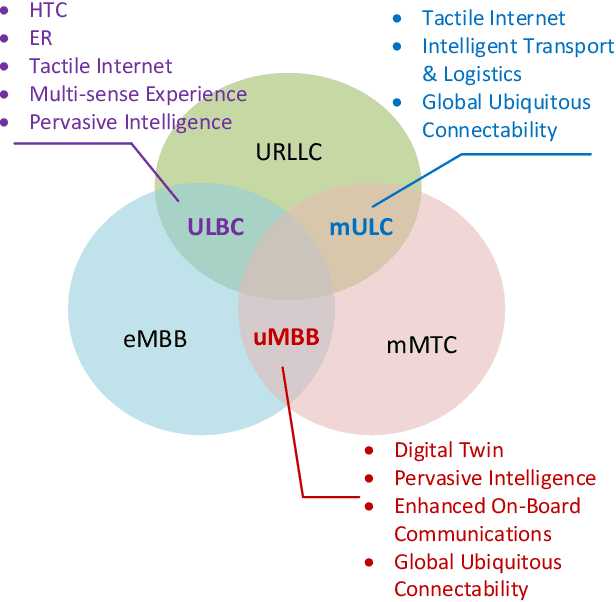
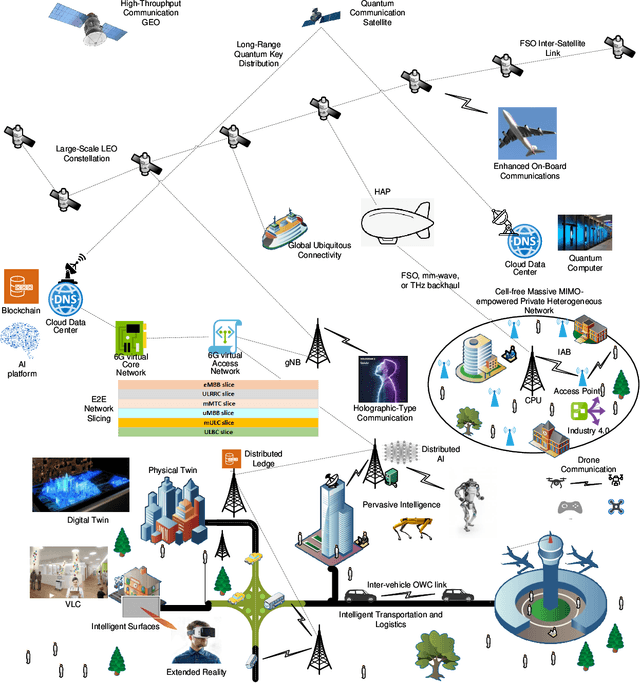
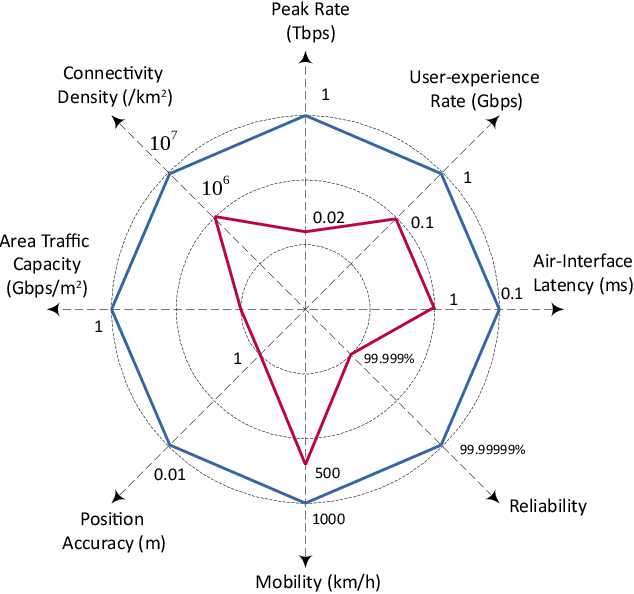
As of today, the fifth generation (5G) mobile communication system has been rolled out in many countries and the number of 5G subscribers already reaches a very large scale. It is time for academia and industry to shift their attention towards the next generation. At this crossroad, an overview of the current state of the art and a vision of future communications are definitely of interest. This article thus aims to provide a comprehensive survey to draw a picture of the sixth generation (6G) system in terms of drivers, use cases, usage scenarios, requirements, key performance indicators (KPIs), architecture, and enabling technologies. First, we attempt to answer the question of "Is there any need for 6G?" by shedding light on its key driving factors, in which we predict the explosive growth of mobile traffic until 2030, and envision potential use cases and usage scenarios. Second, the technical requirements of 6G are discussed and compared with those of 5G with respect to a set of KPIs in a quantitative manner. Third, the state-of-the-art 6G research efforts and activities from representative institutions and countries are summarized, and a tentative roadmap of definition, specification, standardization, and regulation is projected. Then, we identify a dozen of potential technologies and introduce their principles, advantages, challenges, and open research issues. Finally, the conclusions are drawn to paint a picture of "What 6G may look like?". This survey is intended to serve as an enlightening guideline to spur interests and further investigations for subsequent research and development of 6G communications systems.
The Consequences of the Framing of Machine Learning Risk Prediction Models: Evaluation of Sepsis in General Wards
Jan 26, 2021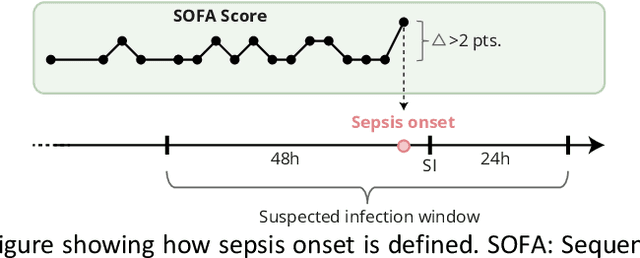

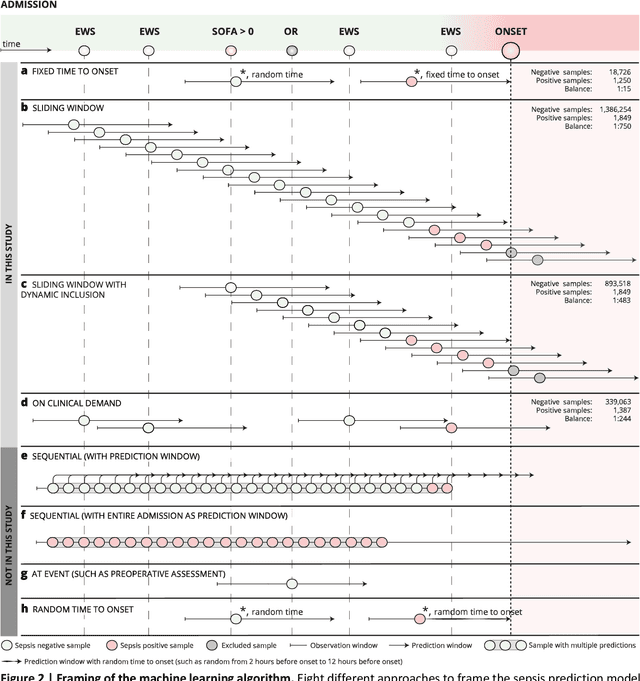

Objectives: To evaluate the consequences of the framing of machine learning risk prediction models. We evaluate how framing affects model performance and model learning in four different approaches previously applied in published artificial-intelligence (AI) models. Setting and participants: We analysed structured secondary healthcare data from 221,283 citizens from four Danish municipalities who were 18 years of age or older. Results: The four models had similar population level performance (a mean area under the receiver operating characteristic curve of 0.73 to 0.82), in contrast to the mean average precision, which varied greatly from 0.007 to 0.385. Correspondingly, the percentage of missing values also varied between framing approaches. The on-clinical-demand framing, which involved samples for each time the clinicians made an early warning score assessment, showed the lowest percentage of missing values among the vital sign parameters, and this model was also able to learn more temporal dependencies than the others. The Shapley additive explanations demonstrated opposing interpretations of SpO2 in the prediction of sepsis as a consequence of differentially framed models. Conclusions: The profound consequences of framing mandate attention from clinicians and AI developers, as the understanding and reporting of framing are pivotal to the successful development and clinical implementation of future AI technology. Model framing must reflect the expected clinical environment. The importance of proper problem framing is by no means exclusive to sepsis prediction and applies to most clinical risk prediction models.
On the confidence of stereo matching in a deep-learning era: a quantitative evaluation
Jan 02, 2021
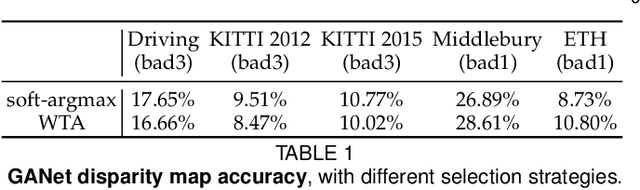
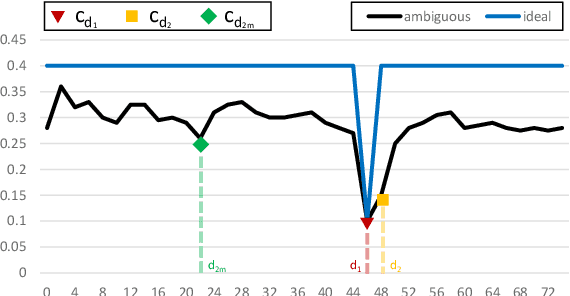
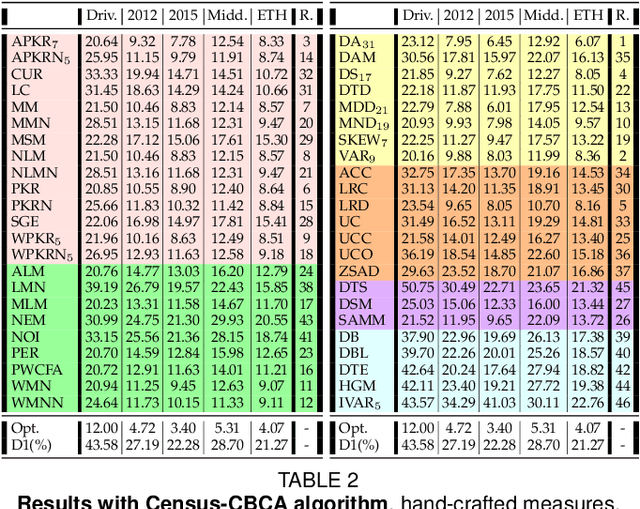
Stereo matching is one of the most popular techniques to estimate dense depth maps by finding the disparity between matching pixels on two, synchronized and rectified images. Alongside with the development of more accurate algorithms, the research community focused on finding good strategies to estimate the reliability, i.e. the confidence, of estimated disparity maps. This information proves to be a powerful cue to naively find wrong matches as well as to improve the overall effectiveness of a variety of stereo algorithms according to different strategies. In this paper, we review more than ten years of developments in the field of confidence estimation for stereo matching. We extensively discuss and evaluate existing confidence measures and their variants, from hand-crafted ones to the most recent, state-of-the-art learning based methods. We study the different behaviors of each measure when applied to a pool of different stereo algorithms and, for the first time in literature, when paired with a state-of-the-art deep stereo network. Our experiments, carried out on five different standard datasets, provide a comprehensive overview of the field, highlighting in particular both strengths and limitations of learning-based strategies.