 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-based performance measures for Time-Domain Global Similarity method
Nov 08, 2017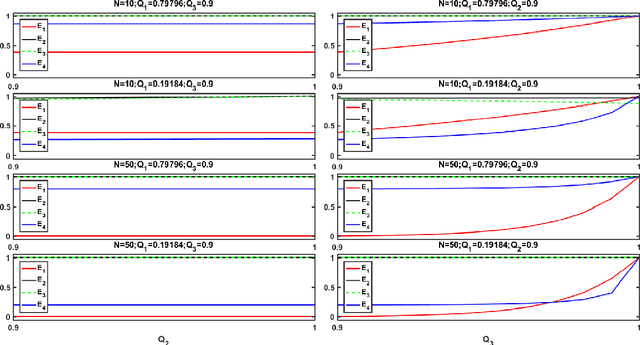
For Time-Domain Global Similarity (TDGS) method, which transforms the data cleaning problem into a binary classification problem about the physical similarity between channels, directly adopting common performance measures could only guarantee the performance for physical similarity. Nevertheless, practical data cleaning tasks have preferences for the correctness of original data sequences. To obtain the general expressions of performance measures based on the preferences of tasks, the mapping relations between performance of TDGS method about physical similarity and correctness of data sequences are investigated by probability theory in this paper. Performance measures for TDGS method in several common data cleaning tasks are set. Cases when these preference-based performance measures could be simplified are introduced.
Improvement of training set structure in fusion data cleaning using Time-Domain Global Similarity method
Jun 30, 2017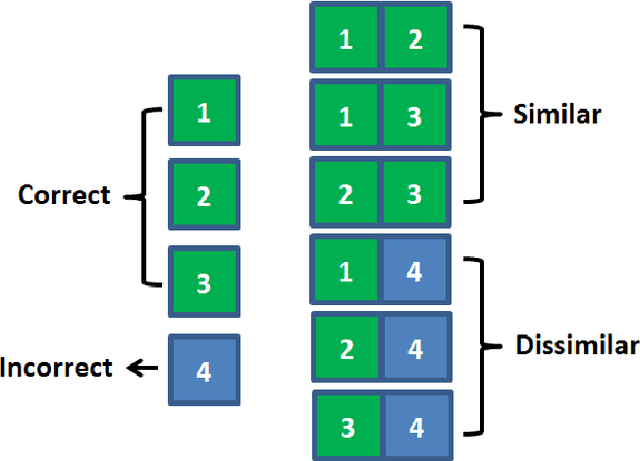
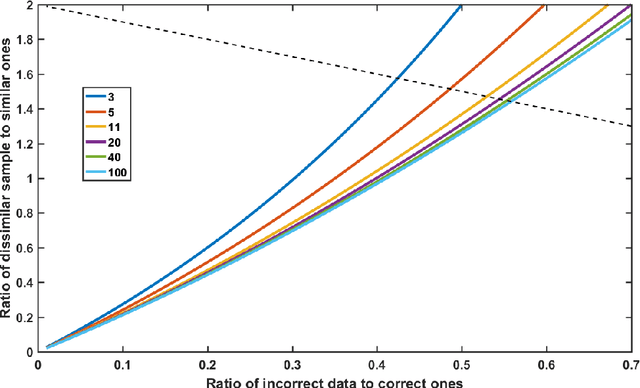
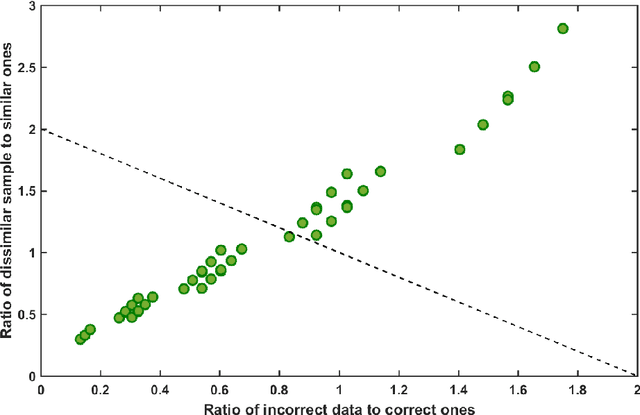
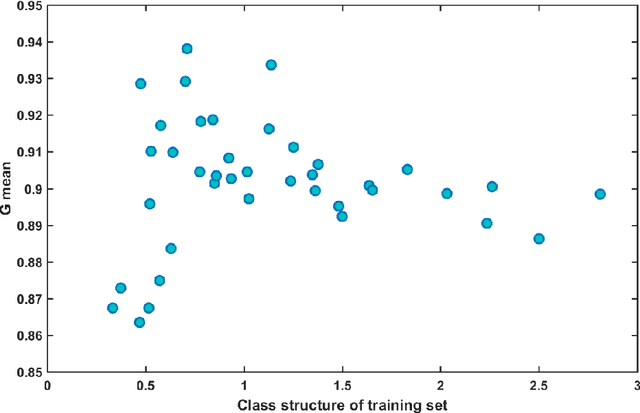
Traditional data cleaning identifies dirty data by classifying original data sequences, which is a class$-$imbalanced problem since the proportion of incorrect data is much less than the proportion of correct ones for most diagnostic systems in Magnetic Confinement Fusion (MCF) devices. When using machine learning algorithms to classify diagnostic data based on class$-$imbalanced training set, most classifiers are biased towards the major class and show very poor classification rates on the minor class. By transforming the direct classification problem about original data sequences into a classification problem about the physical similarity between data sequences, the class$-$balanced effect of Time$-$Domain Global Similarity (TDGS) method on training set structure is investigated in this paper. Meanwhile, the impact of improved training set structure on data cleaning performance of TDGS method is demonstrated with an application example in EAST POlarimetry$-$INTerferometry (POINT) system.