 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fake it Till You Make it: Self-Supervised Semantic Shifts for Monolingual Word Embedding Tasks
Jan 30, 2021
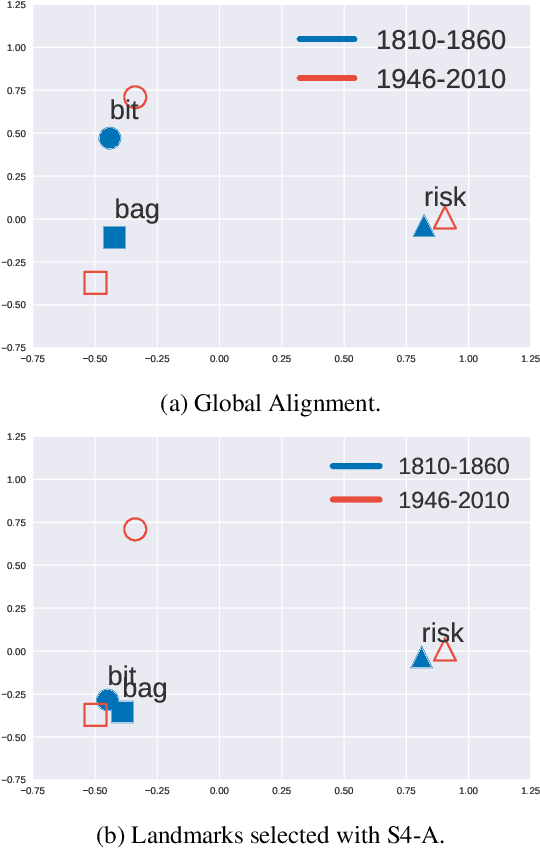
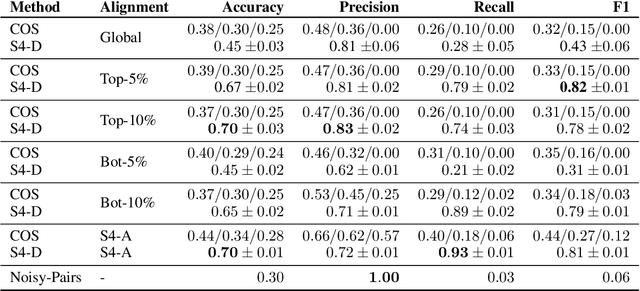
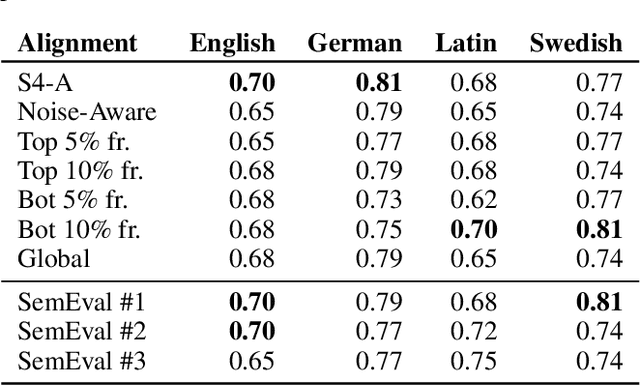
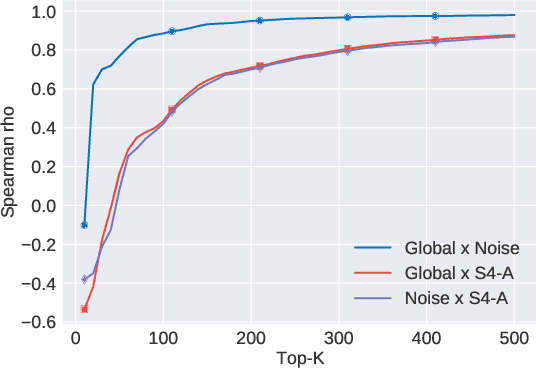
The use of language is subject to variation over time as well as across social groups and knowledge domains, leading to differences even in the monolingual scenario. Such variation in word usage is often called lexical semantic change (LSC). The goal of LSC is to characterize and quantify language variations with respect to word meaning, to measure how distinct two language sources are (that is, people or language models). Because there is hardly any data available for such a task, most solutions involve unsupervised methods to align two embeddings and predict semantic change with respect to a distance measure. To that end, we propose a self-supervised approach to model lexical semantic change by generating training samples by introducing perturbations of word vectors in the input corpora. We show that our method can be used for the detection of semantic change with any alignment method. Furthermore, it can be used to choose the landmark words to use in alignment and can lead to substantial improvements over the existing techniques for alignment. We illustrate the utility of our techniques using experimental results on three different datasets, involving words with the same or different meanings. Our methods not only provide significant improvements but also can lead to novel findings for the LSC problem.
A3T-GCN: Attention Temporal Graph Convolutional Network for Traffic Forecasting
Jun 20, 2020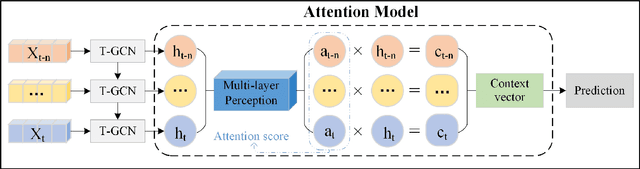
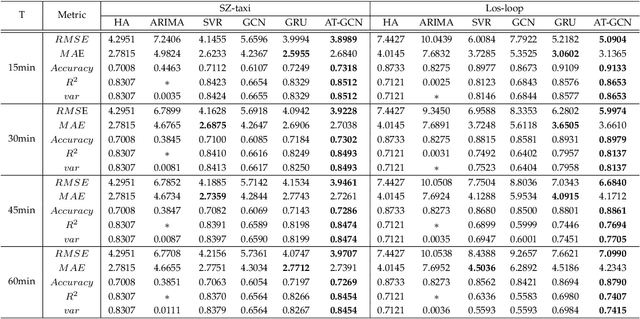
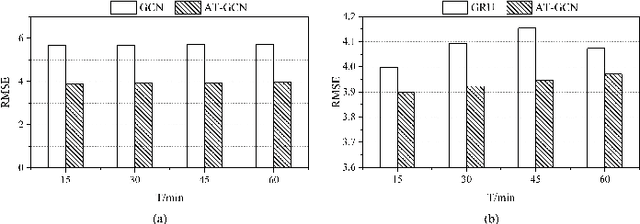
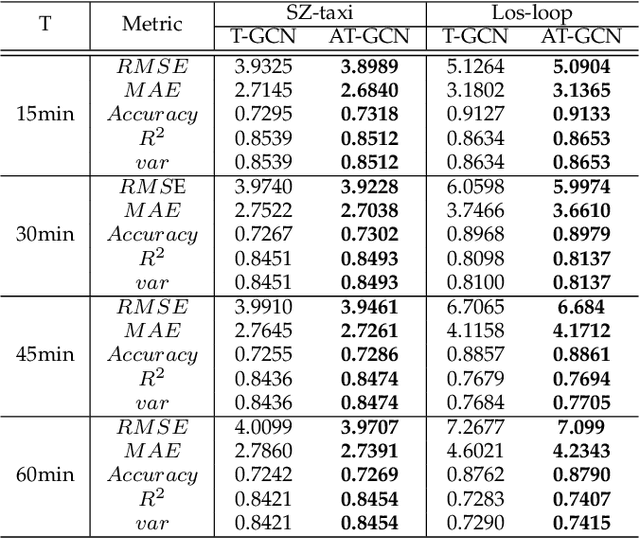
Accurate real-time traffic forecasting is a core technological problem against the implementation of the intelligent transportation system. However, it remains challenging considering the complex spatial and temporal dependencies among traffic flows. In the spatial dimension, due to the connectivity of the road network, the traffic flows between linked roads are closely related. In terms of the temporal factor, although there exists a tendency among adjacent time points in general, the importance of distant past points is not necessarily smaller than that of recent past points since traffic flows are also affected by external factors. In this study, an attention temporal graph convolutional network (A3T-GCN) traffic forecasting method was proposed to simultaneously capture global temporal dynamics and spatial correlations. The A3T-GCN model learns the short-time trend in time series by using the gated recurrent units and learns the spatial dependence based on the topology of the road network through the graph convolutional network. Moreover, the attention mechanism was introduced to adjust the importance of different time points and assemble global temporal information to improve prediction accuracy. Experimental results in real-world datasets demonstrate the effectiveness and robustness of proposed A3T-GCN. The source code can be visited at https://github.com/lehaifeng/T-GCN/A3T.
MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks
Jan 15, 2019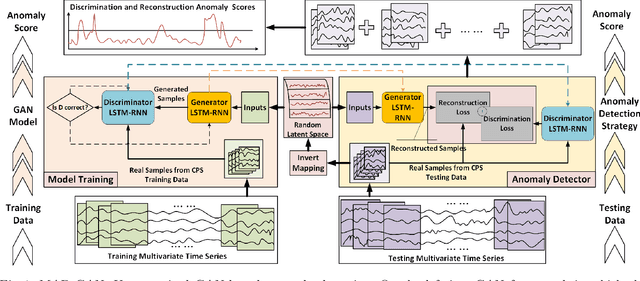
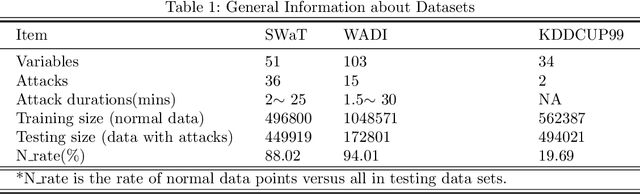
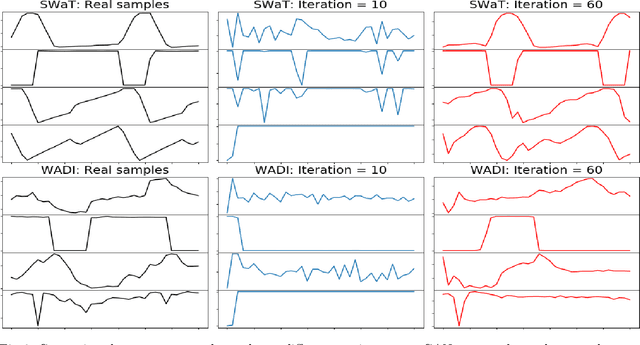
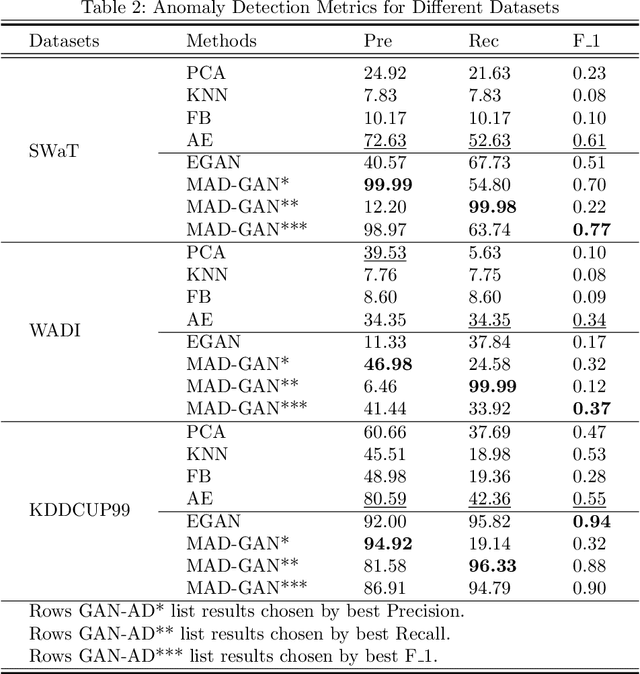
The prevalence of networked sensors and actuators in many real-world systems such as smart buildings, factories, power plants, and data centers generate substantial amounts of multivariate time series data for these systems. The rich sensor data can be continuously monitored for intrusion events through anomaly detection. However, conventional threshold-based anomaly detection methods are inadequate due to the dynamic complexities of these systems, while supervised machine learning methods are unable to exploit the large amounts of data due to the lack of labeled data. On the other hand, current unsupervised machine learning approaches have not fully exploited the spatial-temporal correlation and other dependencies amongst the multiple variables (sensors/actuators) in the system for detecting anomalies. In this work, we propose an unsupervised multivariate anomaly detection method based on Generative Adversarial Networks (GANs). Instead of treating each data stream independently, our proposed MAD-GAN framework considers the entire variable set concurrently to capture the latent interactions amongst the variables. We also fully exploit both the generator and discriminator produced by the GAN, using a novel anomaly score called DR-score to detect anomalies by discrimination and reconstruction. We have tested our proposed MAD-GAN using two recent datasets collected from real-world CPS: the Secure Water Treatment (SWaT) and the Water Distribution (WADI) datasets. Our experimental results showed that the proposed MAD-GAN is effective in reporting anomalies caused by various cyber-intrusions compared in these complex real-world systems.
EdgeLoc: An Edge-IoT Framework for Robust Indoor Localization Using Capsule Networks
Sep 12, 2020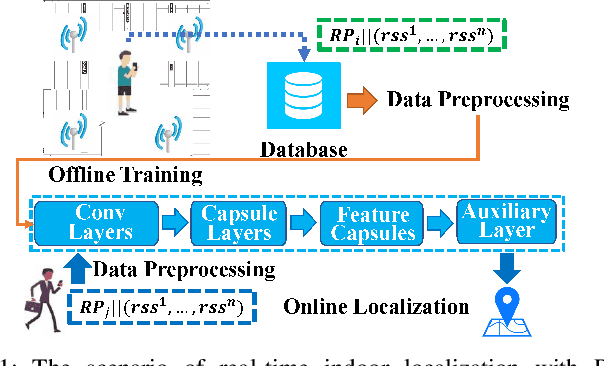
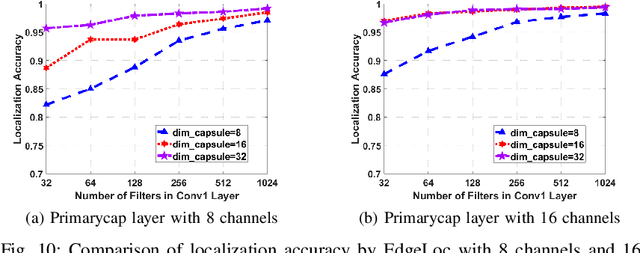
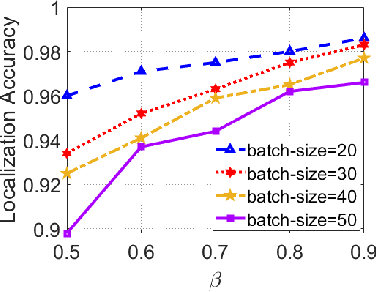
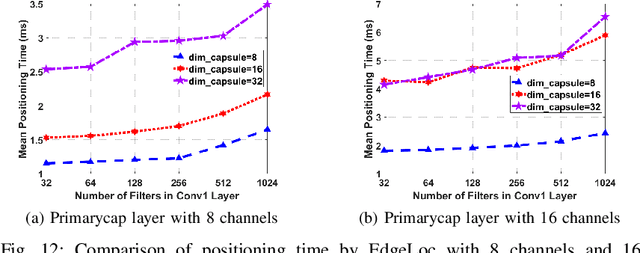
With the unprecedented demand for location-based services in indoor scenarios, wireless indoor localization has become essential for mobile users. While GPS is not available at indoor spaces, WiFi RSS fingerprinting has become popular with its ubiquitous accessibility. However, it is challenging to achieve robust and efficient indoor localization with two major challenges. First, the localization accuracy can be degraded by the random signal fluctuations, which would influence conventional localization algorithms that simply learn handcrafted features from raw fingerprint data. Second, mobile users are sensitive to the localization delay, but conventional indoor localization algorithms are computation-intensive and time-consuming. In this paper, we propose EdgeLoc, an edge-IoT framework for efficient and robust indoor localization using capsule networks. We develop a deep learning model with the CapsNet to efficiently extract hierarchical information from WiFi fingerprint data, thereby significantly improving the localization accuracy. Moreover, we implement an edge-computing prototype system to achieve a nearly real-time localization process, by enabling mobile users with the deep-learning model that has been well-trained by the edge server. We conduct a real-world field experimental study with over 33,600 data points and an extensive synthetic experiment with the open dataset, and the experimental results validate the effectiveness of EdgeLoc. The best trade-off of the EdgeLoc system achieves 98.5% localization accuracy within an average positioning time of only 2.31 ms in the field experiment.
Super-resolution-based Change Detection Network with Stacked Attention Module for Images with Different Resolutions
Feb 27, 2021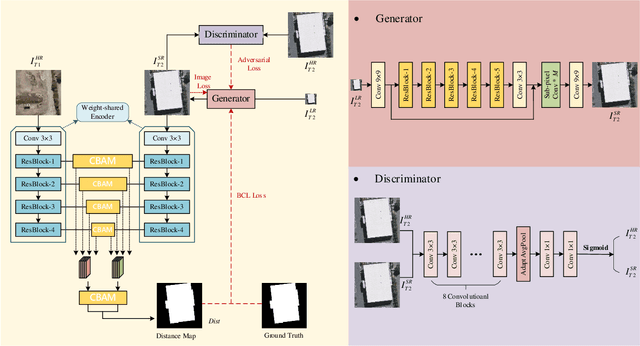

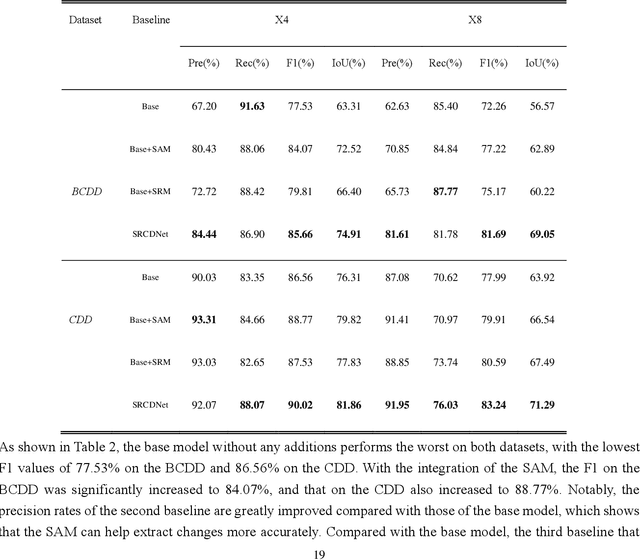

Change detection, which aims to distinguish surface changes based on bi-temporal images, plays a vital role in ecological protection and urban planning. Since high resolution (HR) images cannot be typically acquired continuously over time, bi-temporal images with different resolutions are often adopted for change detection in practical applications. Traditional subpixel-based methods for change detection using images with different resolutions may lead to substantial error accumulation when HR images are employed; this is because of intraclass heterogeneity and interclass similarity. Therefore, it is necessary to develop a novel method for change detection using images with different resolutions, that is more suitable for HR images. To this end, we propose a super-resolution-based change detection network (SRCDNet) with a stacked attention module. The SRCDNet employs a super resolution (SR) module containing a generator and a discriminator to directly learn SR images through adversarial learning and overcome the resolution difference between bi-temporal images. To enhance the useful information in multi-scale features, a stacked attention module consisting of five convolutional block attention modules (CBAMs) is integrated to the feature extractor. The final change map is obtained through a metric learning-based change decision module, wherein a distance map between bi-temporal features is calculated. The experimental results demonstrate the superiority of the proposed method, which not only outperforms all baselines -with the highest F1 scores of 87.40% on the building change detection dataset and 92.94% on the change detection dataset -but also obtains the best accuracies on experiments performed with images having a 4x and 8x resolution difference. The source code of SRCDNet will be available at https://github.com/liumency/SRCDNet.
Hierarchical Recurrent Attention Networks for Structured Online Maps
Dec 22, 2020
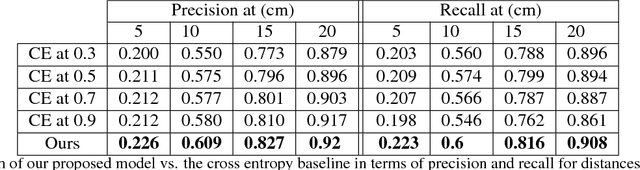
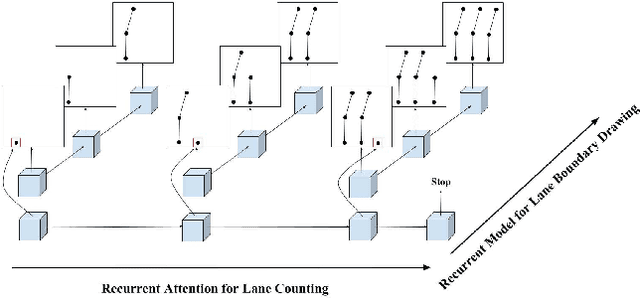

In this paper, we tackle the problem of online road network extraction from sparse 3D point clouds. Our method is inspired by how an annotator builds a lane graph, by first identifying how many lanes there are and then drawing each one in turn. We develop a hierarchical recurrent network that attends to initial regions of a lane boundary and traces them out completely by outputting a structured polyline. We also propose a novel differentiable loss function that measures the deviation of the edges of the ground truth polylines and their predictions. This is more suitable than distances on vertices, as there exists many ways to draw equivalent polylines. We demonstrate the effectiveness of our method on a 90 km stretch of highway, and show that we can recover the right topology 92\% of the time.
MP3net: coherent, minute-long music generation from raw audio with a simple convolutional GAN
Jan 12, 2021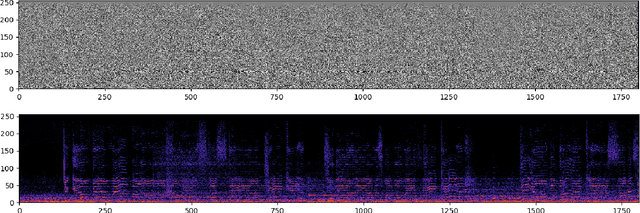
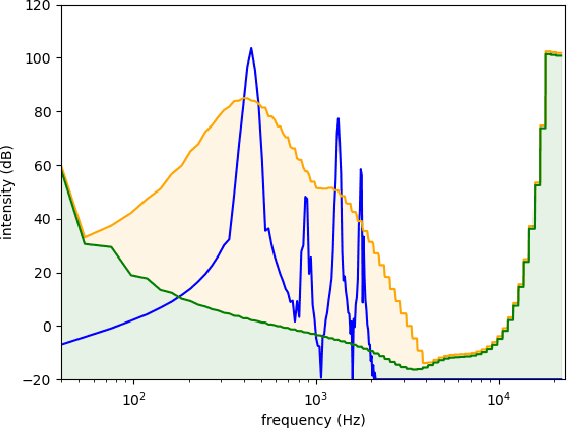
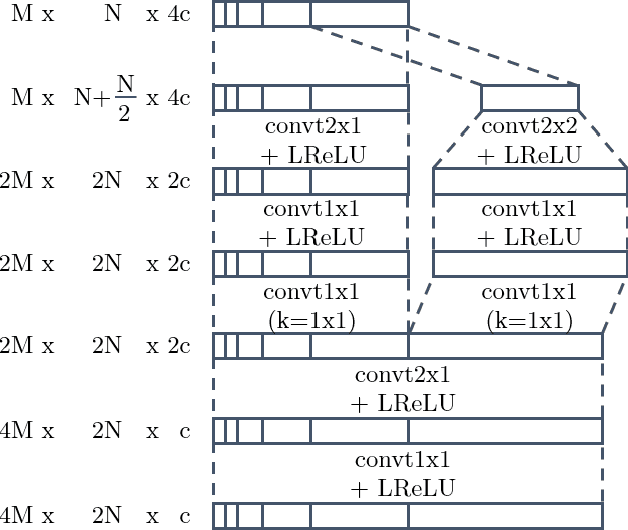
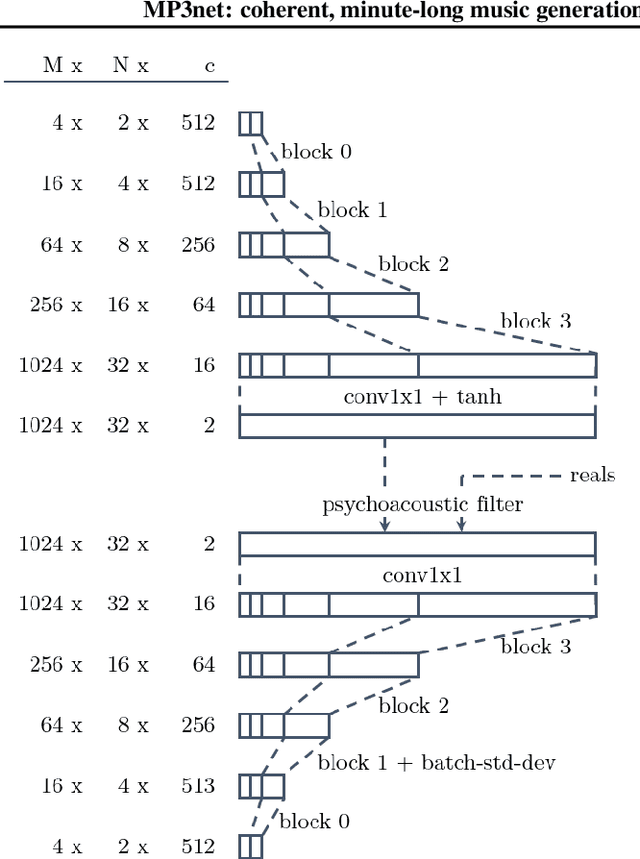
We present a deep convolutional GAN which leverages techniques from MP3/Vorbis audio compression to produce long, high-quality audio samples with long-range coherence. The model uses a Modified Discrete Cosine Transform (MDCT) data representation, which includes all phase information. Phase generation is hence integral part of the model. We leverage the auditory masking and psychoacoustic perception limit of the human ear to widen the true distribution and stabilize the training process. The model architecture is a deep 2D convolutional network, where each subsequent generator model block increases the resolution along the time axis and adds a higher octave along the frequency axis. The deeper layers are connected with all parts of the output and have the context of the full track. This enables generation of samples which exhibit long-range coherence. We use MP3net to create 95s stereo tracks with a 22kHz sample rate after training for 250h on a single Cloud TPUv2. An additional benefit of the CNN-based model architecture is that generation of new songs is almost instantaneous.
The Robot Household Marathon Experiment
Nov 19, 2020
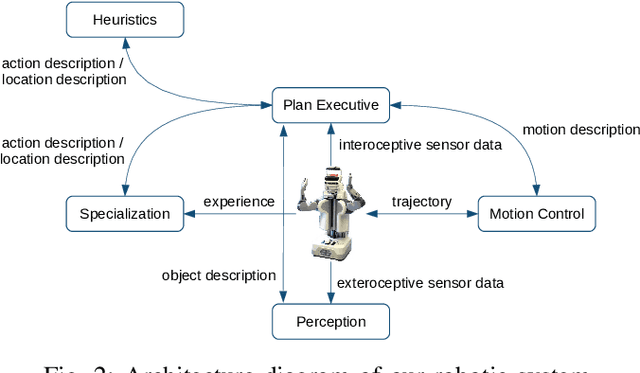
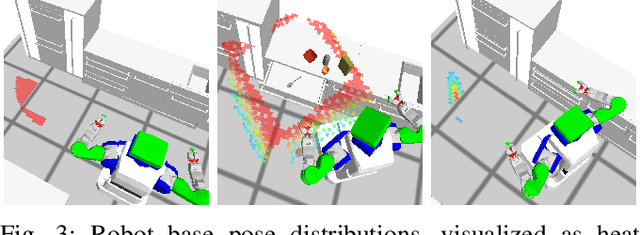

In this paper, we present an experiment, designed to investigate and evaluate the scalability and the robustness aspects of mobile manipulation. The experiment involves performing variations of mobile pick and place actions and opening/closing environment containers in a human household. The robot is expected to act completely autonomously for extended periods of time. We discuss the scientific challenges raised by the experiment as well as present our robotic system that can address these challenges and successfully perform all the tasks of the experiment. We present empirical results and the lessons learned as well as discuss where we hit limitations.
Clustering Financial Time Series: How Long is Enough?
Apr 14, 2016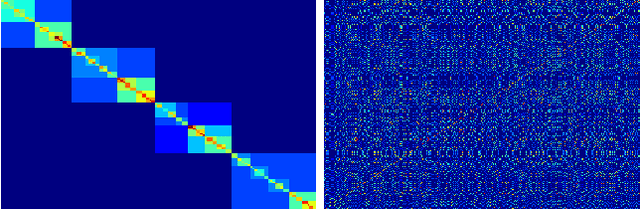
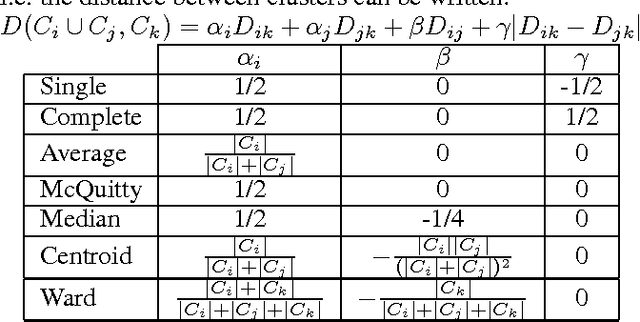
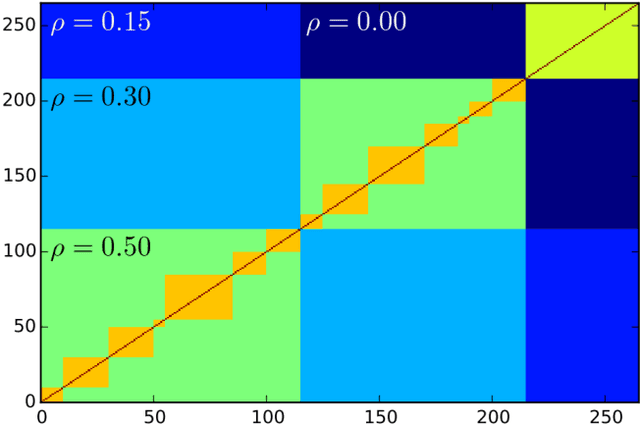
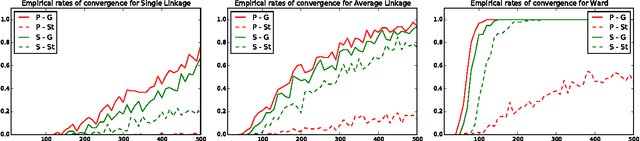
Researchers have used from 30 days to several years of daily returns as source data for clustering financial time series based on their correlations. This paper sets up a statistical framework to study the validity of such practices. We first show that clustering correlated random variables from their observed values is statistically consistent. Then, we also give a first empirical answer to the much debated question: How long should the time series be? If too short, the clusters found can be spurious; if too long, dynamics can be smoothed out.
Predictive Probability Path Planning Model For Dynamic Environments
Jul 29, 2020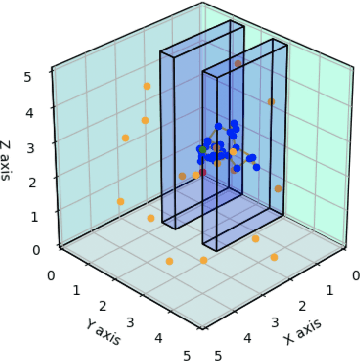
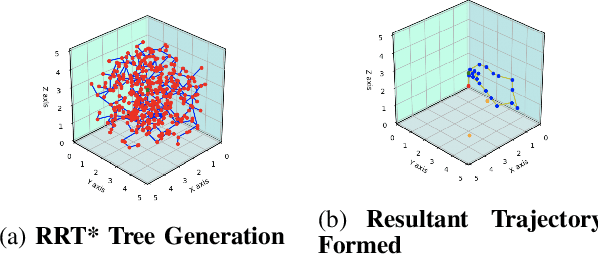
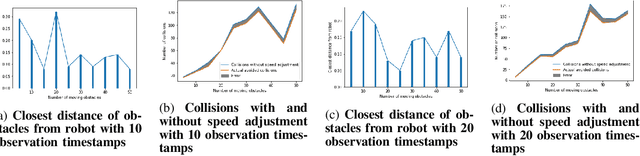
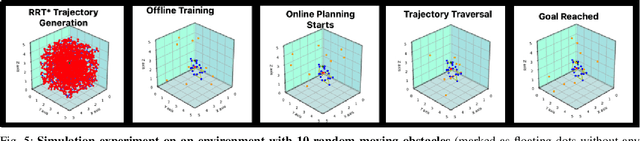
Path planning in dynamic environments is essential to high-risk applications such as unmanned aerial vehicles, self-driving cars, and autonomous underwater vehicles. In this paper, we generate collision-free trajectories for a robot within any given environment with temporal and spatial uncertainties caused due to randomly moving obstacles. We use two Poisson distributions to model the movements of obstacles across the generated trajectory of a robot in both space and time to determine the probability of collision with an obstacle. Measures are taken to avoid an obstacle by intelligently manipulating the speed of the robot at space-time intervals where a larger number of obstacles intersect the trajectory of the robot. Our method potentially reduces the use of computationally expensive collision detection libraries. Based on our experiments, there has been a significant improvement over existing methods in terms of safety, accuracy, execution time and computational cost. Our results show a high level of accuracy between the predicted and actual number of collisions with moving obstacles.