 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable Scene Flow from Point Clouds in the Real World
Mar 03, 2021
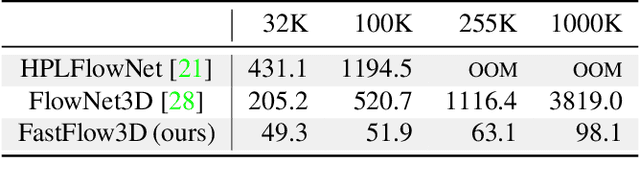
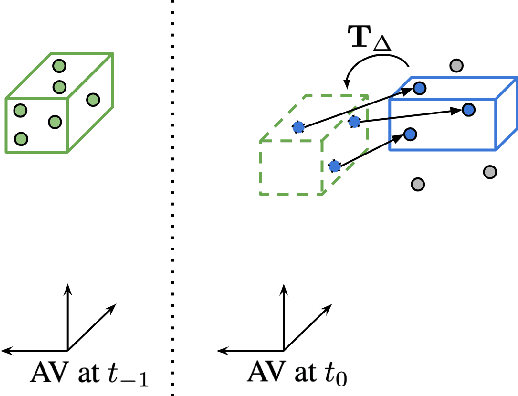
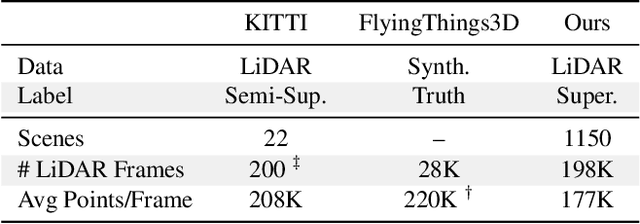
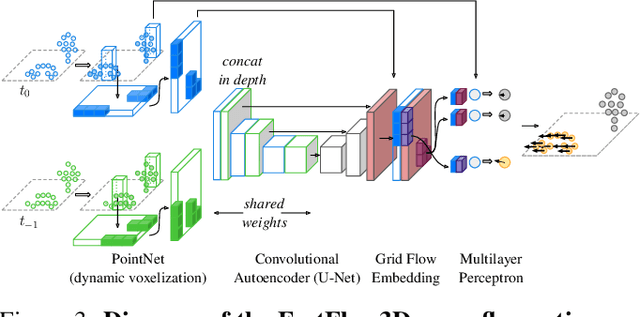
Autonomous vehicles operate in highly dynamic environments necessitating an accurate assessment of which aspects of a scene are moving and where they are moving to. A popular approach to 3D motion estimation -- termed scene flow -- is to employ 3D point cloud data from consecutive LiDAR scans, although such approaches have been limited by the small size of real-world, annotated LiDAR data. In this work, we introduce a new large scale benchmark for scene flow based on the Waymo Open Dataset. The dataset is $\sim$1,000$\times$ larger than previous real-world datasets in terms of the number of annotated frames and is derived from the corresponding tracked 3D objects. We demonstrate how previous works were bounded based on the amount of real LiDAR data available, suggesting that larger datasets are required to achieve state-of-the-art predictive performance. Furthermore, we show how previous heuristics for operating on point clouds such as artificial down-sampling heavily degrade performance, motivating a new class of models that are tractable on the full point cloud. To address this issue, we introduce the model architecture FastFlow3D that provides real time inference on the full point cloud. Finally, we demonstrate that this problem is amenable to techniques from semi-supervised learning by highlighting open problems for generalizing methods for predicting motion on unlabeled objects. We hope that this dataset may provide new opportunities for developing real world scene flow systems and motivate a new class of machine learning problems.
An Unsupervised Multivariate Time Series Kernel Approach for Identifying Patients with Surgical Site Infection from Blood Samples
Mar 21, 2018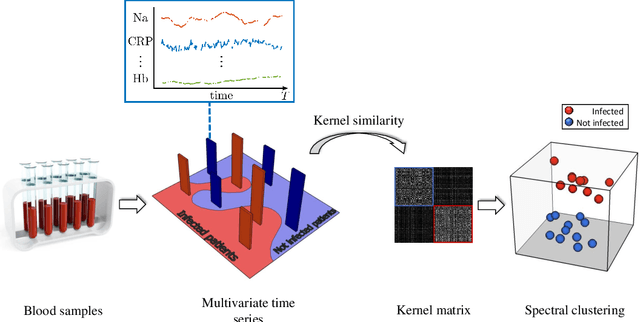
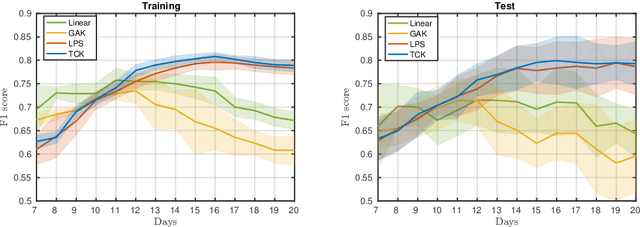
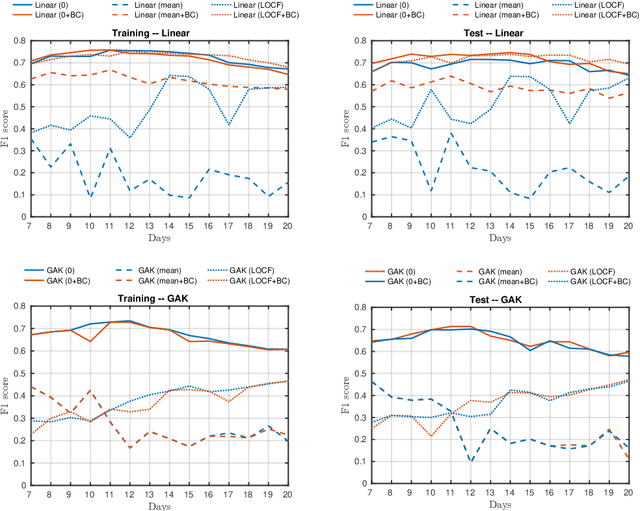
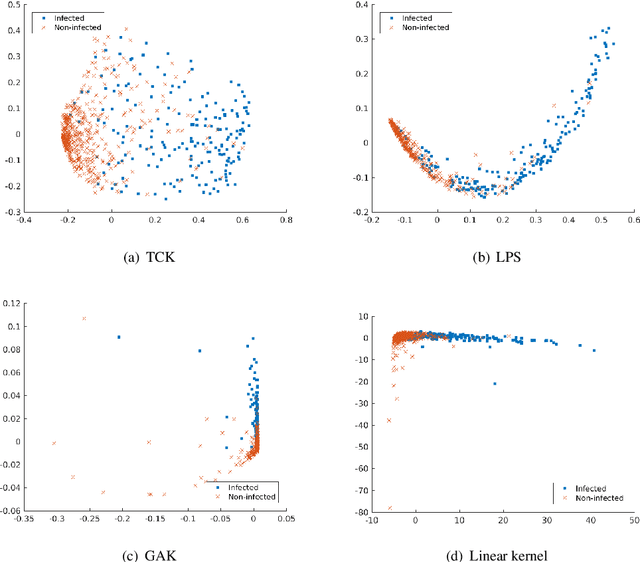
A large fraction of the electronic health records consists of clinical measurements collected over time, such as blood tests, which provide important information about the health status of a patient. These sequences of clinical measurements are naturally represented as time series, characterized by multiple variables and the presence of missing data, which complicate analysis. In this work, we propose a surgical site infection detection framework for patients undergoing colorectal cancer surgery that is completely unsupervised, hence alleviating the problem of getting access to labelled training data. The framework is based on powerful kernels for multivariate time series that account for missing data when computing similarities. Our approach show superior performance compared to baselines that have to resort to imputation techniques and performs comparable to a supervised classification baseline.
Improved active output selection strategy for noisy environments
Jan 10, 2021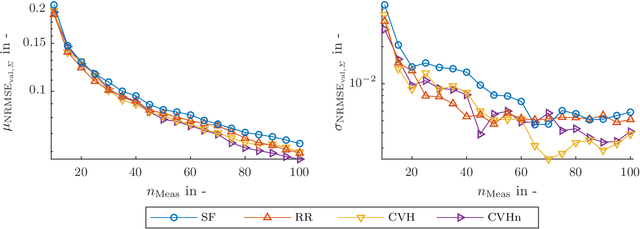
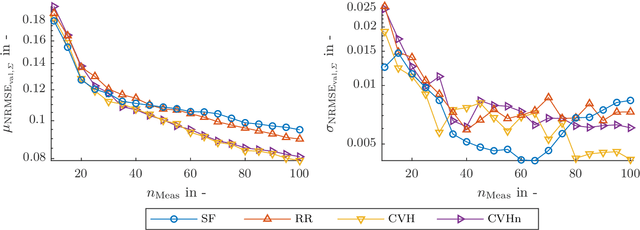
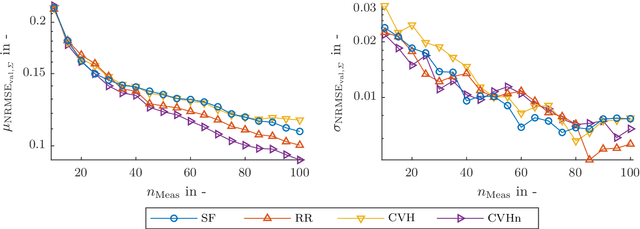
The test bench time needed for model-based calibration can be reduced with active learning methods for test design. This paper presents an improved strategy for active output selection. This is the task of learning multiple models in the same input dimensions and suits the needs of calibration tasks. Compared to an existing strategy, we take into account the noise estimate, which is inherent to Gaussian processes. The method is validated on three different toy examples. The performance compared to the existing best strategy is the same or better in each example. In a best case scenario, the new strategy needs at least 10% less measurements compared to all other active or passive strategies. Further efforts will evaluate the strategy on a real-world application. Moreover, the implementation of more sophisticated active-learning strategies for the query placement will be realized.
Optimal Full Ranking from Pairwise Comparisons
Jan 21, 2021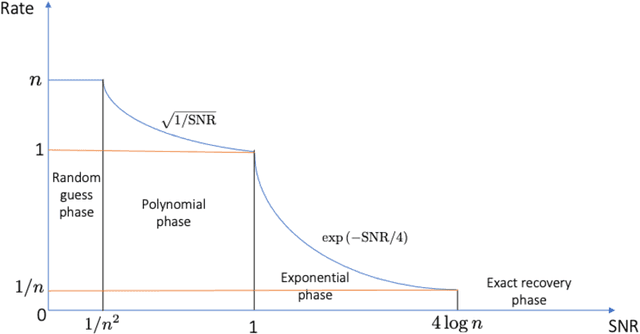
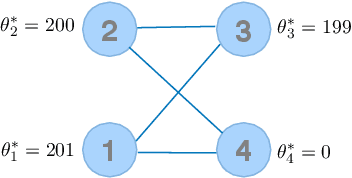
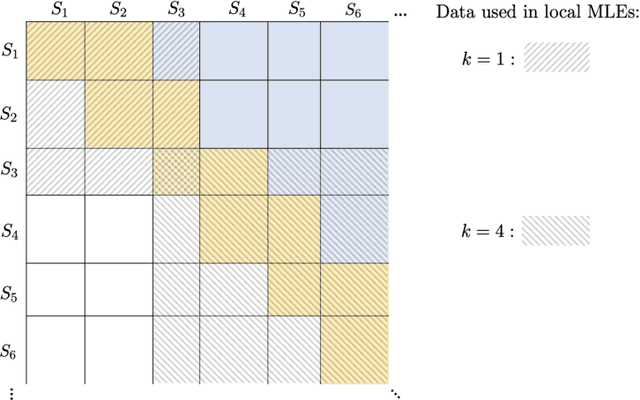
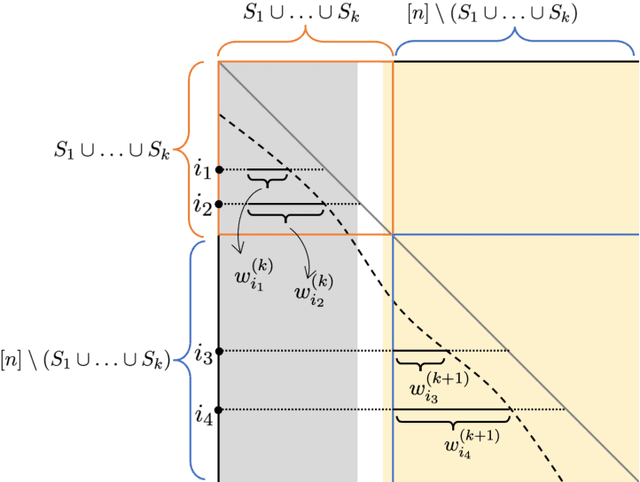
We consider the problem of ranking $n$ players from partial pairwise comparison data under the Bradley-Terry-Luce model. For the first time in the literature, the minimax rate of this ranking problem is derived with respect to the Kendall's tau distance that measures the difference between two rank vectors by counting the number of inversions. The minimax rate of ranking exhibits a transition between an exponential rate and a polynomial rate depending on the magnitude of the signal-to-noise ratio of the problem. To the best of our knowledge, this phenomenon is unique to full ranking and has not been seen in any other statistical estimation problem. To achieve the minimax rate, we propose a divide-and-conquer ranking algorithm that first divides the $n$ players into groups of similar skills and then computes local MLE within each group. The optimality of the proposed algorithm is established by a careful approximate independence argument between the two steps.
GLISTER: Generalization based Data Subset Selection for Efficient and Robust Learning
Dec 22, 2020

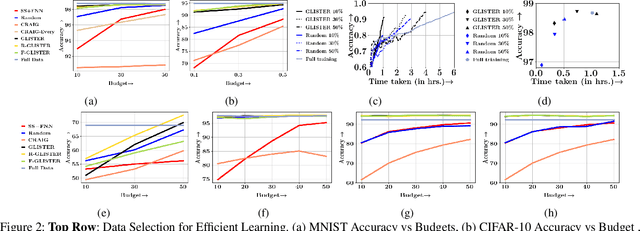
Large scale machine learning and deep models are extremely data-hungry. Unfortunately, obtaining large amounts of labeled data is expensive, and training state-of-the-art models (with hyperparameter tuning) requires significant computing resources and time. Secondly, real-world data is noisy and imbalanced. As a result, several recent papers try to make the training process more efficient and robust. However, most existing work either focuses on robustness or efficiency, but not both. In this work, we introduce Glister, a GeneraLIzation based data Subset selecTion for Efficient and Robust learning framework. We formulate Glister as a mixed discrete-continuous bi-level optimization problem to select a subset of the training data, which maximizes the log-likelihood on a held-out validation set. Next, we propose an iterative online algorithm Glister-Online, which performs data selection iteratively along with the parameter updates and can be applied to any loss-based learning algorithm. We then show that for a rich class of loss functions including cross-entropy, hinge-loss, squared-loss, and logistic-loss, the inner discrete data selection is an instance of (weakly) submodular optimization, and we analyze conditions for which Glister-Online reduces the validation loss and converges. Finally, we propose Glister-Active, an extension to batch active learning, and we empirically demonstrate the performance of Glister on a wide range of tasks including, (a) data selection to reduce training time, (b) robust learning under label noise and imbalance settings, and (c) batch-active learning with several deep and shallow models. We show that our framework improves upon state of the art both in efficiency and accuracy (in cases (a) and (c)) and is more efficient compared to other state-of-the-art robust learning algorithms in case (b).
$\textbf{MyoMapNet}$: Accelerated Modified Look-Locker Inversion Recovery Myocardial T1 Mapping via Neural Networks
Mar 31, 2021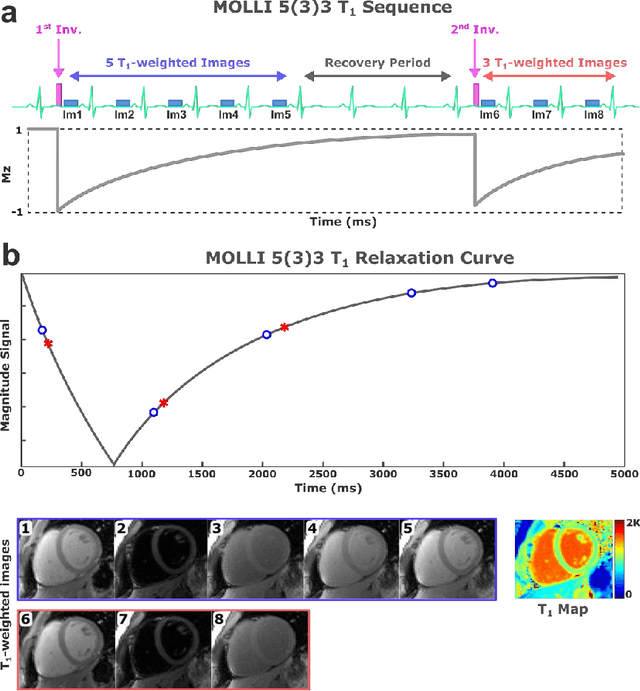
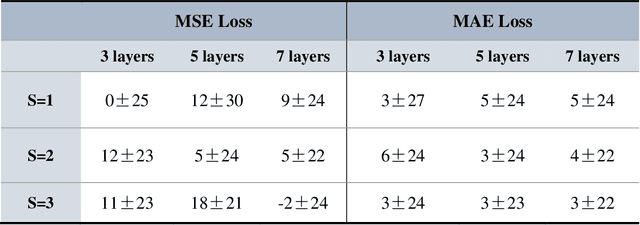
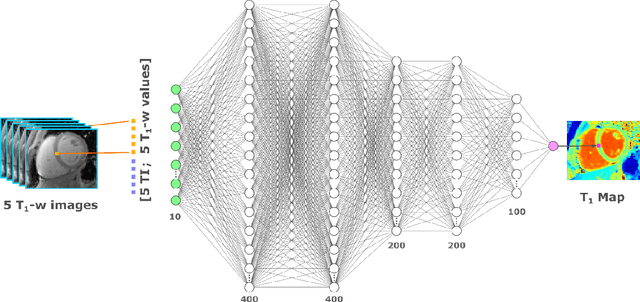
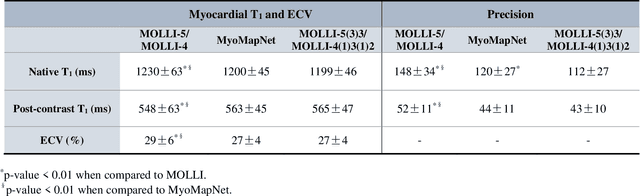
Purpose: To develop and evaluate MyoMapNet, a rapid myocardial T1 mapping approach that uses neural networks (NN) to estimate voxel-wise myocardial T1 and extracellular (ECV) from T1-weighted images collected after a single inversion pulse over 4-5 heartbeats. Method: MyoMapNet utilizes a simple fully-connected NN to estimate T1 values from 5 (native) or 4 (post-contrast) T1-weighted images. Native MOLLI-5(3)3 T1 was collected in 717 subjects (386 males, 55$\pm$16.5 years) and post-contrast MOLLI-4(1)3(1)2 in 535 subjects (232 male, 56.5$\pm$15 years). The dataset was divided into training (80%) and testing (20%), where 20% of the training set was used to optimize MyoMapNet architecture (size and loss functions). We used MyoMapNet to estimate T1 and ECV maps with the first 5 (native) or 4 (post-contrast) T1-weighted images from the corresponding MOLLI sequence compared to the conventional and an abbreviated MOLLI using similar number of T1-weighted images with 3-parameter curve-fitting. Results: In our preliminary optimizaiton step, we determined that a 5-layers NN trained using mean-absolute-error loss yields lower estimation errors and was used subsequently in independent testing study. The myocardial T1 by MyoMapNet was similar to MOLLI (1200$\pm$45ms vs. 1199$\pm$46ms; P=0.3 for native T1, and 27.3$\pm$3.5% vs. 27.1$\pm$4%; P=0.4 for ECV). MyoMapNet had significantly smaller errors in T1 estimations compared to abbreviated-MOLLI (1$\pm$17ms vs. 31$\pm$34ms, P<0.01 for in native T1, and 0.1$\pm$1.3% vs. 1.9$\pm$2.5%, P<0.01 for ECV). The duration of T1 estimation was approximately 2 ms per slice using MyoMapNet. Conclusion: MyoMapNet T1 mapping enables myocardial T1 quantification in 4-5 heartbeats with near-instantaneous map estimation time with similar accuracy and precision as MOLLI. Keywords: Myocardial T1 mapping, MOLLI, T1 reconstruction, Neural network, Deep Learning.
Benchmarking of eight recurrent neural network variants for breath phase and adventitious sound detection on a self-developed open-access lung sound database-HF_Lung_V1
Mar 03, 2021

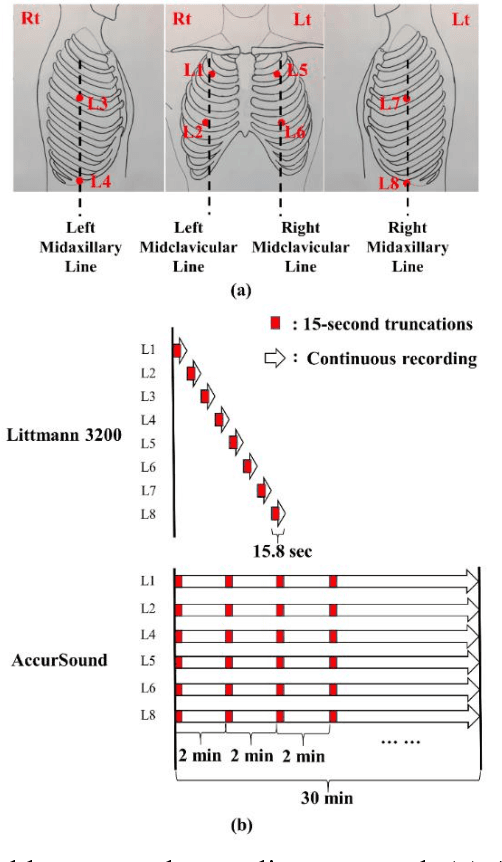
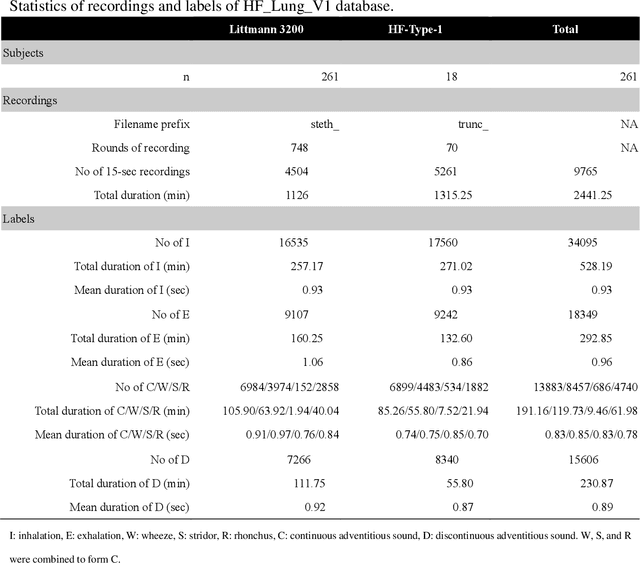
A reliable, remote, and continuous real-time respiratory sound monitor with automated respiratory sound analysis ability is urgently required in many clinical scenarios-such as in monitoring disease progression of coronavirus disease 2019-to replace conventional auscultation with a handheld stethoscope. However, a robust computerized respiratory sound analysis algorithm has not yet been validated in practical applications. In this study, we developed a lung sound database (HF_Lung_V1) comprising 9,765 audio files of lung sounds (duration of 15 s each), 34,095 inhalation labels, 18,349 exhalation labels, 13,883 continuous adventitious sound (CAS) labels (comprising 8,457 wheeze labels, 686 stridor labels, and 4,740 rhonchi labels), and 15,606 discontinuous adventitious sound labels (all crackles). We conducted benchmark tests for long short-term memory (LSTM), gated recurrent unit (GRU), bidirectional LSTM (BiLSTM), bidirectional GRU (BiGRU), convolutional neural network (CNN)-LSTM, CNN-GRU, CNN-BiLSTM, and CNN-BiGRU models for breath phase detection and adventitious sound detection. We also conducted a performance comparison between the LSTM-based and GRU-based models, between unidirectional and bidirectional models, and between models with and without a CNN. The results revealed that these models exhibited adequate performance in lung sound analysis. The GRU-based models outperformed, in terms of F1 scores and areas under the receiver operating characteristic curves, the LSTM-based models in most of the defined tasks. Furthermore, all bidirectional models outperformed their unidirectional counterparts. Finally, the addition of a CNN improved the accuracy of lung sound analysis, especially in the CAS detection tasks.
Deep Reservoir Networks with Learned Hidden Reservoir Weights using Direct Feedback Alignment
Oct 15, 2020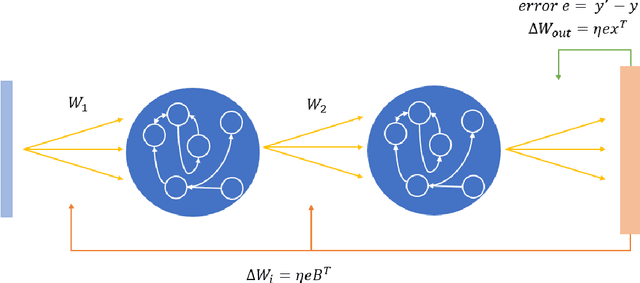

Deep Reservoir Computing has emerged as a new paradigm for deep learning, which is based around the reservoir computing principle of maintaining random pools of neurons combined with hierarchical deep learning. The reservoir paradigm reflects and respects the high degree of recurrence in biological brains, and the role that neuronal dynamics play in learning. However, one issue hampering deep reservoir network development is that one cannot backpropagate through the reservoir layers. Recent deep reservoir architectures do not learn hidden or hierarchical representations in the same manner as deep artificial neural networks, but rather concatenate all hidden reservoirs together to perform traditional regression. Here we present a novel Deep Reservoir Network for time series prediction and classification that learns through the non-differentiable hidden reservoir layers using a biologically-inspired backpropagation alternative called Direct Feedback Alignment, which resembles global dopamine signal broadcasting in the brain. We demonstrate its efficacy on two real world multidimensional time series datasets.
Decision-makers Processing of AI Algorithmic Advice: Automation Bias versus Selective Adherence
Mar 03, 2021
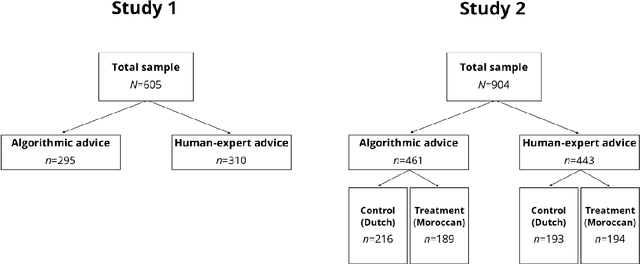
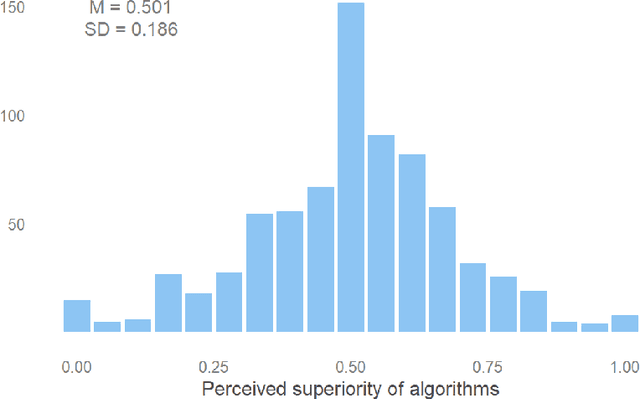
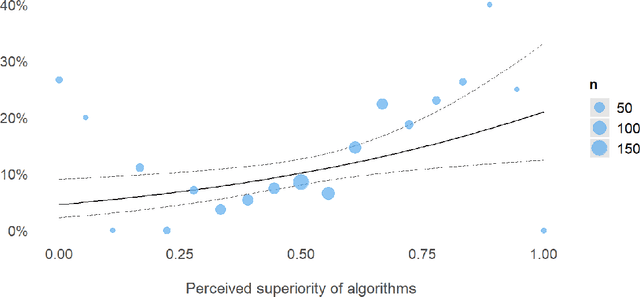
Artificial intelligence algorithms are increasingly adopted as decisional aides by public organisations, with the promise of overcoming biases of human decision-makers. At the same time, the use of algorithms may introduce new biases in the human-algorithm interaction. A key concern emerging from psychology studies regards human overreliance on algorithmic advice even in the face of warning signals and contradictory information from other sources (automation bias). A second concern regards decision-makers inclination to selectively adopt algorithmic advice when it matches their pre-existing beliefs and stereotypes (selective adherence). To date, we lack rigorous empirical evidence about the prevalence of these biases in a public sector context. We assess these via two pre-registered experimental studies (N=1,509), simulating the use of algorithmic advice in decisions pertaining to the employment of school teachers in the Netherlands. In study 1, we test automation bias by exploring participants adherence to a prediction of teachers performance, which contradicts additional evidence, while comparing between two types of predictions: algorithmic v. human-expert. We do not find evidence for automation bias. In study 2, we replicate these findings, and we also test selective adherence by manipulating the teachers ethnic background. We find a propensity for adherence when the advice predicts low performance for a teacher of a negatively stereotyped ethnic minority, with no significant differences between algorithmic and human advice. Overall, our findings of selective, biased adherence belie the promise of neutrality that has propelled algorithm use in the public sector.
Unified Multi-Modal Landmark Tracking for Tightly Coupled Lidar-Visual-Inertial Odometry
Nov 13, 2020
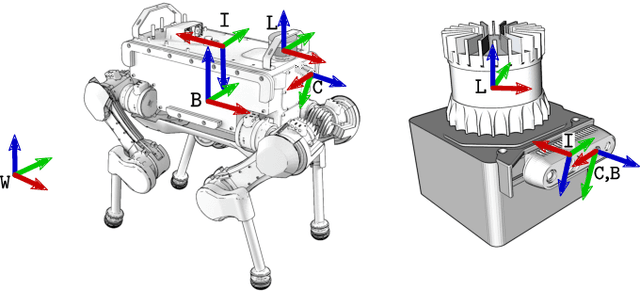
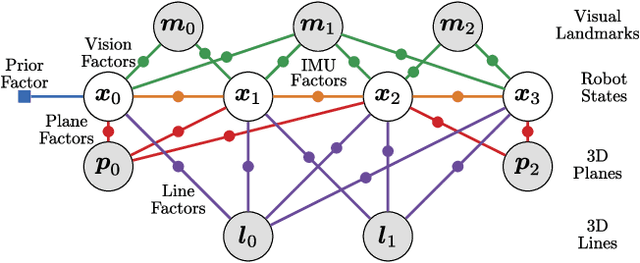
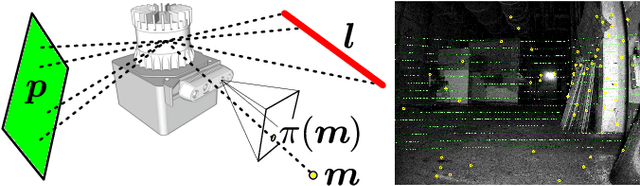
We present an efficient multi-sensor odometry system for mobile platforms that jointly optimizes visual, lidar, and inertial information within a single integrated factor graph. This runs in real-time at full framerate using fixed lag smoothing. To perform such tight integration, a new method to extract 3D line and planar primitives from lidar point clouds is presented. This approach overcomes the suboptimality of typical frame-to-frame tracking methods by treating the primitives as landmarks and tracking them over multiple scans. True integration of lidar features with standard visual features and IMU is made possible using a subtle passive synchronization of lidar and camera frames. The lightweight formulation of the 3D features allows for real-time execution on a single CPU. Our proposed system has been tested on a variety of platforms and scenarios, including underground exploration with a legged robot and outdoor scanning with a dynamically moving handheld device, for a total duration of 96 min and 2.4 km traveled distance. In these test sequences, using only one exteroceptive sensor leads to failure due to either underconstrained geometry (affecting lidar) and textureless areas caused by aggressive lighting changes (affecting vision). In these conditions, our factor graph naturally uses the best information available from each sensor modality without any hard switches.