 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Coreset for Federated Learning
Jan 13, 2024Federated Learning (FL) is used to learn machine learning models with data that is partitioned across multiple clients, including resource-constrained edge devices. It is therefore important to devise solutions that are efficient in terms of compute, communication, and energy consumption, while ensuring compliance with the FL framework's privacy requirements. Conventional approaches to these problems select a weighted subset of the training dataset, known as coreset, and learn by fitting models on it. Such coreset selection approaches are also known to be robust to data noise. However, these approaches rely on the overall statistics of the training data and are not easily extendable to the FL setup. In this paper, we propose an algorithm called Gradient based Coreset for Robust and Efficient Federated Learning (GCFL) that selects a coreset at each client, only every $K$ communication rounds and derives updates only from it, assuming the availability of a small validation dataset at the server. We demonstrate that our coreset selection technique is highly effective in accounting for noise in clients' data. We conduct experiments using four real-world datasets and show that GCFL is (1) more compute and energy efficient than FL, (2) robust to various kinds of noise in both the feature space and labels, (3) preserves the privacy of the validation dataset, and (4) introduces a small communication overhead but achieves significant gains in performance, particularly in cases when the clients' data is noisy.
Using Early Readouts to Mediate Featural Bias in Distillation
Oct 28, 2023Deep networks tend to learn spurious feature-label correlations in real-world supervised learning tasks. This vulnerability is aggravated in distillation, where a student model may have lesser representational capacity than the corresponding teacher model. Often, knowledge of specific spurious correlations is used to reweight instances & rebalance the learning process. We propose a novel early readout mechanism whereby we attempt to predict the label using representations from earlier network layers. We show that these early readouts automatically identify problem instances or groups in the form of confident, incorrect predictions. Leveraging these signals to modulate the distillation loss on an instance level allows us to substantially improve not only group fairness measures across benchmark datasets, but also overall accuracy of the student model. We also provide secondary analyses that bring insight into the role of feature learning in supervision and distillation.
Partitioned Gradient Matching-based Data Subset Selection for Compute-Efficient Robust ASR Training
Oct 30, 2022



Training state-of-the-art ASR systems such as RNN-T often has a high associated financial and environmental cost. Training with a subset of training data could mitigate this problem if the subset selected could achieve on-par performance with training with the entire dataset. Although there are many data subset selection(DSS) algorithms, direct application to the RNN-T is difficult, especially the DSS algorithms that are adaptive and use learning dynamics such as gradients, as RNN-T tend to have gradients with a significantly larger memory footprint. In this paper, we propose Partitioned Gradient Matching (PGM) a novel distributable DSS algorithm, suitable for massive datasets like those used to train RNN-T. Through extensive experiments on Librispeech 100H and Librispeech 960H, we show that PGM achieves between 3x to 6x speedup with only a very small accuracy degradation (under 1% absolute WER difference). In addition, we demonstrate similar results for PGM even in settings where the training data is corrupted with noise.
ALM-KD: Knowledge Distillation with noisy labels via adaptive loss mixing
Feb 07, 2022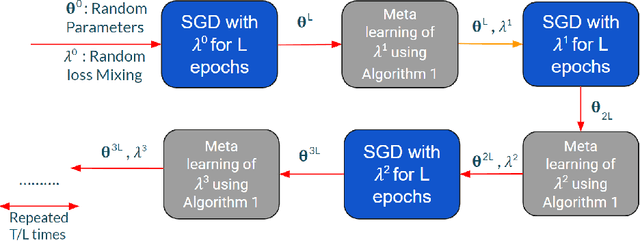
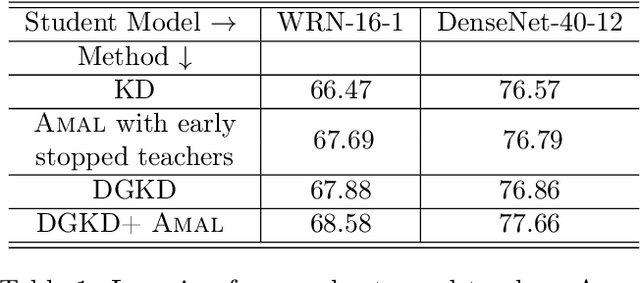
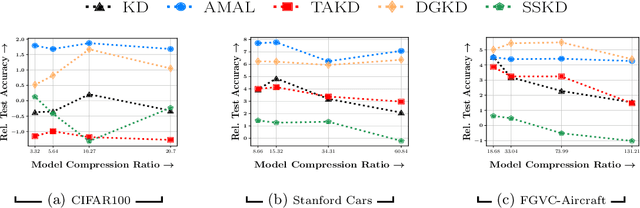
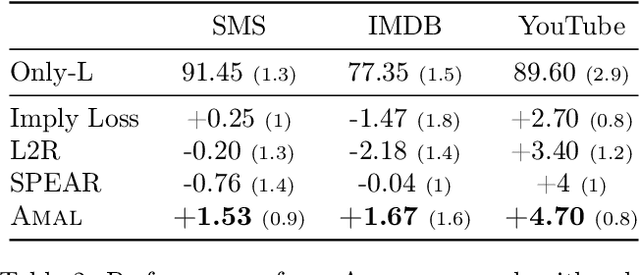
Knowledge distillation is a technique where the outputs of a pretrained model, often known as the teacher model is used for training a student model in a supervised setting. The teacher model outputs being a richer distribution over labels should improve the student model's performance as opposed to training with the usual hard labels. However, the label distribution imposed by the logits of the teacher network may not be always informative and may lead to poor student performance. We tackle this problem via the use of an adaptive loss mixing scheme during KD. Specifically, our method learns an instance-specific convex combination of the teacher-matching and label supervision objectives, using meta learning on a validation metric signalling to the student `how much' of KD is to be used. Through a range of experiments on controlled synthetic data and real-world datasets, we demonstrate performance gains obtained using our approach in the standard KD setting as well as in multi-teacher and self-distillation settings.
Effective Evaluation of Deep Active Learning on Image Classification Tasks
Jun 30, 2021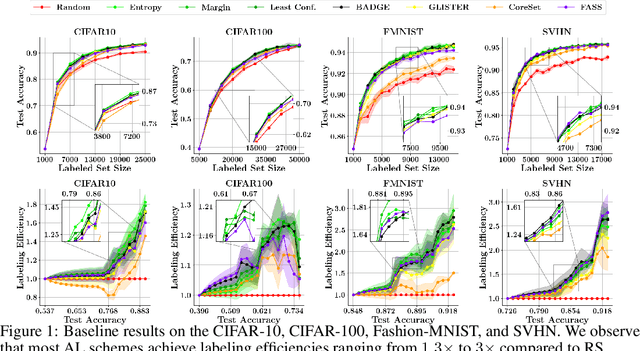
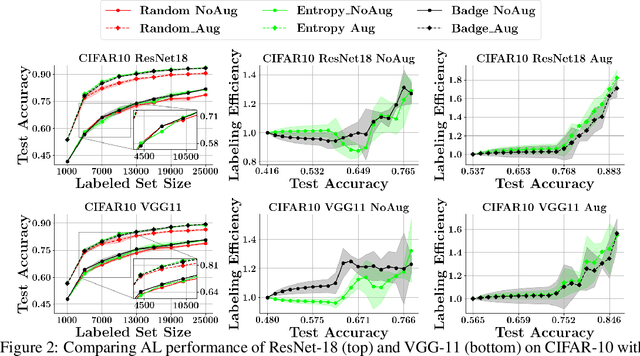
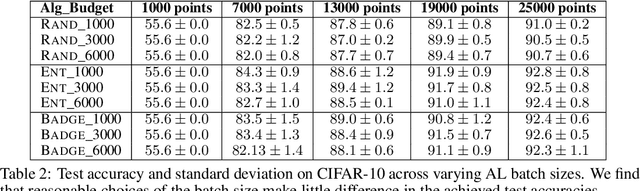
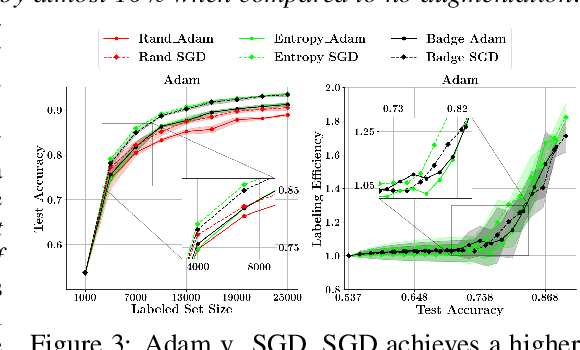
With the goal of making deep learning more label-efficient, a growing number of papers have been studying active learning (AL) for deep models. However, there are a number of issues in the prevalent experimental settings, mainly stemming from a lack of unified implementation and benchmarking. Issues in the current literature include sometimes contradictory observations on the performance of different AL algorithms, unintended exclusion of important generalization approaches such as data augmentation and SGD for optimization, a lack of study of evaluation facets like the labeling efficiency of AL, and little or no clarity on the scenarios in which AL outperforms random sampling (RS). In this work, we present a unified re-implementation of state-of-the-art AL algorithms in the context of image classification, and we carefully study these issues as facets of effective evaluation. On the positive side, we show that AL techniques are 2x to 4x more label-efficient compared to RS with the use of data augmentation. Surprisingly, when data augmentation is included, there is no longer a consistent gain in using BADGE, a state-of-the-art approach, over simple uncertainty sampling. We then do a careful analysis of how existing approaches perform with varying amounts of redundancy and number of examples per class. Finally, we provide several insights for AL practitioners to consider in future work, such as the effect of the AL batch size, the effect of initialization, the importance of retraining a new model at every round, and other insights.
Training Data Subset Selection for Regression with Controlled Generalization Error
Jun 23, 2021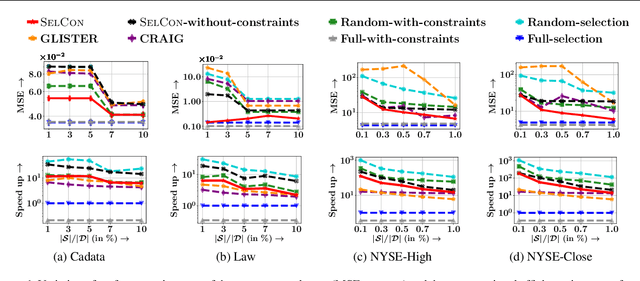
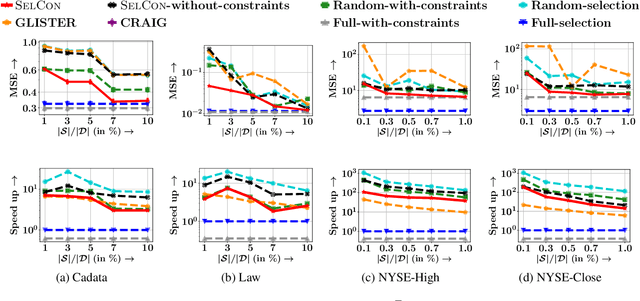
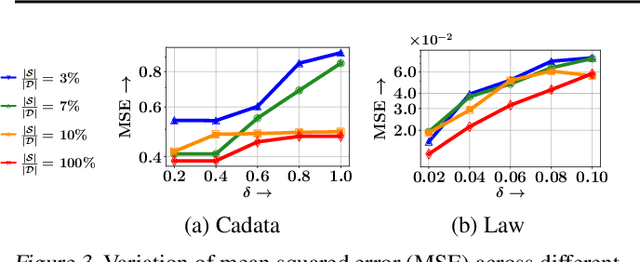
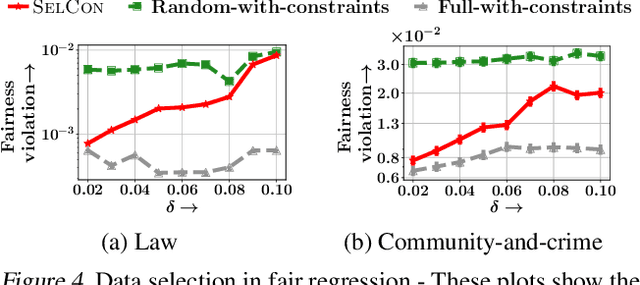
Data subset selection from a large number of training instances has been a successful approach toward efficient and cost-effective machine learning. However, models trained on a smaller subset may show poor generalization ability. In this paper, our goal is to design an algorithm for selecting a subset of the training data, so that the model can be trained quickly, without significantly sacrificing on accuracy. More specifically, we focus on data subset selection for L2 regularized regression problems and provide a novel problem formulation which seeks to minimize the training loss with respect to both the trainable parameters and the subset of training data, subject to error bounds on the validation set. We tackle this problem using several technical innovations. First, we represent this problem with simplified constraints using the dual of the original training problem and show that the objective of this new representation is a monotone and alpha-submodular function, for a wide variety of modeling choices. Such properties lead us to develop SELCON, an efficient majorization-minimization algorithm for data subset selection, that admits an approximation guarantee even when the training provides an imperfect estimate of the trained model. Finally, our experiments on several datasets show that SELCON trades off accuracy and efficiency more effectively than the current state-of-the-art.
GRAD-MATCH: A Gradient Matching Based Data Subset Selection for Efficient Learning
Feb 27, 2021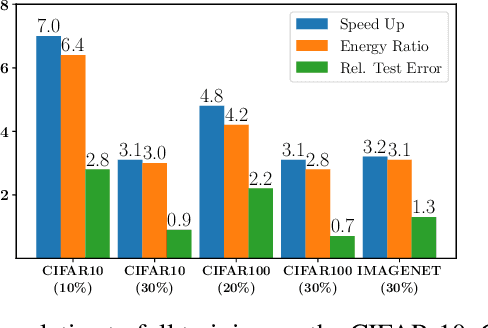
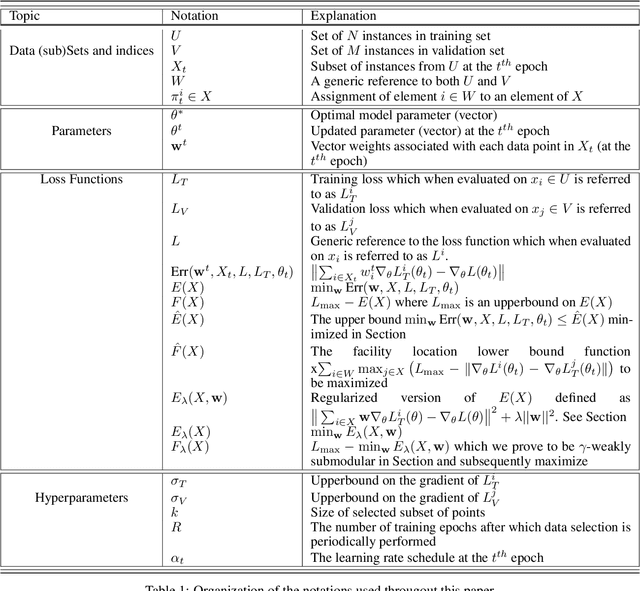

The great success of modern machine learning models on large datasets is contingent on extensive computational resources with high financial and environmental costs. One way to address this is by extracting subsets that generalize on par with the full data. In this work, we propose a general framework, GRAD-MATCH, which finds subsets that closely match the gradient of the training or validation set. We find such subsets effectively using an orthogonal matching pursuit algorithm. We show rigorous theoretical and convergence guarantees of the proposed algorithm and, through our extensive experiments on real-world datasets, show the effectiveness of our proposed framework. We show that GRAD-MATCH significantly and consistently outperforms several recent data-selection algorithms and is Pareto-optimal with respect to the accuracy-efficiency trade-off. The code of GRADMATCH is available as a part of the CORDS toolkit: https://github.com/decile-team/cords.
GLISTER: Generalization based Data Subset Selection for Efficient and Robust Learning
Jan 15, 2021

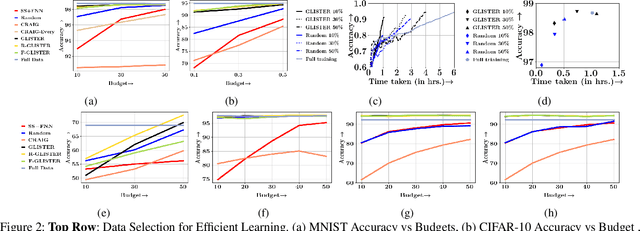
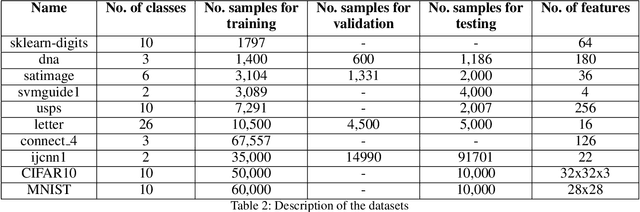
Large scale machine learning and deep models are extremely data-hungry. Unfortunately, obtaining large amounts of labeled data is expensive, and training state-of-the-art models (with hyperparameter tuning) requires significant computing resources and time. Secondly, real-world data is noisy and imbalanced. As a result, several recent papers try to make the training process more efficient and robust. However, most existing work either focuses on robustness or efficiency, but not both. In this work, we introduce Glister, a GeneraLIzation based data Subset selecTion for Efficient and Robust learning framework. We formulate Glister as a mixed discrete-continuous bi-level optimization problem to select a subset of the training data, which maximizes the log-likelihood on a held-out validation set. Next, we propose an iterative online algorithm Glister-Online, which performs data selection iteratively along with the parameter updates and can be applied to any loss-based learning algorithm. We then show that for a rich class of loss functions including cross-entropy, hinge-loss, squared-loss, and logistic-loss, the inner discrete data selection is an instance of (weakly) submodular optimization, and we analyze conditions for which Glister-Online reduces the validation loss and converges. Finally, we propose Glister-Active, an extension to batch active learning, and we empirically demonstrate the performance of Glister on a wide range of tasks including, (a) data selection to reduce training time, (b) robust learning under label noise and imbalance settings, and (c) batch-active learning with several deep and shallow models. We show that our framework improves upon state of the art both in efficiency and accuracy (in cases (a) and (c)) and is more efficient compared to other state-of-the-art robust learning algorithms in case (b).