 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Non-Linear Phase-Shifting of Haar Wavelets for Run-Time All-Frequency Lighting
May 20, 2017
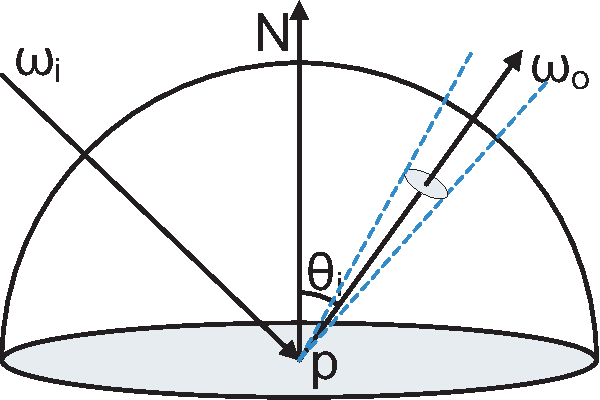
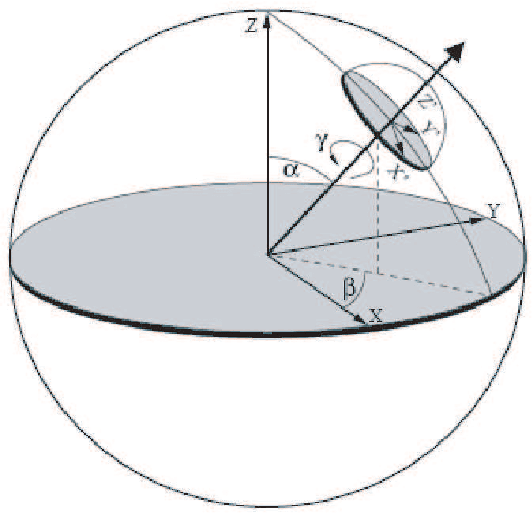

This paper focuses on real-time all-frequency image-based rendering using an innovative solution for run-time computation of light transport. The approach is based on new results derived for non-linear phase shifting in the Haar wavelet domain. Although image-based methods for real-time rendering of dynamic glossy objects have been proposed, they do not truly scale to all possible frequencies and high sampling rates without trading storage, glossiness, or computational time, while varying both lighting and viewpoint. This is due to the fact that current approaches are limited to precomputed radiance transfer (PRT), which is prohibitively expensive in terms of memory requirements and real-time rendering when both varying light and viewpoint changes are required together with high sampling rates for high frequency lighting of glossy material. On the other hand, current methods cannot handle object rotation, which is one of the paramount issues for all PRT methods using wavelets. This latter problem arises because the precomputed data are defined in a global coordinate system and encoded in the wavelet domain, while the object is rotated in a local coordinate system. At the root of all the above problems is the lack of efficient run-time solution to the nontrivial problem of rotating wavelets (a non-linear phase-shift), which we solve in this paper.
Improved algorithms for online load balancing
Jul 21, 2020We consider an online load balancing problem and its extensions in the framework of repeated games. On each round, the player chooses a distribution (task allocation) over $K$ servers, and then the environment reveals the load of each server, which determines the computation time of each server for processing the task assigned. After all rounds, the cost of the player is measured by some norm of the cumulative computation-time vector. The cost is the makespan if the norm is $L_\infty$-norm. The goal is to minimize the regret, i.e., minimizing the player's cost relative to the cost of the best fixed distribution in hindsight. We propose algorithms for general norms and prove their regret bounds. In particular, for $L_\infty$-norm, our regret bound matches the best known bound and the proposed algorithm runs in polynomial time per trial involving linear programming and second order programming, whereas no polynomial time algorithm was previously known to achieve the bound.
Detection of Binary Square Fiducial Markers Using an Event Camera
Jan 19, 2021


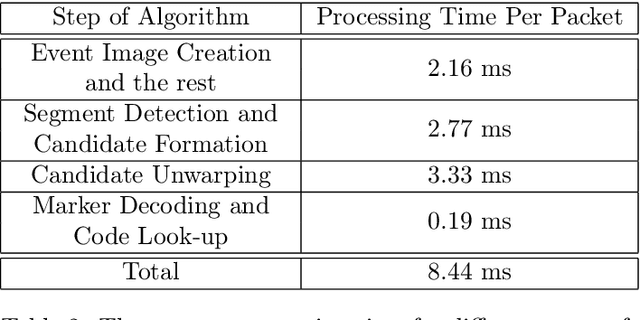
Event cameras are a new type of image sensors that output changes in light intensity (events) instead of absolute intensity values. They have a very high temporal resolution and a high dynamic range. In this paper, we propose a method to detect and decode binary square markers using an event camera. We detect the edges of the markers by detecting line segments in an image created from events in the current packet. The line segments are combined to form marker candidates. The bit value of marker cells is decoded using the events on their borders. To the best of our knowledge, no other approach exists for detecting square binary markers directly from an event camera. Experimental results show that the performance of our proposal is much superior to the one from the RGB ArUco marker detector. Additionally, the proposed method can run on a single CPU thread in real-time.
Constrained optimization under uncertainty for decision-making problems: Application to Real-Time Strategy games
Jan 07, 2019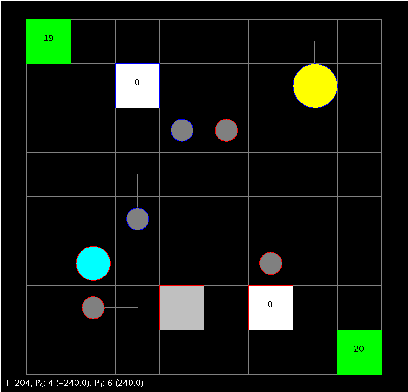
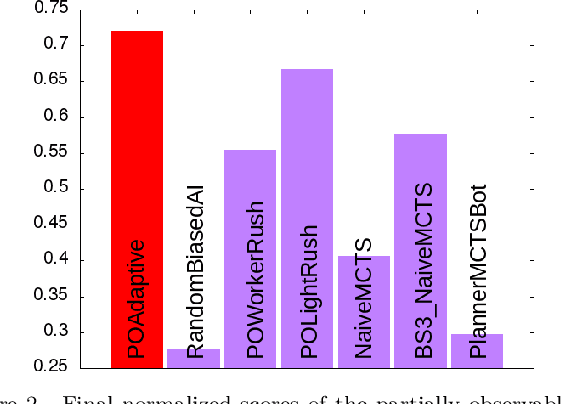
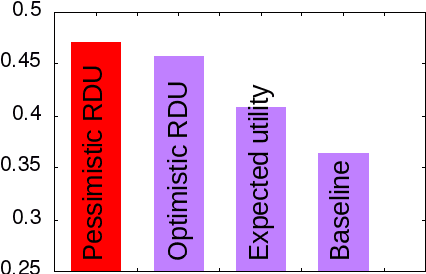
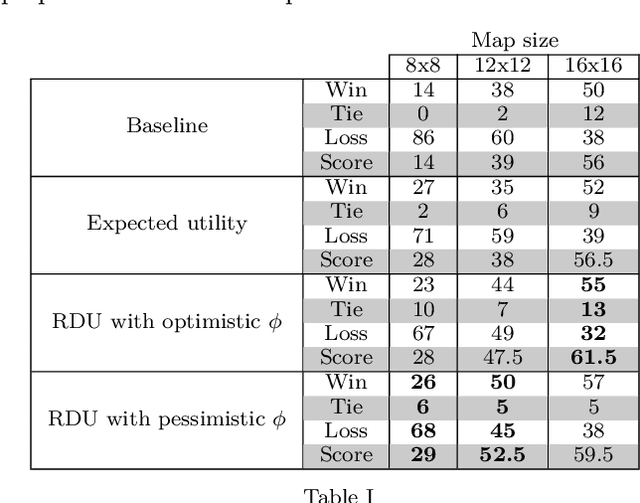
Decision-making problems can be modeled as combinatorial optimization problems with Constraint Programming formalisms such as Constrained Optimization Problems. However, few Constraint Programming formalisms can deal with both optimization and uncertainty at the same time, and none of them are convenient to model problems we tackle in this paper. Here, we propose a way to deal with combinatorial optimization problems under uncertainty within the classical Constrained Optimization Problems formalism by injecting the Rank Dependent Utility from decision theory. We also propose a proof of concept of our method to show it is implementable and can solve concrete decision-making problems using a regular constraint solver, and propose a bot that won the partially observable track of the 2018 {\mu}RTS AI competition. Our result shows it is possible to handle uncertainty with regular Constraint Programming solvers, without having to define a new formalism neither to develop dedicated solvers. This brings new perspective to tackle uncertainty in Constraint Programming.
Knowledge Grounded Conversational Symptom Detection with Graph Memory Networks
Jan 24, 2021

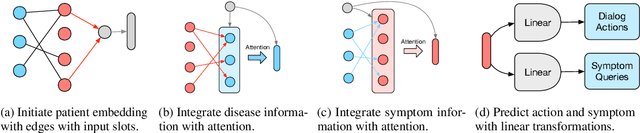
In this work, we propose a novel goal-oriented dialog task, automatic symptom detection. We build a system that can interact with patients through dialog to detect and collect clinical symptoms automatically, which can save a doctor's time interviewing the patient. Given a set of explicit symptoms provided by the patient to initiate a dialog for diagnosing, the system is trained to collect implicit symptoms by asking questions, in order to collect more information for making an accurate diagnosis. After getting the reply from the patient for each question, the system also decides whether current information is enough for a human doctor to make a diagnosis. To achieve this goal, we propose two neural models and a training pipeline for the multi-step reasoning task. We also build a knowledge graph as additional inputs to further improve model performance. Experiments show that our model significantly outperforms the baseline by 4%, discovering 67% of implicit symptoms on average with a limited number of questions.
GO-Finder: A Registration-Free Wearable System for Assisting Users in Finding Lost Objects via Hand-Held Object Discovery
Feb 12, 2021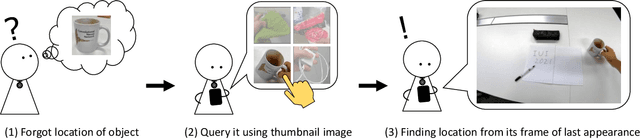
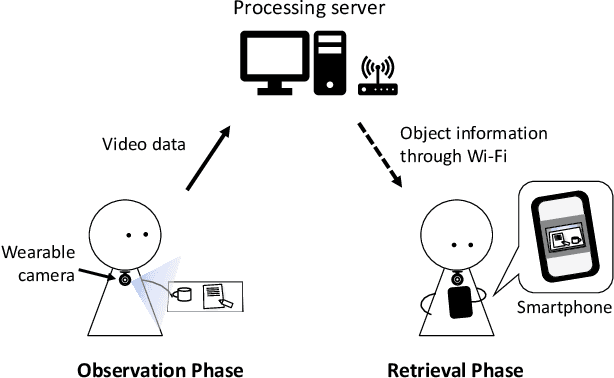
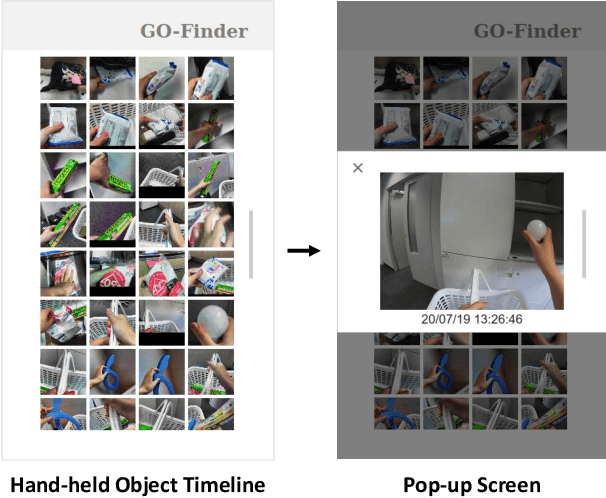
People spend an enormous amount of time and effort looking for lost objects. To help remind people of the location of lost objects, various computational systems that provide information on their locations have been developed. However, prior systems for assisting people in finding objects require users to register the target objects in advance. This requirement imposes a cumbersome burden on the users, and the system cannot help remind them of unexpectedly lost objects. We propose GO-Finder ("Generic Object Finder"), a registration-free wearable camera based system for assisting people in finding an arbitrary number of objects based on two key features: automatic discovery of hand-held objects and image-based candidate selection. Given a video taken from a wearable camera, Go-Finder automatically detects and groups hand-held objects to form a visual timeline of the objects. Users can retrieve the last appearance of the object by browsing the timeline through a smartphone app. We conducted a user study to investigate how users benefit from using GO-Finder and confirmed improved accuracy and reduced mental load regarding the object search task by providing clear visual cues on object locations.
Improving Transformation Invariance in Contrastive Representation Learning
Oct 19, 2020
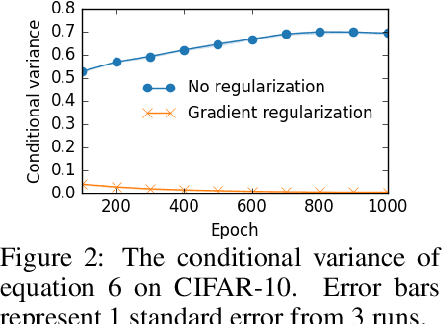
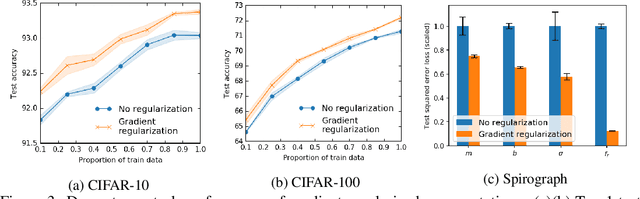

We propose methods to strengthen the invariance properties of representations obtained by contrastive learning. While existing approaches implicitly induce a degree of invariance as representations are learned, we look to more directly enforce invariance in the encoding process. To this end, we first introduce a training objective for contrastive learning that uses a novel regularizer to control how the representation changes under transformation. We show that representations trained with this objective perform better on downstream tasks and are more robust to the introduction of nuisance transformations at test time. Second, we propose a change to how test time representations are generated by introducing a feature averaging approach that combines encodings from multiple transformations of the original input, finding that this leads to across the board performance gains. Finally, we introduce the novel Spirograph dataset to explore our ideas in the context of a differentiable generative process with multiple downstream tasks, showing that our techniques for learning invariance are highly beneficial.
RomeBERT: Robust Training of Multi-Exit BERT
Jan 24, 2021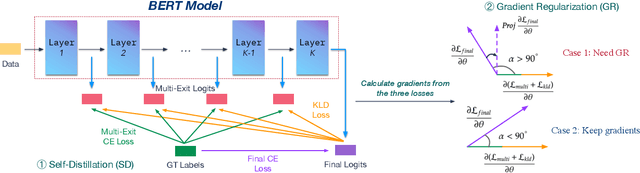
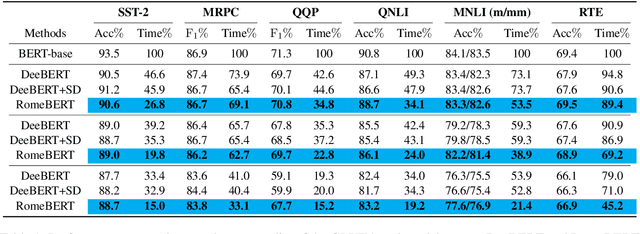
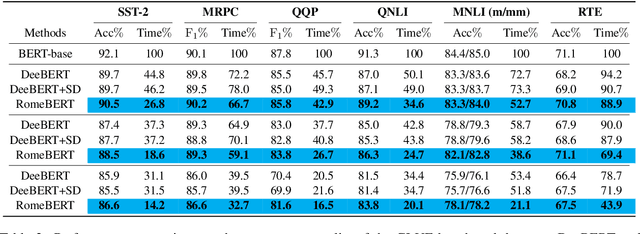
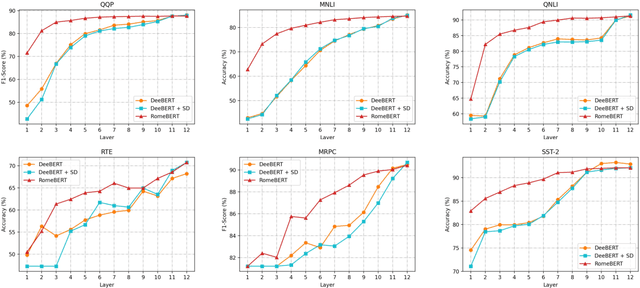
BERT has achieved superior performances on Natural Language Understanding (NLU) tasks. However, BERT possesses a large number of parameters and demands certain resources to deploy. For acceleration, Dynamic Early Exiting for BERT (DeeBERT) has been proposed recently, which incorporates multiple exits and adopts a dynamic early-exit mechanism to ensure efficient inference. While obtaining an efficiency-performance tradeoff, the performances of early exits in multi-exit BERT are significantly worse than late exits. In this paper, we leverage gradient regularized self-distillation for RObust training of Multi-Exit BERT (RomeBERT), which can effectively solve the performance imbalance problem between early and late exits. Moreover, the proposed RomeBERT adopts a one-stage joint training strategy for multi-exits and the BERT backbone while DeeBERT needs two stages that require more training time. Extensive experiments on GLUE datasets are performed to demonstrate the superiority of our approach. Our code is available at https://github.com/romebert/RomeBERT.
Unsupervised Features for Facial Expression Intensity Estimation over Time
May 03, 2018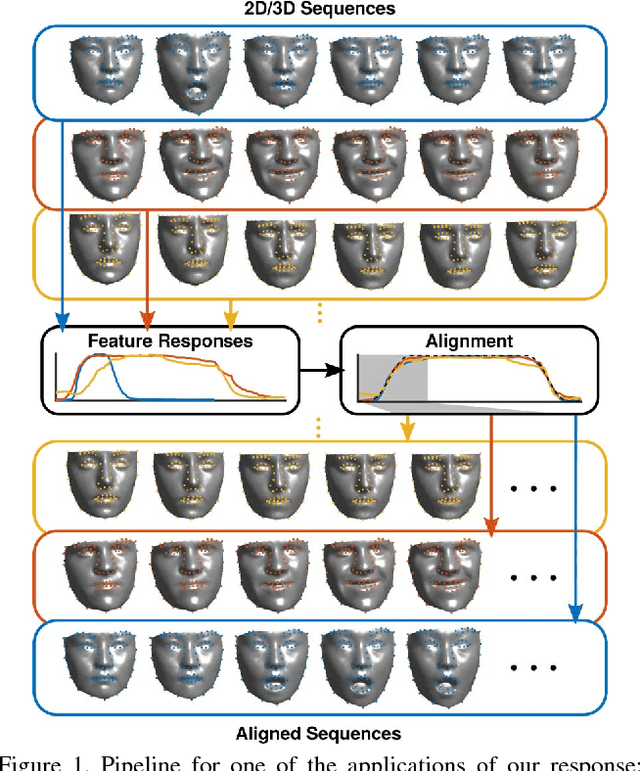
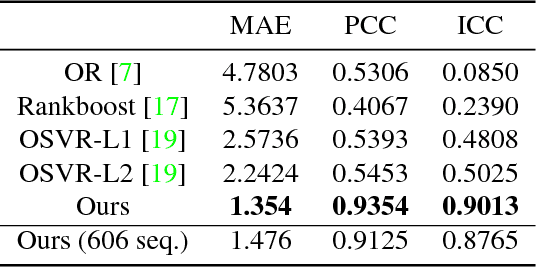
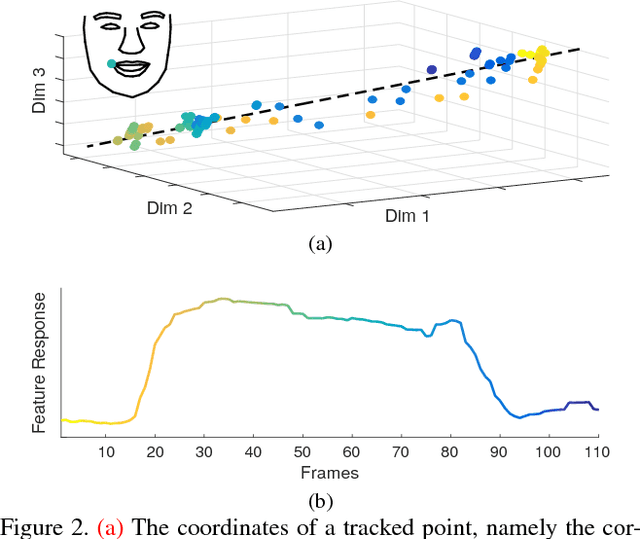
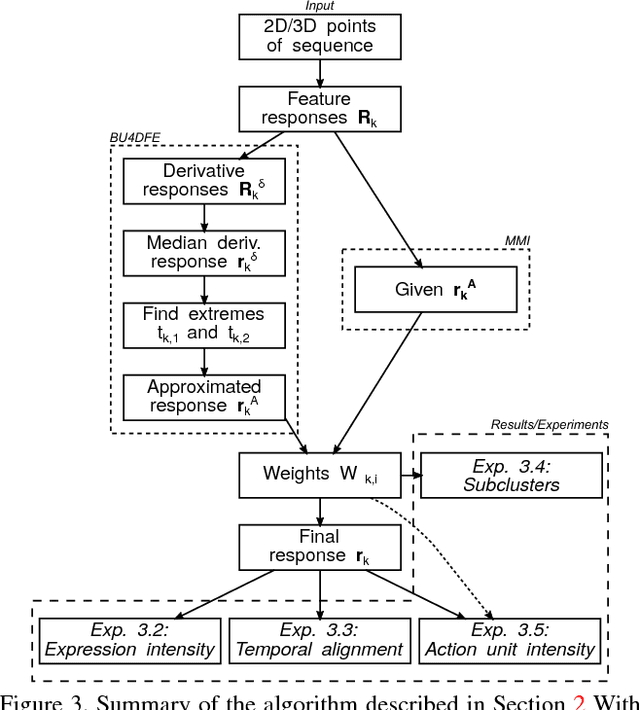
The diversity of facial shapes and motions among persons is one of the greatest challenges for automatic analysis of facial expressions. In this paper, we propose a feature describing expression intensity over time, while being invariant to person and the type of performed expression. Our feature is a weighted combination of the dynamics of multiple points adapted to the overall expression trajectory. We evaluate our method on several tasks all related to temporal analysis of facial expression. The proposed feature is compared to a state-of-the-art method for expression intensity estimation, which it outperforms. We use our proposed feature to temporally align multiple sequences of recorded 3D facial expressions. Furthermore, we show how our feature can be used to reveal person-specific differences in performances of facial expressions. Additionally, we apply our feature to identify the local changes in face video sequences based on action unit labels. For all the experiments our feature proves to be robust against noise and outliers, making it applicable to a variety of applications for analysis of facial movements.
A Spiking Neural Network (SNN) for detecting High Frequency Oscillations (HFOs) in the intraoperative ECoG
Nov 17, 2020
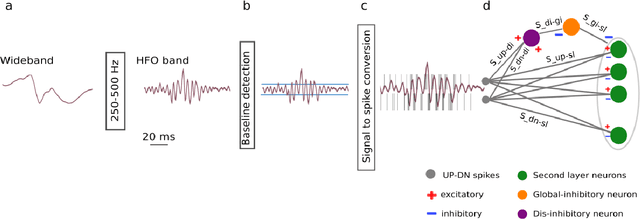
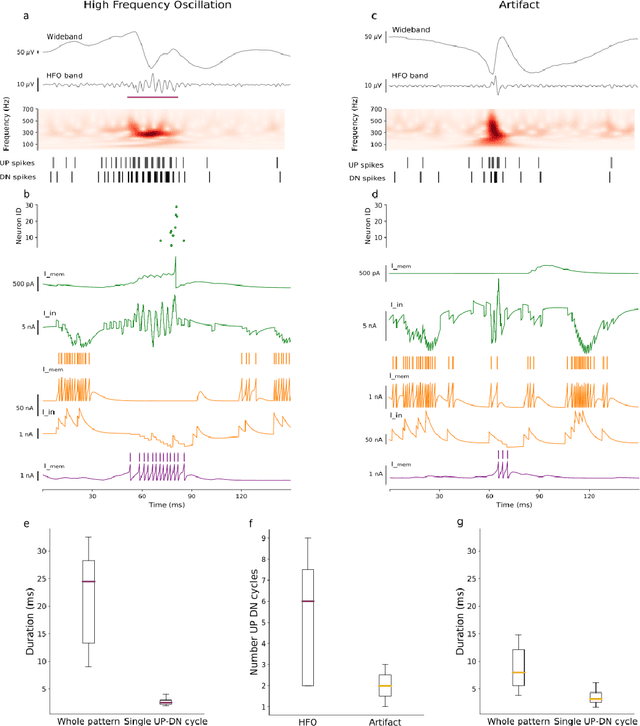
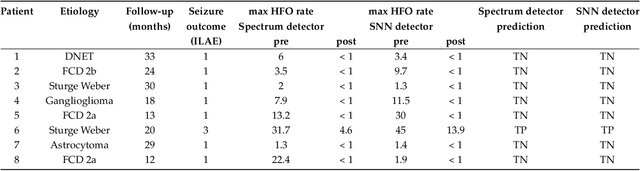
To achieve seizure freedom, epilepsy surgery requires the complete resection of the epileptogenic brain tissue. In intraoperative ECoG recordings, high frequency oscillations (HFOs) generated by epileptogenic tissue can be used to tailor the resection margin. However, automatic detection of HFOs in real-time remains an open challenge. Here we present a spiking neural network (SNN) for automatic HFO detection that is optimally suited for neuromorphic hardware implementation. We trained the SNN to detect HFO signals measured from intraoperative ECoG on-line, using an independently labeled dataset. We targeted the detection of HFOs in the fast ripple frequency range (250-500 Hz) and compared the network results with the labeled HFO data. We endowed the SNN with a novel artifact rejection mechanism to suppress sharp transients and demonstrate its effectiveness on the ECoG dataset. The HFO rates (median 6.6 HFO/min in pre-resection recordings) detected by this SNN are comparable to those published in the dataset (58 min, 16 recordings). The postsurgical seizure outcome was "predicted" with 100% accuracy for all 8 patients. These results provide a further step towards the construction of a real-time portable battery-operated HFO detection system that can be used during epilepsy surgery to guide the resection of the epileptogenic zone.