 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRomeBERT: Robust Training of Multi-Exit BERT
Paper and Code
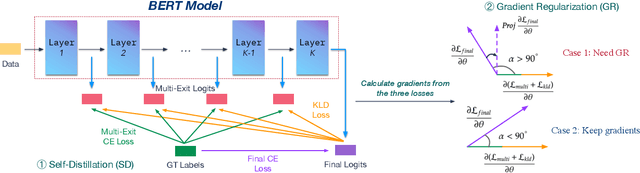
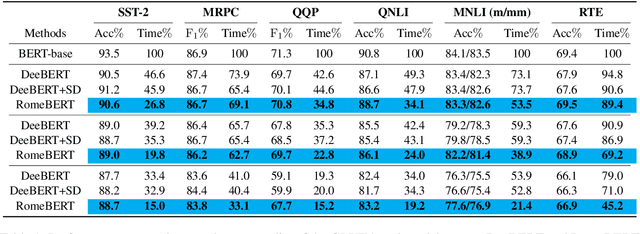
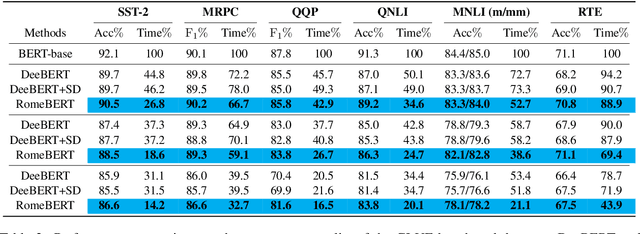
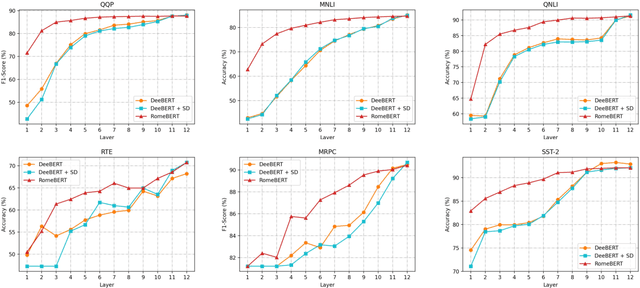
BERT has achieved superior performances on Natural Language Understanding (NLU) tasks. However, BERT possesses a large number of parameters and demands certain resources to deploy. For acceleration, Dynamic Early Exiting for BERT (DeeBERT) has been proposed recently, which incorporates multiple exits and adopts a dynamic early-exit mechanism to ensure efficient inference. While obtaining an efficiency-performance tradeoff, the performances of early exits in multi-exit BERT are significantly worse than late exits. In this paper, we leverage gradient regularized self-distillation for RObust training of Multi-Exit BERT (RomeBERT), which can effectively solve the performance imbalance problem between early and late exits. Moreover, the proposed RomeBERT adopts a one-stage joint training strategy for multi-exits and the BERT backbone while DeeBERT needs two stages that require more training time. Extensive experiments on GLUE datasets are performed to demonstrate the superiority of our approach. Our code is available at https://github.com/romebert/RomeBERT.