 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Are We Ready for Unmanned Surface Vehicles in Inland Waterways? The USVInland Multisensor Dataset and Benchmark
Mar 09, 2021



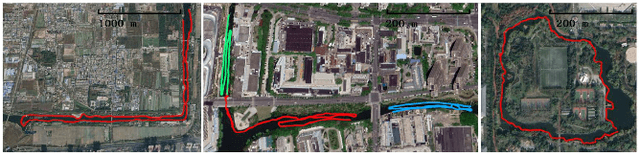
Unmanned surface vehicles (USVs) have great value with their ability to execute hazardous and time-consuming missions over water surfaces. Recently, USVs for inland waterways have attracted increasing attention for their potential application in autonomous monitoring, transportation, and cleaning. However, unlike sailing in open water, the challenges posed by scenes of inland waterways, such as the complex distribution of obstacles, the global positioning system (GPS) signal denial environment, the reflection of bank-side structures, and the fog over the water surface, all impede USV application in inland waterways. To address these problems and stimulate relevant research, we introduce USVInland, a multisensor dataset for USVs in inland waterways. The collection of USVInland spans a trajectory of more than 26 km in diverse real-world scenes of inland waterways using various modalities, including lidar, stereo cameras, millimeter-wave radar, GPS, and inertial measurement units (IMUs). Based on the requirements and challenges in the perception and navigation of USVs for inland waterways, we build benchmarks for simultaneous localization and mapping (SLAM), stereo matching, and water segmentation. We evaluate common algorithms for the above tasks to determine the influence of unique inland waterway scenes on algorithm performance. Our dataset and the development tools are available online at https://www.orca-tech.cn/datasets.html.
An Evaluation of Edge TPU Accelerators for Convolutional Neural Networks
Feb 20, 2021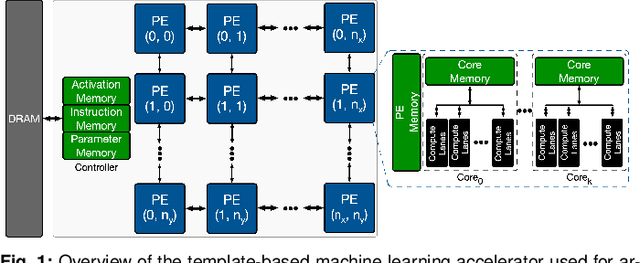
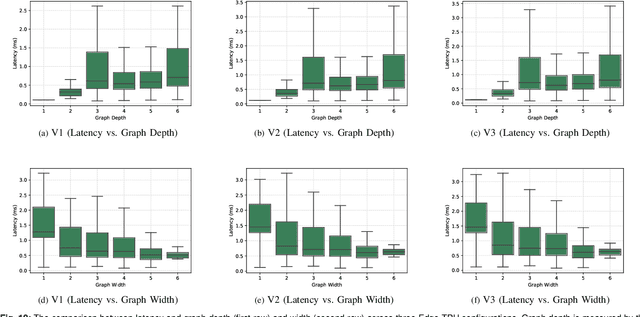
Edge TPUs are a domain of accelerators for low-power, edge devices and are widely used in various Google products such as Coral and Pixel devices. In this paper, we first discuss the major microarchitectural details of Edge TPUs. Then, we extensively evaluate three classes of Edge TPUs, covering different computing ecosystems, that are either currently deployed in Google products or are the product pipeline, across 423K unique convolutional neural networks. Building upon this extensive study, we discuss critical and interpretable microarchitectural insights about the studied classes of Edge TPUs. Mainly, we discuss how Edge TPU accelerators perform across convolutional neural networks with different structures. Finally, we present our ongoing efforts in developing high-accuracy learned machine learning models to estimate the major performance metrics of accelerators such as latency and energy consumption. These learned models enable significantly faster (in the order of milliseconds) evaluations of accelerators as an alternative to time-consuming cycle-accurate simulators and establish an exciting opportunity for rapid hard-ware/software co-design.
Searching a Raw Video Database using Natural Language Queries
Dec 31, 2020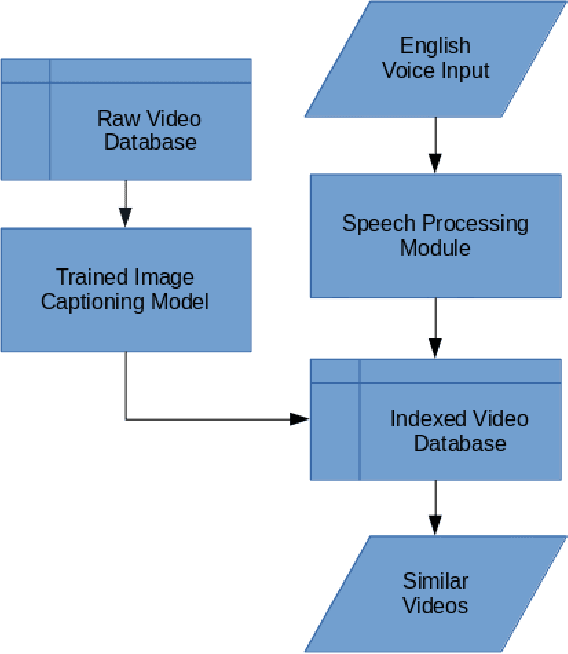


The number of videos being produced and consequently stored in databases for video streaming platforms has been increasing exponentially over time. This vast database should be easily index-able to find the requisite clip or video to match the given search specification, preferably in the form of a textual query. This work aims to provide an end-to-end pipeline to search a video database with a voice query from the end user. The pipeline makes use of Recurrent Neural Networks in combination with Convolutional Neural Networks to generate captions of the video clips present in the database.
NUBOT: Embedded Knowledge Graph With RASA Framework for Generating Semantic Intents Responses in Roman Urdu
Feb 20, 2021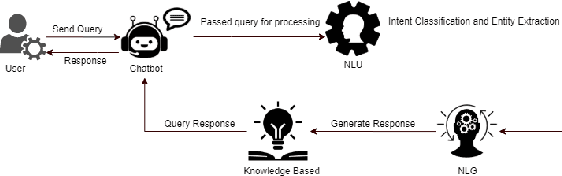
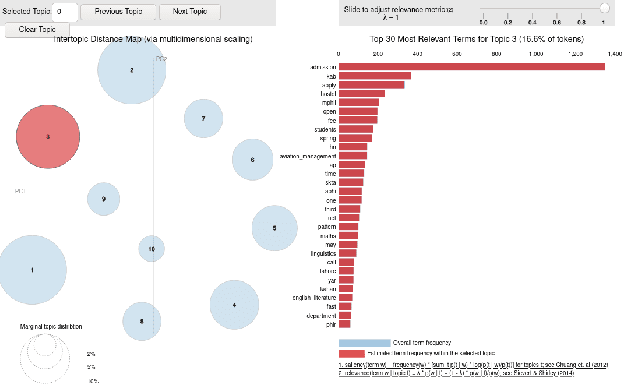
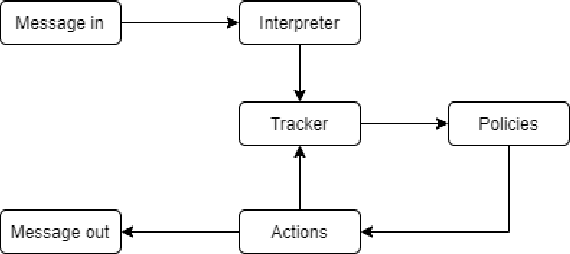
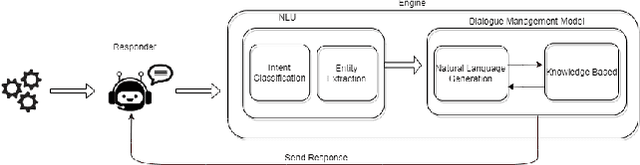
The understanding of the human language is quantified by identifying intents and entities. Even though classification methods that rely on labeled information are often used for the comprehension of language understanding, it is incredibly time consuming and tedious process to generate high propensity supervised datasets. In this paper, we present the generation of accurate intents for the corresponding Roman Urdu unstructured data and integrate this corpus in RASA NLU module for intent classification. We embed knowledge graph with RASA Framework to maintain the dialog history for semantic based natural language mechanism for chatbot communication. We compare results of our work with existing linguistic systems combined with semantic technologies. Minimum accuracy of intents generation is 64 percent of confidence and in the response generation part minimum accuracy is 82.1 percent and maximum accuracy gain is 96.7 percent. All the scores refers to log precision, recall, and f1 measure for each intents once summarized for all. Furthermore, it creates a confusion matrix represents that which intents are ambiguously recognized by approach.
Fast threshold optimization for multi-label audio tagging using Surrogate gradient learning
Mar 01, 2021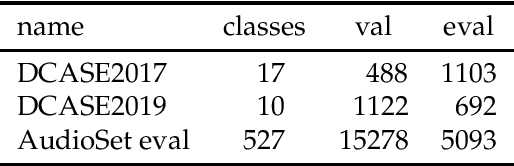
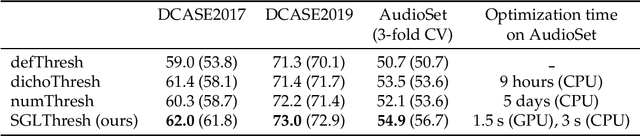
Multi-label audio tagging consists of assigning sets of tags to audio recordings. At inference time, thresholds are applied on the confidence scores outputted by a probabilistic classifier, in order to decide which classes are detected active. In this work, we consider having at disposal a trained classifier and we seek to automatically optimize the decision thresholds according to a performance metric of interest, in our case F-measure (micro-F1). We propose a new method, called SGL-Thresh for Surrogate Gradient Learning of Thresholds, that makes use of gradient descent. Since F1 is not differentiable, we propose to approximate the thresholding operation gradients with the gradients of a sigmoid function. We report experiments on three datasets, using state-of-the-art pre-trained deep neural networks. In all cases, SGL-Thresh outperformed three other approaches: a default threshold value (defThresh), an heuristic search algorithm and a method estimating F1 gradients numerically. It reached 54.9\% F1 on AudioSet eval, compared to 50.7% with defThresh. SGL-Thresh is very fast and scalable to a large number of tags. To facilitate reproducibility, data and source code in Pytorch are available online: https://github.com/topel/SGL-Thresh
A 3D model-based approach for fitting masks to faces in the wild
Mar 01, 2021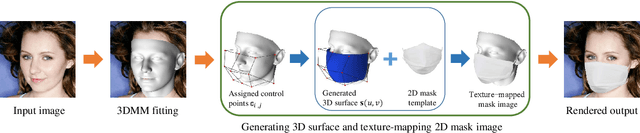
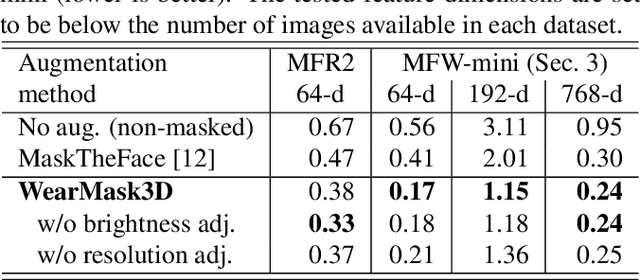

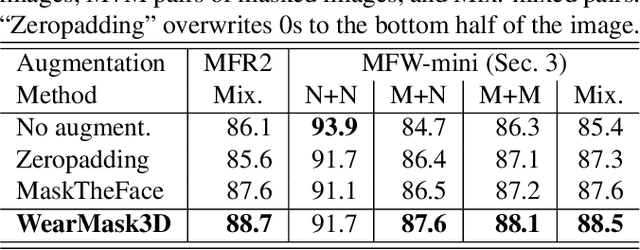
Face recognition research now requires a large number of labelled masked face images in the era of this unprecedented COVID-19 pandemic. Unfortunately, the rapid spread of the virus has left us little time to prepare for such dataset in the wild. To circumvent this issue, we present a 3D model-based approach called WearMask3D for augmenting face images of various poses to the masked face counterparts. Our method proceeds by first fitting a 3D morphable model on the input image, second overlaying the mask surface onto the face model and warping the respective mask texture, and last projecting the 3D mask back to 2D. The mask texture is adapted based on the brightness and resolution of the input image. By working in 3D, our method can produce more natural masked faces of diverse poses from a single mask texture. To compare precisely between different augmentation approaches, we have constructed a dataset comprising masked and unmasked faces with labels called MFW-mini. Experimental results demonstrate WearMask3D, which will be made publicly available, produces more realistic masked images, and utilizing these images for training leads to improved recognition accuracy of masked faces compared to the state-of-the-art.
A Survey On (Stochastic Fractal Search) Algorithm
Jan 25, 2021
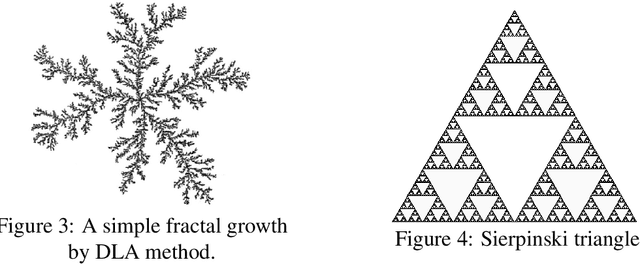
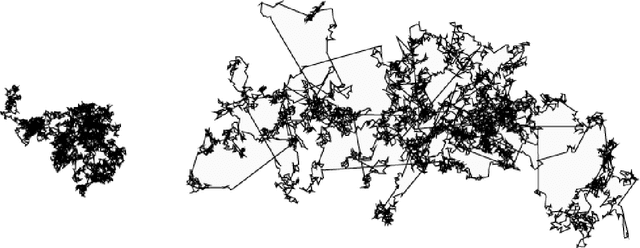
Evolutionary Algorithms are naturally inspired approximation optimisation algorithms that usually interfere with science problems when common mathematical methods are unable to provide a good solution or finding the exact solution requires an unreasonable amount of time using traditional exhaustive search algorithms. The success of these population-based frameworks is mainly due to their flexibility and ease of adaptation to the most different and complex optimisation problems. This paper presents a metaheuristic algorithm called Stochastic Fractal Search, inspired by the natural phenomenon of growth based on a mathematical concept called the fractal, which is shown to be able to explore the search space more efficiently. This paper also focuses on the algorithm steps and some example applications of engineering design optimisation problems commonly used in the literature being applied to the proposed algorithm.
Predicting Parkinson's Disease with Multimodal Irregularly Collected Longitudinal Smartphone Data
Sep 25, 2020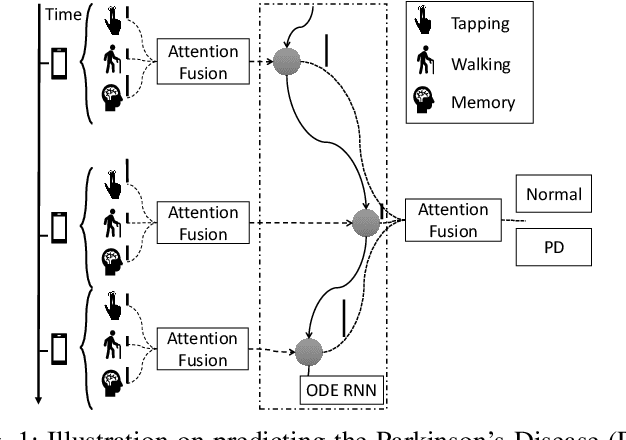
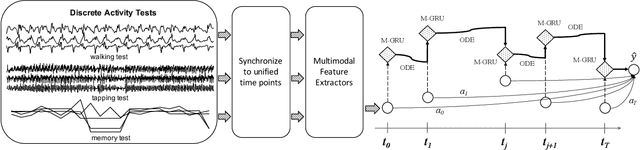
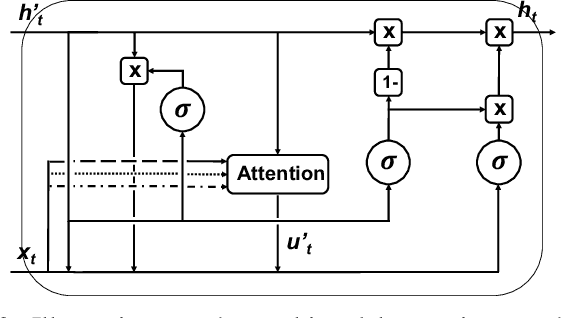
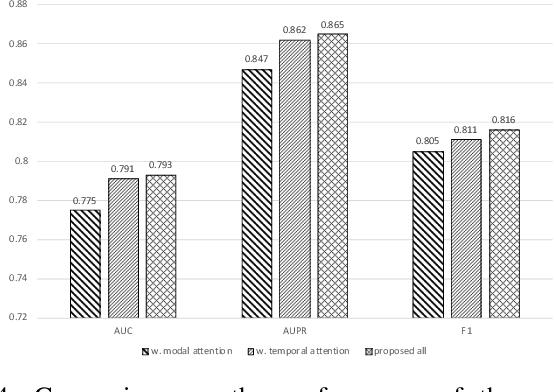
Parkinsons Disease is a neurological disorder and prevalent in elderly people. Traditional ways to diagnose the disease rely on in-person subjective clinical evaluations on the quality of a set of activity tests. The high-resolution longitudinal activity data collected by smartphone applications nowadays make it possible to conduct remote and convenient health assessment. However, out-of-lab tests often suffer from poor quality controls as well as irregularly collected observations, leading to noisy test results. To address these issues, we propose a novel time-series based approach to predicting Parkinson's Disease with raw activity test data collected by smartphones in the wild. The proposed method first synchronizes discrete activity tests into multimodal features at unified time points. Next, it distills and enriches local and global representations from noisy data across modalities and temporal observations by two attention modules. With the proposed mechanisms, our model is capable of handling noisy observations and at the same time extracting refined temporal features for improved prediction performance. Quantitative and qualitative results on a large public dataset demonstrate the effectiveness of the proposed approach.
STOPPAGE: Spatio-temporal Data Driven Cloud-Fog-Edge Computing Framework for Pandemic Monitoring and Management
Apr 04, 2021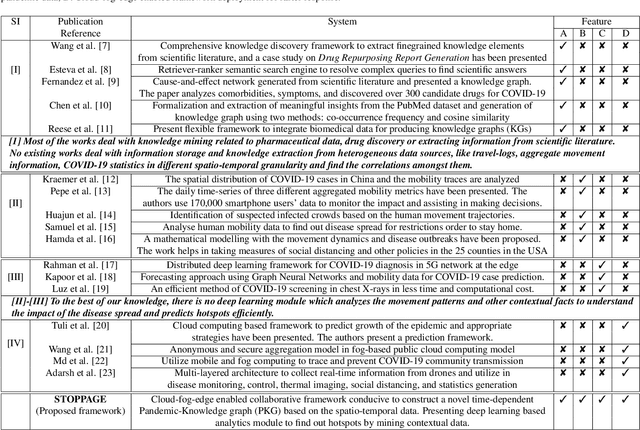
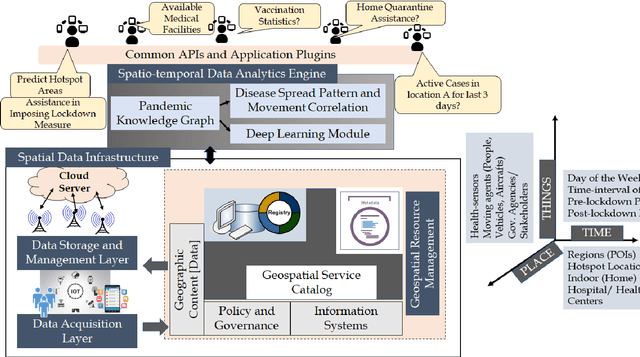
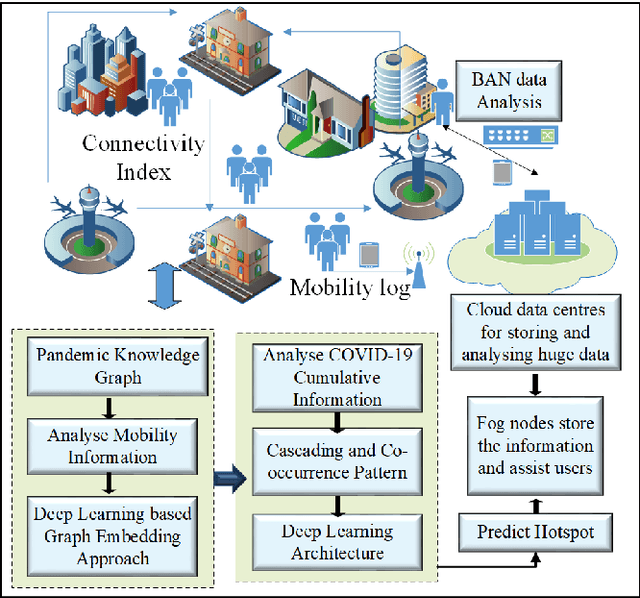
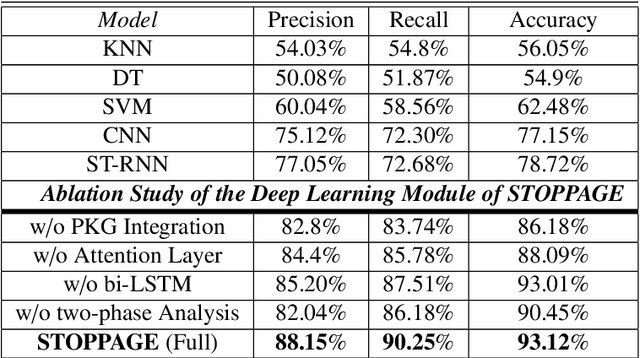
Several researches and evidence show the increasing likelihood of pandemics (large-scale outbreaks of infectious disease) which has far reaching sequels in all aspects of human lives ranging from rapid mortality rates to economic and social disruption across the world. In the recent time, COVID-19 (Coronavirus Disease 2019) pandemic disrupted normal human lives, and motivated by the urgent need of combating COVID-19, researchers have put significant efforts in modelling and analysing the disease spread patterns for effective preventive measures (in addition to developing pharmaceutical solutions, like vaccine). In this regards, it is absolutely necessary to develop an analytics framework by extracting and incorporating the knowledge of heterogeneous datasources to deliver insights in improving administrative policy and enhance the preparedness to combat the pandemic. Specifically, human mobility, travel history and other transport statistics have significant impacts on the spread of any infectious disease. In this direction, this paper proposes a spatio-temporal knowledge mining framework, named STOPPAGE to model the impact of human mobility and other contextual information over large geographic area in different temporal scales. The framework has two major modules: (i) Spatio-temporal data and computing infrastructure using fog/edge based architecture; and (ii) Spatio-temporal data analytics module to efficiently extract knowledge from heterogeneous data sources. Typically, we develop a Pandemic-knowledge graph to discover correlations among mobility information and disease spread, a deep learning architecture to predict the next hot-spot zones; and provide necessary support in home-health monitoring utilizing Femtolet and fog/edge based solutions. The experimental evaluations on real-life datasets related to COVID-19 in India illustrate the efficacy of the proposed methods.
Long Document Summarization in a Low Resource Setting using Pretrained Language Models
Mar 01, 2021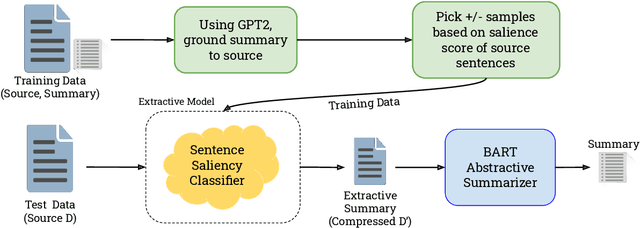
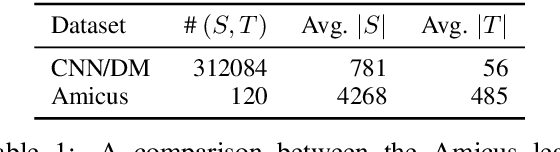

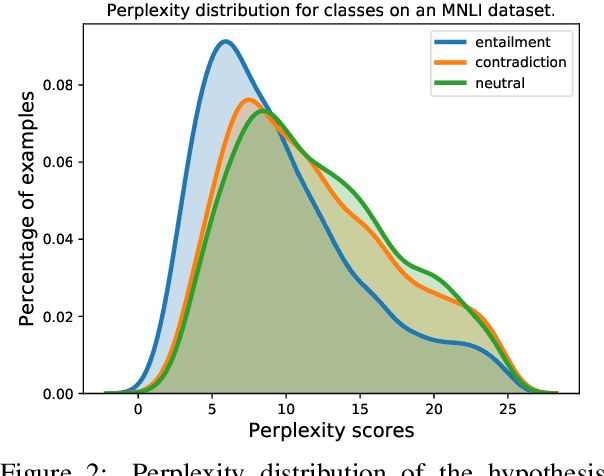
Abstractive summarization is the task of compressing a long document into a coherent short document while retaining salient information. Modern abstractive summarization methods are based on deep neural networks which often require large training datasets. Since collecting summarization datasets is an expensive and time-consuming task, practical industrial settings are usually low-resource. In this paper, we study a challenging low-resource setting of summarizing long legal briefs with an average source document length of 4268 words and only 120 available (document, summary) pairs. To account for data scarcity, we used a modern pretrained abstractive summarizer BART (Lewis et al., 2020), which only achieves 17.9 ROUGE-L as it struggles with long documents. We thus attempt to compress these long documents by identifying salient sentences in the source which best ground the summary, using a novel algorithm based on GPT-2 (Radford et al., 2019) language model perplexity scores, that operates within the low resource regime. On feeding the compressed documents to BART, we observe a 6.0 ROUGE-L improvement. Our method also beats several competitive salience detection baselines. Furthermore, the identified salient sentences tend to agree with an independent human labeling by domain experts.