 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoosing the Right Regularizer for Applied ML: Simulation Benchmarks of Popular Scikit-learn Regularization Frameworks
Apr 07, 2026This study surveys the historical development of regularization, tracing its evolution from stepwise regression in the 1960s to recent advancements in formal error control, structured penalties for non-independent features, Bayesian methods, and l0-based regularization (among other techniques). We empirically evaluate the performance of four canonical frameworks -- Ridge, Lasso, ElasticNet, and Post-Lasso OLS -- across 134,400 simulations spanning a 7-dimensional manifold grounded in eight production-grade machine learning models. Our findings demonstrate that for prediction accuracy when the sample-to-feature ratio is sufficient (n/p >= 78), Ridge, Lasso, and ElasticNet are nearly interchangeable. However, we find that Lasso recall is highly fragile under multicollinearity; at high condition numbers (kappa) and low SNR, Lasso recall collapses to 0.18 while ElasticNet maintains 0.93. Consequently, we advise practitioners against using Lasso or Post-Lasso OLS at high kappa with small sample sizes. The analysis concludes with an objective-driven decision guide to assist machine learning engineers in selecting the optimal scikit-learn-supported framework based on observable feature space attributes.
Long Document Summarization in a Low Resource Setting using Pretrained Language Models
Mar 01, 2021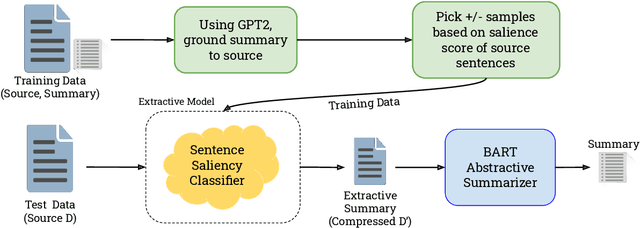
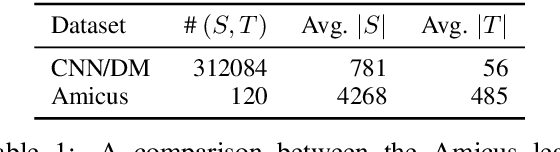

Abstractive summarization is the task of compressing a long document into a coherent short document while retaining salient information. Modern abstractive summarization methods are based on deep neural networks which often require large training datasets. Since collecting summarization datasets is an expensive and time-consuming task, practical industrial settings are usually low-resource. In this paper, we study a challenging low-resource setting of summarizing long legal briefs with an average source document length of 4268 words and only 120 available (document, summary) pairs. To account for data scarcity, we used a modern pretrained abstractive summarizer BART (Lewis et al., 2020), which only achieves 17.9 ROUGE-L as it struggles with long documents. We thus attempt to compress these long documents by identifying salient sentences in the source which best ground the summary, using a novel algorithm based on GPT-2 (Radford et al., 2019) language model perplexity scores, that operates within the low resource regime. On feeding the compressed documents to BART, we observe a 6.0 ROUGE-L improvement. Our method also beats several competitive salience detection baselines. Furthermore, the identified salient sentences tend to agree with an independent human labeling by domain experts.