 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RAPIQUE: Rapid and Accurate Video Quality Prediction of User Generated Content
Jan 26, 2021
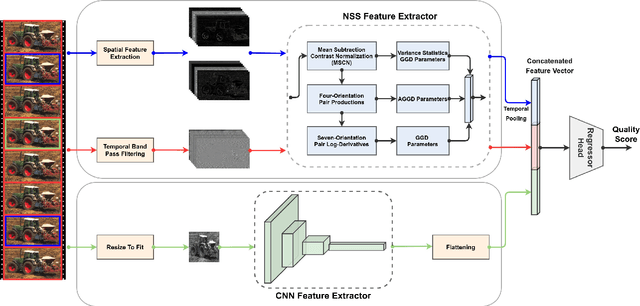
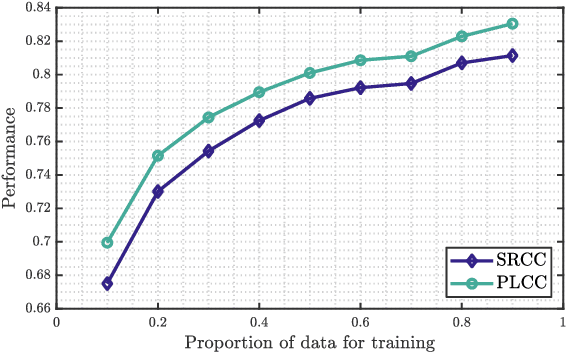
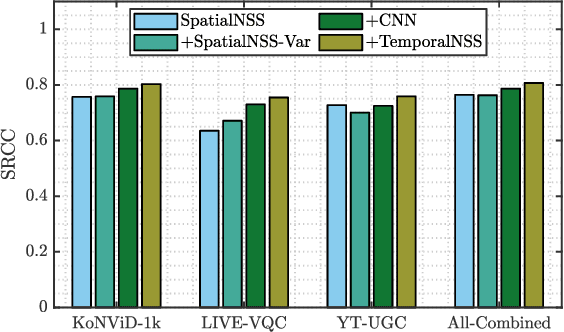
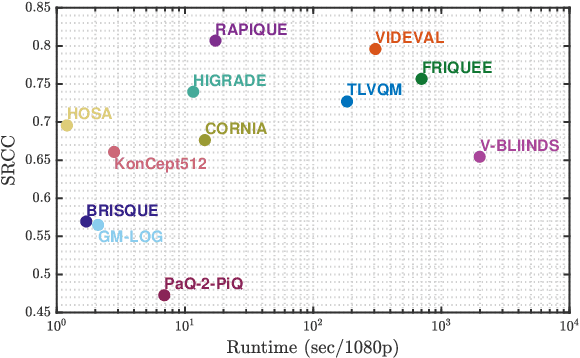
Blind or no-reference video quality assessment of user-generated content (UGC) has become a trending, challenging, unsolved problem. Accurate and efficient video quality predictors suitable for this content are thus in great demand to achieve more intelligent analysis and processing of UGC videos. Previous studies have shown that natural scene statistics and deep learning features are both sufficient to capture spatial distortions, which contribute to a significant aspect of UGC video quality issues. However, these models are either incapable or inefficient for predicting the quality of complex and diverse UGC videos in practical applications. Here we introduce an effective and efficient video quality model for UGC content, which we dub the Rapid and Accurate Video Quality Evaluator (RAPIQUE), which we show performs comparably to state-of-the-art (SOTA) models but with orders-of-magnitude faster runtime. RAPIQUE combines and leverages the advantages of both quality-aware scene statistics features and semantics-aware deep convolutional features, allowing us to design the first general and efficient spatial and temporal (space-time) bandpass statistics model for video quality modeling. Our experimental results on recent large-scale UGC video quality databases show that RAPIQUE delivers top performances on all the datasets at a considerably lower computational expense. We hope this work promotes and inspires further efforts towards practical modeling of video quality problems for potential real-time and low-latency applications. To promote public usage, an implementation of RAPIQUE has been made freely available online: \url{https://github.com/vztu/RAPIQUE}.
Hierarchical growing grid networks for skeleton based action recognition
Apr 22, 2021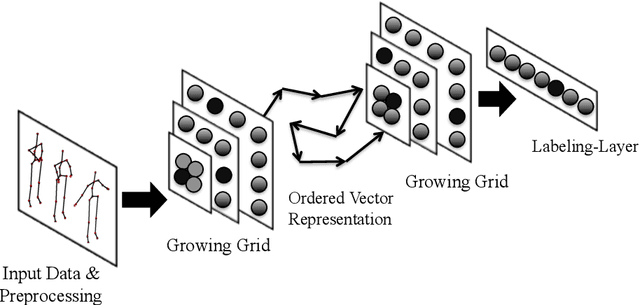
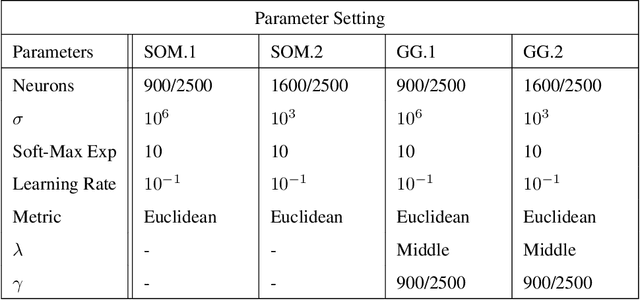
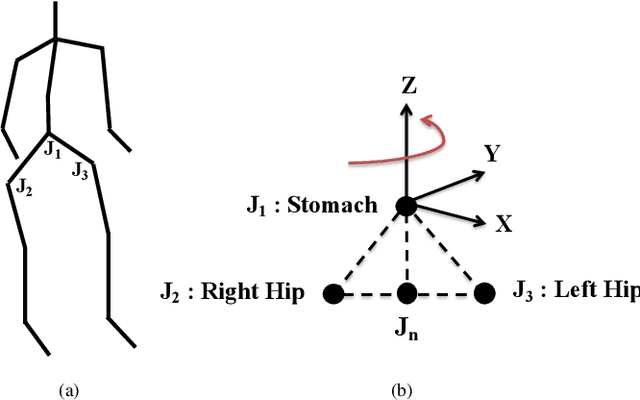
In this paper, a novel cognitive architecture for action recognition is developed by applying layers of growing grid neural networks.Using these layers makes the system capable of automatically arranging its representational structure. In addition to the expansion of the neural map during the growth phase, the system is provided with a prior knowledge of the input space, which increases the processing speed of the learning phase. Apart from two layers of growing grid networks the architecture is composed of a preprocessing layer, an ordered vector representation layer and a one-layer supervised neural network. These layers are designed to solve the action recognition problem. The first-layer growing grid receives the input data of human actions and the neural map generates an action pattern vector representing each action sequence by connecting the elicited activation of the trained map. The pattern vectors are then sent to the ordered vector representation layer to build the time-invariant input vectors of key activations for the second-layer growing grid. The second-layer growing grid categorizes the input vectors to the corresponding action clusters/sub-clusters and finally the one-layer supervised neural network labels the shaped clusters with action labels. Three experiments using different datasets of actions show that the system is capable of learning to categorize the actions quickly and efficiently. The performance of the growing grid architecture is com-pared with the results from a system based on Self-Organizing Maps, showing that the growing grid architecture performs significantly superior on the action recognition tasks.
Environment and Person Independent Activity Recognition with a Commodity IEEE 802.11ac Access Point
Mar 17, 2021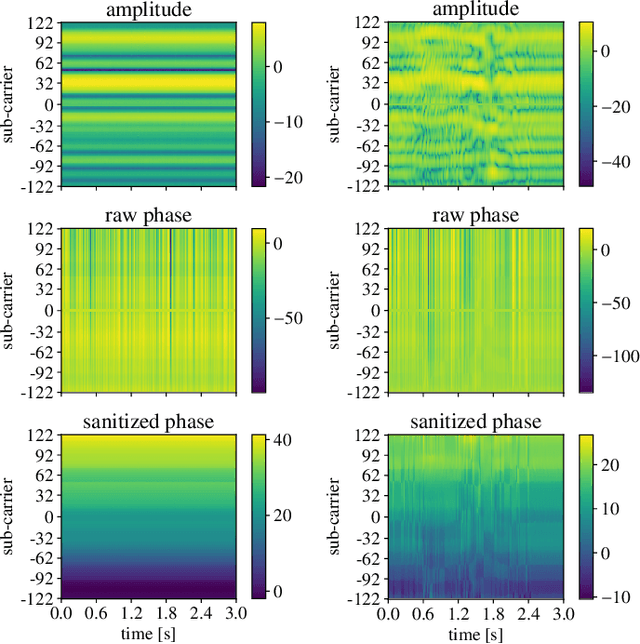
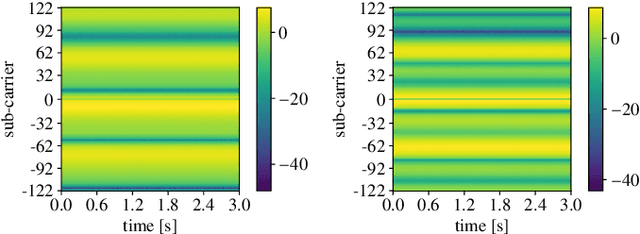
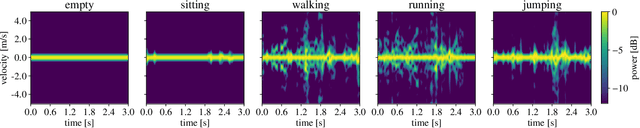
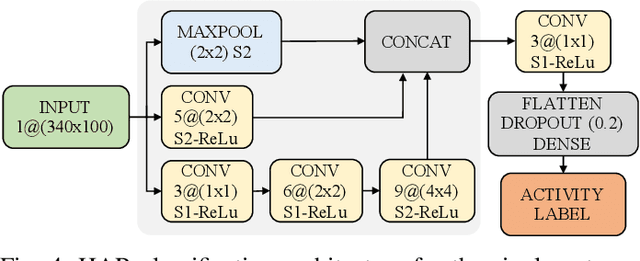
Here, we propose an original approach for human activity recognition (HAR) with commercial IEEE 802.11ac (WiFi) devices, which generalizes across different persons, days and environments. To achieve this, we devise a technique to extract, clean and process the received phases from the channel frequency response (CFR) of the WiFi channel, obtaining an estimate of the Doppler shift at the receiver of the communication link. The Doppler shift reveals the presence of moving scatterers in the environment, while not being affected by (environment specific) static objects. The proposed HAR framework is trained on data collected as a person performs four different activities and is tested on unseen setups, to assess its performance as the person, the day and/or the environment change with respect to those considered at training time. In the worst case scenario, the proposed HAR technique reaches an average accuracy higher than 95%, validating the effectiveness of the extracted Doppler information, used in conjunction with a learning algorithm based on a neural network, in recognizing human activities in a subject and environment independent fashion.
Model-based versus Model-free Deep Reinforcement Learning for Autonomous Racing Cars
Mar 08, 2021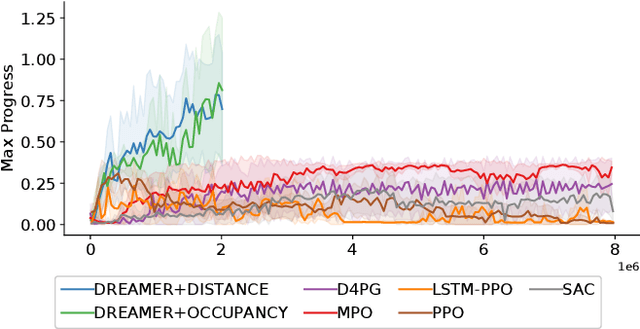
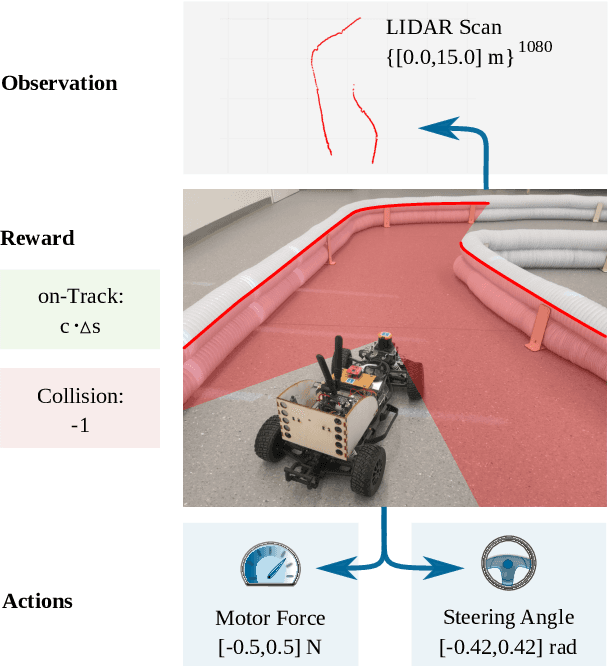

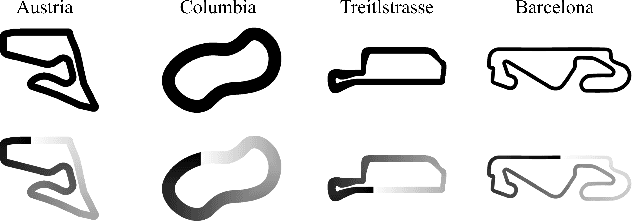
Despite the rich theoretical foundation of model-based deep reinforcement learning (RL) agents, their effectiveness in real-world robotics-applications is less studied and understood. In this paper, we, therefore, investigate how such agents generalize to real-world autonomous-vehicle control-tasks, where advanced model-free deep RL algorithms fail. In particular, we set up a series of time-lap tasks for an F1TENTH racing robot, equipped with high-dimensional LiDAR sensors, on a set of test tracks with a gradual increase in their complexity. In this continuous-control setting, we show that model-based agents capable of learning in imagination, substantially outperform model-free agents with respect to performance, sample efficiency, successful task completion, and generalization. Moreover, we show that the generalization ability of model-based agents strongly depends on the observation-model choice. Finally, we provide extensive empirical evidence for the effectiveness of model-based agents provided with long enough memory horizons in sim2real tasks.
Stochasticity helps to navigate rough landscapes: comparing gradient-descent-based algorithms in the phase retrieval problem
Mar 08, 2021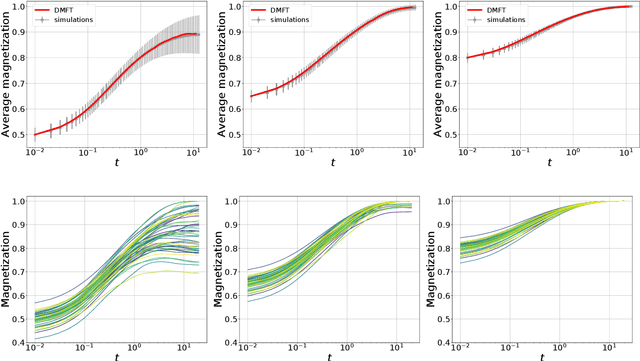
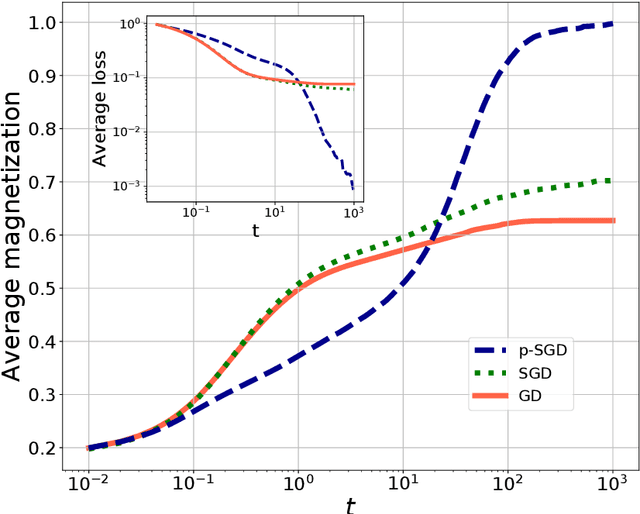
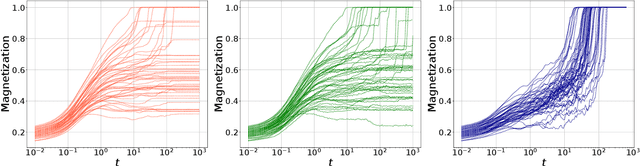
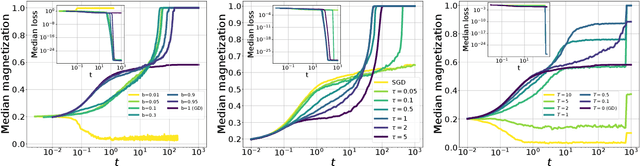
In this paper we investigate how gradient-based algorithms such as gradient descent, (multi-pass) stochastic gradient descent, its persistent variant, and the Langevin algorithm navigate non-convex losslandscapes and which of them is able to reach the best generalization error at limited sample complexity. We consider the loss landscape of the high-dimensional phase retrieval problem as a prototypical highly non-convex example. We observe that for phase retrieval the stochastic variants of gradient descent are able to reach perfect generalization for regions of control parameters where the gradient descent algorithm is not. We apply dynamical mean-field theory from statistical physics to characterize analytically the full trajectories of these algorithms in their continuous-time limit, with a warm start, and for large system sizes. We further unveil several intriguing properties of the landscape and the algorithms such as that the gradient descent can obtain better generalization properties from less informed initializations.
Comparative Evaluation of 3D and 2D Deep Learning Techniques for Semantic Segmentation in CT Scans
Jan 19, 2021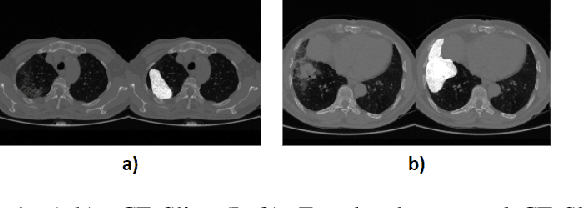

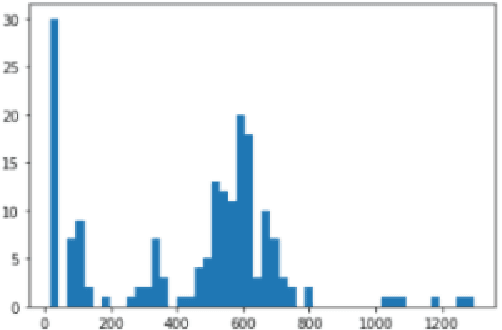
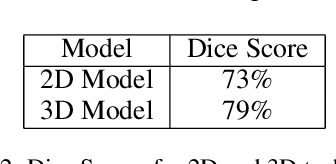
Image segmentation plays a pivotal role in several medical-imaging applications by assisting the segmentation of the regions of interest. Deep learning-based approaches have been widely adopted for semantic segmentation of medical data. In recent years, in addition to 2D deep learning architectures, 3D architectures have been employed as the predictive algorithms for 3D medical image data. In this paper, we propose a 3D stack-based deep learning technique for segmenting manifestations of consolidation and ground-glass opacities in 3D Computed Tomography (CT) scans. We also present a comparison based on the segmentation results, the contextual information retained, and the inference time between this 3D technique and a traditional 2D deep learning technique. We also define the area-plot, which represents the peculiar pattern observed in the slice-wise areas of the pathology regions predicted by these deep learning models. In our exhaustive evaluation, 3D technique performs better than the 2D technique for the segmentation of CT scans. We get dice scores of 79% and 73% for the 3D and the 2D techniques respectively. The 3D technique results in a 5X reduction in the inference time compared to the 2D technique. Results also show that the area-plots predicted by the 3D model are more similar to the ground truth than those predicted by the 2D model. We also show how increasing the amount of contextual information retained during the training can improve the 3D model's performance.
Semantic Modeling with SUMO
Dec 31, 2020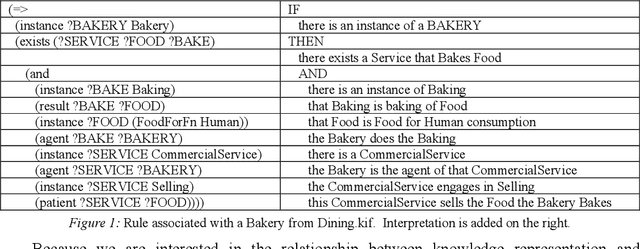

While ontologies are typically applied to static descriptions of the world, we propose to apply them as representations for dynamic simulations. In this paper, we explore using the Suggested Upper Merged Ontology (SUMO) to develop a semantic simulation. We provide two proof-of-concept demonstrations modeling transitions in a simulated gasoline engine. In our models, the knowledge base evolves as the simulation executes. Faults can be detected at run-time.
Dynamical prediction of two meteorological factors using the deep neural network and the long short-term memory $(2)$
Apr 28, 2021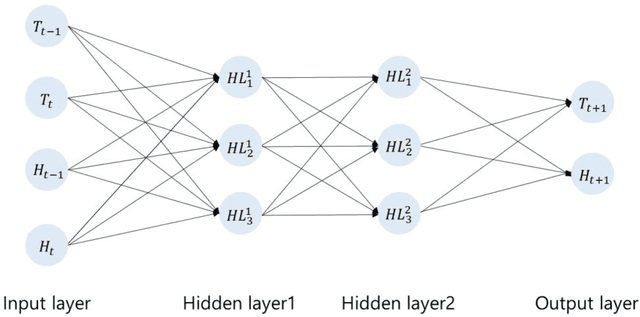
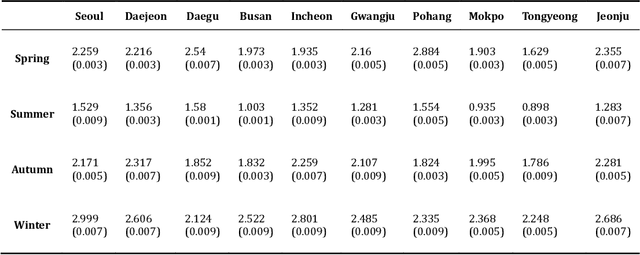
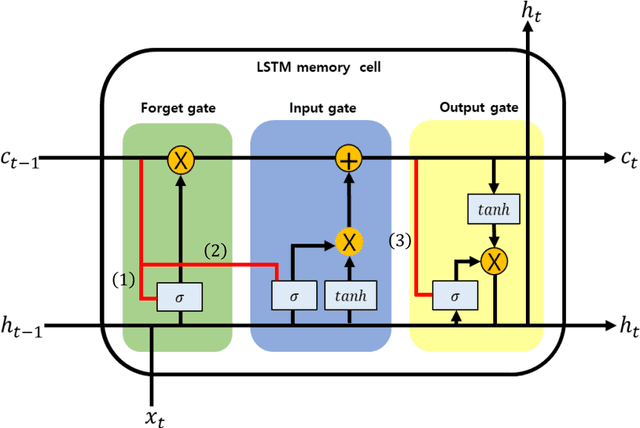
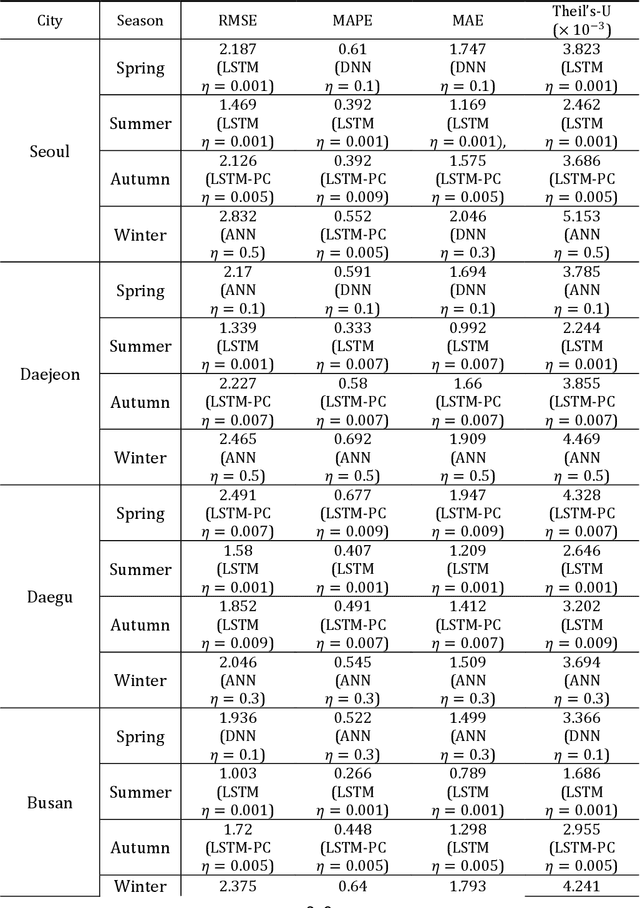
This paper presents the predictive accuracy using two-variate meteorological factors, average temperature and average humidity, in neural network algorithms. We analyze result in five learning architectures such as the traditional artificial neural network, deep neural network, and extreme learning machine, long short-term memory, and long-short-term memory with peephole connections, after manipulating the computer-simulation. Our neural network modes are trained on the daily time-series dataset during seven years (from 2014 to 2020). From the trained results for 2500, 5000, and 7500 epochs, we obtain the predicted accuracies of the meteorological factors produced from outputs in ten metropolitan cities (Seoul, Daejeon, Daegu, Busan, Incheon, Gwangju, Pohang, Mokpo, Tongyeong, and Jeonju). The error statistics is found from the result of outputs, and we compare these values to each other after the manipulation of five neural networks. As using the long-short-term memory model in testing 1 (the average temperature predicted from the input layer with six input nodes), Tonyeong has the lowest root mean squared error (RMSE) value of 0.866 $(%)$ in summer from the computer-simulation in order to predict the temperature. To predict the humidity, the RMSE is shown the lowest value of 5.732 $(%)$, when using the long short-term memory model in summer in Mokpo in testing 2 (the average humidity predicted from the input layer with six input nodes). Particularly, the long short-term memory model is is found to be more accurate in forecasting daily levels than other neural network models in temperature and humidity forecastings. Our result may provide a computer-simuation basis for the necessity of exploring and develping a novel neural network evaluation method in the future.
Chemistry-informed Macromolecule Graph Representation for Similarity Computation and Supervised Learning
Mar 03, 2021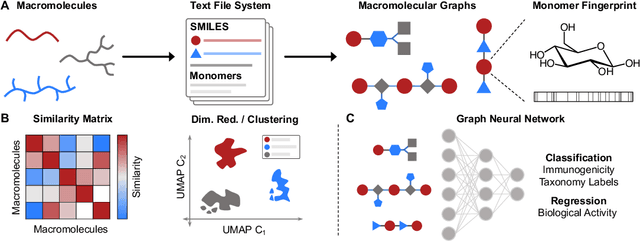
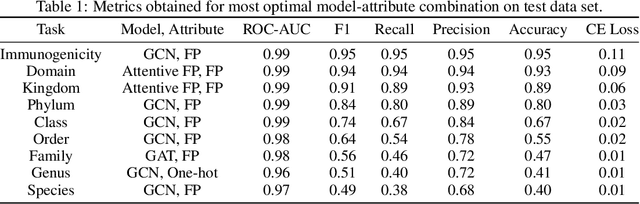
Macromolecules are large, complex molecules composed of covalently bonded monomer units, existing in different stereochemical configurations and topologies. As a result of such chemical diversity, representing, comparing, and learning over macromolecules emerge as critical challenges. To address this, we developed a macromolecule graph representation, with monomers and bonds as nodes and edges, respectively. We captured the inherent chemistry of the macromolecule by using molecular fingerprints for node and edge attributes. For the first time, we demonstrated computation of chemical similarity between 2 macromolecules of varying chemistry and topology, using exact graph edit distances and graph kernels. We also trained graph neural networks for a variety of glycan classification tasks, achieving state-of-the-art results. Our work has two-fold implications - it provides a general framework for representation, comparison, and learning of macromolecules; and enables quantitative chemistry-informed decision-making and iterative design in the macromolecular chemical space.
Learnable Embedding Sizes for Recommender Systems
Jan 19, 2021

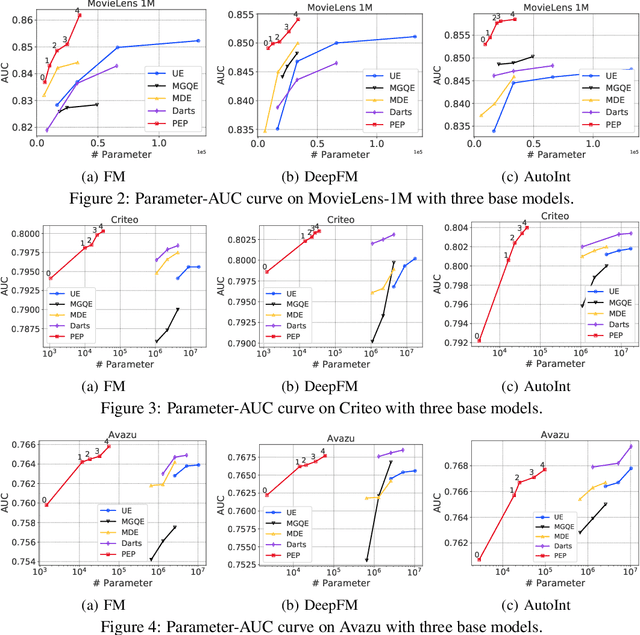
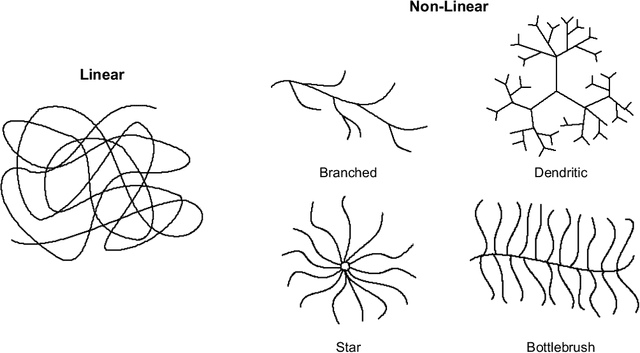
The embedding-based representation learning is commonly used in deep learning recommendation models to map the raw sparse features to dense vectors. The traditional embedding manner that assigns a uniform size to all features has two issues. First, the numerous features inevitably lead to a gigantic embedding table that causes a high memory usage cost. Second, it is likely to cause the over-fitting problem for those features that do not require too large representation capacity. Existing works that try to address the problem always cause a significant drop in recommendation performance or suffers from the limitation of unaffordable training time cost. In this paper, we proposed a novel approach, named PEP (short for Plug-in Embedding Pruning), to reduce the size of the embedding table while obviating a drop in accuracy and computational optimization. PEP prunes embedding parameter where the pruning threshold(s) can be adaptively learned from data. Therefore we can automatically obtain a mixed-dimension embedding-scheme by pruning redundant parameters for each feature. PEP is a general framework that can plug in various base recommendation models. Extensive experiments demonstrate it can efficiently cut down embedding parameters and boost the base model's performance. Specifically, it achieves strong recommendation performance while reducing 97-99% parameters. As for the computation cost, PEP only brings an additional 20-30% time cost compared with base models. Codes are available at https://github.com/ssui-liu/learnable-embed-sizes-for-RecSys.