 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LSTM Based Sentiment Analysis for Cryptocurrency Prediction
Mar 27, 2021


Recent studies in big data analytics and natural language processing develop automatic techniques in analyzing sentiment in the social media information. In addition, the growing user base of social media and the high volume of posts also provide valuable sentiment information to predict the price fluctuation of the cryptocurrency. This research is directed to predicting the volatile price movement of cryptocurrency by analyzing the sentiment in social media and finding the correlation between them. While previous work has been developed to analyze sentiment in English social media posts, we propose a method to identify the sentiment of the Chinese social media posts from the most popular Chinese social media platform Sina-Weibo. We develop the pipeline to capture Weibo posts, describe the creation of the crypto-specific sentiment dictionary, and propose a long short-term memory (LSTM) based recurrent neural network along with the historical cryptocurrency price movement to predict the price trend for future time frames. The conducted experiments demonstrate the proposed approach outperforms the state of the art auto regressive based model by 18.5% in precision and 15.4% in recall.
A Study on Efficiency in Continual Learning Inspired by Human Learning
Oct 28, 2020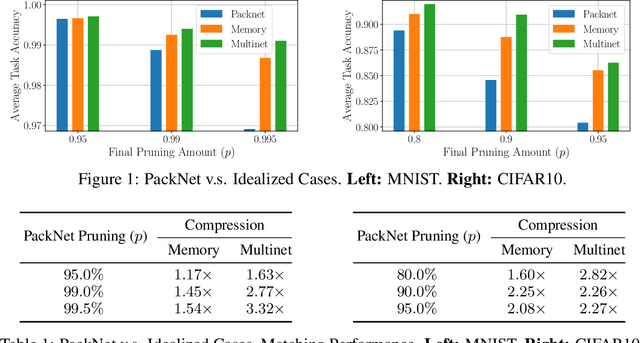

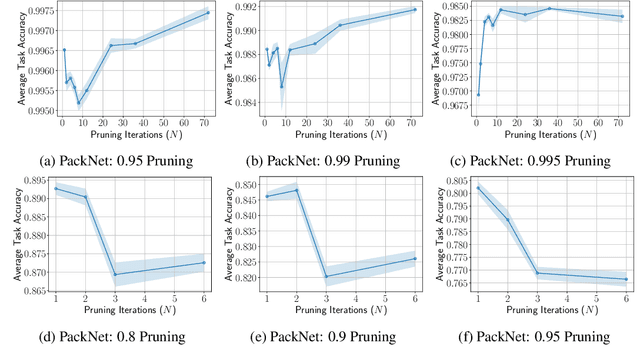
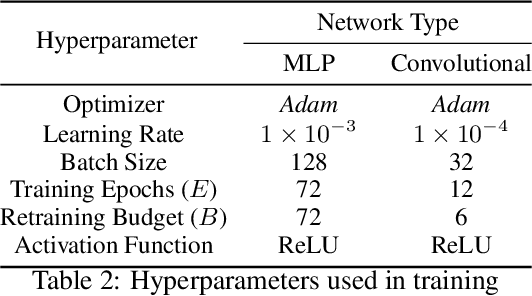
Humans are efficient continual learning systems; we continually learn new skills from birth with finite cells and resources. Our learning is highly optimized both in terms of capacity and time while not suffering from catastrophic forgetting. In this work we study the efficiency of continual learning systems, taking inspiration from human learning. In particular, inspired by the mechanisms of sleep, we evaluate popular pruning-based continual learning algorithms, using PackNet as a case study. First, we identify that weight freezing, which is used in continual learning without biological justification, can result in over $2\times$ as many weights being used for a given level of performance. Secondly, we note the similarity in human day and night time behaviors to the training and pruning phases respectively of PackNet. We study a setting where the pruning phase is given a time budget, and identify connections between iterative pruning and multiple sleep cycles in humans. We show there exists an optimal choice of iteration v.s. epochs given different tasks.
Efficient Reachability Analysis of Closed-Loop Systems with Neural Network Controllers
Jan 05, 2021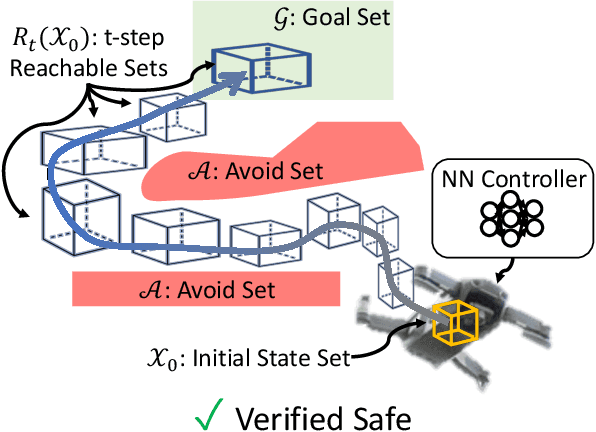
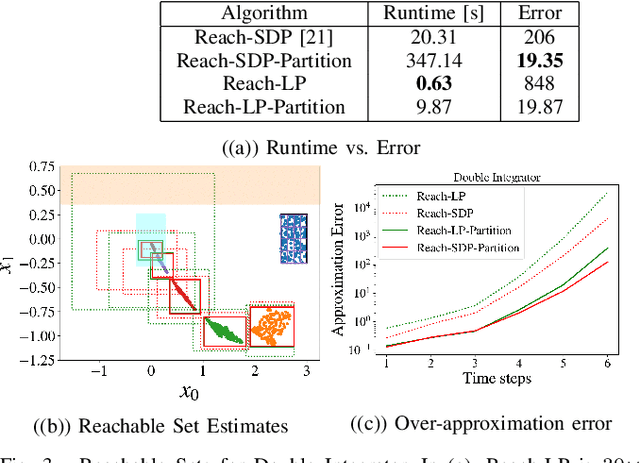
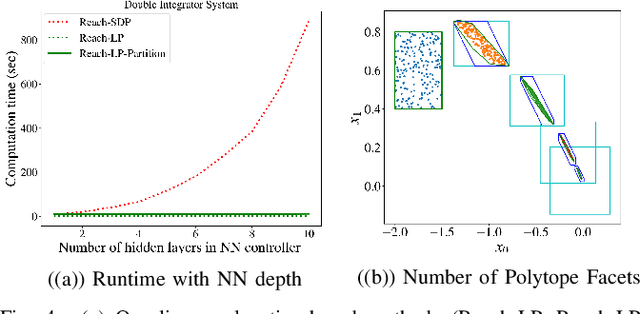
Neural Networks (NNs) can provide major empirical performance improvements for robotic systems, but they also introduce challenges in formally analyzing those systems' safety properties. In particular, this work focuses on estimating the forward reachable set of closed-loop systems with NN controllers. Recent work provides bounds on these reachable sets, yet the computationally efficient approaches provide overly conservative bounds (thus cannot be used to verify useful properties), whereas tighter methods are too intensive for online computation. This work bridges the gap by formulating a convex optimization problem for reachability analysis for closed-loop systems with NN controllers. While the solutions are less tight than prior semidefinite program-based methods, they are substantially faster to compute, and some of the available computation time can be used to refine the bounds through input set partitioning, which more than overcomes the tightness gap. The proposed framework further considers systems with measurement and process noise, thus being applicable to realistic systems with uncertainty. Finally, numerical comparisons show $10\times$ reduction in conservatism in $\frac{1}{2}$ of the computation time compared to the state-of-the-art, and the ability to handle various sources of uncertainty is highlighted on a quadrotor model.
Reliably fast adversarial training via latent adversarial perturbation
Apr 04, 2021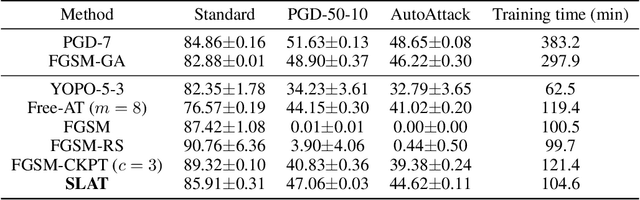
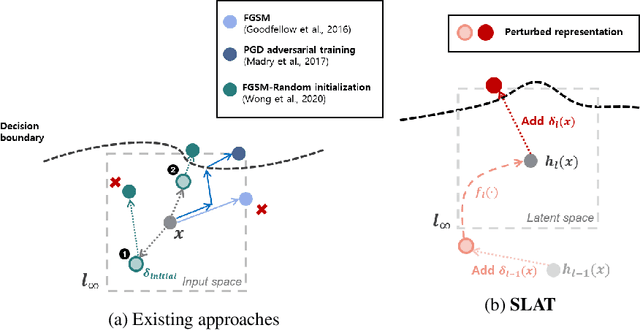

While multi-step adversarial training is widely popular as an effective defense method against strong adversarial attacks, its computational cost is notoriously expensive, compared to standard training. Several single-step adversarial training methods have been proposed to mitigate the above-mentioned overhead cost; however, their performance is not sufficiently reliable depending on the optimization setting. To overcome such limitations, we deviate from the existing input-space-based adversarial training regime and propose a single-step latent adversarial training method (SLAT), which leverages the gradients of latent representation as the latent adversarial perturbation. We demonstrate that the L1 norm of feature gradients is implicitly regularized through the adopted latent perturbation, thereby recovering local linearity and ensuring reliable performance, compared to the existing single-step adversarial training methods. Because latent perturbation is based on the gradients of the latent representations which can be obtained for free in the process of input gradients computation, the proposed method costs roughly the same time as the fast gradient sign method. Experiment results demonstrate that the proposed method, despite its structural simplicity, outperforms state-of-the-art accelerated adversarial training methods.
The Convex Feasible Set Algorithm for Real Time Optimization in Motion Planning
May 19, 2018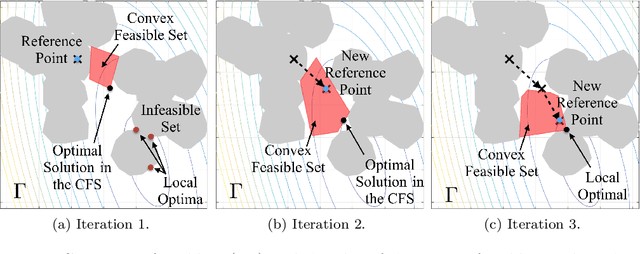
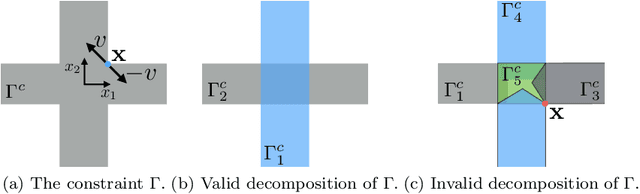
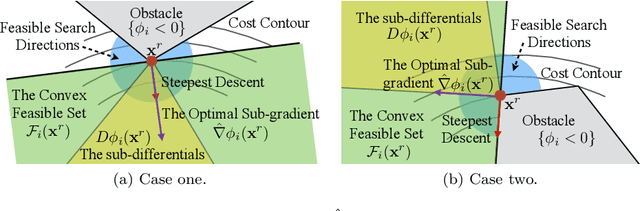
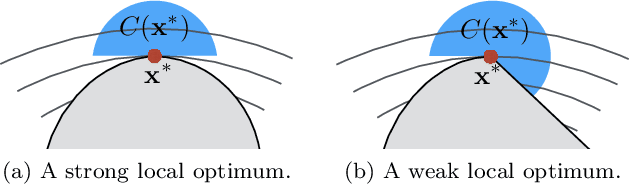
With the development of robotics, there are growing needs for real time motion planning. However, due to obstacles in the environment, the planning problem is highly non-convex, which makes it difficult to achieve real time computation using existing non-convex optimization algorithms. This paper introduces the convex feasible set algorithm (CFS) which is a fast algorithm for non-convex optimization problems that have convex costs and non-convex constraints. The idea is to find a convex feasible set for the original problem and iteratively solve a sequence of subproblems using the convex constraints. The feasibility and the convergence of the proposed algorithm are proved in the paper. The application of this method on motion planning for mobile robots is discussed. The simulations demonstrate the effectiveness of the proposed algorithm.
SCNet: Training Inference Sample Consistency for Instance Segmentation
Dec 18, 2020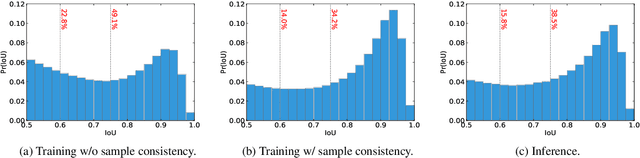
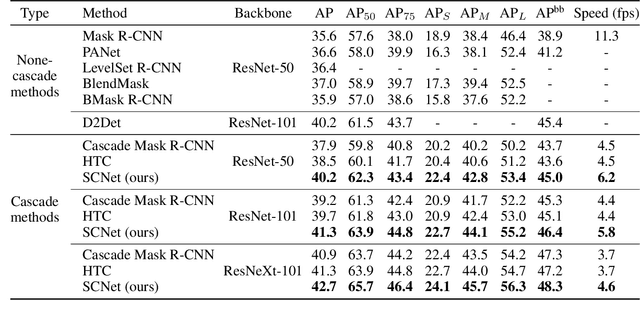


Cascaded architectures have brought significant performance improvement in object detection and instance segmentation. However, there are lingering issues regarding the disparity in the Intersection-over-Union (IoU) distribution of the samples between training and inference. This disparity can potentially exacerbate detection accuracy. This paper proposes an architecture referred to as Sample Consistency Network (SCNet) to ensure that the IoU distribution of the samples at training time is close to that at inference time. Furthermore, SCNet incorporates feature relay and utilizes global contextual information to further reinforce the reciprocal relationships among classifying, detecting, and segmenting sub-tasks. Extensive experiments on the standard COCO dataset reveal the effectiveness of the proposed method over multiple evaluation metrics, including box AP, mask AP, and inference speed. In particular, while running 38\% faster, the proposed SCNet improves the AP of the box and mask predictions by respectively 1.3 and 2.3 points compared to the strong Cascade Mask R-CNN baseline. Code is available at \url{https://github.com/thangvubk/SCNet}.
Nondeterminism and Instability in Neural Network Optimization
Mar 08, 2021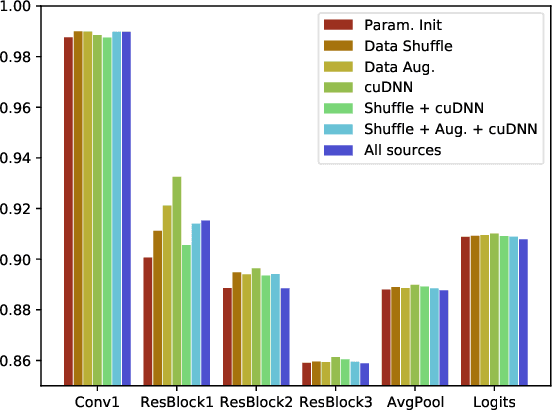
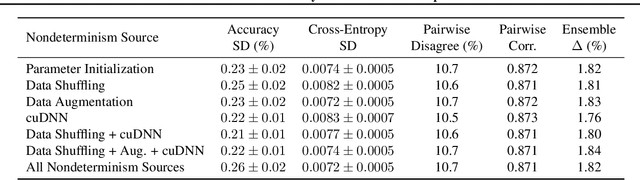
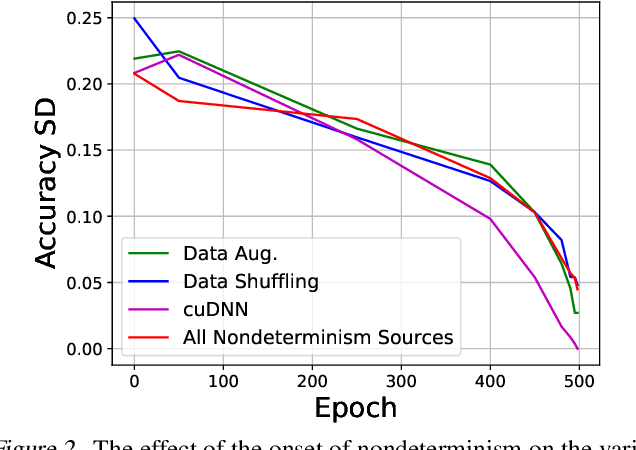

Nondeterminism in neural network optimization produces uncertainty in performance, making small improvements difficult to discern from run-to-run variability. While uncertainty can be reduced by training multiple model copies, doing so is time-consuming, costly, and harms reproducibility. In this work, we establish an experimental protocol for understanding the effect of optimization nondeterminism on model diversity, allowing us to isolate the effects of a variety of sources of nondeterminism. Surprisingly, we find that all sources of nondeterminism have similar effects on measures of model diversity. To explain this intriguing fact, we identify the instability of model training, taken as an end-to-end procedure, as the key determinant. We show that even one-bit changes in initial parameters result in models converging to vastly different values. Last, we propose two approaches for reducing the effects of instability on run-to-run variability.
Reinforcement Learning For Data Poisoning on Graph Neural Networks
Feb 12, 2021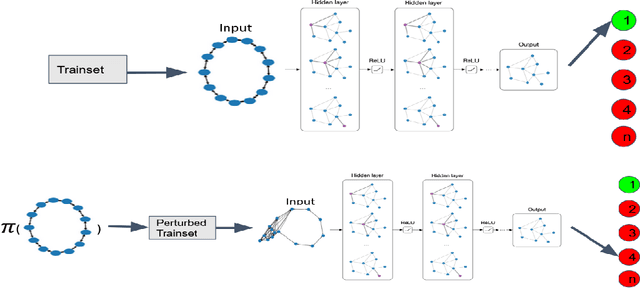
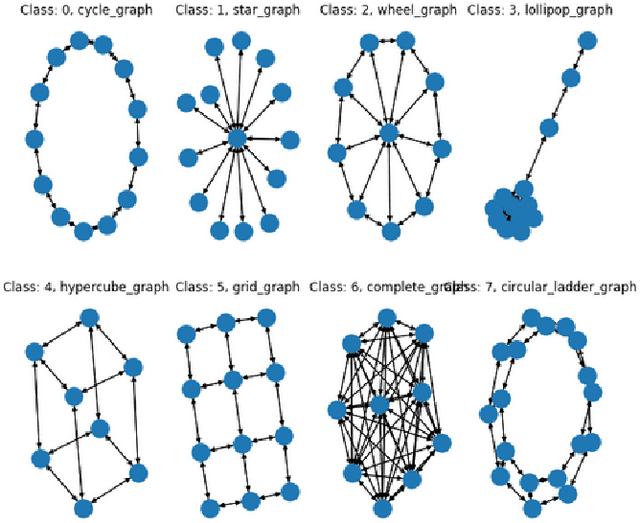
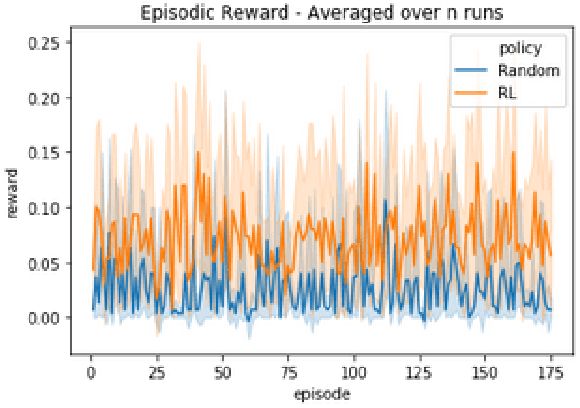
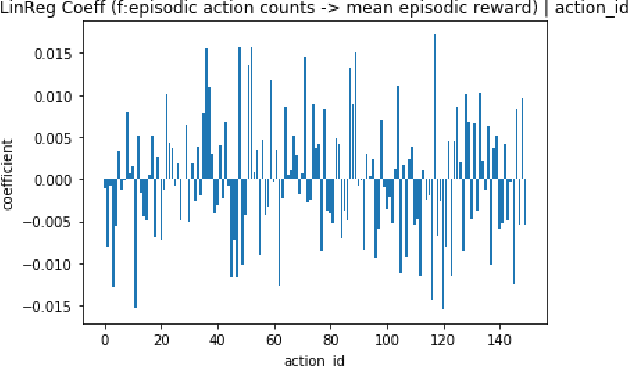
Adversarial Machine Learning has emerged as a substantial subfield of Computer Science due to a lack of robustness in the models we train along with crowdsourcing practices that enable attackers to tamper with data. In the last two years, interest has surged in adversarial attacks on graphs yet the Graph Classification setting remains nearly untouched. Since a Graph Classification dataset consists of discrete graphs with class labels, related work has forgone direct gradient optimization in favor of an indirect Reinforcement Learning approach. We will study the novel problem of Data Poisoning (training time) attack on Neural Networks for Graph Classification using Reinforcement Learning Agents.
Deep Spectrum Cartography: Completing Radio Map Tensors Using Learned Neural Models
May 01, 2021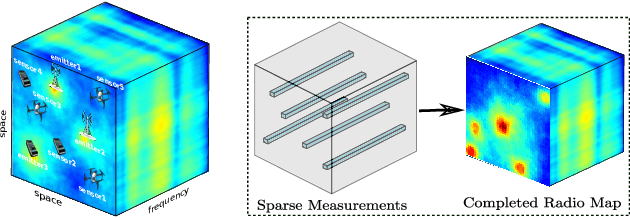
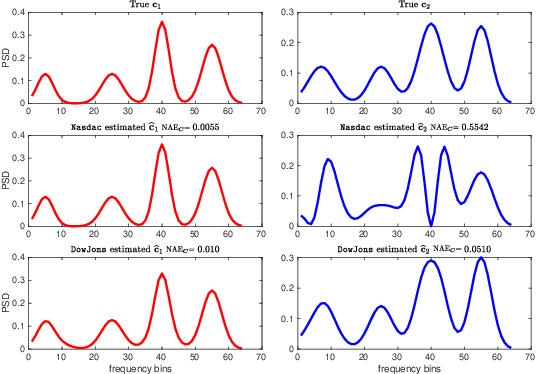
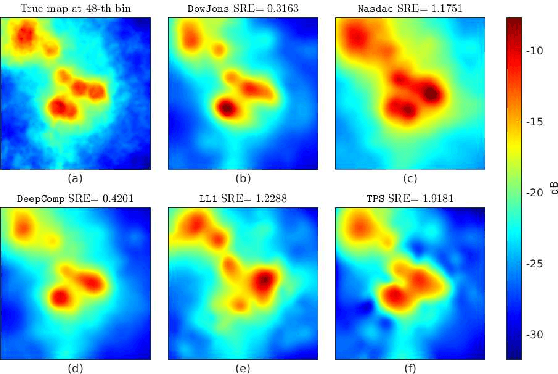
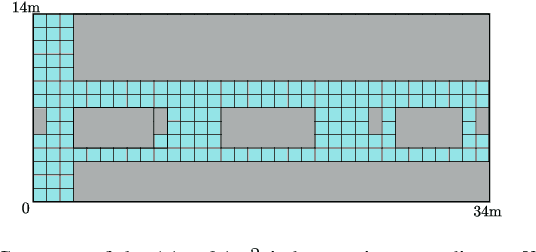
The spectrum cartography (SC) technique constructs multi-domain (e.g., frequency, space, and time) radio frequency (RF) maps from limited measurements, which can be viewed as an ill-posed tensor completion problem. Model-based cartography techniques often rely on handcrafted priors (e.g., sparsity, smoothness and low-rank structures) for the completion task. Such priors may be inadequate to capture the essence of complex wireless environments -- especially when severe shadowing happens. To circumvent such challenges, offline-trained deep neural models of radio maps were considered for SC, as deep neural networks (DNNs) are able to "learn" intricate underlying structures from data. However, such deep learning (DL)-based SC approaches encounter serious challenges in both off-line model learning (training) and completion (generalization), possibly because the latent state space for generating the radio maps is prohibitively large. In this work, an emitter radio map disaggregation-based approach is proposed, under which only individual emitters' radio maps are modeled by DNNs. This way, the learning and generalization challenges can both be substantially alleviated. Using the learned DNNs, a fast nonnegative matrix factorization-based two-stage SC method and a performance-enhanced iterative optimization algorithm are proposed. Theoretical aspects -- such as recoverability of the radio tensor, sample complexity, and noise robustness -- under the proposed framework are characterized, and such theoretical properties have been elusive in the context of DL-based radio tensor completion. Experiments using synthetic and real-data from indoor and heavily shadowed environments are employed to showcase the effectiveness of the proposed methods.
Modular Object-Oriented Games: A Task Framework for Reinforcement Learning, Psychology, and Neuroscience
Feb 25, 2021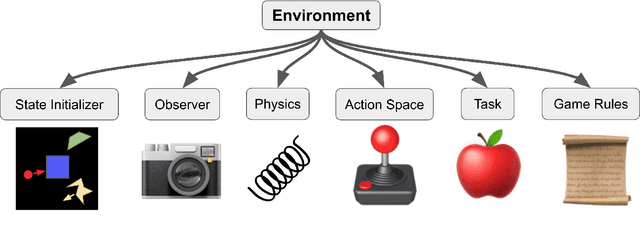
In recent years, trends towards studying simulated games have gained momentum in the fields of artificial intelligence, cognitive science, psychology, and neuroscience. The intersections of these fields have also grown recently, as researchers increasing study such games using both artificial agents and human or animal subjects. However, implementing games can be a time-consuming endeavor and may require a researcher to grapple with complex codebases that are not easily customized. Furthermore, interdisciplinary researchers studying some combination of artificial intelligence, human psychology, and animal neurophysiology face additional challenges, because existing platforms are designed for only one of these domains. Here we introduce Modular Object-Oriented Games, a Python task framework that is lightweight, flexible, customizable, and designed for use by machine learning, psychology, and neurophysiology researchers.