 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contextual Biasing of Language Models for Speech Recognition in Goal-Oriented Conversational Agents
Mar 18, 2021

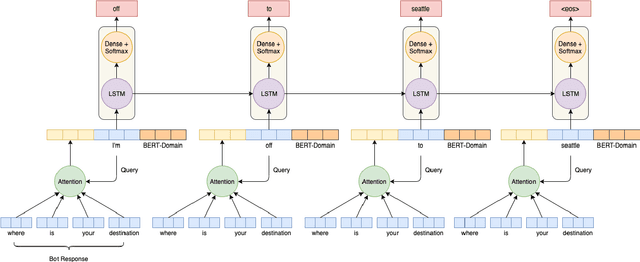
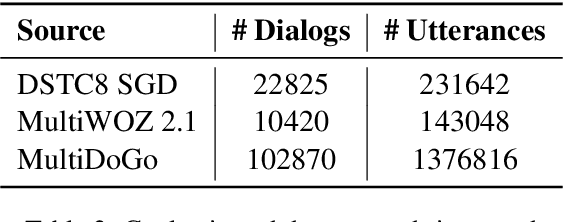
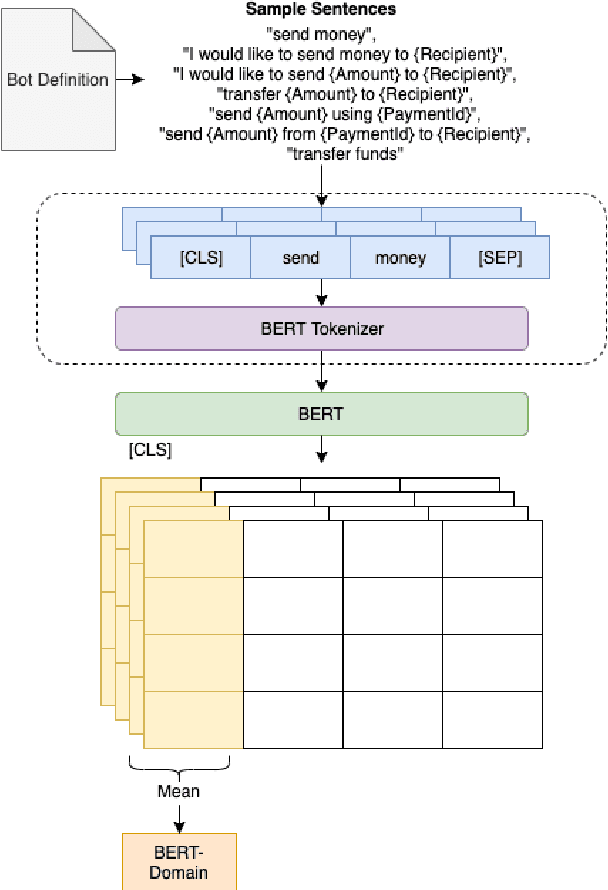
Goal-oriented conversational interfaces are designed to accomplish specific tasks and typically have interactions that tend to span multiple turns adhering to a pre-defined structure and a goal. However, conventional neural language models (NLM) in Automatic Speech Recognition (ASR) systems are mostly trained sentence-wise with limited context. In this paper, we explore different ways to incorporate context into a LSTM based NLM in order to model long range dependencies and improve speech recognition. Specifically, we use context carry over across multiple turns and use lexical contextual cues such as system dialog act from Natural Language Understanding (NLU) models and the user provided structure of the chatbot. We also propose a new architecture that utilizes context embeddings derived from BERT on sample utterances provided during inference time. Our experiments show a word error rate (WER) relative reduction of 7% over non-contextual utterance-level NLM rescorers on goal-oriented audio datasets.
Open Range Pitch Tracking for Carrier Frequency Difference Estimation from HF Transmitted Speech
Mar 03, 2021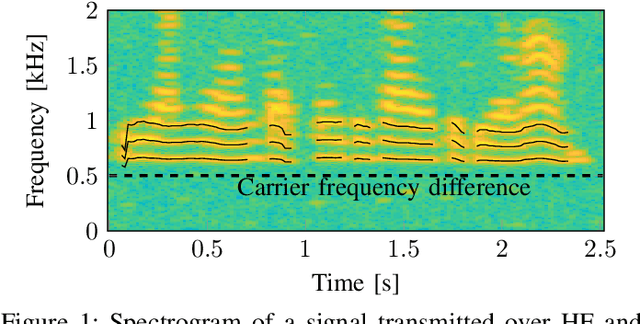
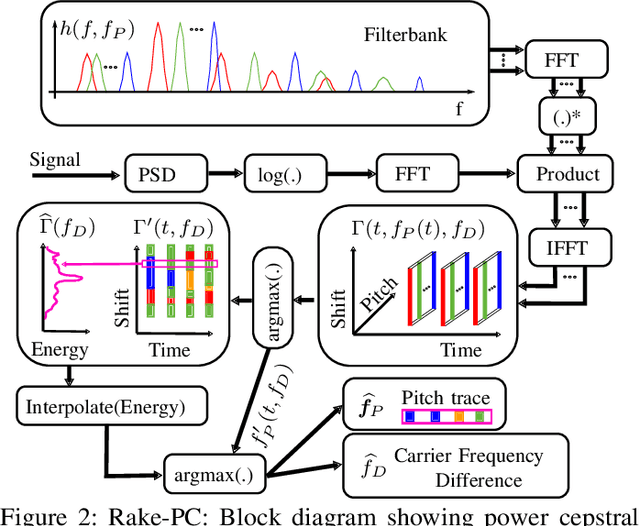
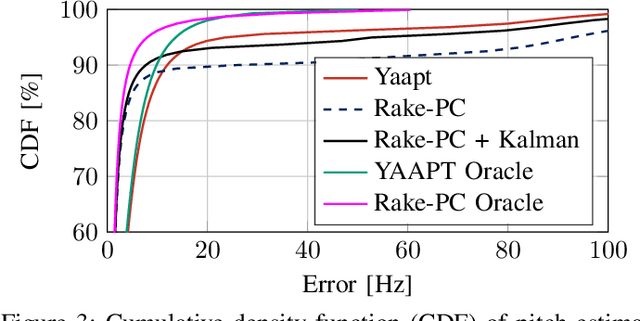
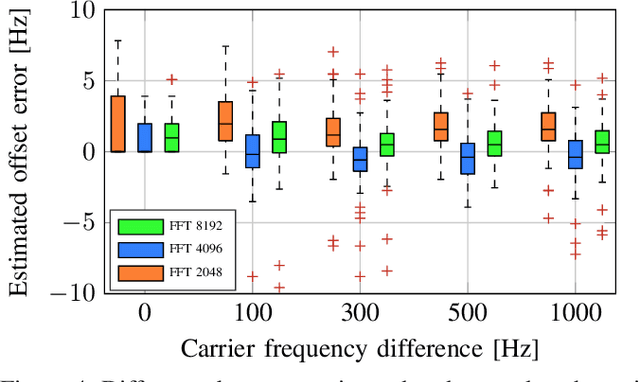
In this paper we investigate the task of detecting carrier frequency differences from demodulated single sideband signals by examining the pitch contours of the received baseband speech signal in the short-time spectral domain. From the detected pitch frequency trajectory and its harmonics a carrier frequency difference, which is caused by demodulating the radio signal with the wrong carrier frequency, can be deduced. A computationally efficient realization in the power cepstral domain is presented. The core component, i.e., the pitch tracking algorithm, is shown to perform comparably to a state of the art algorithm. The full carrier frequency difference estimation system is tested on recordings of real transmissions over HF links. A comparison with an existing approach shows improved estimation accuracy, both on short and longer speech utterances
Combining exogenous and endogenous signals with a semi-supervised co-attention network for early detection of COVID-19 fake tweets
Apr 12, 2021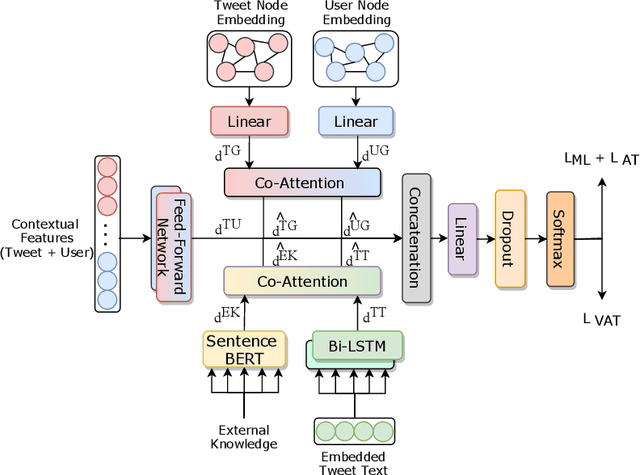
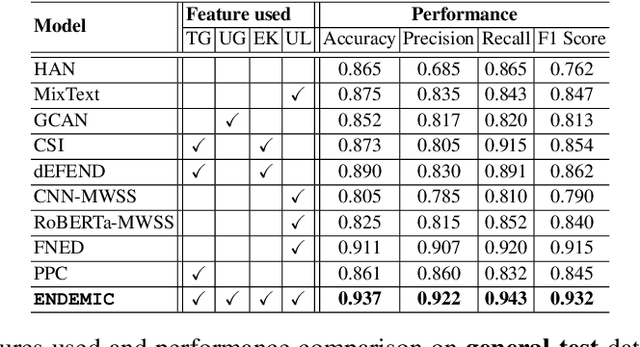
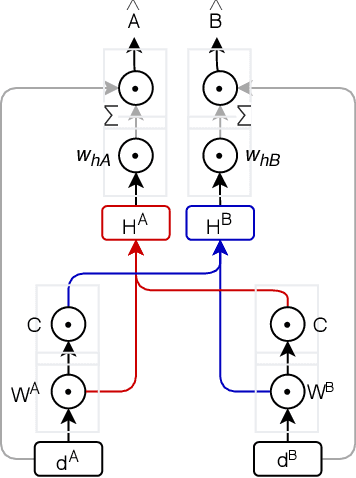
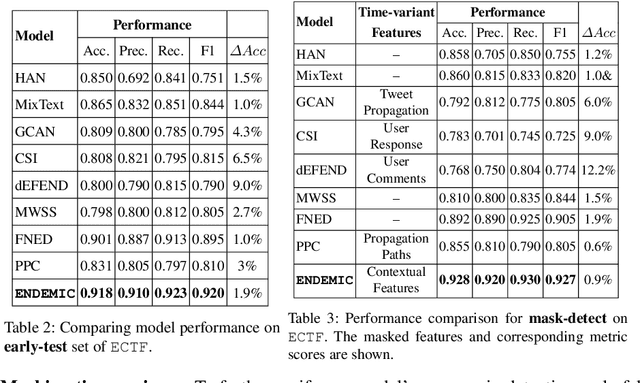
Fake tweets are observed to be ever-increasing, demanding immediate countermeasures to combat their spread. During COVID-19, tweets with misinformation should be flagged and neutralized in their early stages to mitigate the damages. Most of the existing methods for early detection of fake news assume to have enough propagation information for large labeled tweets -- which may not be an ideal setting for cases like COVID-19 where both aspects are largely absent. In this work, we present ENDEMIC, a novel early detection model which leverages exogenous and endogenous signals related to tweets, while learning on limited labeled data. We first develop a novel dataset, called CTF for early COVID-19 Twitter fake news, with additional behavioral test sets to validate early detection. We build a heterogeneous graph with follower-followee, user-tweet, and tweet-retweet connections and train a graph embedding model to aggregate propagation information. Graph embeddings and contextual features constitute endogenous, while time-relative web-scraped information constitutes exogenous signals. ENDEMIC is trained in a semi-supervised fashion, overcoming the challenge of limited labeled data. We propose a co-attention mechanism to fuse signal representations optimally. Experimental results on ECTF, PolitiFact, and GossipCop show that ENDEMIC is highly reliable in detecting early fake tweets, outperforming nine state-of-the-art methods significantly.
Bayesian filtering for nonlinear stochastic systems using holonomic gradient method with integral transform
Mar 03, 2021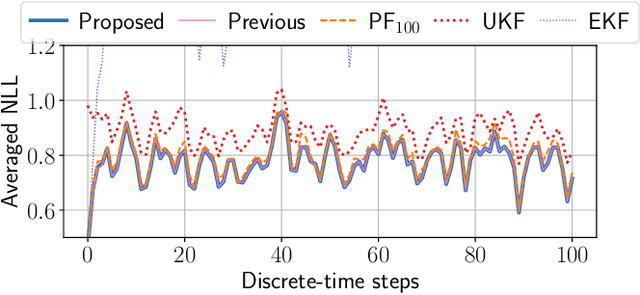
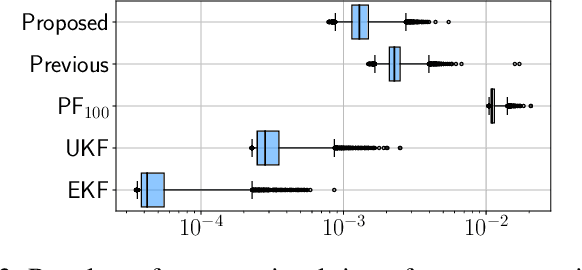
This paper proposes a symbolic-numeric Bayesian filtering method for a class of discrete-time nonlinear stochastic systems to achieve high accuracy with a relatively small online computational cost. The proposed method is based on the holonomic gradient method (HGM), which is a symbolic-numeric method to evaluate integrals efficiently depending on several parameters. By approximating the posterior probability density function (PDF) of the state as a Gaussian PDF, the update process of its mean and variance can be formulated as evaluations of several integrals that exactly take into account the nonlinearity of the system dynamics. An integral transform is used to evaluate these integrals more efficiently using the HGM than our previous method. Further, a numerical example is provided to demonstrate the efficiency of the proposed method compared to other existing methods.
Enriched Annotations for Tumor Attribute Classification from Pathology Reports with Limited Labeled Data
Dec 15, 2020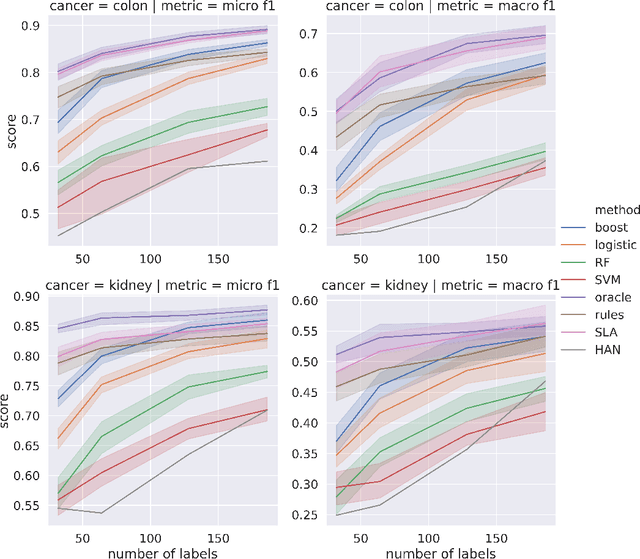
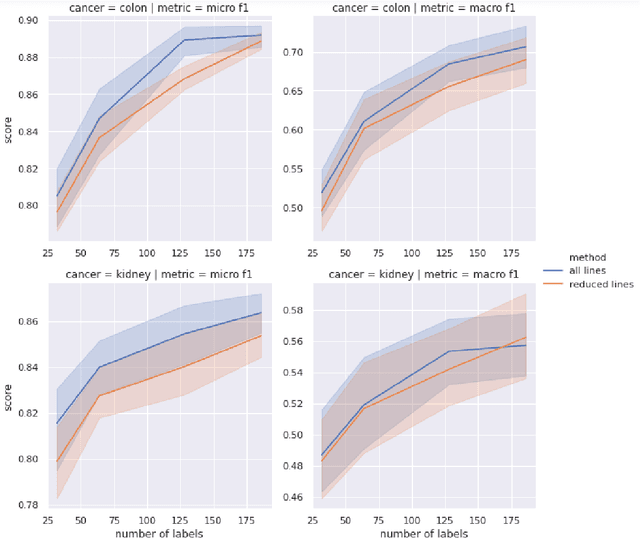
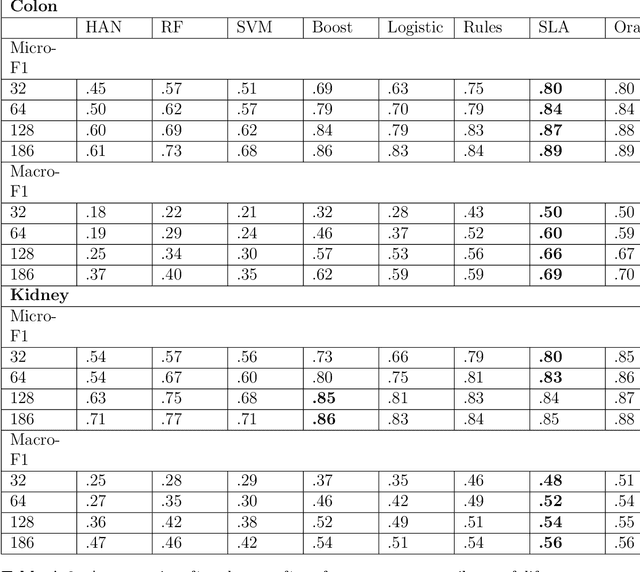
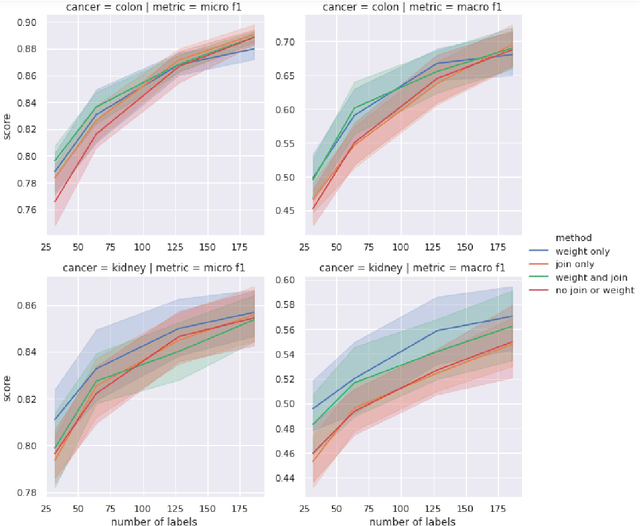
Precision medicine has the potential to revolutionize healthcare, but much of the data for patients is locked away in unstructured free-text, limiting research and delivery of effective personalized treatments. Generating large annotated datasets for information extraction from clinical notes is often challenging and expensive due to the high level of expertise needed for high quality annotations. To enable natural language processing for small dataset sizes, we develop a novel enriched hierarchical annotation scheme and algorithm, Supervised Line Attention (SLA), and apply this algorithm to predicting categorical tumor attributes from kidney and colon cancer pathology reports from the University of California San Francisco (UCSF). Whereas previous work only annotated document level labels, we in addition ask the annotators to enrich the traditional label by asking them to also highlight the relevant line or potentially lines for the final label, which leads to a 20% increase of annotation time required per document. With the enriched annotations, we develop a simple and interpretable machine learning algorithm that first predicts the relevant lines in the document and then predicts the tumor attribute. Our results show across the small dataset sizes of 32, 64, 128, and 186 labeled documents per cancer, SLA only requires half the number of labeled documents as state-of-the-art methods to achieve similar or better micro-f1 and macro-f1 scores for the vast majority of comparisons that we made. Accounting for the increased annotation time, this leads to a 40% reduction in total annotation time over the state of the art.
The Implicit Biases of Stochastic Gradient Descent on Deep Neural Networks with Batch Normalization
Feb 06, 2021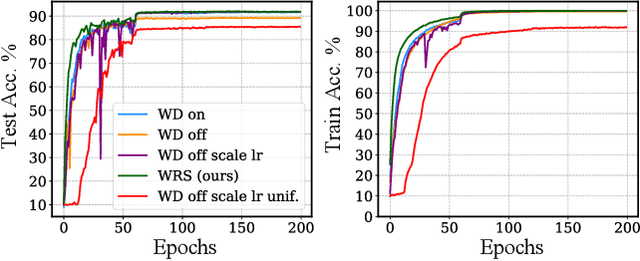
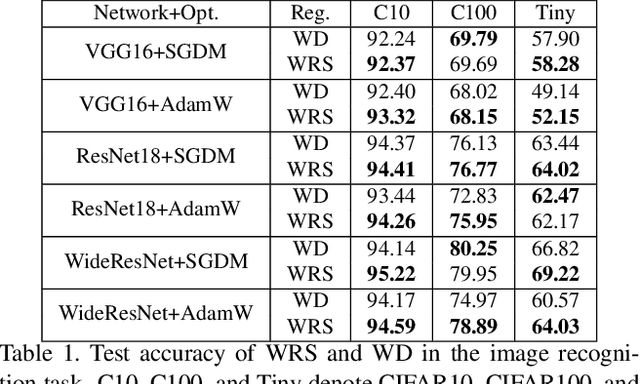
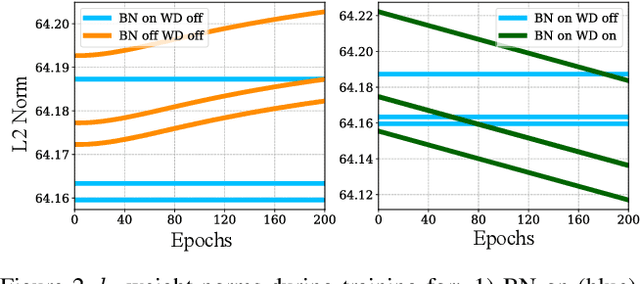
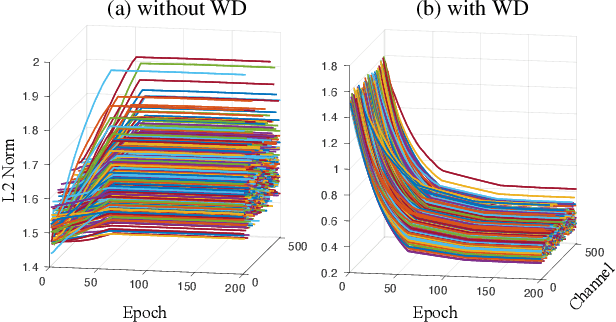
Deep neural networks with batch normalization (BN-DNNs) are invariant to weight rescaling due to their normalization operations. However, using weight decay (WD) benefits these weight-scale-invariant networks, which is often attributed to an increase of the effective learning rate when the weight norms are decreased. In this paper, we demonstrate the insufficiency of the previous explanation and investigate the implicit biases of stochastic gradient descent (SGD) on BN-DNNs to provide a theoretical explanation for the efficacy of weight decay. We identity two implicit biases of SGD on BN-DNNs: 1) the weight norms in SGD training remain constant in the continuous-time domain and keep increasing in the discrete-time domain; 2) SGD optimizes weight vectors in fully-connected networks or convolution kernels in convolution neural networks by updating components lying in the input feature span, while leaving those components orthogonal to the input feature span unchanged. Thus, SGD without WD accumulates weight noise orthogonal to the input feature span, and cannot eliminate such noise. Our empirical studies corroborate the hypothesis that weight decay suppresses weight noise that is left untouched by SGD. Furthermore, we propose to use weight rescaling (WRS) instead of weight decay to achieve the same regularization effect, while avoiding performance degradation of WD on some momentum-based optimizers. Our empirical results on image recognition show that regardless of optimization methods and network architectures, training BN-DNNs using WRS achieves similar or better performance compared with using WD. We also show that training with WRS generalizes better compared to WD, on other computer vision tasks.
Scalable Graph Neural Networks via Bidirectional Propagation
Oct 29, 2020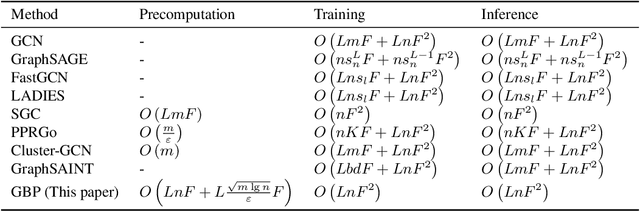
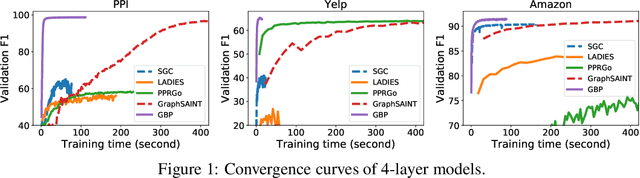
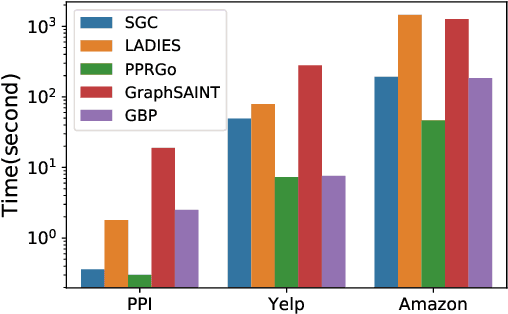
Graph Neural Networks (GNN) is an emerging field for learning on non-Euclidean data. Recently, there has been increased interest in designing GNN that scales to large graphs. Most existing methods use "graph sampling" or "layer-wise sampling" techniques to reduce training time. However, these methods still suffer from degrading performance and scalability problems when applying to graphs with billions of edges. This paper presents GBP, a scalable GNN that utilizes a localized bidirectional propagation process from both the feature vectors and the training/testing nodes. Theoretical analysis shows that GBP is the first method that achieves sub-linear time complexity for both the precomputation and the training phases. An extensive empirical study demonstrates that GBP achieves state-of-the-art performance with significantly less training/testing time. Most notably, GBP can deliver superior performance on a graph with over 60 million nodes and 1.8 billion edges in less than half an hour on a single machine.
A Human-Centered Dynamic Scheduling Architecture for Collaborative Application
Mar 03, 2021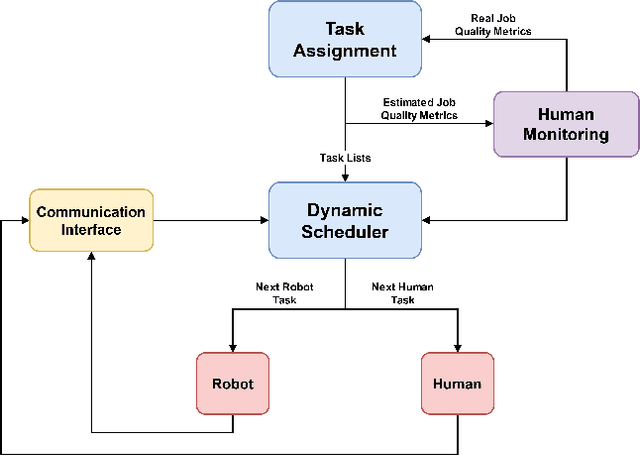
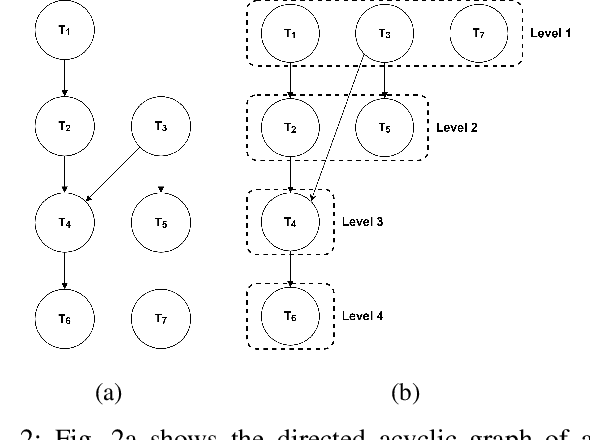
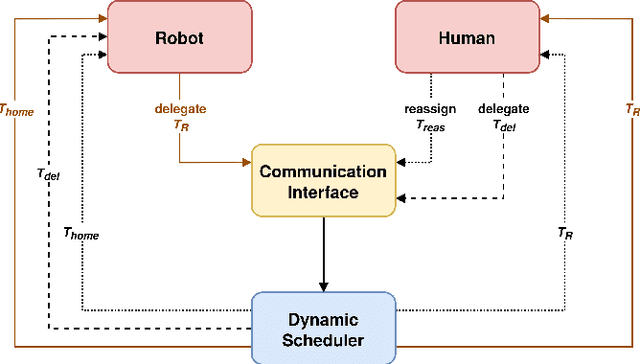

In collaborative robotic applications, human and robot have to work together during a whole shift for executing a sequence of jobs. The performance of the human robot team can be enhanced by scheduling the right tasks to the human and the robot. The scheduling should consider the task execution constraints, the variability in the task execution by the human, and the job quality of the human. Therefore, it is necessary to dynamically schedule the assigned tasks. In this paper, we propose a two-layered architecture for task allocation and scheduling in a collaborative cell. Job quality is explicitly considered during the allocation of the tasks and over a sequence of jobs. The tasks are dynamically scheduled based on the real time monitoring of the human's activities. The effectiveness of the proposed architecture is experimentally validated.
Dynamic Traffic Modeling From Overhead Imagery
Dec 18, 2020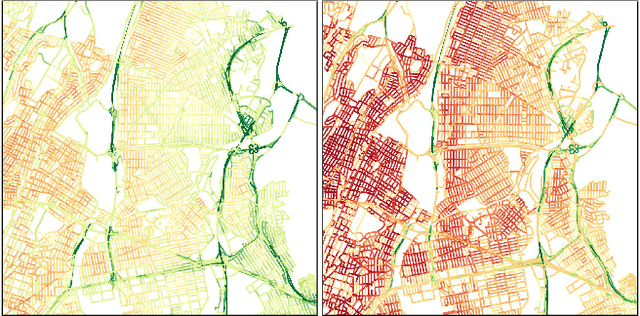
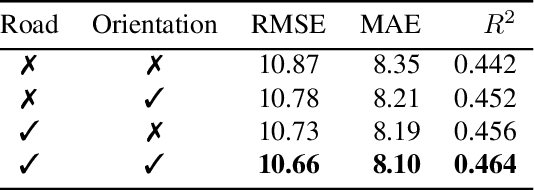
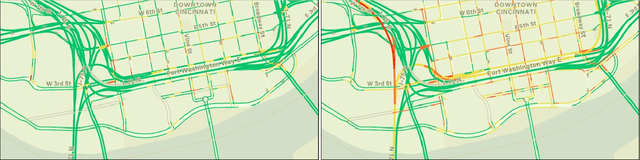
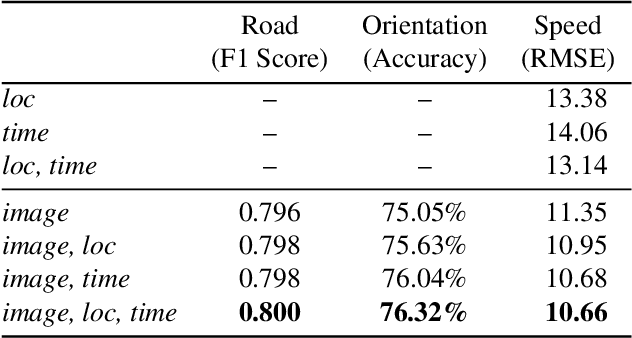
Our goal is to use overhead imagery to understand patterns in traffic flow, for instance answering questions such as how fast could you traverse Times Square at 3am on a Sunday. A traditional approach for solving this problem would be to model the speed of each road segment as a function of time. However, this strategy is limited in that a significant amount of data must first be collected before a model can be used and it fails to generalize to new areas. Instead, we propose an automatic approach for generating dynamic maps of traffic speeds using convolutional neural networks. Our method operates on overhead imagery, is conditioned on location and time, and outputs a local motion model that captures likely directions of travel and corresponding travel speeds. To train our model, we take advantage of historical traffic data collected from New York City. Experimental results demonstrate that our method can be applied to generate accurate city-scale traffic models.
On TasNet for Low-Latency Single-Speaker Speech Enhancement
Mar 27, 2021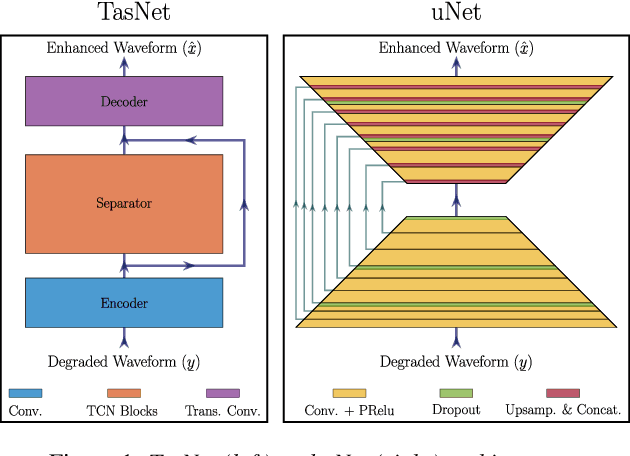
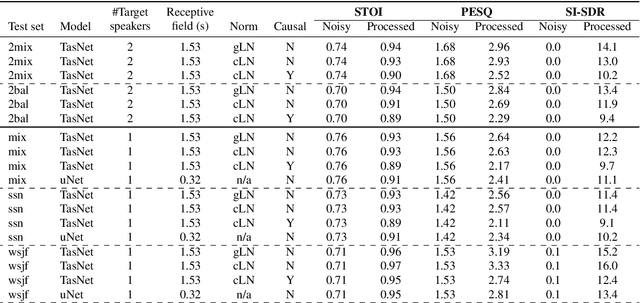
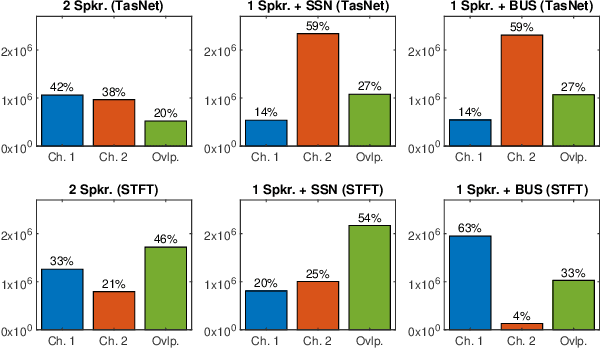
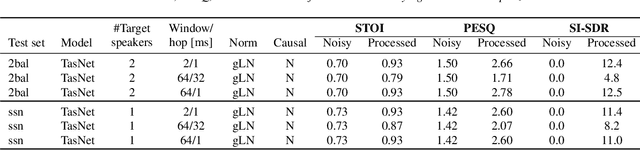
In recent years, speech processing algorithms have seen tremendous progress primarily due to the deep learning renaissance. This is especially true for speech separation where the time-domain audio separation network (TasNet) has led to significant improvements. However, for the related task of single-speaker speech enhancement, which is of obvious importance, it is yet unknown, if the TasNet architecture is equally successful. In this paper, we show that TasNet improves state-of-the-art also for speech enhancement, and that the largest gains are achieved for modulated noise sources such as speech. Furthermore, we show that TasNet learns an efficient inner-domain representation, where target and noise signal components are highly separable. This is especially true for noise in terms of interfering speech signals, which might explain why TasNet performs so well on the separation task. Additionally, we show that TasNet performs poorly for large frame hops and conjecture that aliasing might be the main cause of this performance drop. Finally, we show that TasNet consistently outperforms a state-of-the-art single-speaker speech enhancement system.