 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn TasNet for Low-Latency Single-Speaker Speech Enhancement
Mar 27, 2021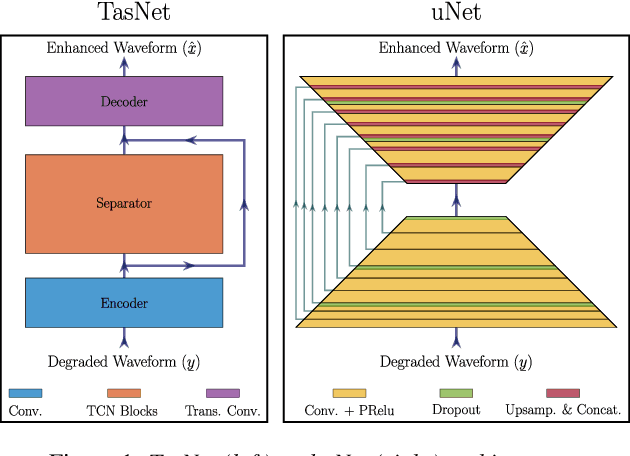
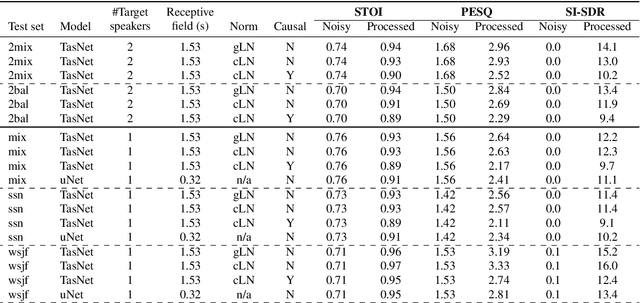
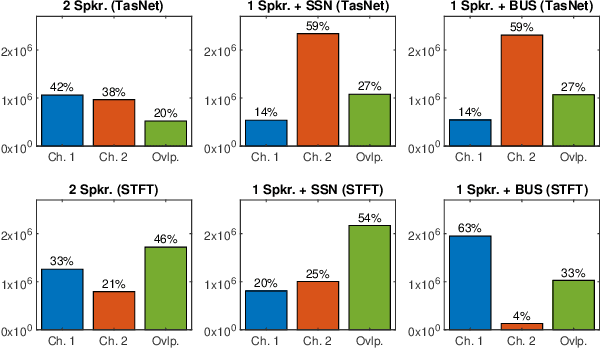
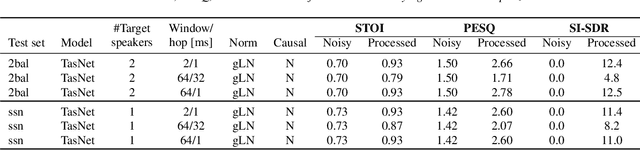
In recent years, speech processing algorithms have seen tremendous progress primarily due to the deep learning renaissance. This is especially true for speech separation where the time-domain audio separation network (TasNet) has led to significant improvements. However, for the related task of single-speaker speech enhancement, which is of obvious importance, it is yet unknown, if the TasNet architecture is equally successful. In this paper, we show that TasNet improves state-of-the-art also for speech enhancement, and that the largest gains are achieved for modulated noise sources such as speech. Furthermore, we show that TasNet learns an efficient inner-domain representation, where target and noise signal components are highly separable. This is especially true for noise in terms of interfering speech signals, which might explain why TasNet performs so well on the separation task. Additionally, we show that TasNet performs poorly for large frame hops and conjecture that aliasing might be the main cause of this performance drop. Finally, we show that TasNet consistently outperforms a state-of-the-art single-speaker speech enhancement system.
On Loss Functions for Supervised Monaural Time-Domain Speech Enhancement
Sep 03, 2019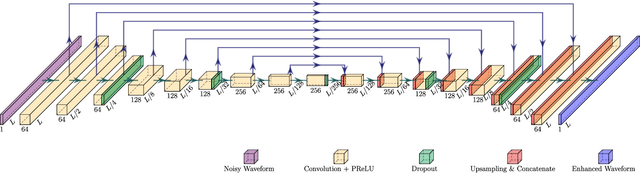
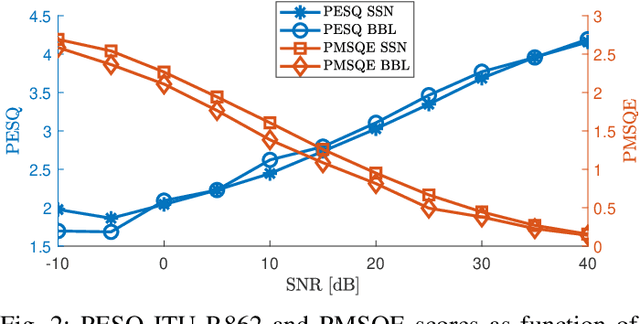
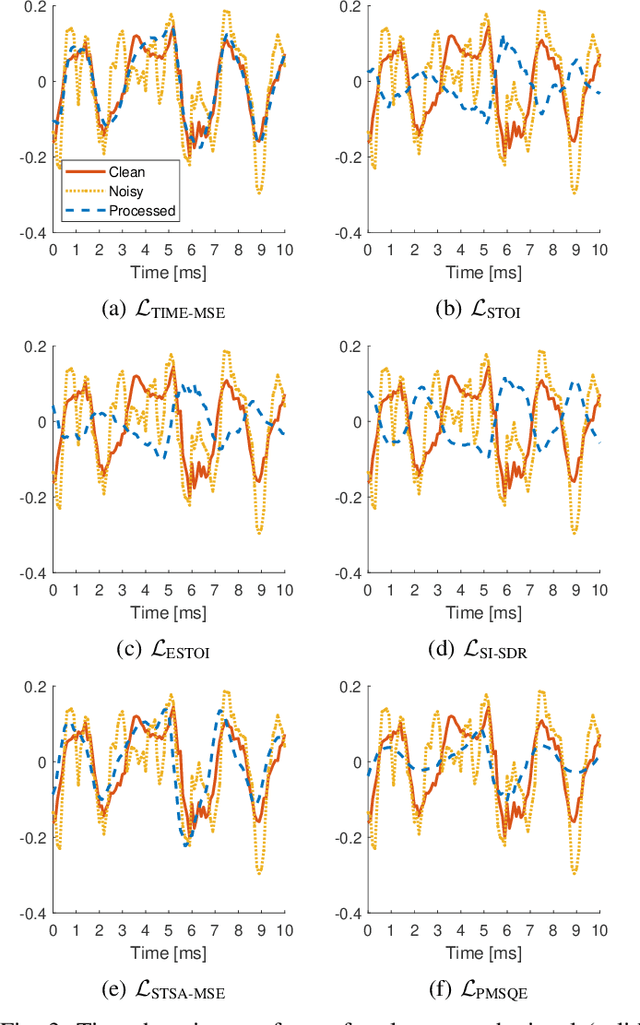

Many deep learning-based speech enhancement algorithms are designed to minimize the mean-square error (MSE) in some transform domain between a predicted and a target speech signal. However, optimizing for MSE does not necessarily guarantee high speech quality or intelligibility, which is the ultimate goal of many speech enhancement algorithms. Additionally, only little is known about the impact of the loss function on the emerging class of time-domain deep learning-based speech enhancement systems. We study how popular loss functions influence the performance of deep learning-based speech enhancement systems. First, we demonstrate that perceptually inspired loss functions might be advantageous if the receiver is the human auditory system. Furthermore, we show that the learning rate is a crucial design parameter even for adaptive gradient-based optimizers, which has been generally overlooked in the literature. Also, we found that waveform matching performance metrics must be used with caution as they in certain situations can fail completely. Finally, we show that a loss function based on scale-invariant signal-to-distortion ratio (SI-SDR) achieves good general performance across a range of popular speech enhancement evaluation metrics, which suggests that SI-SDR is a good candidate as a general-purpose loss function for speech enhancement systems.
Multi-talker Speech Separation with Utterance-level Permutation Invariant Training of Deep Recurrent Neural Networks
Jul 11, 2017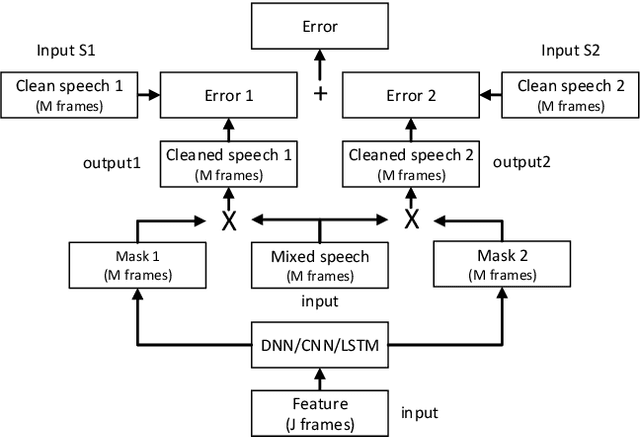
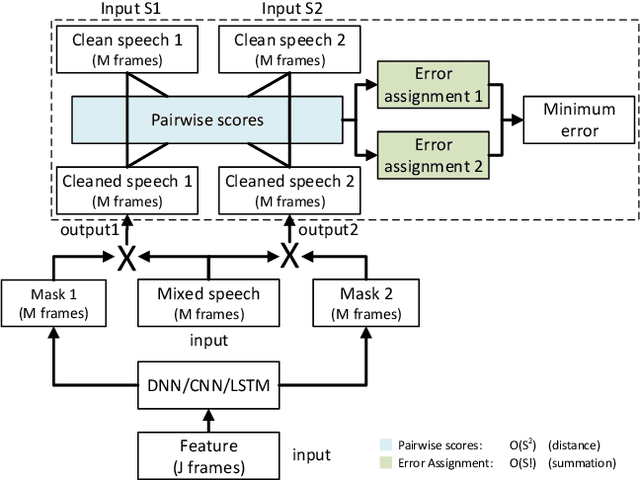
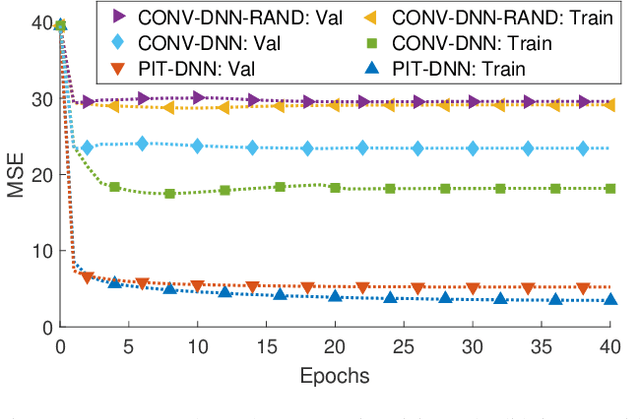
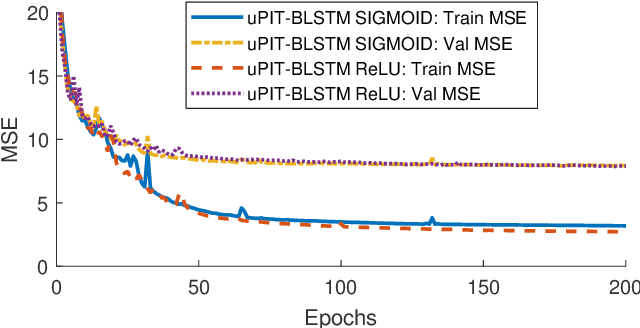
In this paper we propose the utterance-level Permutation Invariant Training (uPIT) technique. uPIT is a practically applicable, end-to-end, deep learning based solution for speaker independent multi-talker speech separation. Specifically, uPIT extends the recently proposed Permutation Invariant Training (PIT) technique with an utterance-level cost function, hence eliminating the need for solving an additional permutation problem during inference, which is otherwise required by frame-level PIT. We achieve this using Recurrent Neural Networks (RNNs) that, during training, minimize the utterance-level separation error, hence forcing separated frames belonging to the same speaker to be aligned to the same output stream. In practice, this allows RNNs, trained with uPIT, to separate multi-talker mixed speech without any prior knowledge of signal duration, number of speakers, speaker identity or gender. We evaluated uPIT on the WSJ0 and Danish two- and three-talker mixed-speech separation tasks and found that uPIT outperforms techniques based on Non-negative Matrix Factorization (NMF) and Computational Auditory Scene Analysis (CASA), and compares favorably with Deep Clustering (DPCL) and the Deep Attractor Network (DANet). Furthermore, we found that models trained with uPIT generalize well to unseen speakers and languages. Finally, we found that a single model, trained with uPIT, can handle both two-speaker, and three-speaker speech mixtures.
Permutation Invariant Training of Deep Models for Speaker-Independent Multi-talker Speech Separation
Jan 03, 2017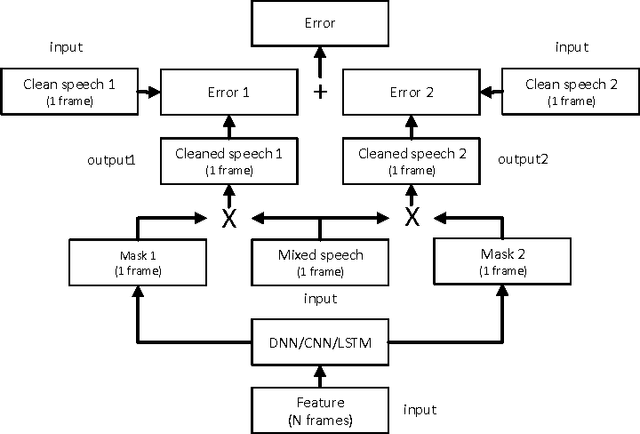
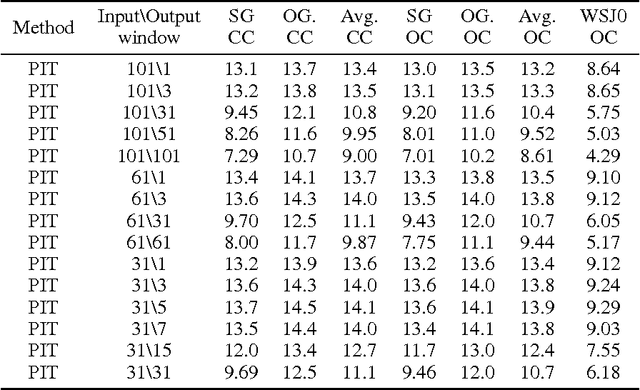
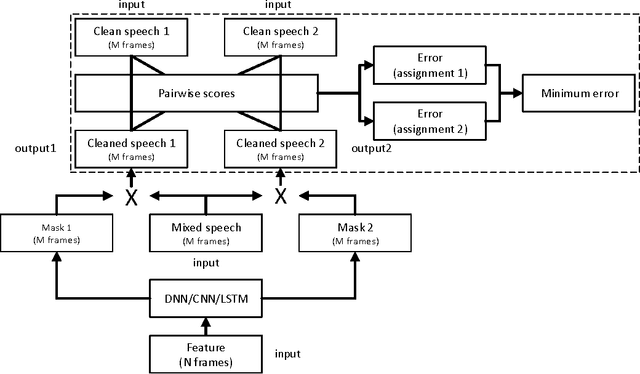
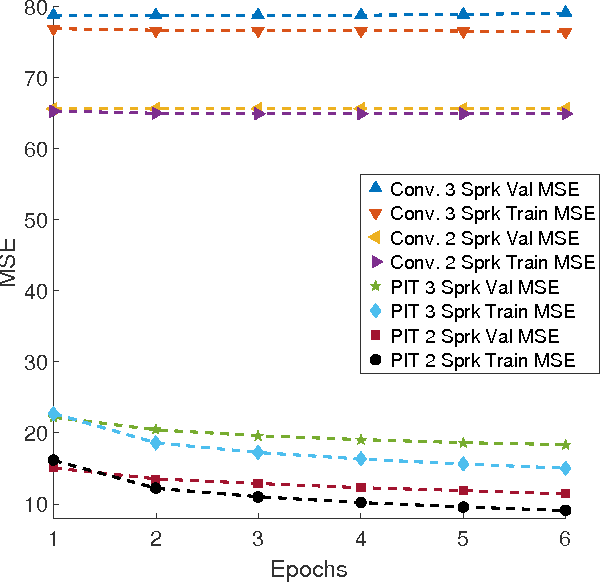
We propose a novel deep learning model, which supports permutation invariant training (PIT), for speaker independent multi-talker speech separation, commonly known as the cocktail-party problem. Different from most of the prior arts that treat speech separation as a multi-class regression problem and the deep clustering technique that considers it a segmentation (or clustering) problem, our model optimizes for the separation regression error, ignoring the order of mixing sources. This strategy cleverly solves the long-lasting label permutation problem that has prevented progress on deep learning based techniques for speech separation. Experiments on the equal-energy mixing setup of a Danish corpus confirms the effectiveness of PIT. We believe improvements built upon PIT can eventually solve the cocktail-party problem and enable real-world adoption of, e.g., automatic meeting transcription and multi-party human-computer interaction, where overlapping speech is common.