 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn TasNet for Low-Latency Single-Speaker Speech Enhancement
Mar 27, 2021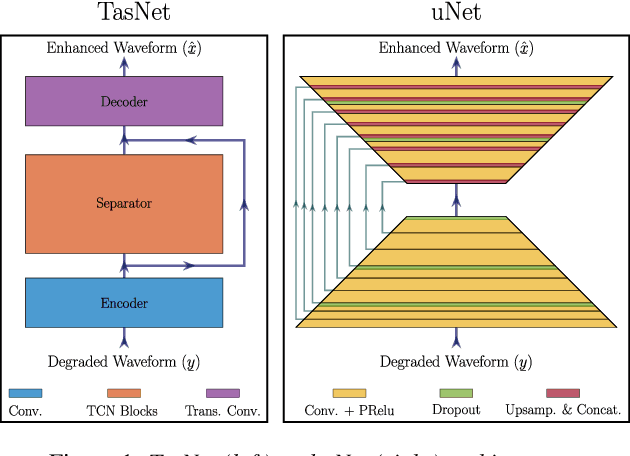
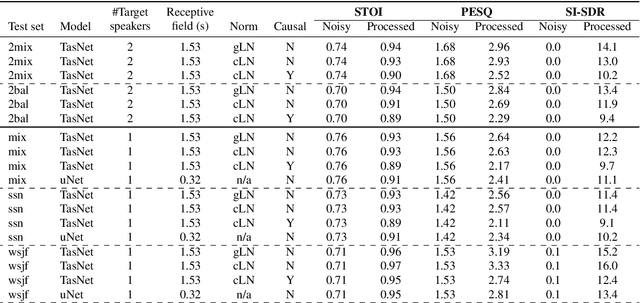
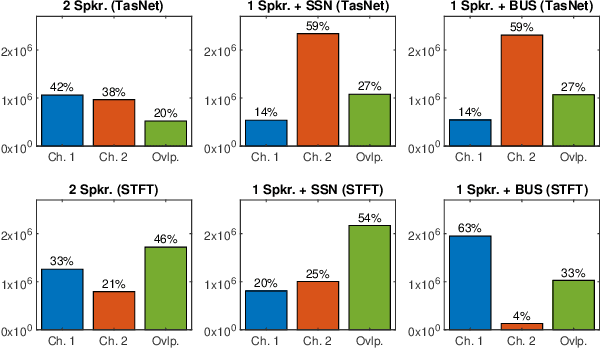
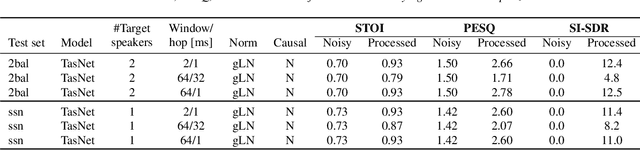
In recent years, speech processing algorithms have seen tremendous progress primarily due to the deep learning renaissance. This is especially true for speech separation where the time-domain audio separation network (TasNet) has led to significant improvements. However, for the related task of single-speaker speech enhancement, which is of obvious importance, it is yet unknown, if the TasNet architecture is equally successful. In this paper, we show that TasNet improves state-of-the-art also for speech enhancement, and that the largest gains are achieved for modulated noise sources such as speech. Furthermore, we show that TasNet learns an efficient inner-domain representation, where target and noise signal components are highly separable. This is especially true for noise in terms of interfering speech signals, which might explain why TasNet performs so well on the separation task. Additionally, we show that TasNet performs poorly for large frame hops and conjecture that aliasing might be the main cause of this performance drop. Finally, we show that TasNet consistently outperforms a state-of-the-art single-speaker speech enhancement system.
On Loss Functions for Supervised Monaural Time-Domain Speech Enhancement
Sep 03, 2019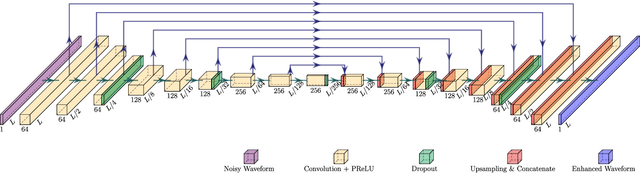
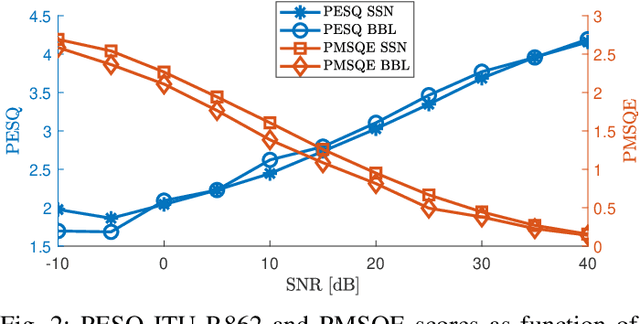
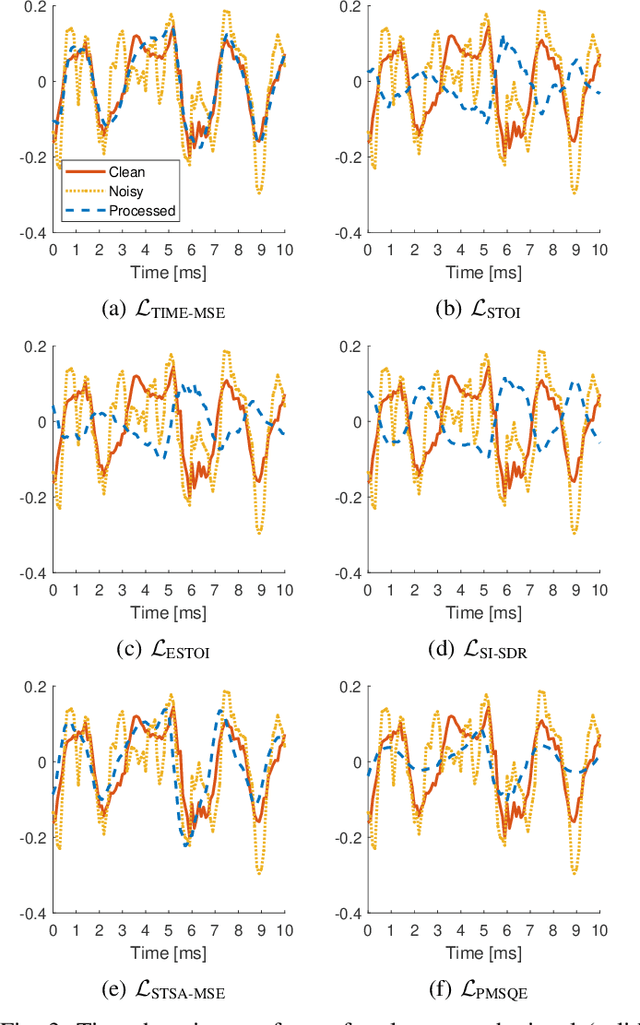

Many deep learning-based speech enhancement algorithms are designed to minimize the mean-square error (MSE) in some transform domain between a predicted and a target speech signal. However, optimizing for MSE does not necessarily guarantee high speech quality or intelligibility, which is the ultimate goal of many speech enhancement algorithms. Additionally, only little is known about the impact of the loss function on the emerging class of time-domain deep learning-based speech enhancement systems. We study how popular loss functions influence the performance of deep learning-based speech enhancement systems. First, we demonstrate that perceptually inspired loss functions might be advantageous if the receiver is the human auditory system. Furthermore, we show that the learning rate is a crucial design parameter even for adaptive gradient-based optimizers, which has been generally overlooked in the literature. Also, we found that waveform matching performance metrics must be used with caution as they in certain situations can fail completely. Finally, we show that a loss function based on scale-invariant signal-to-distortion ratio (SI-SDR) achieves good general performance across a range of popular speech enhancement evaluation metrics, which suggests that SI-SDR is a good candidate as a general-purpose loss function for speech enhancement systems.