 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HumAID: Human-Annotated Disaster Incidents Data from Twitter with Deep Learning Benchmarks
Apr 08, 2021
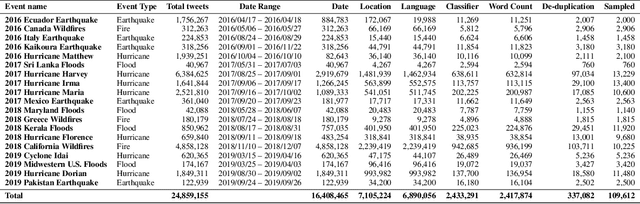
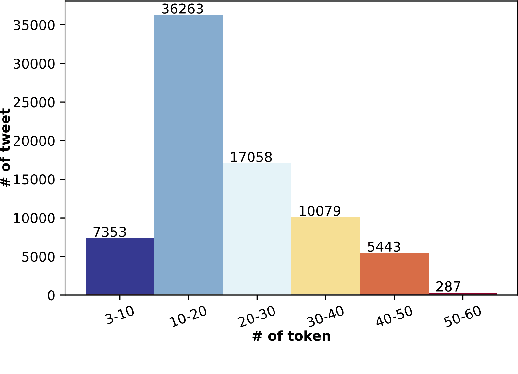
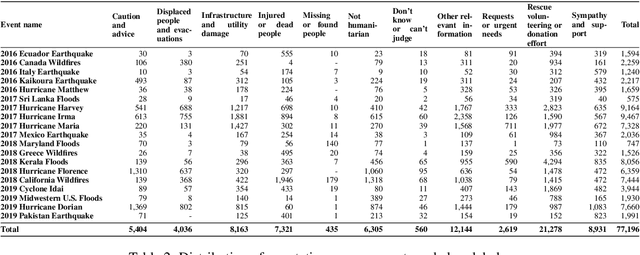
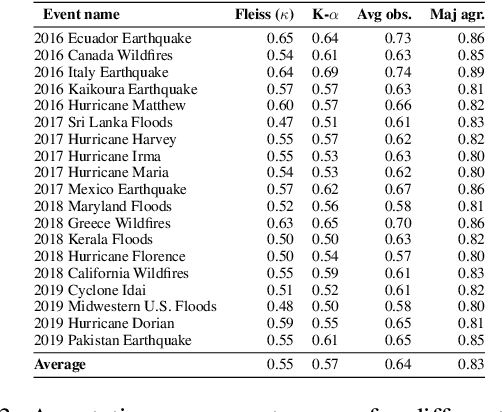
Social networks are widely used for information consumption and dissemination, especially during time-critical events such as natural disasters. Despite its significantly large volume, social media content is often too noisy for direct use in any application. Therefore, it is important to filter, categorize, and concisely summarize the available content to facilitate effective consumption and decision-making. To address such issues automatic classification systems have been developed using supervised modeling approaches, thanks to the earlier efforts on creating labeled datasets. However, existing datasets are limited in different aspects (e.g., size, contains duplicates) and less suitable to support more advanced and data-hungry deep learning models. In this paper, we present a new large-scale dataset with ~77K human-labeled tweets, sampled from a pool of ~24 million tweets across 19 disaster events that happened between 2016 and 2019. Moreover, we propose a data collection and sampling pipeline, which is important for social media data sampling for human annotation. We report multiclass classification results using classic and deep learning (fastText and transformer) based models to set the ground for future studies. The dataset and associated resources are publicly available. https://crisisnlp.qcri.org/humaid_dataset.html
Split Modeling for High-Dimensional Logistic Regression
Mar 12, 2021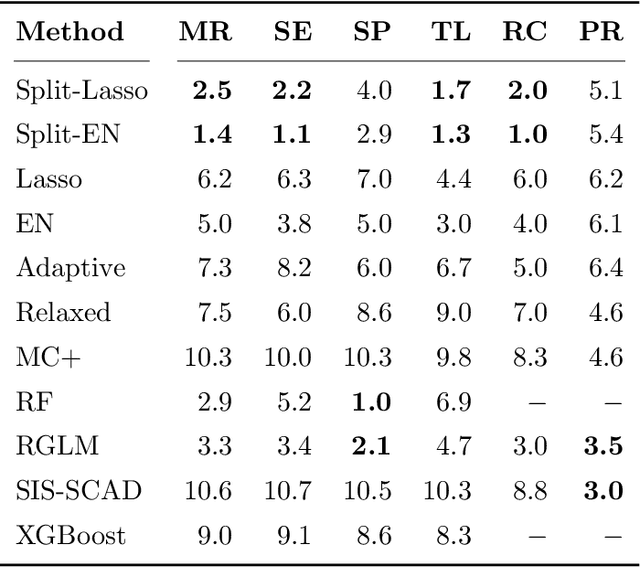
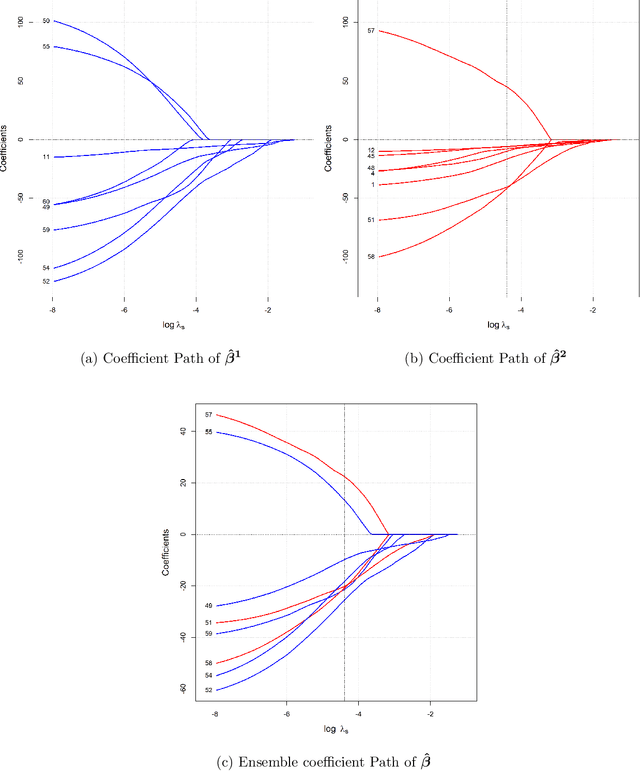
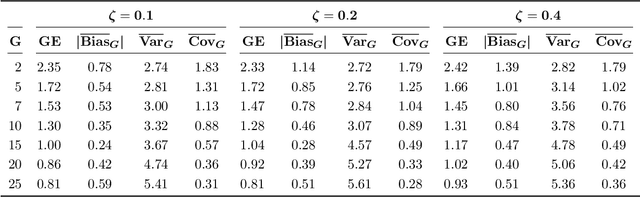
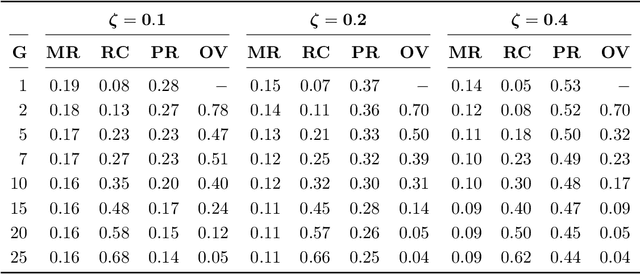
A novel method is proposed to learn an ensemble of logistic classification models in the context of high-dimensional binary classification. The models in the ensemble are built simultaneously by optimizing a multi-convex objective function. To enforce diversity between the models the objective function penalizes overlap between the models in the ensemble. We study the bias and variance of the individual models as well as their correlation and discuss how our method learns the ensemble by exploiting the accuracy-diversity trade-off for ensemble models. In contrast to other ensembling approaches, the resulting ensemble model is fully interpretable as a logistic regression model and at the same time yields excellent prediction accuracy as demonstrated in an extensive simulation study and gene expression data applications. An open-source compiled software library implementing the proposed method is briefly discussed.
Dory: Overcoming Barriers to Computing Persistent Homology
Mar 22, 2021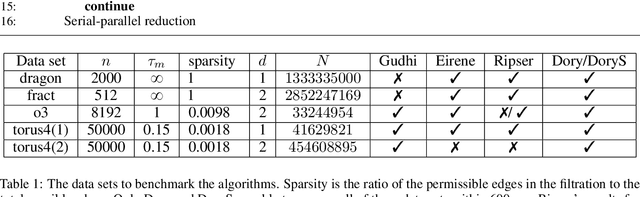
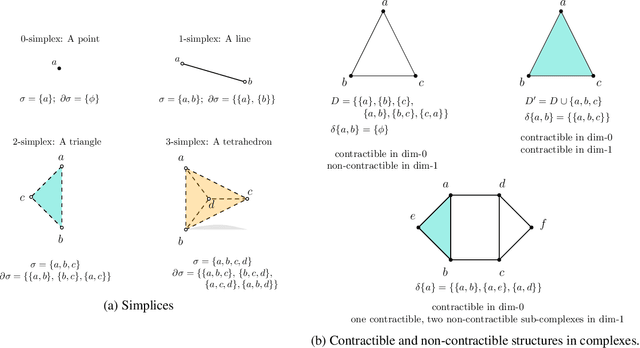
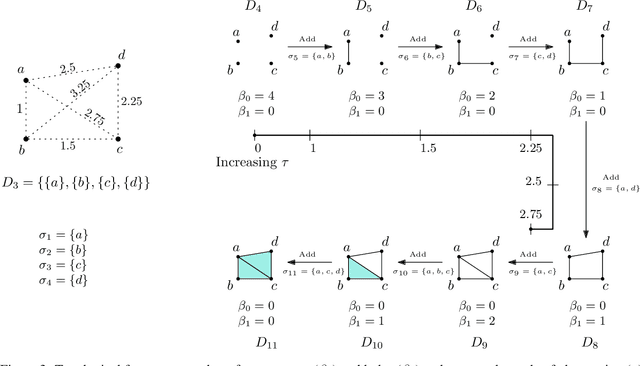
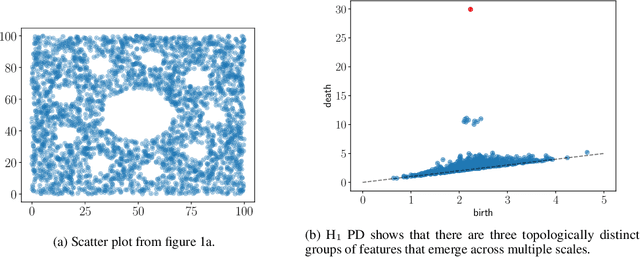
Persistent homology (PH) is an approach to topological data analysis (TDA) that computes multi-scale topologically invariant properties of high-dimensional data that are robust to noise. While PH has revealed useful patterns across various applications, computational requirements have limited applications to small data sets of a few thousand points. We present Dory, an efficient and scalable algorithm that can compute the persistent homology of large data sets. Dory uses significantly less memory than published algorithms and also provides significant reductions in the computation time compared to most algorithms. It scales to process data sets with millions of points. As an application, we compute the PH of the human genome at high resolution as revealed by a genome-wide Hi-C data set. Results show that the topology of the human genome changes significantly upon treatment with auxin, a molecule that degrades cohesin, corroborating the hypothesis that cohesin plays a crucial role in loop formation in DNA.
H-Net: Unsupervised Attention-based Stereo Depth Estimation Leveraging Epipolar Geometry
Apr 22, 2021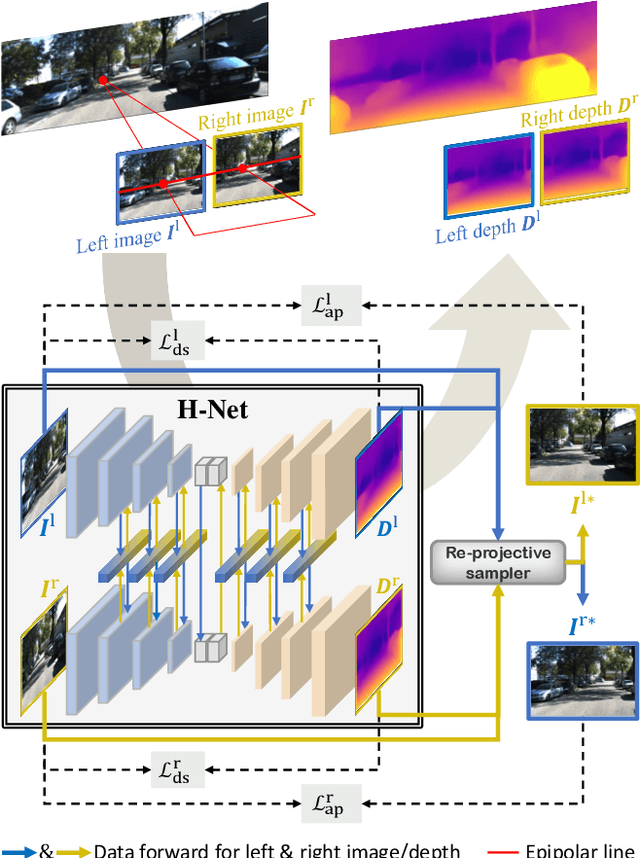
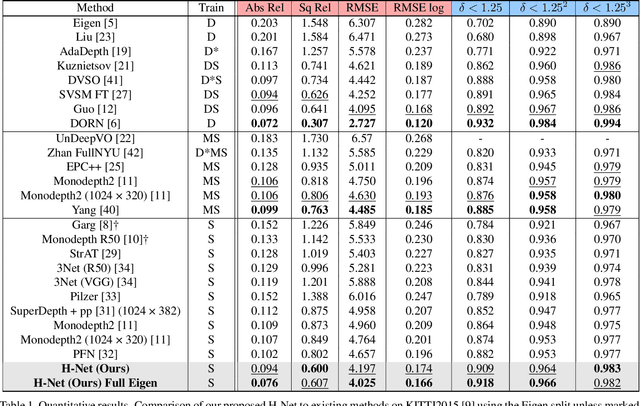
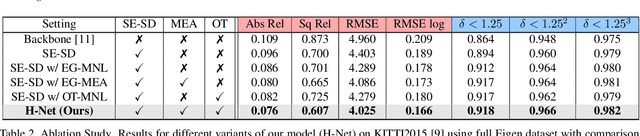
Depth estimation from a stereo image pair has become one of the most explored applications in computer vision, with most of the previous methods relying on fully supervised learning settings. However, due to the difficulty in acquiring accurate and scalable ground truth data, the training of fully supervised methods is challenging. As an alternative, self-supervised methods are becoming more popular to mitigate this challenge. In this paper, we introduce the H-Net, a deep-learning framework for unsupervised stereo depth estimation that leverages epipolar geometry to refine stereo matching. For the first time, a Siamese autoencoder architecture is used for depth estimation which allows mutual information between the rectified stereo images to be extracted. To enforce the epipolar constraint, the mutual epipolar attention mechanism has been designed which gives more emphasis to correspondences of features which lie on the same epipolar line while learning mutual information between the input stereo pair. Stereo correspondences are further enhanced by incorporating semantic information to the proposed attention mechanism. More specifically, the optimal transport algorithm is used to suppress attention and eliminate outliers in areas not visible in both cameras. Extensive experiments on KITTI2015 and Cityscapes show that our method outperforms the state-ofthe-art unsupervised stereo depth estimation methods while closing the gap with the fully supervised approaches.
Real-Time Energy Disaggregation of a Distribution Feeder's Demand Using Online Learning
May 04, 2018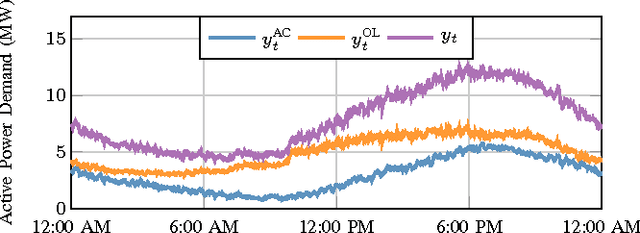
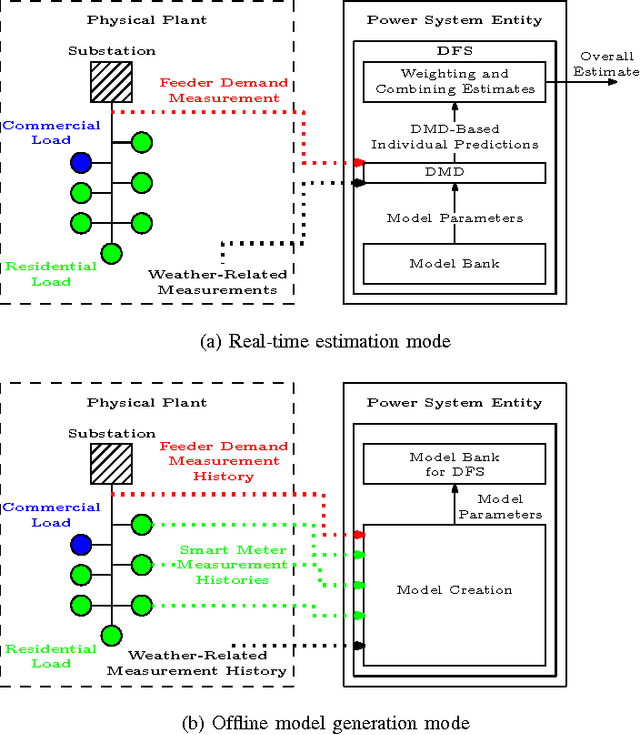
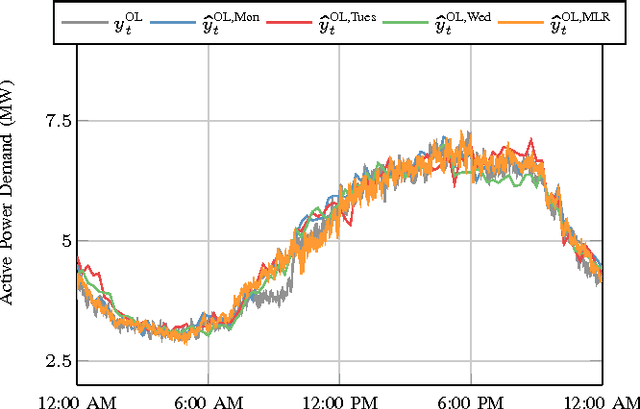
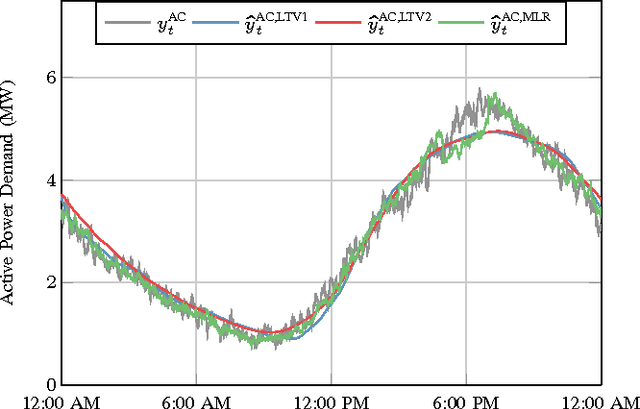
Though distribution system operators have been adding more sensors to their networks, they still often lack an accurate real-time picture of the behavior of distributed energy resources such as demand responsive electric loads and residential solar generation. Such information could improve system reliability, economic efficiency, and environmental impact. Rather than installing additional, costly sensing and communication infrastructure to obtain additional real-time information, it may be possible to use existing sensing capabilities and leverage knowledge about the system to reduce the need for new infrastructure. In this paper, we disaggregate a distribution feeder's demand measurements into: 1) the demand of a population of air conditioners, and 2) the demand of the remaining loads connected to the feeder. We use an online learning algorithm, Dynamic Fixed Share (DFS), that uses the real-time distribution feeder measurements as well as models generated from historical building- and device-level data. We develop two implementations of the algorithm and conduct case studies using real demand data from households and commercial buildings to investigate the effectiveness of the algorithm. The case studies demonstrate that DFS can effectively perform online disaggregation and the choice and construction of models included in the algorithm affects its accuracy, which is comparable to that of a set of Kalman filters.
Recent Advances in Adversarial Training for Adversarial Robustness
Feb 23, 2021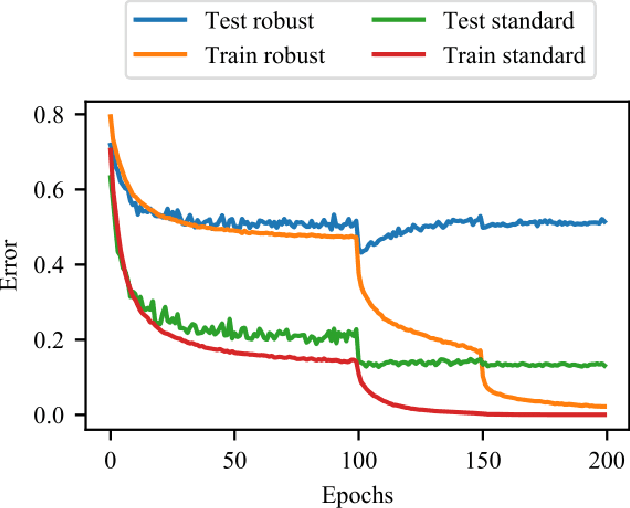
Adversarial training is one of the most effective approaches defending against adversarial examples for deep learning models. Unlike other defense strategies, adversarial training aims to promote the robustness of models intrinsically. During the last few years, adversarial training has been studied and discussed from various aspects. A variety of improvements and developments of adversarial training are proposed, which were, however, neglected in existing surveys. For the first time in this survey, we systematically review the recent progress on adversarial training for adversarial robustness with a novel taxonomy. Then we discuss the generalization problems in adversarial training from three perspectives. Finally, we highlight the challenges which are not fully tackled and present potential future directions.
A Simple Baseline for StyleGAN Inversion
Apr 15, 2021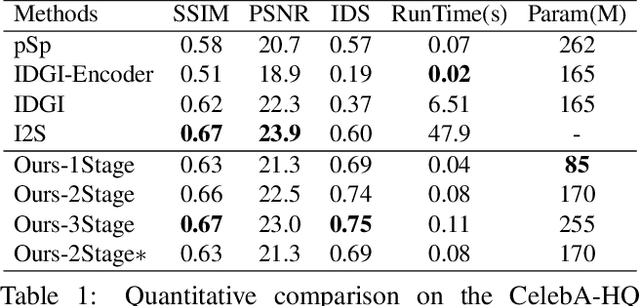
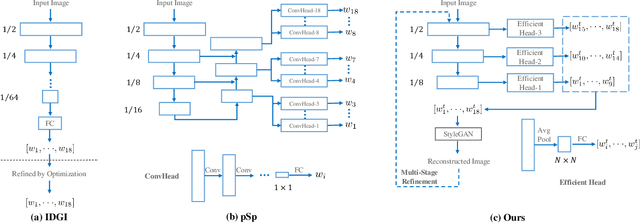
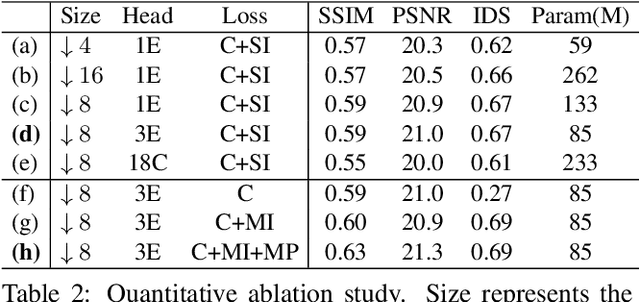

This paper studies the problem of StyleGAN inversion, which plays an essential role in enabling the pretrained StyleGAN to be used for real facial image editing tasks. This problem has the high demand for quality and efficiency. Existing optimization-based methods can produce high quality results, but the optimization often takes a long time. On the contrary, forward-based methods are usually faster but the quality of their results is inferior. In this paper, we present a new feed-forward network for StyleGAN inversion, with significant improvement in terms of efficiency and quality. In our inversion network, we introduce: 1) a shallower backbone with multiple efficient heads across scales; 2) multi-layer identity loss and multi-layer face parsing loss to the loss function; and 3) multi-stage refinement. Combining these designs together forms a simple and efficient baseline method which exploits all benefits of optimization-based and forward-based methods. Quantitative and qualitative results show that our method performs better than existing forward-based methods and comparably to state-of-the-art optimization-based methods, while maintaining the high efficiency as well as forward-based methods. Moreover, a number of real image editing applications demonstrate the efficacy of our method. Our project page is ~\url{https://wty-ustc.github.io/inversion}.
Online Caching with Optimal Switching Regret
Jan 18, 2021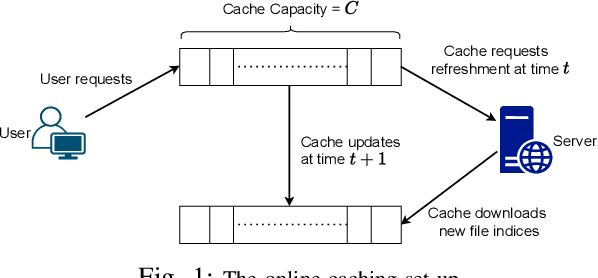
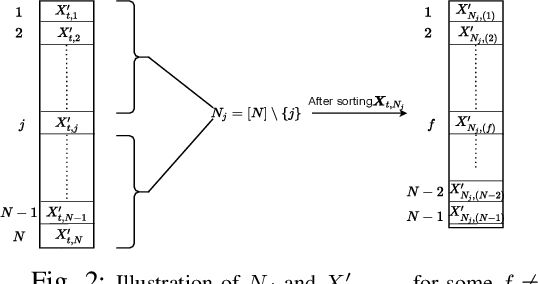
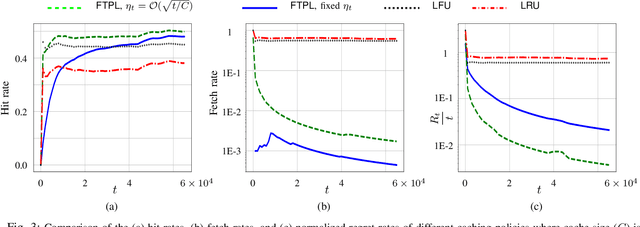
We consider the classical uncoded caching problem from an online learning point-of-view. A cache of limited storage capacity can hold $C$ files at a time from a large catalog. A user requests an arbitrary file from the catalog at each time slot. Before the file request from the user arrives, a caching policy populates the cache with any $C$ files of its choice. In the case of a cache-hit, the policy receives a unit reward and zero rewards otherwise. In addition to that, there is a cost associated with fetching files to the cache, which we refer to as the switching cost. The objective is to design a caching policy that incurs minimal regret while considering both the rewards due to cache-hits and the switching cost due to the file fetches. The main contribution of this paper is the switching regret analysis of a Follow the Perturbed Leader-based anytime caching policy, which is shown to have an order optimal switching regret. In this pursuit, we improve the best-known switching regret bound for this problem by a factor of $\Theta(\sqrt{C}).$ We conclude the paper by comparing the performance of different popular caching policies using a publicly available trace from a commercial CDN server.
Robust Motion In-betweening
Feb 09, 2021

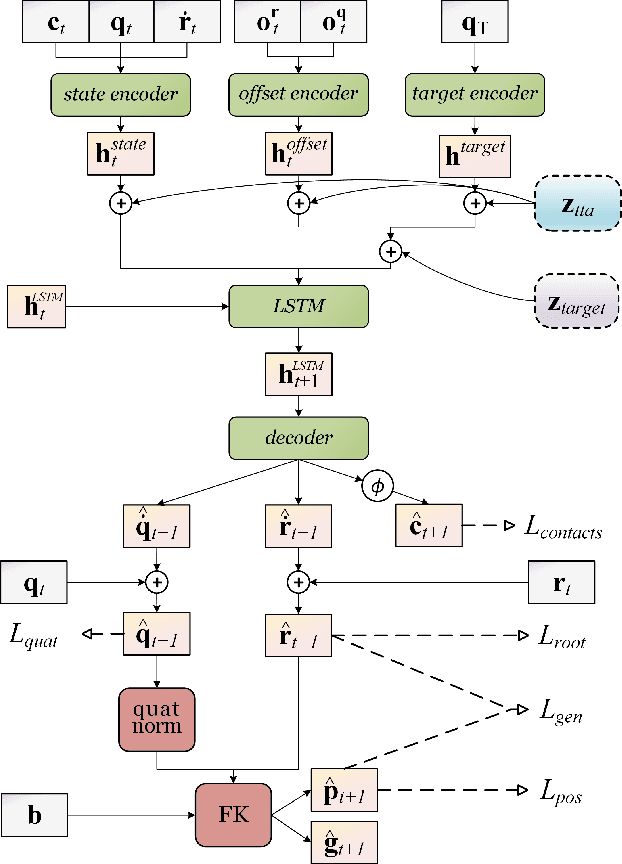
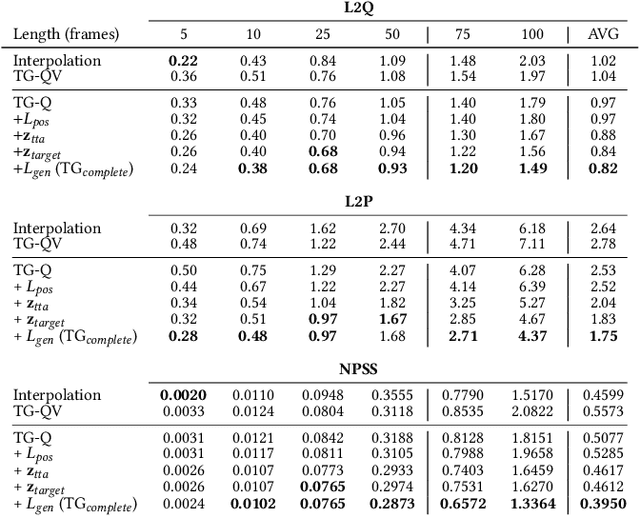
In this work we present a novel, robust transition generation technique that can serve as a new tool for 3D animators, based on adversarial recurrent neural networks. The system synthesizes high-quality motions that use temporally-sparse keyframes as animation constraints. This is reminiscent of the job of in-betweening in traditional animation pipelines, in which an animator draws motion frames between provided keyframes. We first show that a state-of-the-art motion prediction model cannot be easily converted into a robust transition generator when only adding conditioning information about future keyframes. To solve this problem, we then propose two novel additive embedding modifiers that are applied at each timestep to latent representations encoded inside the network's architecture. One modifier is a time-to-arrival embedding that allows variations of the transition length with a single model. The other is a scheduled target noise vector that allows the system to be robust to target distortions and to sample different transitions given fixed keyframes. To qualitatively evaluate our method, we present a custom MotionBuilder plugin that uses our trained model to perform in-betweening in production scenarios. To quantitatively evaluate performance on transitions and generalizations to longer time horizons, we present well-defined in-betweening benchmarks on a subset of the widely used Human3.6M dataset and on LaFAN1, a novel high quality motion capture dataset that is more appropriate for transition generation. We are releasing this new dataset along with this work, with accompanying code for reproducing our baseline results.
Generative Adversarial Networks (GAN) Powered Fast Magnetic Resonance Imaging -- Mini Review, Comparison and Perspectives
May 04, 2021
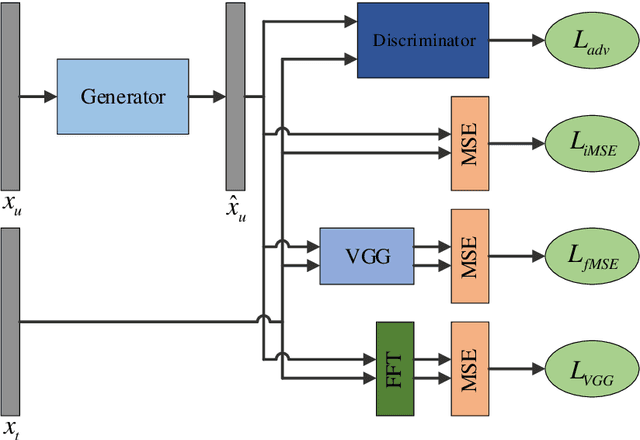
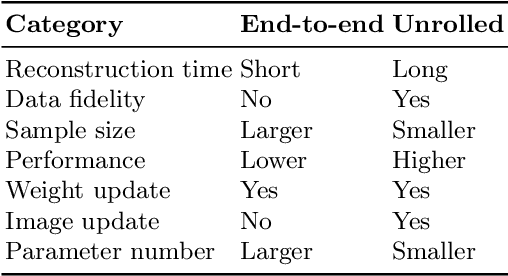
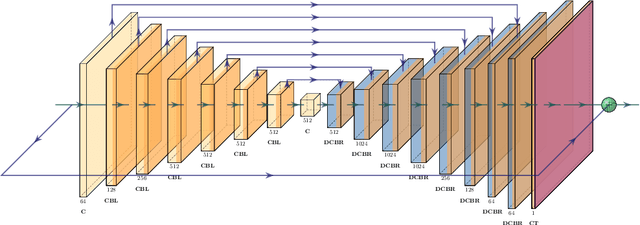
Magnetic Resonance Imaging (MRI) is a vital component of medical imaging. When compared to other image modalities, it has advantages such as the absence of radiation, superior soft tissue contrast, and complementary multiple sequence information. However, one drawback of MRI is its comparatively slow scanning and reconstruction compared to other image modalities, limiting its usage in some clinical applications when imaging time is critical. Traditional compressive sensing based MRI (CS-MRI) reconstruction can speed up MRI acquisition, but suffers from a long iterative process and noise-induced artefacts. Recently, Deep Neural Networks (DNNs) have been used in sparse MRI reconstruction models to recreate relatively high-quality images from heavily undersampled k-space data, allowing for much faster MRI scanning. However, there are still some hurdles to tackle. For example, directly training DNNs based on L1/L2 distance to the target fully sampled images could result in blurry reconstruction because L1/L2 loss can only enforce overall image or patch similarity and does not take into account local information such as anatomical sharpness. It is also hard to preserve fine image details while maintaining a natural appearance. More recently, Generative Adversarial Networks (GAN) based methods are proposed to solve fast MRI with enhanced image perceptual quality. The encoder obtains a latent space for the undersampling image, and the image is reconstructed by the decoder using the GAN loss. In this chapter, we review the GAN powered fast MRI methods with a comparative study on various anatomical datasets to demonstrate the generalisability and robustness of this kind of fast MRI while providing future perspectives.