 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Polynomial-time probabilistic reasoning with partial observations via implicit learning in probability logics
Jun 28, 2018
Standard approaches to probabilistic reasoning require that one possesses an explicit model of the distribution in question. But, the empirical learning of models of probability distributions from partial observations is a problem for which efficient algorithms are generally not known. In this work we consider the use of bounded-degree fragments of the "sum-of-squares" logic as a probability logic. Prior work has shown that we can decide refutability for such fragments in polynomial-time. We propose to use such fragments to answer queries about whether a given probability distribution satisfies a given system of constraints and bounds on expected values. We show that in answering such queries, such constraints and bounds can be implicitly learned from partial observations in polynomial-time as well. It is known that this logic is capable of deriving many bounds that are useful in probabilistic analysis. We show here that it furthermore captures useful polynomial-time fragments of resolution. Thus, these fragments are also quite expressive.
TAD: Trigger Approximation based Black-box Trojan Detection for AI
Feb 24, 2021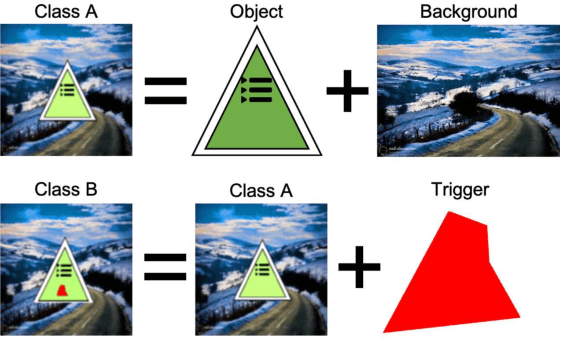

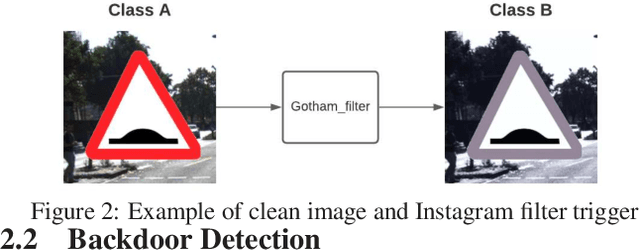
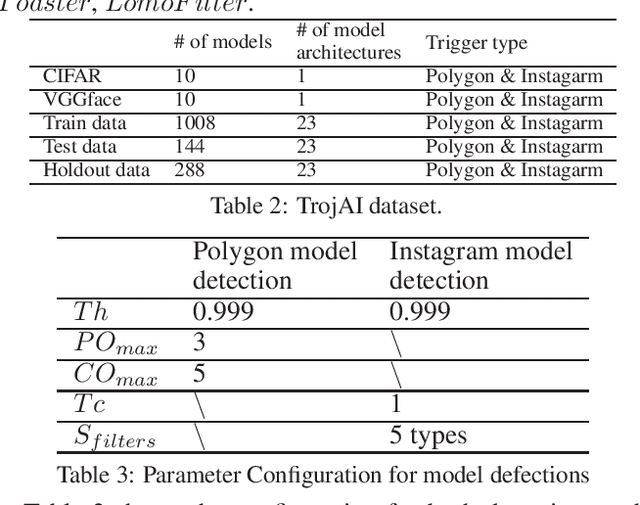
An emerging amount of intelligent applications have been developed with the surge of Machine Learning (ML). Deep Neural Networks (DNNs) have demonstrated unprecedented performance across various fields such as medical diagnosis and autonomous driving. While DNNs are widely employed in security-sensitive fields, they are identified to be vulnerable to Neural Trojan (NT) attacks that are controlled and activated by the stealthy trigger. We call this vulnerable model adversarial artificial intelligence (AI). In this paper, we target to design a robust Trojan detection scheme that inspects whether a pre-trained AI model has been Trojaned before its deployment. Prior works are oblivious of the intrinsic property of trigger distribution and try to reconstruct the trigger pattern using simple heuristics, i.e., stimulating the given model to incorrect outputs. As a result, their detection time and effectiveness are limited. We leverage the observation that the pixel trigger typically features spatial dependency and propose TAD, the first trigger approximation based Trojan detection framework that enables fast and scalable search of the trigger in the input space. Furthermore, TAD can also detect Trojans embedded in the feature space where certain filter transformations are used to activate the Trojan. We perform extensive experiments to investigate the performance of the TAD across various datasets and ML models. Empirical results show that TAD achieves a ROC-AUC score of 0:91 on the public TrojAI dataset 1 and the average detection time per model is 7:1 minutes.
PAFNet: An Efficient Anchor-Free Object Detector Guidance
Apr 28, 2021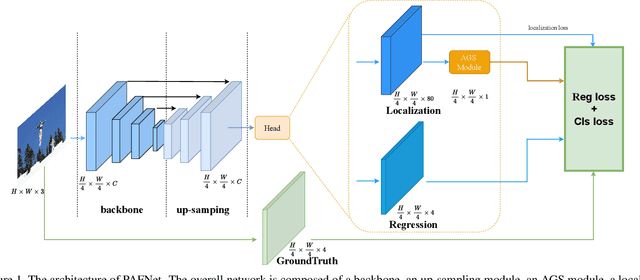
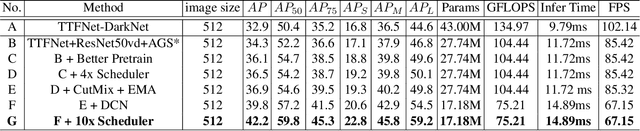
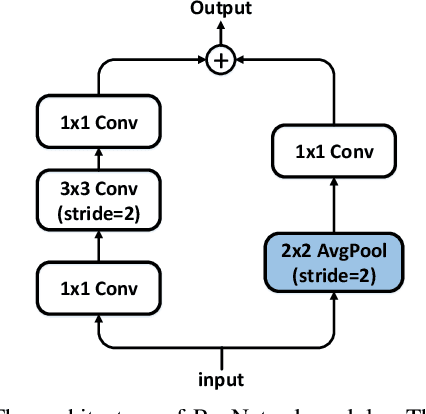

Object detection is a basic but challenging task in computer vision, which plays a key role in a variety of industrial applications. However, object detectors based on deep learning usually require greater storage requirements and longer inference time, which hinders its practicality seriously. Therefore, a trade-off between effectiveness and efficiency is necessary in practical scenarios. Considering that without constraint of pre-defined anchors, anchor-free detectors can achieve acceptable accuracy and inference speed simultaneously. In this paper, we start from an anchor-free detector called TTFNet, modify the structure of TTFNet and introduce multiple existing tricks to realize effective server and mobile solutions respectively. Since all experiments in this paper are conducted based on PaddlePaddle, we call the model as PAFNet(Paddle Anchor Free Network). For server side, PAFNet can achieve a better balance between effectiveness (42.2% mAP) and efficiency (67.15 FPS) on a single V100 GPU. For moblie side, PAFNet-lite can achieve a better accuracy of (23.9% mAP) and 26.00 ms on Kirin 990 ARM CPU, outperforming the existing state-of-the-art anchor-free detectors by significant margins. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Tracking and Visualizing Signs of Degradation for an Early Failure Prediction of a Rolling Bearing
Nov 18, 2020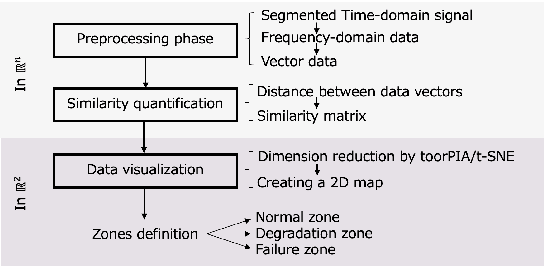

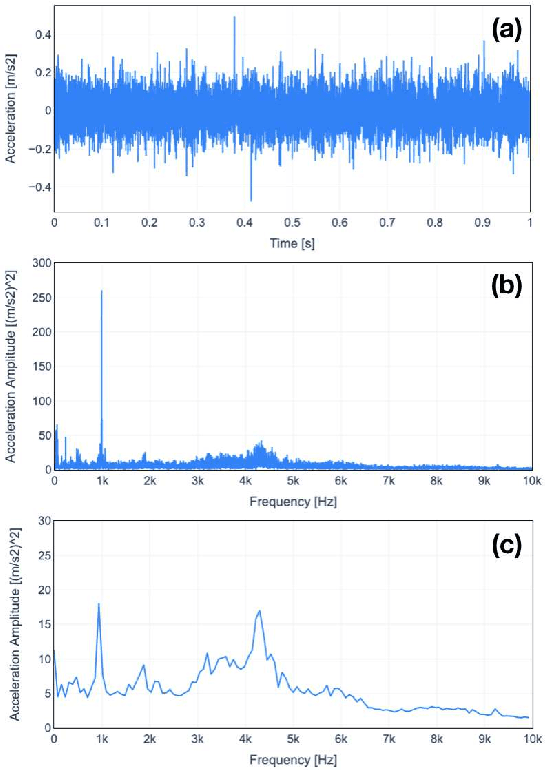
Predictive maintenance, i.e. predicting failure to be few steps ahead of the fault, is one of the pillars of Industry 4.0. An effective method for that is to track early signs of degradation before a failure happens. This paper presents an innovative failure predictive scheme for machines. The proposed scheme combines the use of full spectrum of the vibration data caused by the machines and data visualization technologies. This scheme is featured by no training data required and by quick start after installation. First, we propose to use full spectrum (as high-dimensional data vector) with no cropping and no complex feature extraction and to visualize data behavior by mapping the high dimensional vectors into a 2D map. We then can ensure the simplicity of process and less possibility of overlooking of important information as well as providing a human-friendly and human-understandable output. Second, we propose Real-Time Data Tracker (RTDT) which predicts the failure at an appropriate time with sufficient time for maintenance by plotting real-time frequency spectrum data of the target machine on the 2D map composed from normal data. Third, we show the test results of our proposal using vibration data of bearings from real-world test-to-failure measurements provided by the public dataset, the IMS dataset.
Explanation as a Defense of Recommendation
Jan 24, 2021
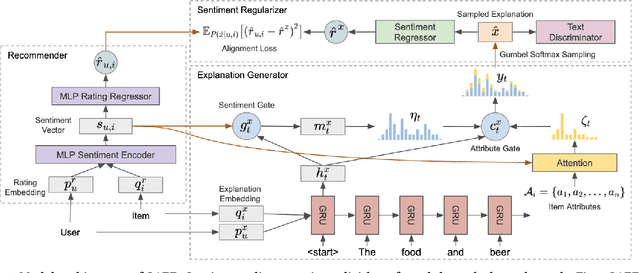
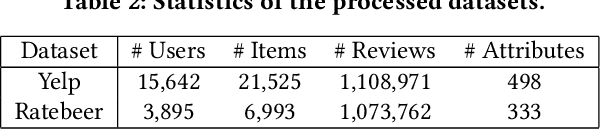
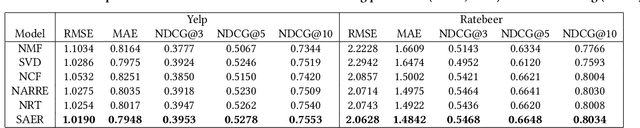
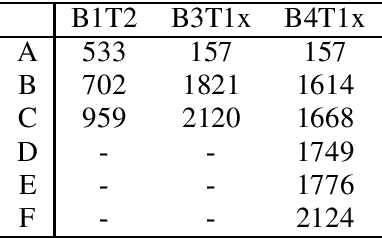
Textual explanations have proved to help improve user satisfaction on machine-made recommendations. However, current mainstream solutions loosely connect the learning of explanation with the learning of recommendation: for example, they are often separately modeled as rating prediction and content generation tasks. In this work, we propose to strengthen their connection by enforcing the idea of sentiment alignment between a recommendation and its corresponding explanation. At training time, the two learning tasks are joined by a latent sentiment vector, which is encoded by the recommendation module and used to make word choices for explanation generation. At both training and inference time, the explanation module is required to generate explanation text that matches sentiment predicted by the recommendation module. Extensive experiments demonstrate our solution outperforms a rich set of baselines in both recommendation and explanation tasks, especially on the improved quality of its generated explanations. More importantly, our user studies confirm our generated explanations help users better recognize the differences between recommended items and understand why an item is recommended.
Deep Learning-based Physical-Layer Secret Key Generation for FDD Systems
May 18, 2021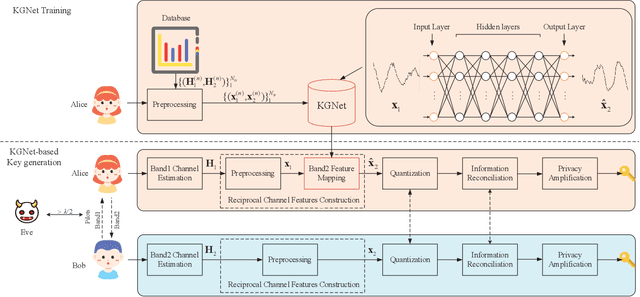
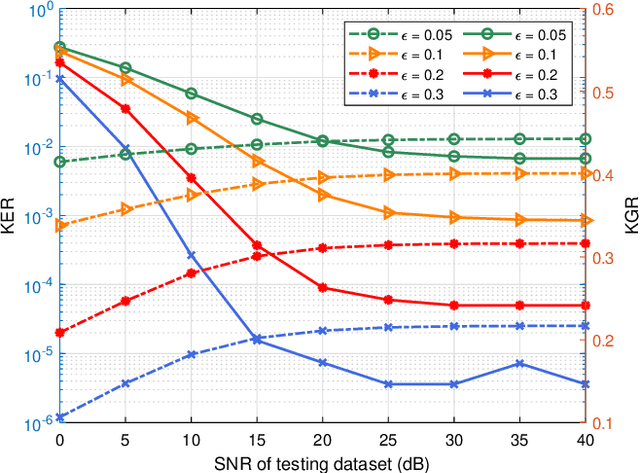
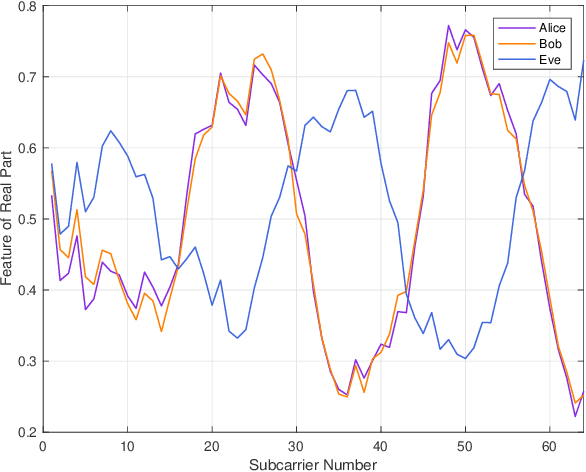
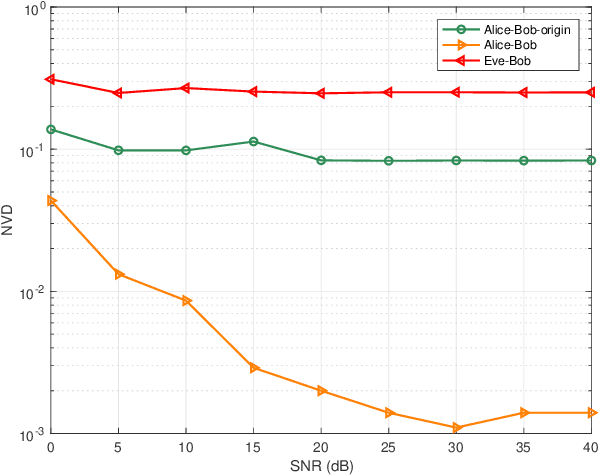
Physical-layer key generation (PKG) establishes cryptographic keys from highly correlated measurements of wireless channels, which relies on reciprocal channel characteristics between uplink and downlink, is a promising wireless security technique for Internet of Things (IoT). However, it is challenging to extract common features in frequency division duplexing (FDD) systems as uplink and downlink transmissions operate at different frequency bands whose channel frequency responses are not reciprocal any more. Existing PKG methods for FDD systems have many limitations, i.e., high overhead and security problems. This paper proposes a novel PKG scheme that uses the feature mapping function between different frequency bands obtained by deep learning to make two users generate highly similar channel features in FDD systems. In particular, this is the first time to apply deep learning for PKG in FDD systems. We first prove the existence of the band feature mapping function for a given environment and a feedforward network with a single hidden layer can approximate the mapping function. Then a Key Generation neural Network (KGNet) is proposed for reciprocal channel feature construction, and a key generation scheme based on the KGNet is also proposed. Numerical results verify the excellent performance of the KGNet-based key generation scheme in terms of randomness, key generation ratio, and key error rate, which proves that it is feasible to generate keys for FDD systems with lower overhead and more secure functions compared to existing methods.
Physically Based Neural Simulator for Garment Animation
Dec 21, 2020
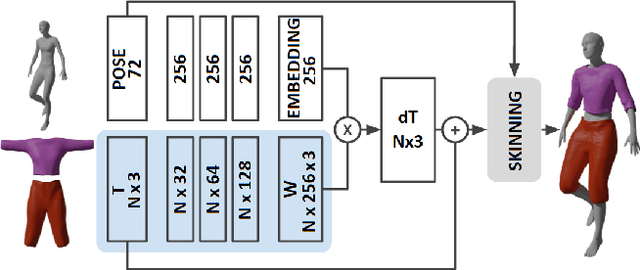

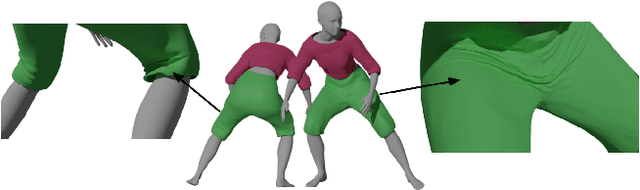
We present a novel approach to the cloth simulation problem in human-centric scenarios through deep learning. Computer graphics approaches rely on Physically Based Simulations (PBS) to animate clothes. These are general solutions that, given a sufficiently fine-grained discretization of space and time, can achieve highly realistic results. However, they are computationally expensive and any scene modification prompts the need of re-simulation. We propose using deep learning, formulated as an implicit PBS, to learn accurate cloth deformations in a constrained scenario: dressed humans. By using deep models, we can obtain high-resolution garments that can be efficiently deployed in real-time. Furthermore, we show it is possible to train these models in an amount of time comparable to a PBS of a few fixed sequences. To the best of our knowledge, we are the first to propose a neural simulator for cloth. Other deep-based approaches for cloth dynamics learn the distribution of huge volumes of simulated data. Therefore, these approaches require a great investment of computational resources for data gathering. Alternatively, data can be gathered through expensive 4D scans in constrained scenarios. With our proposed methodology, we completely skip the data gathering part while obtaining appealing results.
Backdoor Scanning for Deep Neural Networks through K-Arm Optimization
Feb 09, 2021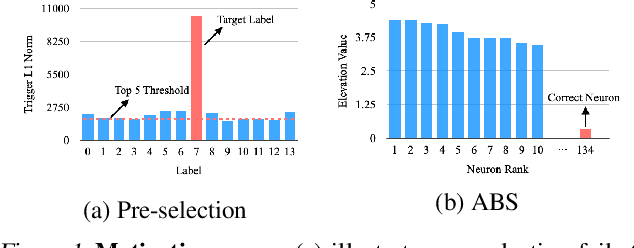
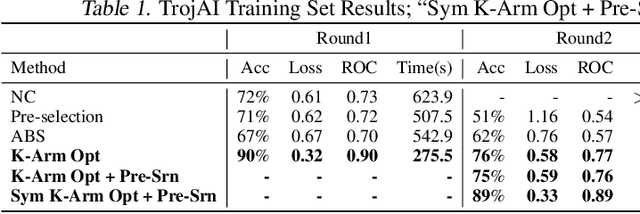
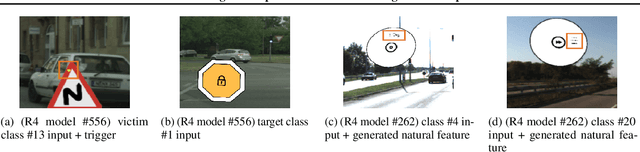

Back-door attack poses a severe threat to deep learning systems. It injects hidden malicious behaviors to a model such that any input stamped with a special pattern can trigger such behaviors. Detecting back-door is hence of pressing need. Many existing defense techniques use optimization to generate the smallest input pattern that forces the model to misclassify a set of benign inputs injected with the pattern to a target label. However, the complexity is quadratic to the number of class labels such that they can hardly handle models with many classes. Inspired by Multi-Arm Bandit in Reinforcement Learning, we propose a K-Arm optimization method for backdoor detection. By iteratively and stochastically selecting the most promising labels for optimization with the guidance of an objective function, we substantially reduce the complexity, allowing to handle models with many classes. Moreover, by iteratively refining the selection of labels to optimize, it substantially mitigates the uncertainty in choosing the right labels, improving detection accuracy. At the time of submission, the evaluation of our method on over 4000 models in the IARPA TrojAI competition from round 1 to the latest round 4 achieves top performance on the leaderboard. Our technique also supersedes three state-of-the-art techniques in terms of accuracy and the scanning time needed.
Scalable, End-to-End, Deep-Learning-Based Data Reconstruction Chain for Particle Imaging Detectors
Feb 01, 2021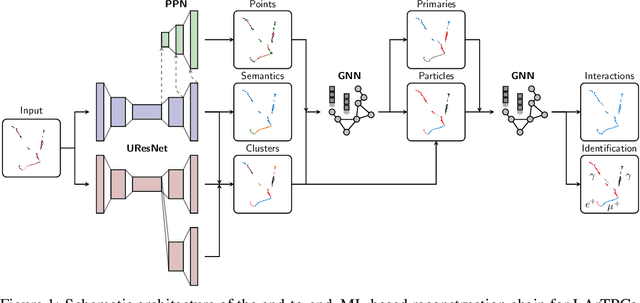
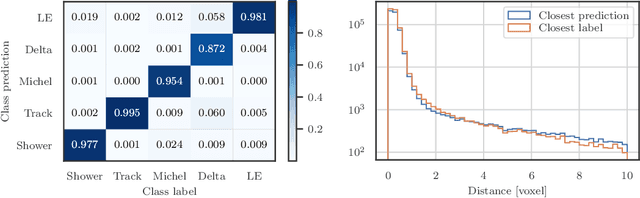
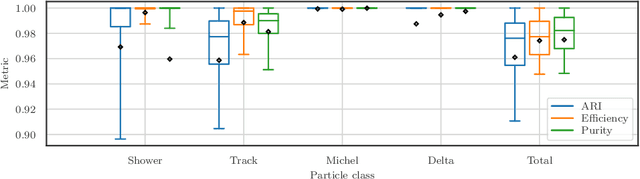
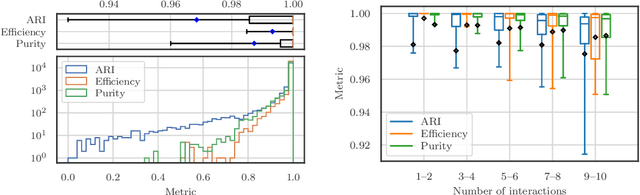
Recent inroads in Computer Vision (CV) and Machine Learning (ML) have motivated a new approach to the analysis of particle imaging detector data. Unlike previous efforts which tackled isolated CV tasks, this paper introduces an end-to-end, ML-based data reconstruction chain for Liquid Argon Time Projection Chambers (LArTPCs), the state-of-the-art in precision imaging at the intensity frontier of neutrino physics. The chain is a multi-task network cascade which combines voxel-level feature extraction using Sparse Convolutional Neural Networks and particle superstructure formation using Graph Neural Networks. Each algorithm incorporates physics-informed inductive biases, while their collective hierarchy is used to enforce a causal structure. The output is a comprehensive description of an event that may be used for high-level physics inference. The chain is end-to-end optimizable, eliminating the need for time-intensive manual software adjustments. It is also the first implementation to handle the unprecedented pile-up of dozens of high energy neutrino interactions, expected in the 3D-imaging LArTPC of the Deep Underground Neutrino Experiment. The chain is trained as a whole and its performance is assessed at each step using an open simulated data set.
Fundamental Performance Limits on Terahertz Wireless Links Imposed by Group Velocity Dispersion
Apr 01, 2021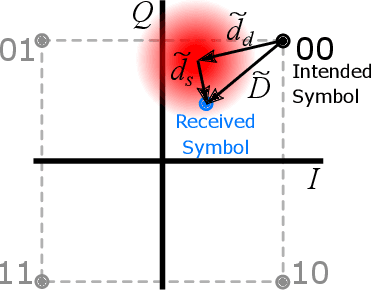
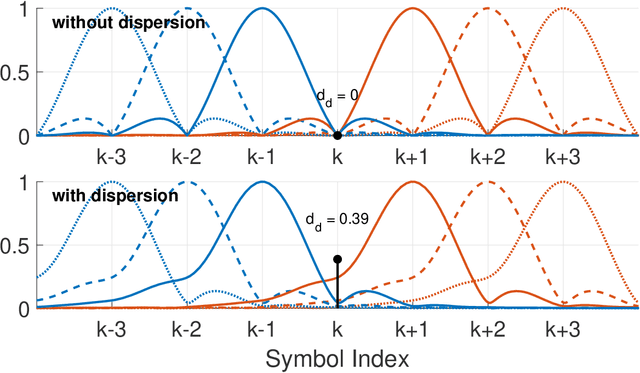
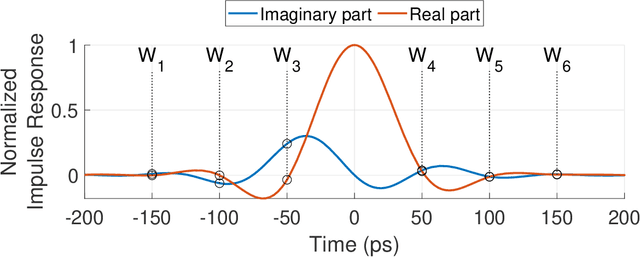
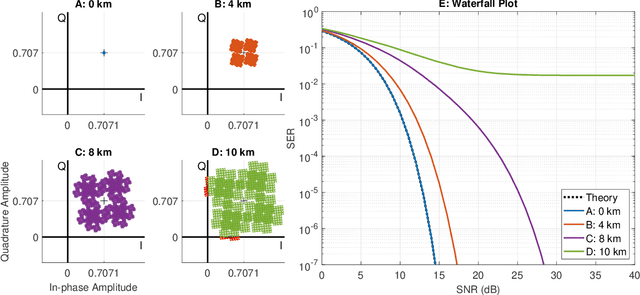
A theoretical framework and numerical simulations quantifying the impact of atmospheric group velocity dispersion on wireless terahertz communication link error rate were developed based upon experimental work. We present, for the first time, predictions of symbol error rate as a function of link distance, signal bandwidth, signal-to-noise ratio, and atmospheric conditions, revealing that long-distance, broadband terahertz communication systems may be limited by inter-symbol interference stemming from group velocity dispersion, rather than attenuation. In such dispersion limited links, increasing signal strength does not improve the symbol error rate and, consequently, theoretical predictions of symbol error rate based only on signal-to-noise ratio are invalid for the broadband case. This work establishes a new and necessary foundation for link budget analysis in future long-distance terahertz communication systems that accounts for the non-negligible effects of both attenuation and dispersion.