 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using Machine Intelligence to Prioritise Code Review Requests
Feb 11, 2021
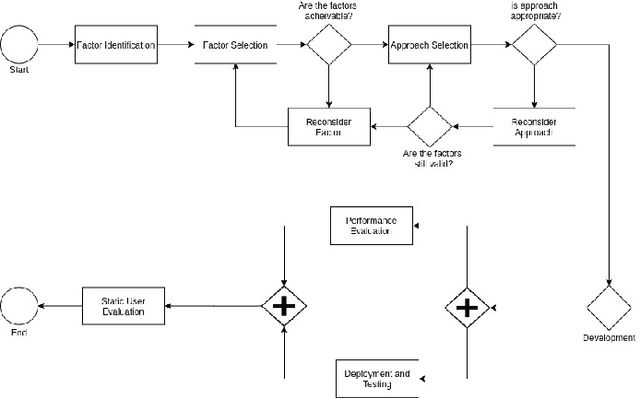
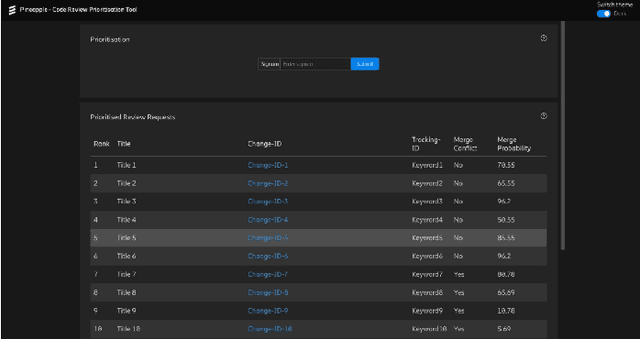
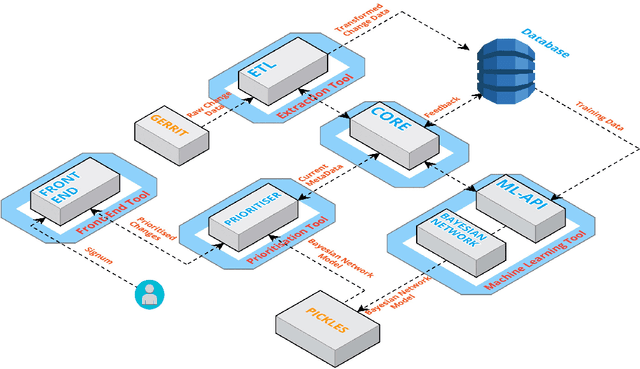
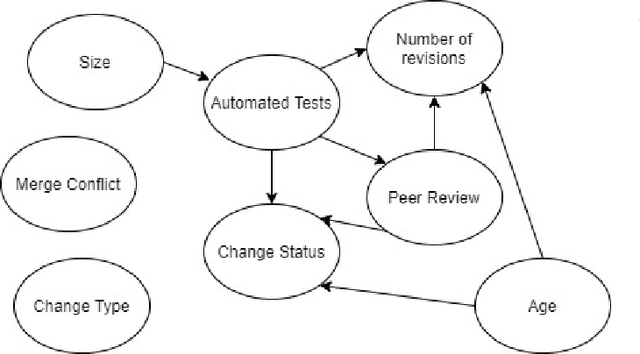
Modern Code Review (MCR) is the process of reviewing new code changes that need to be merged with an existing codebase. As a developer, one may receive many code review requests every day, i.e., the review requests need to be prioritised. Manually prioritising review requests is a challenging and time-consuming process. To address the above problem, we conducted an industrial case study at Ericsson aiming at developing a tool called Pineapple, which uses a Bayesian Network to prioritise code review requests. To validate our approach/tool, we deployed it in a live software development project at Ericsson, wherein more than 150 developers develop a telecommunication product. We focused on evaluating the predictive performance, feasibility, and usefulness of our approach. The results indicate that Pineapple has competent predictive performance (RMSE = 0.21 and MAE = 0.15). Furthermore, around 82.6% of Pineapple's users believe the tool can support code review request prioritisation by providing reliable results, and around 56.5% of the users believe it helps reducing code review lead time. As future work, we plan to evaluate Pineapple's predictive performance, usefulness, and feasibility through a longitudinal investigation.
Scaling up Memory-Efficient Formal Verification Tools for Tree Ensembles
May 06, 2021
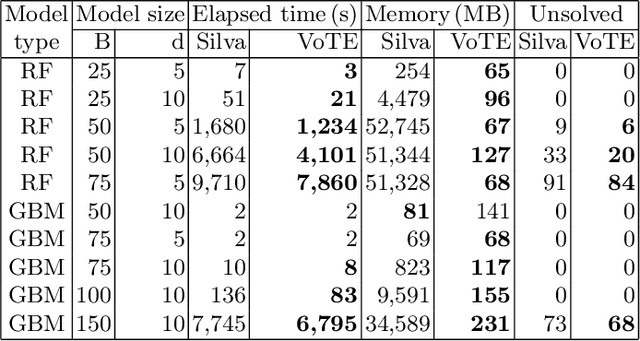
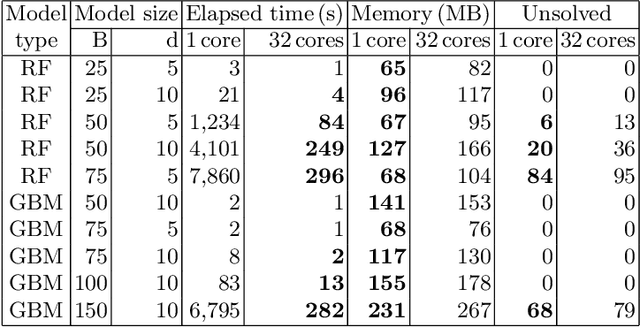
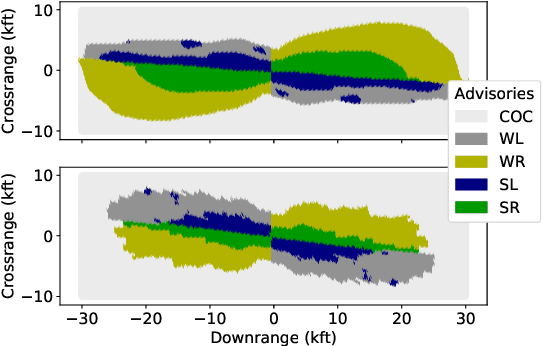
To guarantee that machine learning models yield outputs that are not only accurate, but also robust, recent works propose formally verifying robustness properties of machine learning models. To be applicable to realistic safety-critical systems, the used verification algorithms need to manage the combinatorial explosion resulting from vast variations in the input domain, and be able to verify correctness properties derived from versatile and domain-specific requirements. In this paper, we formalise the VoTE algorithm presented earlier as a tool description, and extend the tool set with mechanisms for systematic scalability studies. In particular, we show a) how the separation of property checking from the core verification engine enables verification of versatile requirements, b) the scalability of the tool, both in terms of time taken for verification and use of memory, and c) that the algorithm has attractive properties that lend themselves well for massive parallelisation. We demonstrate the application of the tool in two case studies, namely digit recognition and aircraft collision avoidance, where the first case study serves to assess the resource utilisation of the tool, and the second to assess the ability to verify versatile correctness properties.
Prediction of Reaction Time and Vigilance Variability from Spatiospectral Features of Resting-State EEG in a Long Sustained Attention Task
Oct 21, 2019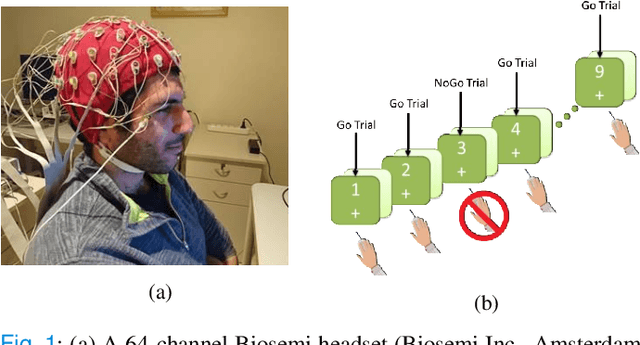
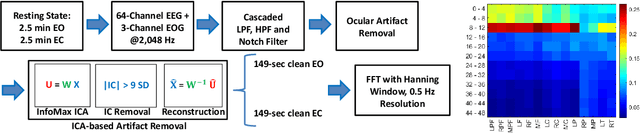
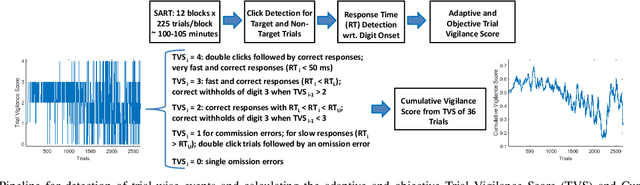
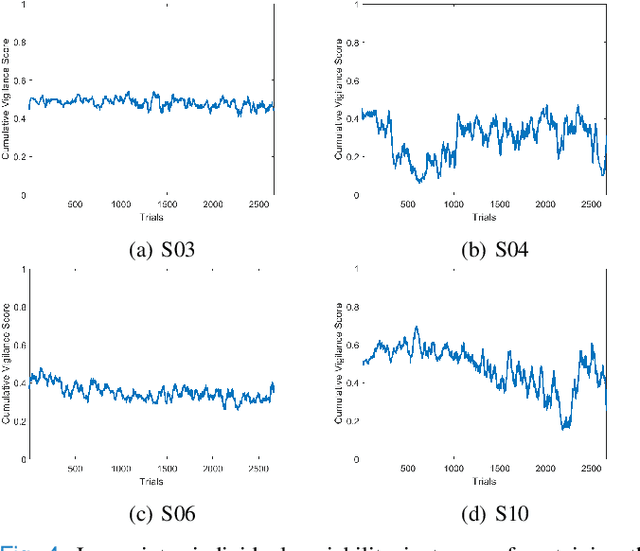
Resting-state brain networks represent the intrinsic state of the brain during the majority of cognitive and sensorimotor tasks. However, no study has yet presented concise predictors of task-induced vigilance variability from spectrospatial features of the pre-task, resting-state electroencephalograms (EEG). We asked ten healthy volunteers (6 females, 4 males) to participate in 105-minute fixed-sequence-varying-duration sessions of sustained attention to response task (SART). A novel and adaptive vigilance scoring scheme was designed based on the performance and response time in consecutive trials, and demonstrated large inter-participant variability in terms of maintaining consistent tonic performance. Multiple linear regression using feature relevance analysis obtained significant predictors of the mean cumulative vigilance score (CVS), mean response time, and variabilities of these scores from the resting-state, band-power ratios of EEG signals, p<0.05. Single-layer neural networks trained with cross-validation also captured different associations for the beta sub-bands. Increase in the gamma (28-48 Hz) and upper beta ratios from the left central and temporal regions predicted slower reactions and more inconsistent vigilance as explained by the increased activation of default mode network (DMN) and differences between the high- and low-attention networks at temporal regions. Higher ratios of parietal alpha from the Brodmann's areas 18, 19, and 37 during the eyes-open states predicted slower responses but more consistent CVS and reactions associated with the superior ability in vigilance maintenance. The proposed framework and these findings on the most stable and significant attention predictors from the intrinsic EEG power ratios can be used to model attention variations during the calibration sessions of BCI applications and vigilance monitoring systems.
Deep Learning-based Beam Tracking for Millimeter-wave Communications under Mobility
Feb 19, 2021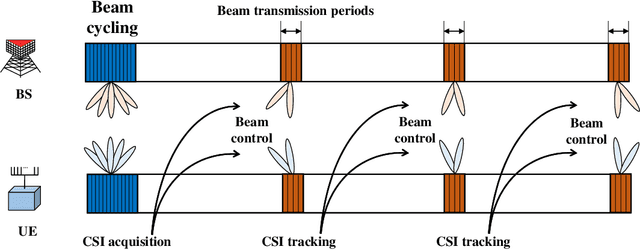
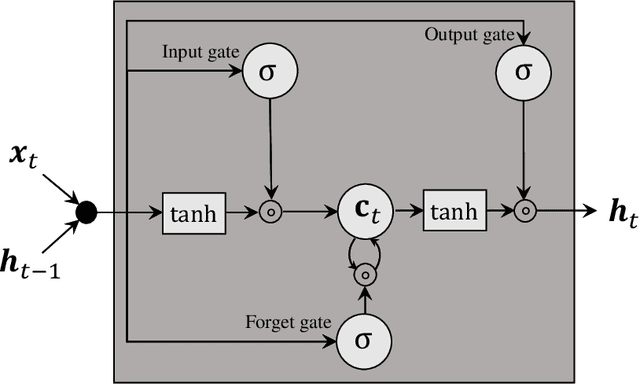
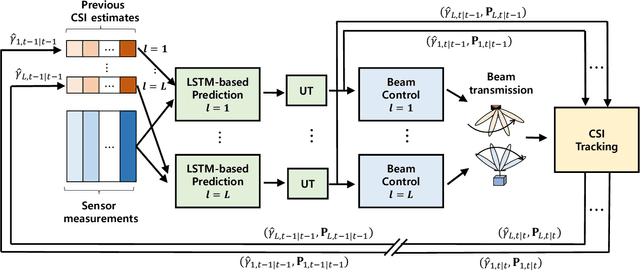
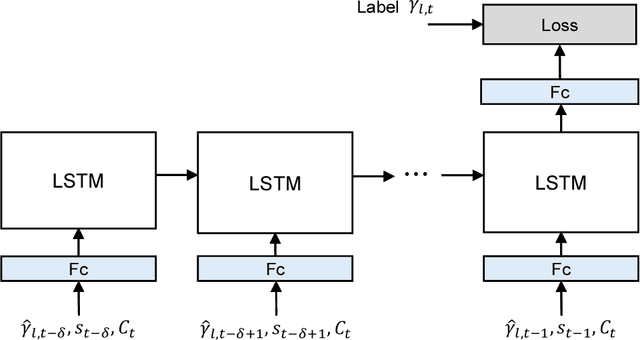
In this paper, we propose a deep learning-based beam tracking method for millimeter-wave (mmWave)communications. Beam tracking is employed for transmitting the known symbols using the sounding beams and tracking time-varying channels to maintain a reliable communication link. When the pose of a user equipment (UE) device varies rapidly, the mmWave channels also tend to vary fast, which hinders seamless communication. Thus, models that can capture temporal behavior of mmWave channels caused by the motion of the device are required, to cope with this problem. Accordingly, we employa deep neural network to analyze the temporal structure and patterns underlying in the time-varying channels and the signals acquired by inertial sensors. We propose a model based on long short termmemory (LSTM) that predicts the distribution of the future channel behavior based on a sequence of input signals available at the UE. This channel distribution is used to 1) control the sounding beams adaptively for the future channel state and 2) update the channel estimate through the measurement update step under a sequential Bayesian estimation framework. Our experimental results demonstrate that the proposed method achieves a significant performance gain over the conventional beam tracking methods under various mobility scenarios.
Concurrent Adversarial Learning for Large-Batch Training
Jun 01, 2021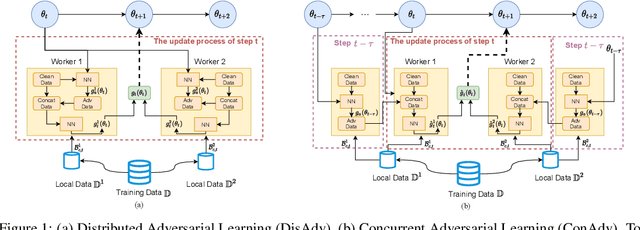
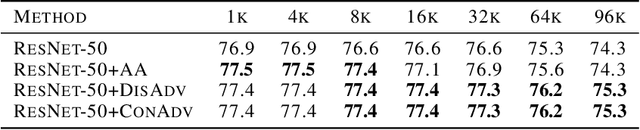
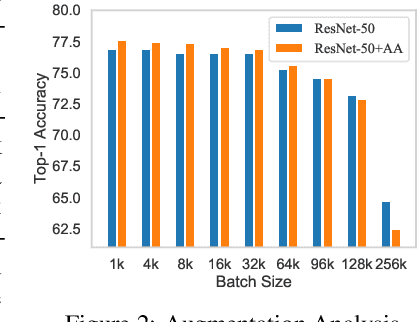

Large-batch training has become a commonly used technique when training neural networks with a large number of GPU/TPU processors. As batch size increases, stochastic optimizers tend to converge to sharp local minima, leading to degraded test performance. Current methods usually use extensive data augmentation to increase the batch size, but we found the performance gain with data augmentation decreases as batch size increases, and data augmentation will become insufficient after certain point. In this paper, we propose to use adversarial learning to increase the batch size in large-batch training. Despite being a natural choice for smoothing the decision surface and biasing towards a flat region, adversarial learning has not been successfully applied in large-batch training since it requires at least two sequential gradient computations at each step, which will at least double the running time compared with vanilla training even with a large number of processors. To overcome this issue, we propose a novel Concurrent Adversarial Learning (ConAdv) method that decouple the sequential gradient computations in adversarial learning by utilizing staled parameters. Experimental results demonstrate that ConAdv can successfully increase the batch size on both ResNet-50 and EfficientNet training on ImageNet while maintaining high accuracy. In particular, we show ConAdv along can achieve 75.3\% top-1 accuracy on ImageNet ResNet-50 training with 96K batch size, and the accuracy can be further improved to 76.2\% when combining ConAdv with data augmentation. This is the first work successfully scales ResNet-50 training batch size to 96K.
Learning Early Exit Strategies for Additive Ranking Ensembles
May 06, 2021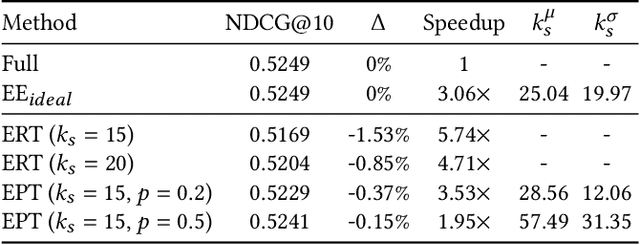
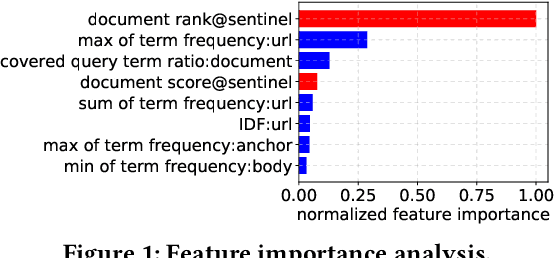
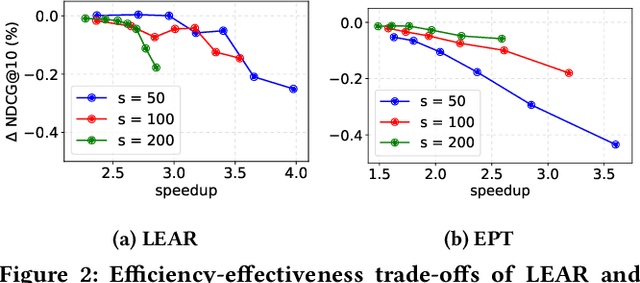
Modern search engine ranking pipelines are commonly based on large machine-learned ensembles of regression trees. We propose LEAR, a novel - learned - technique aimed to reduce the average number of trees traversed by documents to accumulate the scores, thus reducing the overall query response time. LEAR exploits a classifier that predicts whether a document can early exit the ensemble because it is unlikely to be ranked among the final top-k results. The early exit decision occurs at a sentinel point, i.e., after having evaluated a limited number of trees, and the partial scores are exploited to filter out non-promising documents. We evaluate LEAR by deploying it in a production-like setting, adopting a state-of-the-art algorithm for ensembles traversal. We provide a comprehensive experimental evaluation on two public datasets. The experiments show that LEAR has a significant impact on the efficiency of the query processing without hindering its ranking quality. In detail, on a first dataset, LEAR is able to achieve a speedup of 3x without any loss in NDCG1@0, while on a second dataset the speedup is larger than 5x with a negligible NDCG@10 loss (< 0.05%).
Investigation of Multiple Resource Theory Design Principles on Robot Teleoperation and Workload Management
Mar 31, 2021
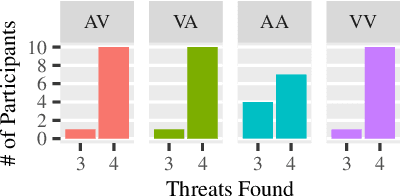
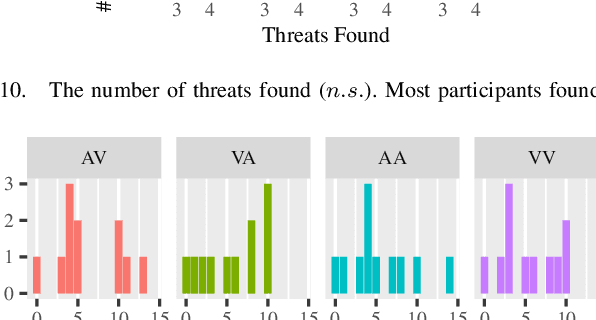
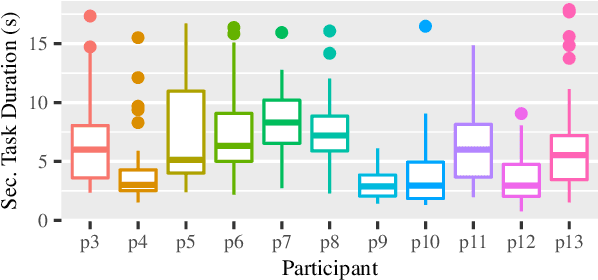
Robot interfaces often only use the visual channel. Inspired by Wickens' Multiple Resource Theory, we investigated if the addition of audio elements would reduce cognitive workload and improve performance. Specifically, we designed a search and threat-defusal task (primary) with a memory test task (secondary). Eleven participants - predominantly first responders - were recruited to control a robot to clear all threats in a combination of four conditions of primary and secondary tasks in visual and auditory channels. We did not find any statistically significant differences in performance or workload across subjects, making it questionable that Multiple Resource Theory could shorten longer-term task completion time and reduce workload. Our results suggest that considering individual differences for splitting interface modalities across multiple channels requires further investigation.
A low-rank representation for unsupervised registration of medical images
May 20, 2021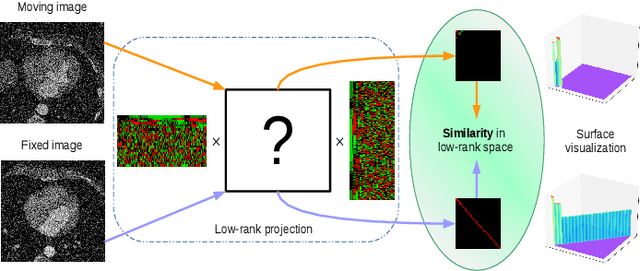
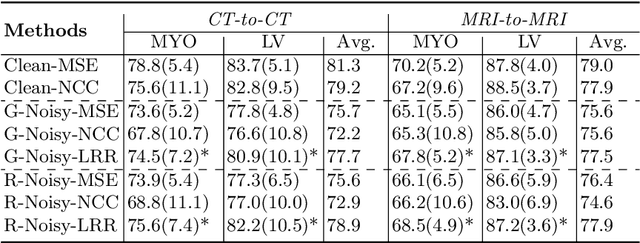

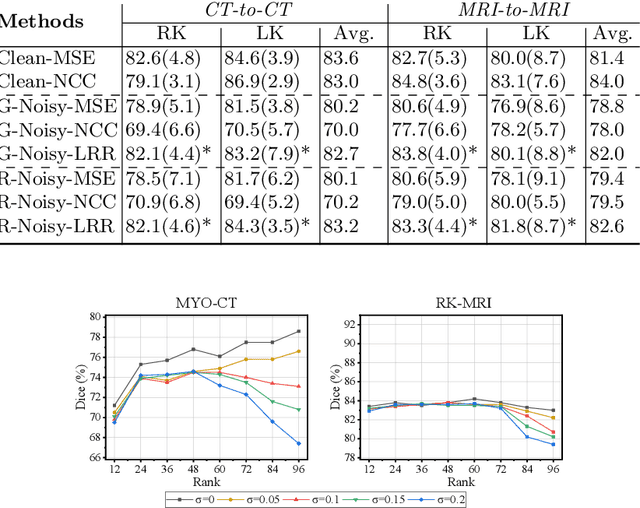
Registration networks have shown great application potentials in medical image analysis. However, supervised training methods have a great demand for large and high-quality labeled datasets, which is time-consuming and sometimes impractical due to data sharing issues. Unsupervised image registration algorithms commonly employ intensity-based similarity measures as loss functions without any manual annotations. These methods estimate the parameterized transformations between pairs of moving and fixed images through the optimization of the network parameters during training. However, these methods become less effective when the image quality varies, e.g., some images are corrupted by substantial noise or artifacts. In this work, we propose a novel approach based on a low-rank representation, i.e., Regnet-LRR, to tackle the problem. We project noisy images into a noise-free low-rank space, and then compute the similarity between the images. Based on the low-rank similarity measure, we train the registration network to predict the dense deformation fields of noisy image pairs. We highlight that the low-rank projection is reformulated in a way that the registration network can successfully update gradients. With two tasks, i.e., cardiac and abdominal intra-modality registration, we demonstrate that the low-rank representation can boost the generalization ability and robustness of models as well as bring significant improvements in noisy data registration scenarios.
Computer Vision Aided URLL Communications: Proactive Service Identification and Coexistence
Mar 18, 2021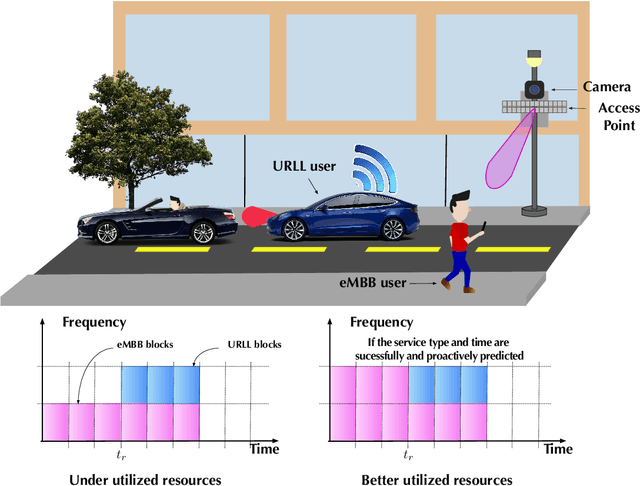
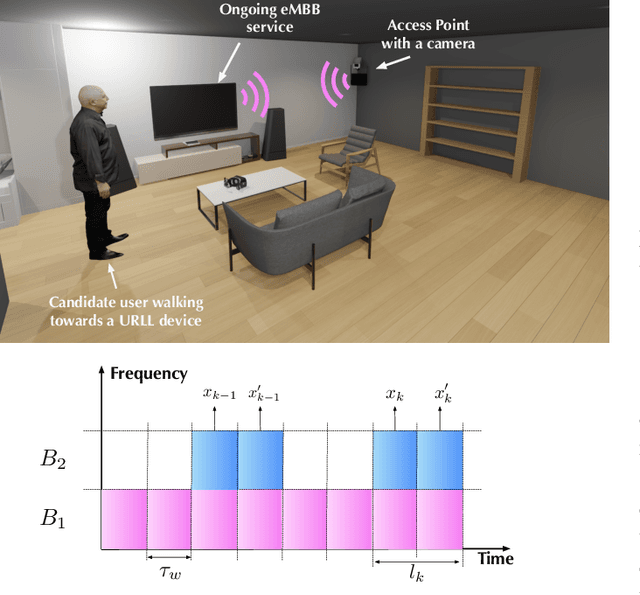
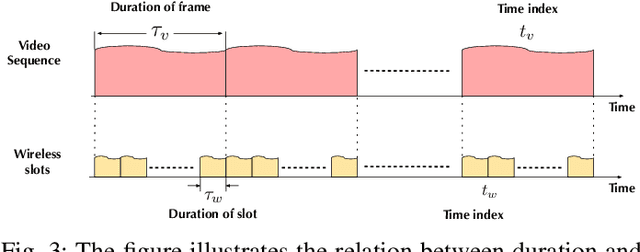
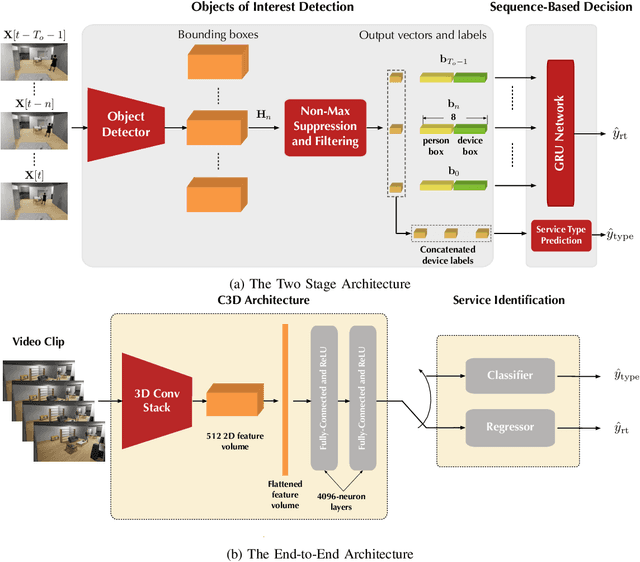
The support of coexisting ultra-reliable and low-latency (URLL) and enhanced Mobile BroadBand (eMBB) services is a key challenge for the current and future wireless communication networks. Those two types of services introduce strict, and in some time conflicting, resource allocation requirements that may result in a power-struggle between reliability, latency, and resource utilization in wireless networks. The difficulty in addressing that challenge could be traced back to the predominant reactive approach in allocating the wireless resources. This allocation operation is carried out based on received service requests and global network statistics, which may not incorporate a sense of \textit{proaction}. Therefore, this paper proposes a novel framework termed \textit{service identification} to develop novel proactive resource allocation algorithms. The developed framework is based on visual data (captured for example by RGB cameras) and deep learning (e.g., deep neural networks). The ultimate objective of this framework is to equip future wireless networks with the ability to analyze user behavior, anticipate incoming services, and perform proactive resource allocation. To demonstrate the potential of the proposed framework, a wireless network scenario with two coexisting URLL and eMBB services is considered, and two deep learning algorithms are designed to utilize RGB video frames and predict incoming service type and its request time. An evaluation dataset based on the considered scenario is developed and used to evaluate the performance of the two algorithms. The results confirm the anticipated value of proaction to wireless networks; the proposed models enable efficient network performance ensuring more than $85\%$ utilization of the network resources at $\sim 98\%$ reliability. This highlights a promising direction for the future vision-aided wireless communication networks.
Neural Spatio-Temporal Point Processes
Nov 09, 2020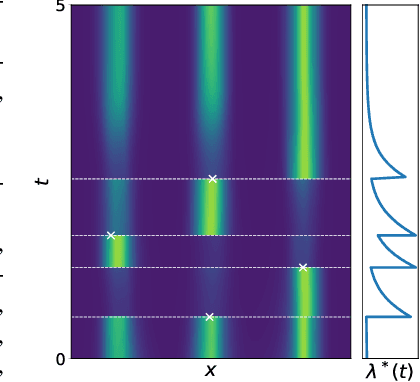
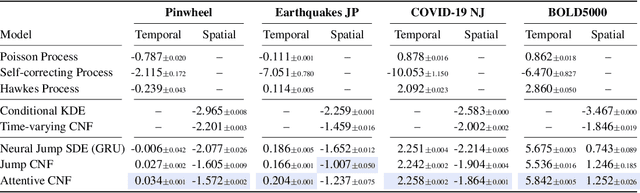
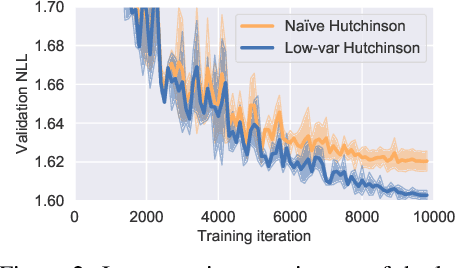

We propose a new class of parameterizations for spatio-temporal point processes which leverage Neural ODEs as a computational method and enable flexible, high-fidelity models of discrete events that are localized in continuous time and space. Central to our approach is a combination of recurrent continuous-time neural networks with two novel neural architectures, i.e., Jump and Attentive Continuous-time Normalizing Flows. This approach allows us to learn complex distributions for both the spatial and temporal domain and to condition non-trivially on the observed event history. We validate our models on data sets from a wide variety of contexts such as seismology, epidemiology, urban mobility, and neuroscience.