 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal Predictive Coding For Model-Based Planning In Latent Space
Jun 14, 2021
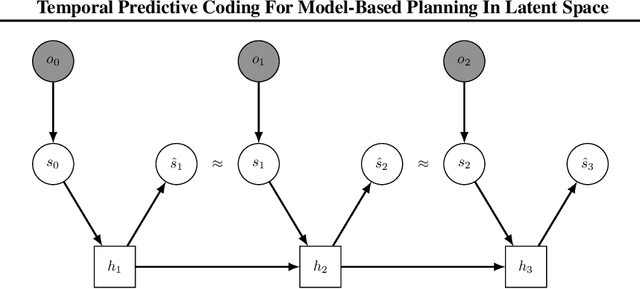
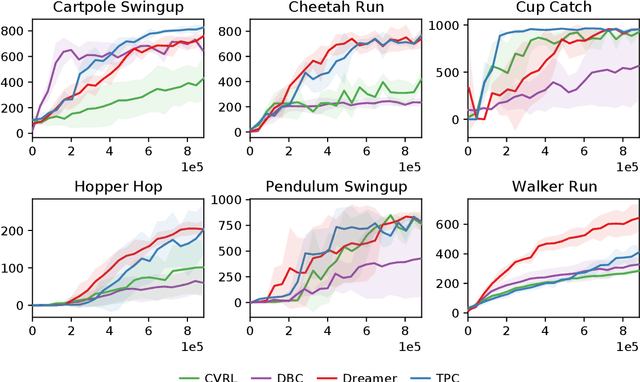
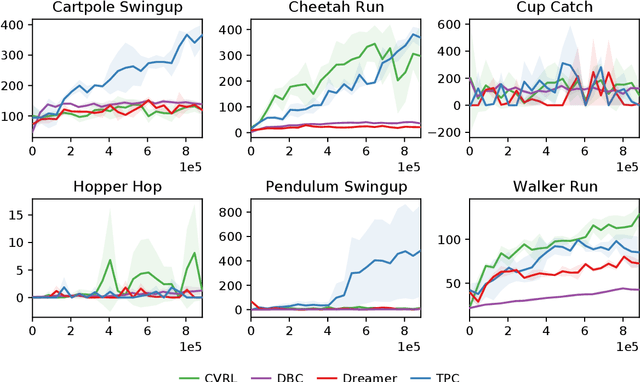
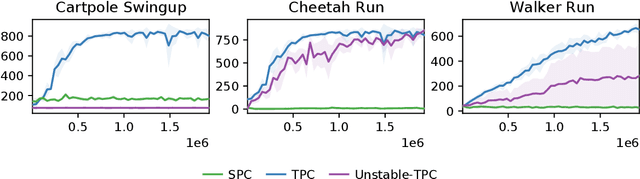
High-dimensional observations are a major challenge in the application of model-based reinforcement learning (MBRL) to real-world environments. To handle high-dimensional sensory inputs, existing approaches use representation learning to map high-dimensional observations into a lower-dimensional latent space that is more amenable to dynamics estimation and planning. In this work, we present an information-theoretic approach that employs temporal predictive coding to encode elements in the environment that can be predicted across time. Since this approach focuses on encoding temporally-predictable information, we implicitly prioritize the encoding of task-relevant components over nuisance information within the environment that are provably task-irrelevant. By learning this representation in conjunction with a recurrent state space model, we can then perform planning in latent space. We evaluate our model on a challenging modification of standard DMControl tasks where the background is replaced with natural videos that contain complex but irrelevant information to the planning task. Our experiments show that our model is superior to existing methods in the challenging complex-background setting while remaining competitive with current state-of-the-art models in the standard setting.
Efficient Matrix-Free Approximations of Second-Order Information, with Applications to Pruning and Optimization
Jul 08, 2021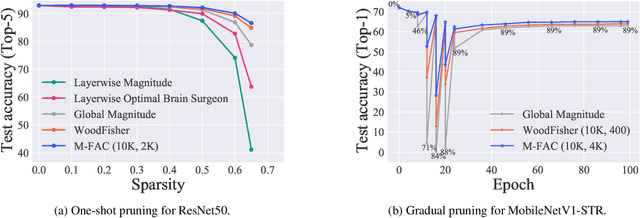
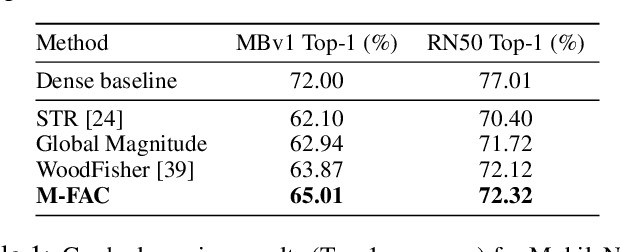
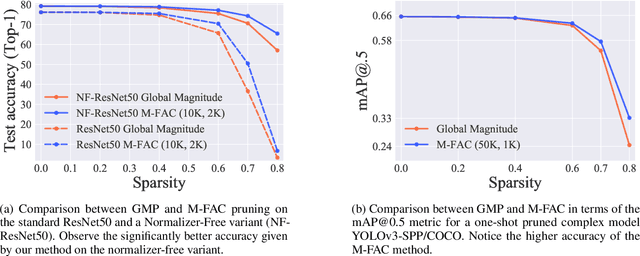
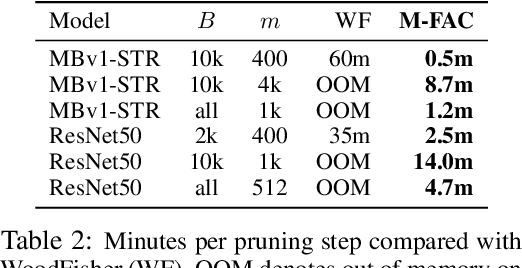
Efficiently approximating local curvature information of the loss function is a key tool for optimization and compression of deep neural networks. Yet, most existing methods to approximate second-order information have high computational or storage costs, which can limit their practicality. In this work, we investigate matrix-free, linear-time approaches for estimating Inverse-Hessian Vector Products (IHVPs) for the case when the Hessian can be approximated as a sum of rank-one matrices, as in the classic approximation of the Hessian by the empirical Fisher matrix. We propose two new algorithms as part of a framework called M-FAC: the first algorithm is tailored towards network compression and can compute the IHVP for dimension $d$, if the Hessian is given as a sum of $m$ rank-one matrices, using $O(dm^2)$ precomputation, $O(dm)$ cost for computing the IHVP, and query cost $O(m)$ for any single element of the inverse Hessian. The second algorithm targets an optimization setting, where we wish to compute the product between the inverse Hessian, estimated over a sliding window of optimization steps, and a given gradient direction, as required for preconditioned SGD. We give an algorithm with cost $O(dm + m^2)$ for computing the IHVP and $O(dm + m^3)$ for adding or removing any gradient from the sliding window. These two algorithms yield state-of-the-art results for network pruning and optimization with lower computational overhead relative to existing second-order methods. Implementations are available at [10] and [18].
SHAFF: Fast and consistent SHApley eFfect estimates via random Forests
May 25, 2021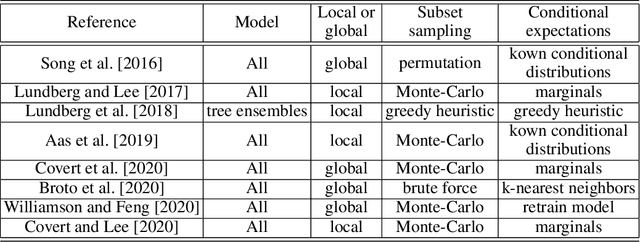
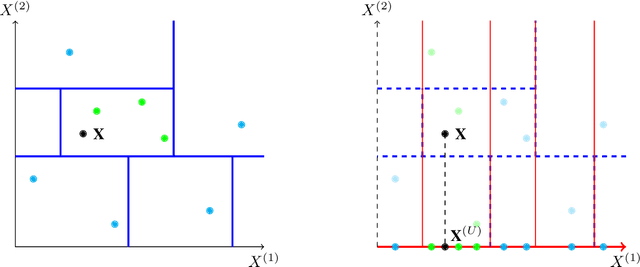
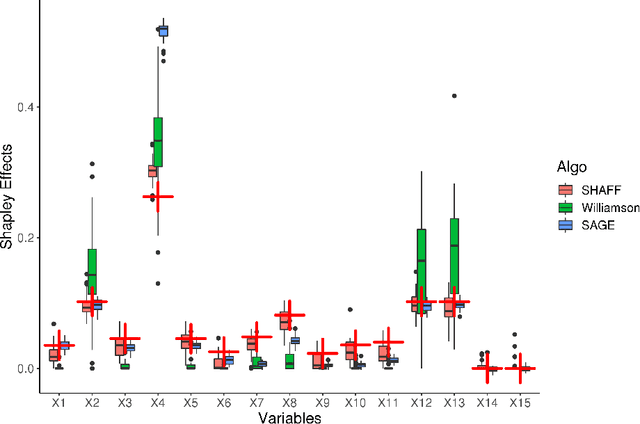
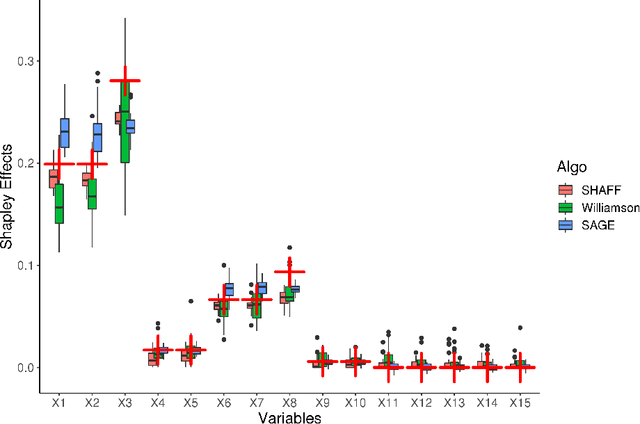
Interpretability of learning algorithms is crucial for applications involving critical decisions, and variable importance is one of the main interpretation tools. Shapley effects are now widely used to interpret both tree ensembles and neural networks, as they can efficiently handle dependence and interactions in the data, as opposed to most other variable importance measures. However, estimating Shapley effects is a challenging task, because of the computational complexity and the conditional expectation estimates. Accordingly, existing Shapley algorithms have flaws: a costly running time, or a bias when input variables are dependent. Therefore, we introduce SHAFF, SHApley eFfects via random Forests, a fast and accurate Shapley effect estimate, even when input variables are dependent. We show SHAFF efficiency through both a theoretical analysis of its consistency, and the practical performance improvements over competitors with extensive experiments. An implementation of SHAFF in C++ and R is available online.
Anomaly Detection with Generative Adversarial Networks for Multivariate Time Series
Oct 09, 2018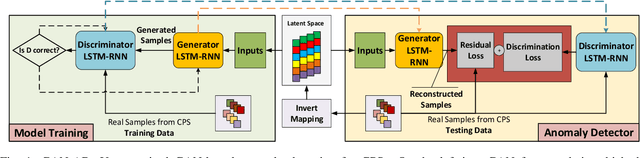
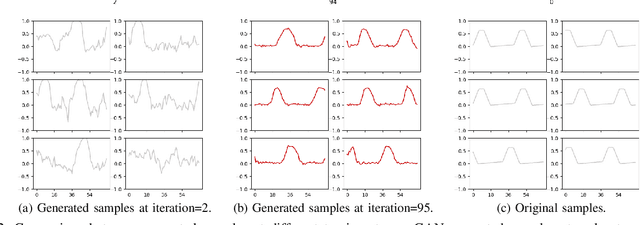
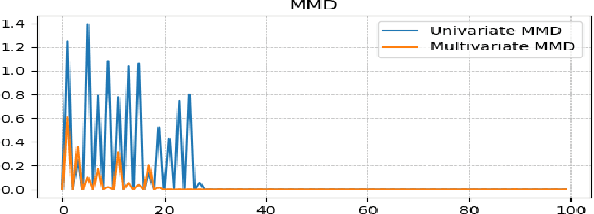
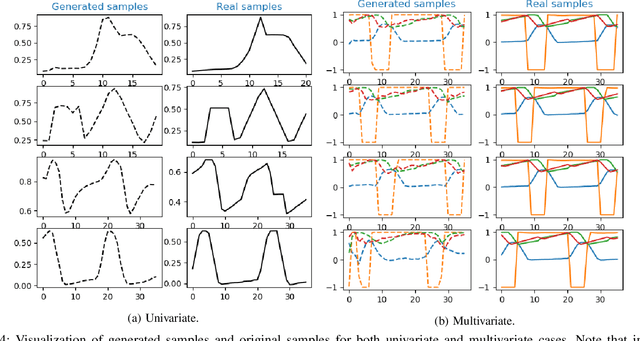
Today's Cyber-Physical Systems (CPSs) are large, complex, and affixed with networked sensors and actuators that are targets for cyber-attacks. Conventional detection techniques are unable to deal with the increasingly dynamic and complex nature of the CPSs. On the other hand, the networked sensors and actuators generate large amounts of data streams that can be continuously monitored for intrusion events. Unsupervised machine learning techniques can be used to model the system behaviour and classify deviant behaviours as possible attacks. In this work, we proposed a novel Generative Adversarial Networks-based Anomaly Detection (GAN-AD) method for such complex networked CPSs. We used LSTM-RNN in our GAN to capture the distribution of the multivariate time series of the sensors and actuators under normal working conditions of a CPS. Instead of treating each sensor's and actuator's time series independently, we model the time series of multiple sensors and actuators in the CPS concurrently to take into account of potential latent interactions between them. To exploit both the generator and the discriminator of our GAN, we deployed the GAN-trained discriminator together with the residuals between generator-reconstructed data and the actual samples to detect possible anomalies in the complex CPS. We used our GAN-AD to distinguish abnormal attacked situations from normal working conditions for a complex six-stage Secure Water Treatment (SWaT) system. Experimental results showed that the proposed strategy is effective in identifying anomalies caused by various attacks with high detection rate and low false positive rate as compared to existing methods.
Real-time Intent Prediction of Pedestrians for Autonomous Ground Vehicles via Spatio-Temporal DenseNet
Apr 22, 2019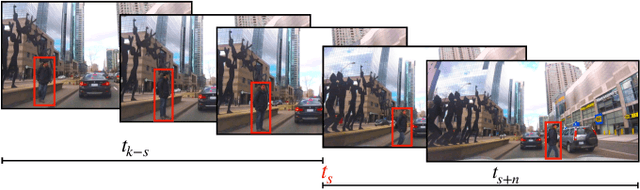
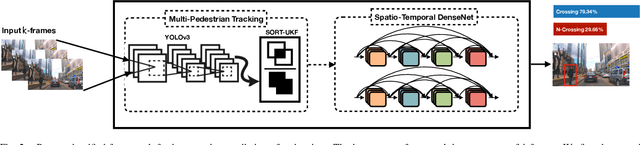
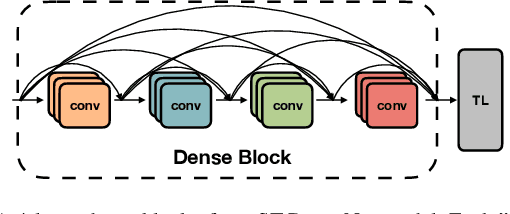
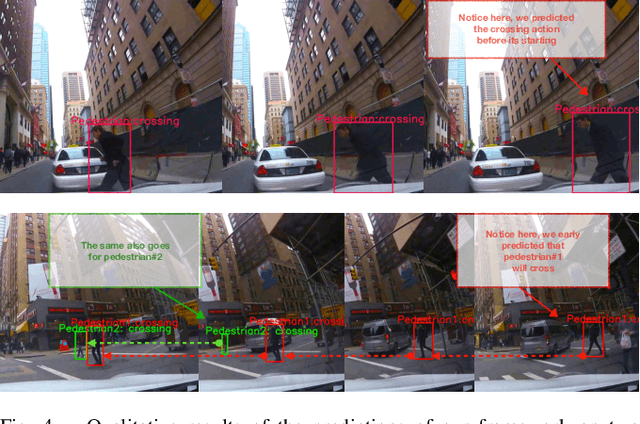
Understanding the behaviors and intentions of humans are one of the main challenges autonomous ground vehicles still faced with. More specifically, when it comes to complex environments such as urban traffic scenes, inferring the intentions and actions of vulnerable road users such as pedestrians become even harder. In this paper, we address the problem of intent action prediction of pedestrians in urban traffic environments using only image sequences from a monocular RGB camera. We propose a real-time framework that can accurately detect, track and predict the intended actions of pedestrians based on a tracking-by-detection technique in conjunction with a novel spatio-temporal DenseNet model. We trained and evaluated our framework based on real data collected from urban traffic environments. Our framework has shown resilient and competitive results in comparison to other baseline approaches. Overall, we achieved an average precision score of 84.76% with a real-time performance at 20 FPS.
LapNet : Automatic Balanced Loss and Optimal Assignment for Real-Time Dense Object Detection
Nov 04, 2019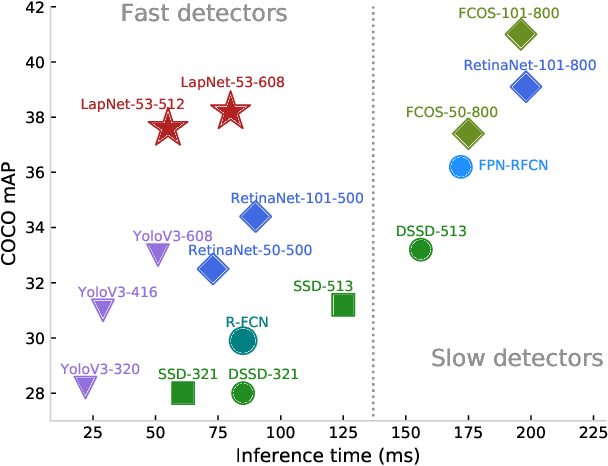
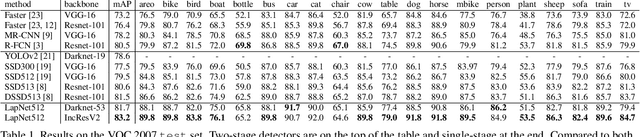

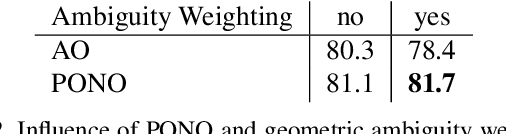
Several modern deep single-stage object detectors are really effective for real time processing but still remain less efficient than more complex ones. The trade-off between model performances and computing speed is an important challenge, directly related to the learning process. In this paper, we propose a new way to efficiently learn a single shot detector providing a very good trade-off between these two factors. For this purpose, we introduce LapNet, an anchor based detector, trained end-to-end without any sampling strategy. Our approach focuses on two limitations of anchor based detector training: (1) the ambiguity of anchor to ground truth assignment and (2) the imbalance between classes and the imbalance between object sizes. More specifically, a new method to assign positive and negative anchors is proposed, based on a new overlapping function called "Per-Object Normalized Overlap" (PONO). This more flexible assignment can be self-corrected by the network itself to avoid the ambiguity between close objects. In the learning process, we also propose to automatically learn weights to balance classes and object sizes to efficiently manage sample imbalance. It allows to build a robust object detector avoiding multi-scale prediction, in a semantic segmentation spirit.
CReaM: Condensed Real-time Models for Depth Prediction using Convolutional Neural Networks
Jul 24, 2018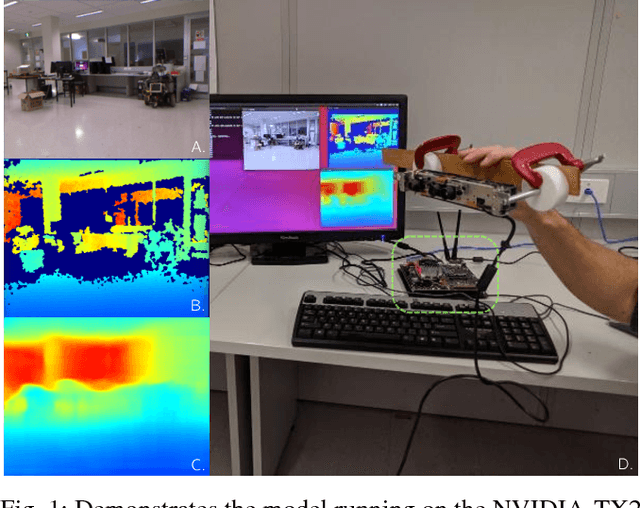
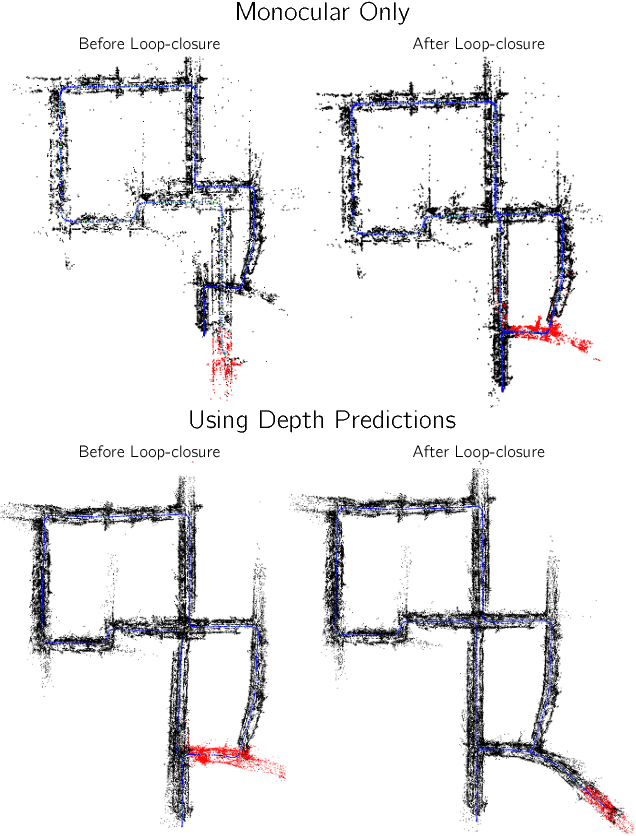
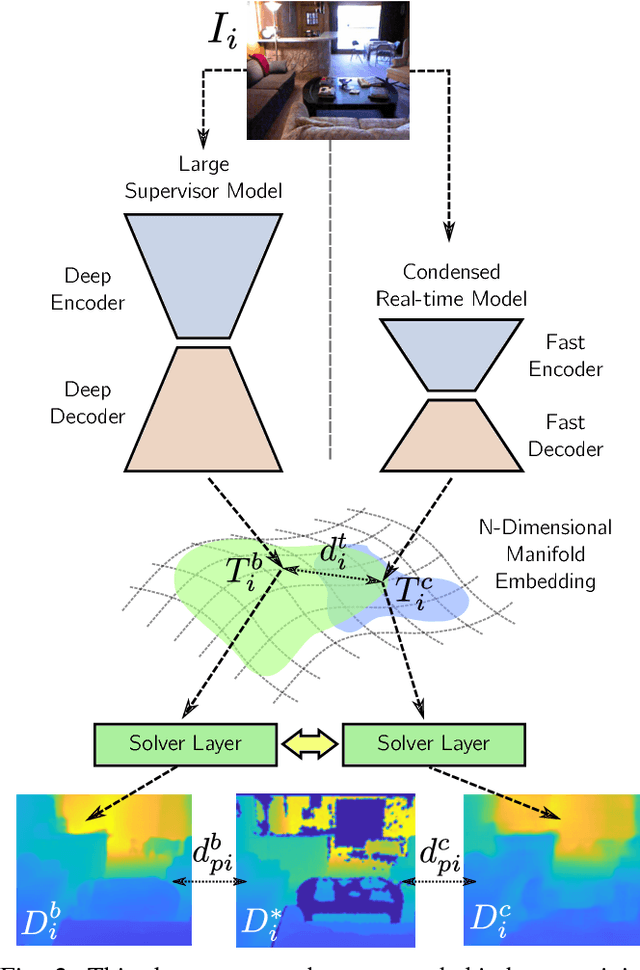
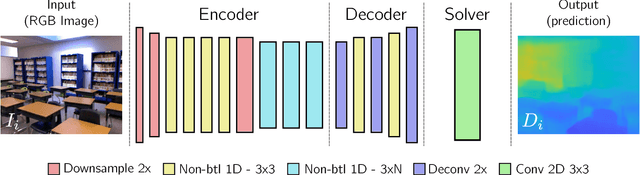
Since the resurgence of CNNs the robotic vision community has developed a range of algorithms that perform classification, semantic segmentation and structure prediction (depths, normals, surface curvature) using neural networks. While some of these models achieve state-of-the art results and super human level performance, deploying these models in a time critical robotic environment remains an ongoing challenge. Real-time frameworks are of paramount importance to build a robotic society where humans and robots integrate seamlessly. To this end, we present a novel real-time structure prediction framework that predicts depth at 30fps on an NVIDIA-TX2. At the time of writing, this is the first piece of work to showcase such a capability on a mobile platform. We also demonstrate with extensive experiments that neural networks with very large model capacities can be leveraged in order to train accurate condensed model architectures in a "from teacher to student" style knowledge transfer.
Relation-Based Associative Joint Location for Human Pose Estimation in Videos
Jul 08, 2021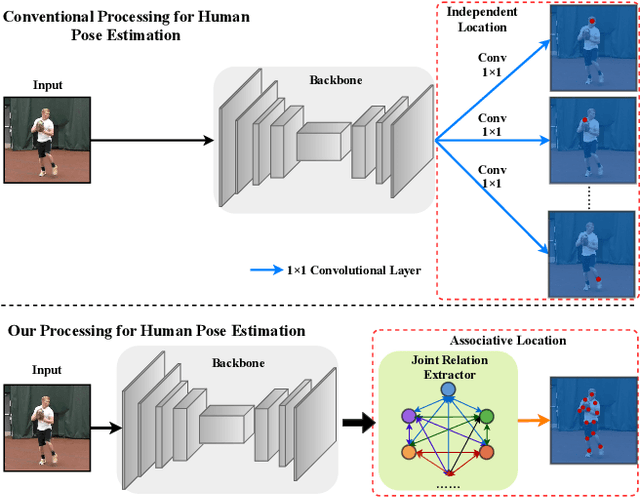
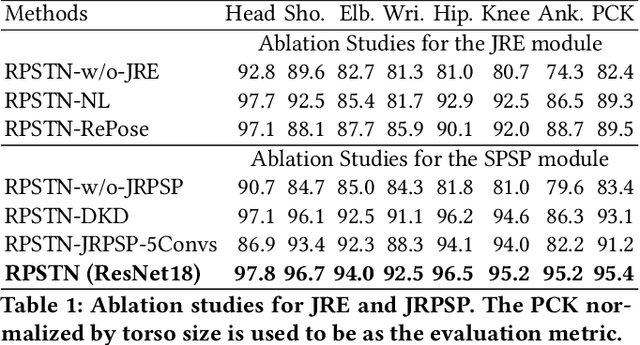
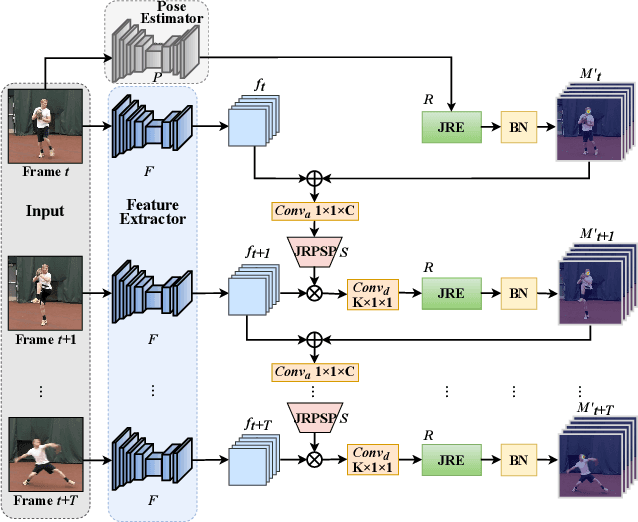
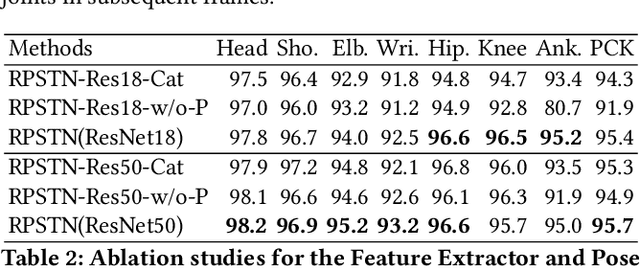
Video-based human pose estimation (HPE) is a vital yet challenging task. While deep learning methods have made significant progress for the HPE, most approaches to this task detect each joint independently, damaging the pose structural information. In this paper, unlike the prior methods, we propose a Relation-based Pose Semantics Transfer Network (RPSTN) to locate joints associatively. Specifically, we design a lightweight joint relation extractor (JRE) to model the pose structural features and associatively generate heatmaps for joints by modeling the relation between any two joints heuristically instead of building each joint heatmap independently. Actually, the proposed JRE module models the spatial configuration of human poses through the relationship between any two joints. Moreover, considering the temporal semantic continuity of videos, the pose semantic information in the current frame is beneficial for guiding the location of joints in the next frame. Therefore, we use the idea of knowledge reuse to propagate the pose semantic information between consecutive frames. In this way, the proposed RPSTN captures temporal dynamics of poses. On the one hand, the JRE module can infer invisible joints according to the relationship between the invisible joints and other visible joints in space. On the other hand, in the time, the propose model can transfer the pose semantic features from the non-occluded frame to the occluded frame to locate occluded joints. Therefore, our method is robust to the occlusion and achieves state-of-the-art results on the two challenging datasets, which demonstrates its effectiveness for video-based human pose estimation. We will release the code and models publicly.
DEHB: Evolutionary Hyberband for Scalable, Robust and Efficient Hyperparameter Optimization
May 20, 2021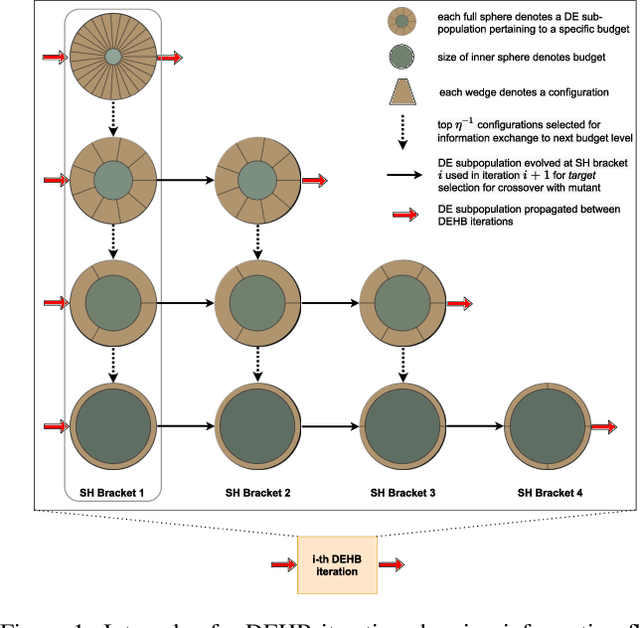
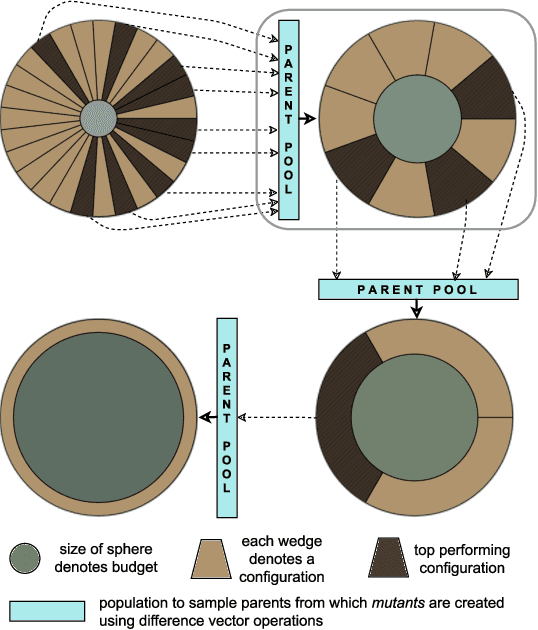
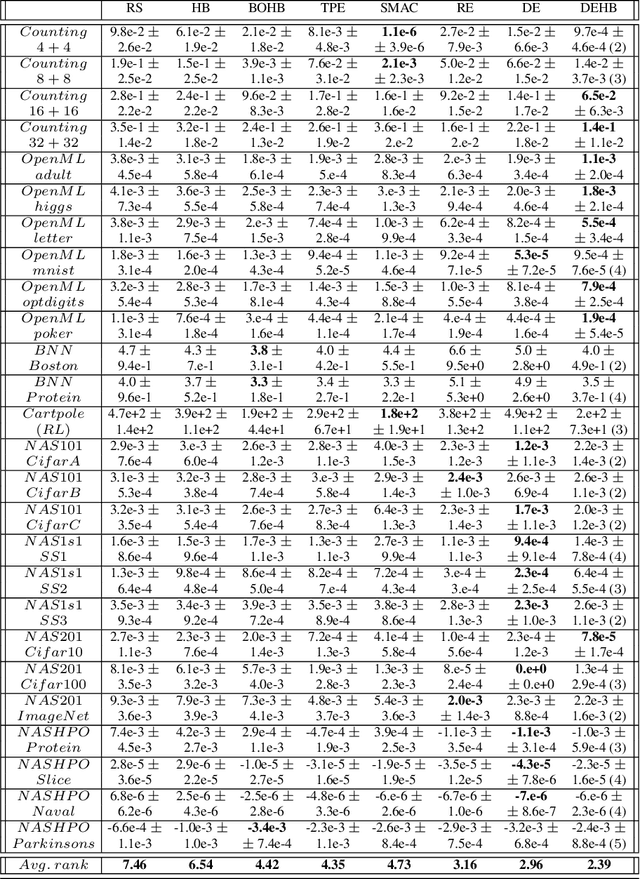
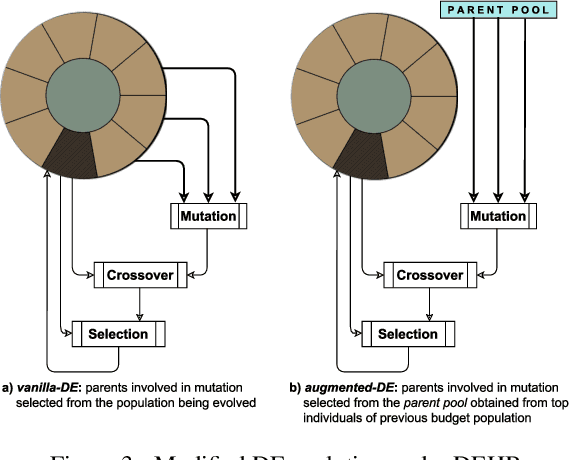
Modern machine learning algorithms crucially rely on several design decisions to achieve strong performance, making the problem of Hyperparameter Optimization (HPO) more important than ever. Here, we combine the advantages of the popular bandit-based HPO method Hyperband (HB) and the evolutionary search approach of Differential Evolution (DE) to yield a new HPO method which we call DEHB. Comprehensive results on a very broad range of HPO problems, as well as a wide range of tabular benchmarks from neural architecture search, demonstrate that DEHB achieves strong performance far more robustly than all previous HPO methods we are aware of, especially for high-dimensional problems with discrete input dimensions. For example, DEHB is up to 1000x faster than random search. It is also efficient in computational time, conceptually simple and easy to implement, positioning it well to become a new default HPO method.
Online Cognitive Data Sensing and Processing Optimization in Energy-harvesting Edge Computing Systems
Jun 27, 2021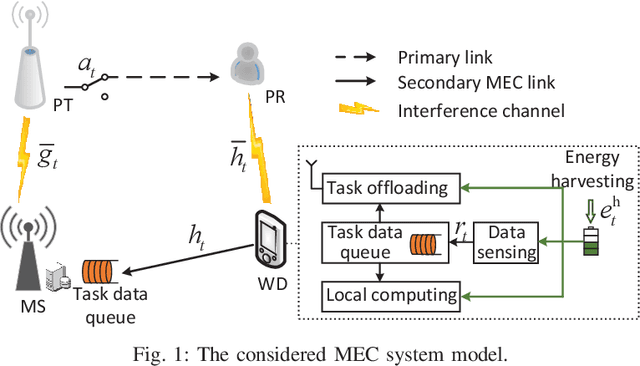
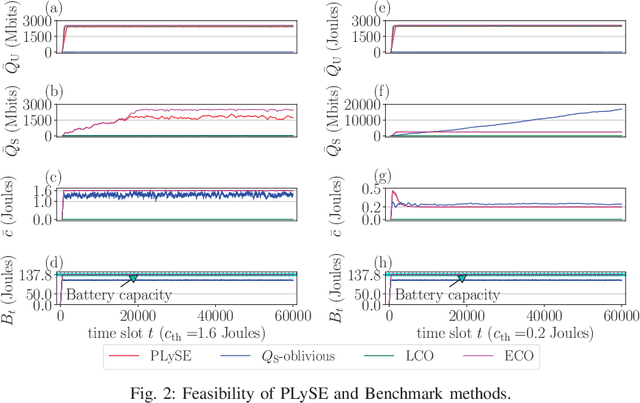
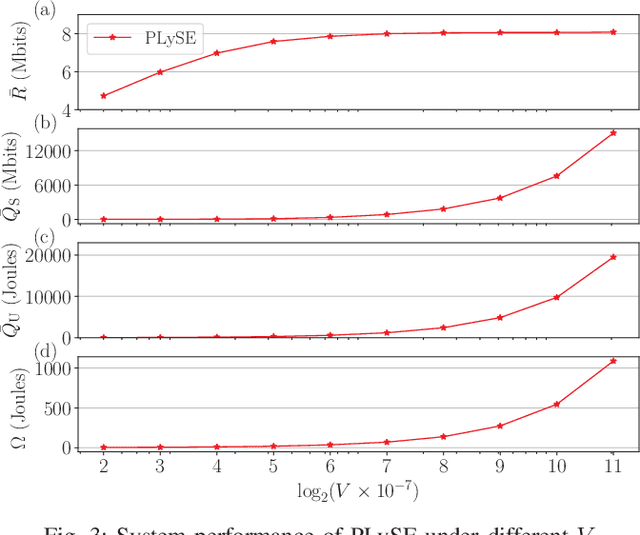
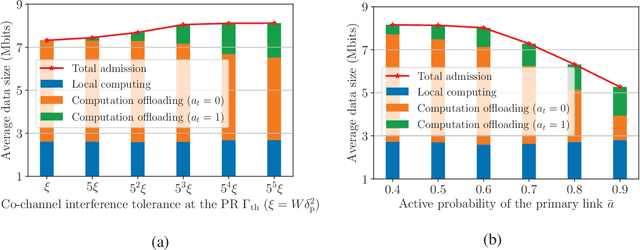
Mobile edge computing (MEC) has recently become a prevailing technique to alleviate the intensive computation burden in Internet of Things (IoT) networks. However, the limited device battery capacity and stringent spectrum resource significantly restrict the data processing performance of MEC-enabled IoT networks. To address the two performance limitations, we consider in this paper an MEC-enabled IoT system with an energy harvesting (EH) wireless device (WD) which opportunistically accesses the licensed spectrum of an overlaid primary communication link for task offloading. We aim to maximize the long-term average sensing rate of the WD subject to quality of service (QoS) requirement of primary link, average power constraint of MEC server (MS) and data queue stability of both MS and WD. We formulate the problem as a multi-stage stochastic optimization and propose an online algorithm named PLySE that applies the perturbed Lyapunov optimization technique to decompose the original problem into per-slot deterministic optimization problems. For each per-slot problem, we derive the closed-form optimal solution of data sensing and processing control to facilitate low-complexity real-time implementation. Interestingly, our analysis finds that the optimal solution exhibits an threshold-based structure. Simulation results collaborate with our analysis and demonstrate more than 46.7\% data sensing rate improvement of the proposed PLySE over representative benchmark methods.