 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Controllable Generation: Faster Training and Better Performance via $x_0$-Supervision
Apr 07, 2026Text-to-Image (T2I) diffusion/flow models have recently achieved remarkable progress in visual fidelity and text alignment. However, they remain limited when users need to precisely control image layouts, something that natural language alone cannot reliably express. Controllable generation methods augment the initial T2I model with additional conditions that more easily describe the scene. Prior works straightforwardly train the augmented network with the same loss as the initial network. Although natural at first glance, this can lead to very long training times in some cases before convergence. In this work, we revisit the training objective of controllable diffusion models through a detailed analysis of their denoising dynamics. We show that direct supervision on the clean target image, dubbed $x_0$-supervision, or an equivalent re-weighting of the diffusion loss, yields faster convergence. Experiments on multiple control settings demonstrate that our formulation accelerates convergence by up to 2$\times$ according to our novel metric (mean Area Under the Convergence Curve - mAUCC), while also improving both visual quality and conditioning accuracy. Our code is available at https://github.com/CEA-LIST/x0-supervision
Online Nonparametric Supervised Learning for Massive Data
May 29, 2024



Despite their benefits in terms of simplicity, low computational cost and data requirement, parametric machine learning algorithms, such as linear discriminant analysis, quadratic discriminant analysis or logistic regression, suffer from serious drawbacks including linearity, poor fit of features to the usually imposed normal distribution and high dimensionality. Batch kernel-based nonparametric classifier, which overcomes the linearity and normality of features constraints, represent an interesting alternative for supervised classification problem. However, it suffers from the ``curse of dimension". The problem can be alleviated by the explosive sample size in the era of big data, while large-scale data size presents some challenges in the storage of data and the calculation of the classifier. These challenges make the classical batch nonparametric classifier no longer applicable. This motivates us to develop a fast algorithm adapted to the real-time calculation of the nonparametric classifier in massive as well as streaming data frameworks. This online classifier includes two steps. First, we consider an online principle components analysis to reduce the dimension of the features with a very low computation cost. Then, a stochastic approximation algorithm is deployed to obtain a real-time calculation of the nonparametric classifier. The proposed methods are evaluated and compared to some commonly used machine learning algorithms for real-time fetal well-being monitoring. The study revealed that, in terms of accuracy, the offline (or Batch), as well as, the online classifiers are good competitors to the random forest algorithm. Moreover, we show that the online classifier gives the best trade-off accuracy/computation cost compared to the offline classifier.
3D-COCO: extension of MS-COCO dataset for image detection and 3D reconstruction modules
Apr 08, 2024



We introduce 3D-COCO, an extension of the original MS-COCO dataset providing 3D models and 2D-3D alignment annotations. 3D-COCO was designed to achieve computer vision tasks such as 3D reconstruction or image detection configurable with textual, 2D image, and 3D CAD model queries. We complete the existing MS-COCO dataset with 28K 3D models collected on ShapeNet and Objaverse. By using an IoU-based method, we match each MS-COCO annotation with the best 3D models to provide a 2D-3D alignment. The open-source nature of 3D-COCO is a premiere that should pave the way for new research on 3D-related topics. The dataset and its source codes is available at https://kalisteo.cea.fr/index.php/coco3d-object-detection-and-reconstruction/
LapNet : Automatic Balanced Loss and Optimal Assignment for Real-Time Dense Object Detection
Nov 04, 2019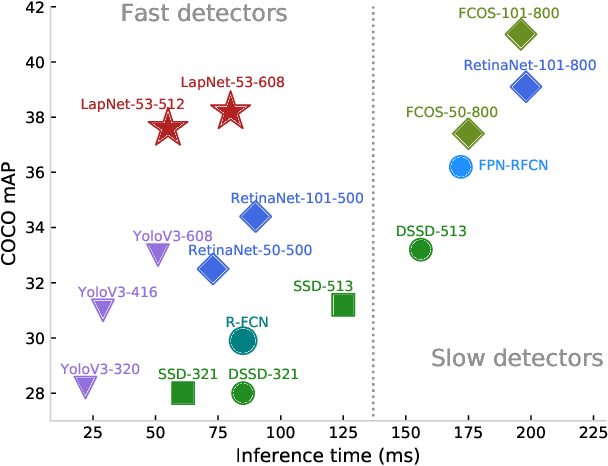
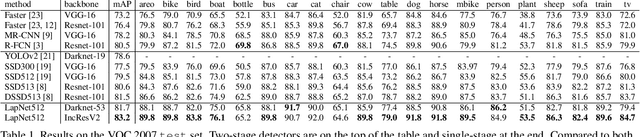

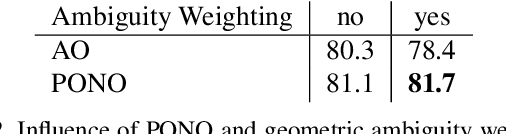
Several modern deep single-stage object detectors are really effective for real time processing but still remain less efficient than more complex ones. The trade-off between model performances and computing speed is an important challenge, directly related to the learning process. In this paper, we propose a new way to efficiently learn a single shot detector providing a very good trade-off between these two factors. For this purpose, we introduce LapNet, an anchor based detector, trained end-to-end without any sampling strategy. Our approach focuses on two limitations of anchor based detector training: (1) the ambiguity of anchor to ground truth assignment and (2) the imbalance between classes and the imbalance between object sizes. More specifically, a new method to assign positive and negative anchors is proposed, based on a new overlapping function called "Per-Object Normalized Overlap" (PONO). This more flexible assignment can be self-corrected by the network itself to avoid the ambiguity between close objects. In the learning process, we also propose to automatically learn weights to balance classes and object sizes to efficiently manage sample imbalance. It allows to build a robust object detector avoiding multi-scale prediction, in a semantic segmentation spirit.
Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image
Mar 22, 2017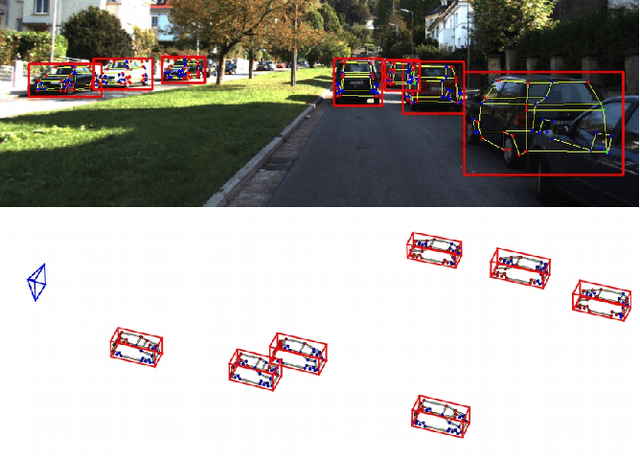
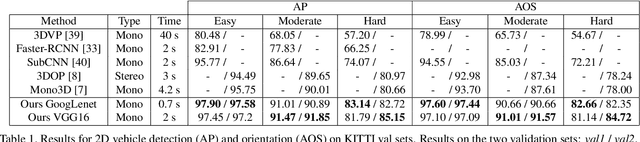
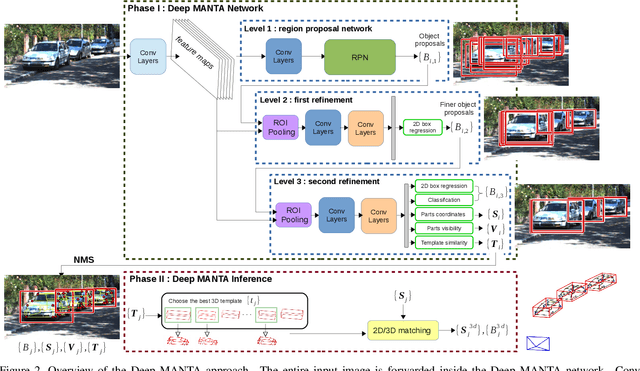
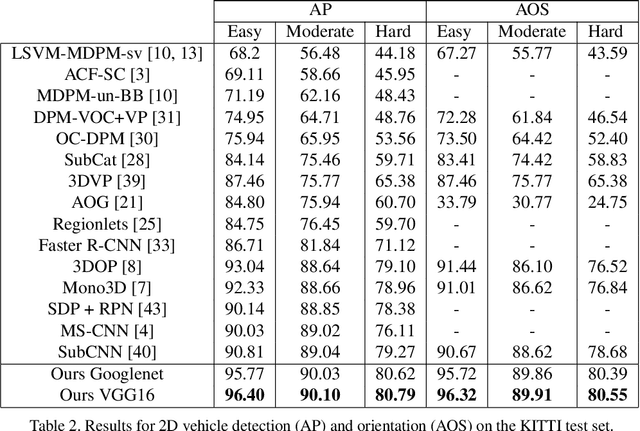
In this paper, we present a novel approach, called Deep MANTA (Deep Many-Tasks), for many-task vehicle analysis from a given image. A robust convolutional network is introduced for simultaneous vehicle detection, part localization, visibility characterization and 3D dimension estimation. Its architecture is based on a new coarse-to-fine object proposal that boosts the vehicle detection. Moreover, the Deep MANTA network is able to localize vehicle parts even if these parts are not visible. In the inference, the network's outputs are used by a real time robust pose estimation algorithm for fine orientation estimation and 3D vehicle localization. We show in experiments that our method outperforms monocular state-of-the-art approaches on vehicle detection, orientation and 3D location tasks on the very challenging KITTI benchmark.