 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Heteroscedastic Aleatoric Uncertainties for Robust Real-Time LiDAR 3D Object Detection
Feb 03, 2019
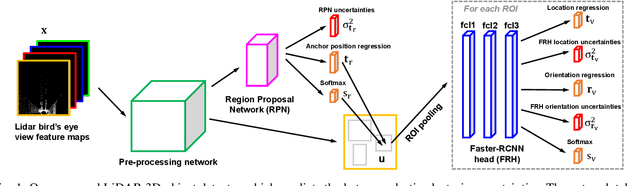

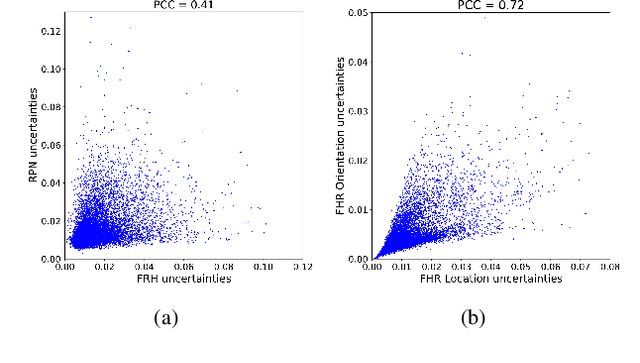
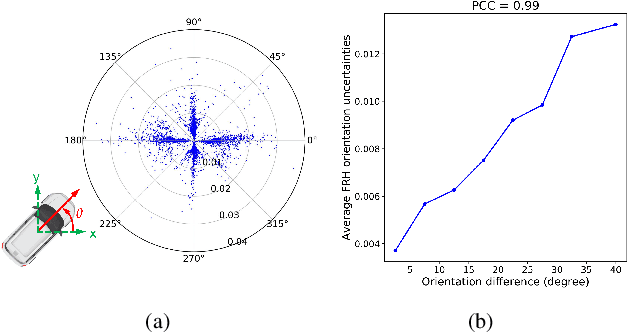
We present a robust real-time LiDAR 3D object detector that leverages heteroscedastic aleatoric uncertainties to significantly improve its detection performance. A multi-loss function is designed to incorporate uncertainty estimations predicted by auxiliary output layers. Using our proposed method, the network ignores to train from noisy samples, and focuses more on informative ones. We validate our method on the KITTI object detection benchmark. Our method surpasses the baseline method which does not explicitly estimate uncertainties by up to nearly 9% in terms of Average Precision (AP). It also produces state-of-the-art results compared to other methods while running with an inference time of only 72 ms. In addition, we conduct extensive experiments to understand how aleatoric uncertainties behave. Extracting aleatoric uncertainties brings almost no additional computation cost during the deployment, making our method highly desirable for autonomous driving applications.
DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion
Dec 03, 2020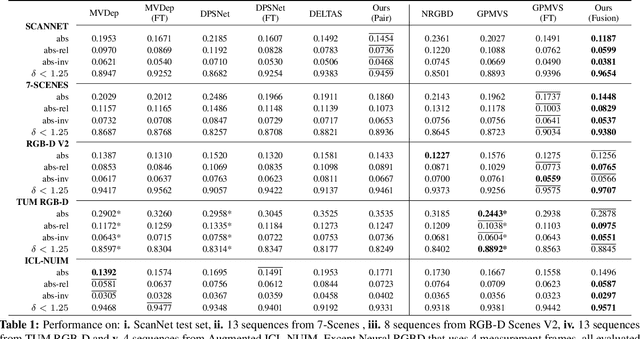
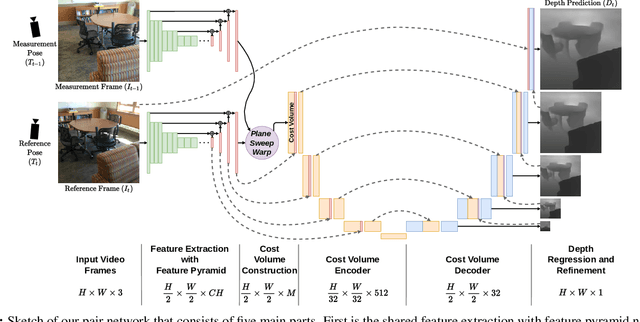
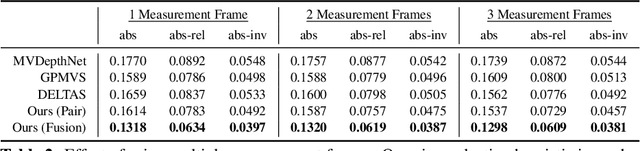
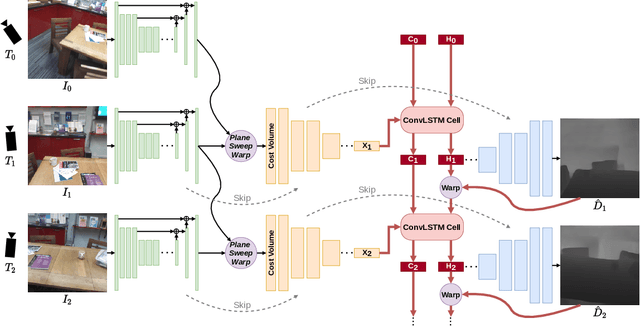
We propose an online multi-view depth prediction approach on posed video streams, where the scene geometry information computed in the previous time steps is propagated to the current time step in an efficient and geometrically plausible way. The backbone of our approach is a real-time capable, lightweight encoder-decoder that relies on cost volumes computed from pairs of images. We extend it by placing a ConvLSTM cell at the bottleneck layer, which compresses an arbitrary amount of past information in its states. The novelty lies in propagating the hidden state of the cell by accounting for the viewpoint changes between time steps. At a given time step, we warp the previous hidden state into the current camera plane using the previous depth prediction. Our extension brings only a small overhead of computation time and memory consumption, while improving the depth predictions significantly. As a result, we outperform the existing state-of-the-art multi-view stereo methods on most of the evaluated metrics in hundreds of indoor scenes while maintaining a real-time performance. Code available: https://github.com/ardaduz/deep-video-mvs
Shapley Explanation Networks
Apr 06, 2021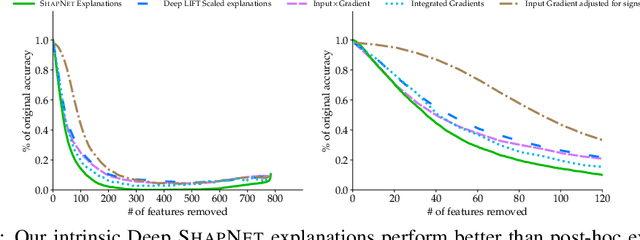


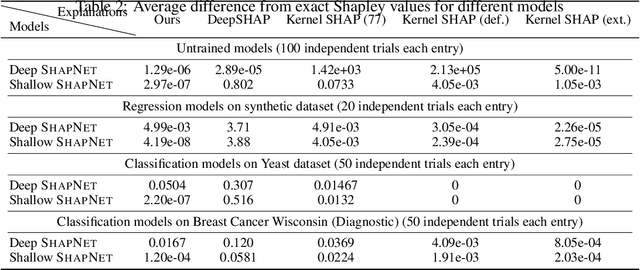
Shapley values have become one of the most popular feature attribution explanation methods. However, most prior work has focused on post-hoc Shapley explanations, which can be computationally demanding due to its exponential time complexity and preclude model regularization based on Shapley explanations during training. Thus, we propose to incorporate Shapley values themselves as latent representations in deep models thereby making Shapley explanations first-class citizens in the modeling paradigm. This intrinsic explanation approach enables layer-wise explanations, explanation regularization of the model during training, and fast explanation computation at test time. We define the Shapley transform that transforms the input into a Shapley representation given a specific function. We operationalize the Shapley transform as a neural network module and construct both shallow and deep networks, called ShapNets, by composing Shapley modules. We prove that our Shallow ShapNets compute the exact Shapley values and our Deep ShapNets maintain the missingness and accuracy properties of Shapley values. We demonstrate on synthetic and real-world datasets that our ShapNets enable layer-wise Shapley explanations, novel Shapley regularizations during training, and fast computation while maintaining reasonable performance. Code is available at https://github.com/inouye-lab/ShapleyExplanationNetworks.
Task Allocation and Coordinated Motion Planning for Autonomous Multi-Robot Optical Inspection Systems
Jun 15, 2021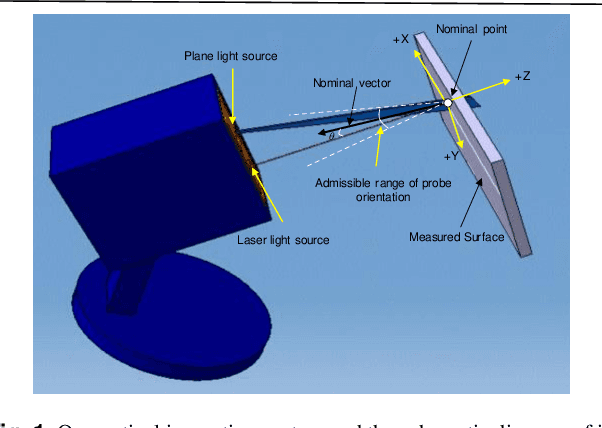
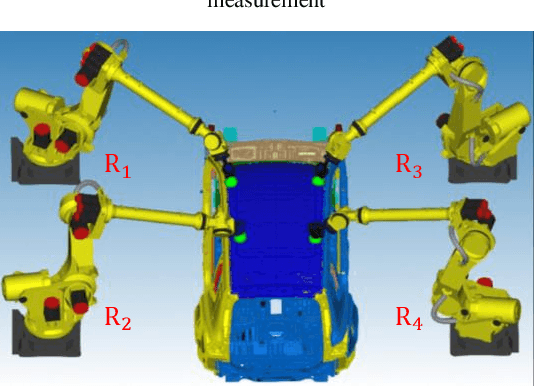
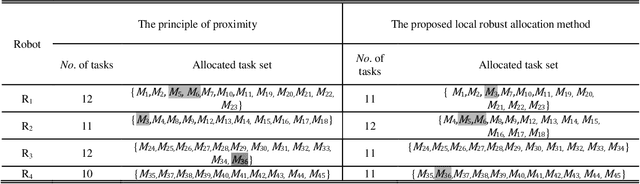
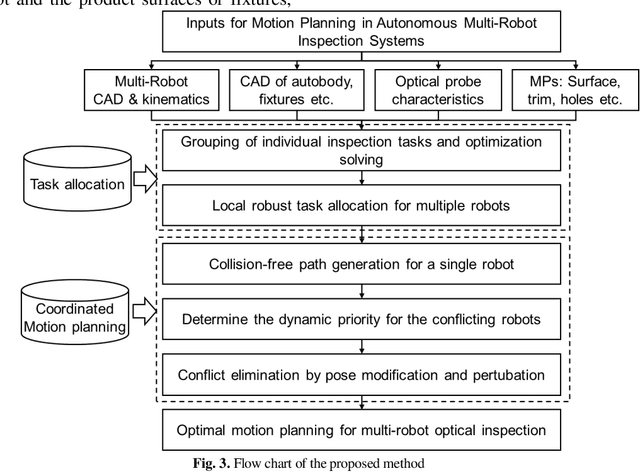
Autonomous multi-robot optical inspection systems are increasingly applied for obtaining inline measurements in process monitoring and quality control. Numerous methods for path planning and robotic coordination have been developed for static and dynamic environments and applied to different fields. However, these approaches may not work for the autonomous multi-robot optical inspection system due to fast computation requirements of inline optimization, unique characteristics on robotic end-effector orientations, and complex large-scale free-form product surfaces. This paper proposes a novel task allocation methodology for coordinated motion planning of multi-robot inspection. Specifically, (1) a local robust inspection task allocation is proposed to achieve efficient and well-balanced measurement assignment among robots; (2) collision-free path planning and coordinated motion planning are developed via dynamic searching in robotic coordinate space and perturbation of probe poses or local paths in the conflicting robots. A case study shows that the proposed approach can mitigate the risk of collisions between robots and environments, resolve conflicts among robots, and reduce the inspection cycle time significantly and consistently.
Ensemble Framework for Real-time Decision Making
Jun 21, 2017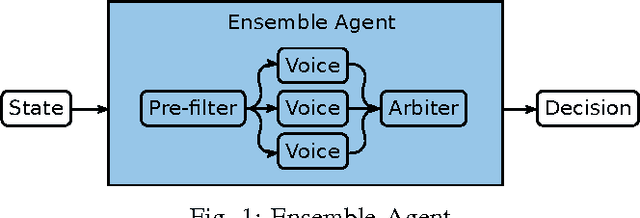

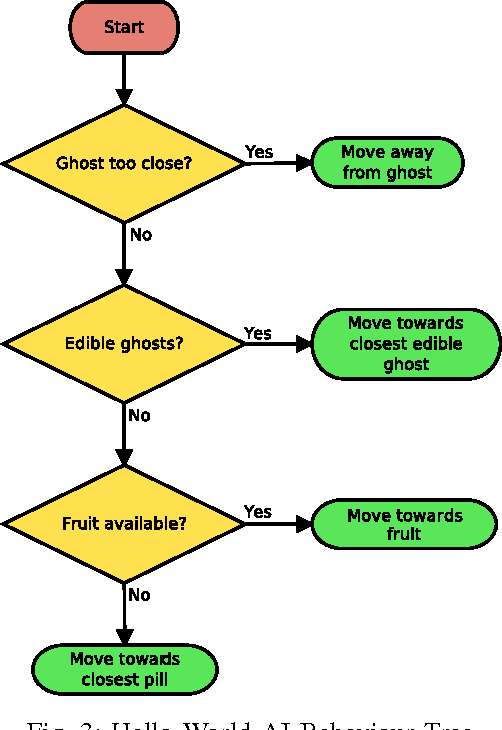
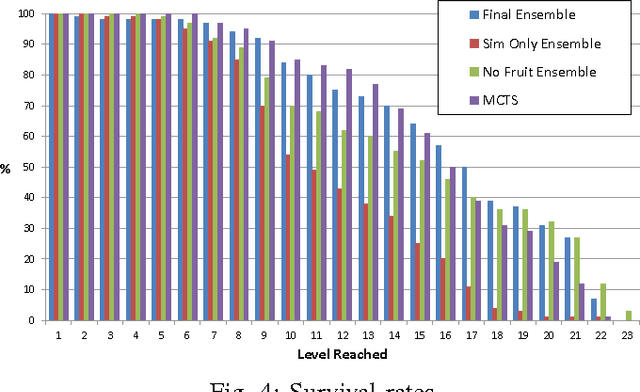
This paper introduces a new framework for real-time decision making in video games. An Ensemble agent is a compound agent composed of multiple agents, each with its own tasks or goals to achieve. Usually when dealing with real-time decision making, reactive agents are used; that is agents that return a decision based on the current state. While reactive agents are very fast, most games require more than just a rule-based agent to achieve good results. Deliberative agents---agents that use a forward model to search future states---are very useful in games with no hard time limit, such as Go or Backgammon, but generally take too long for real-time games. The Ensemble framework addresses this issue by allowing the agent to be both deliberative and reactive at the same time. This is achieved by breaking up the game-play into logical roles and having highly focused components for each role, with each component disregarding anything outwith its own role. Reactive agents can be used where a reactive agent is suited to the role, and where a deliberative approach is required, branching is kept to a minimum by the removal of all extraneous factors, enabling an informed decision to be made within a much smaller time-frame. An Arbiter is used to combine the component results, allowing high performing agents to be created from simple, efficient components.
Graph Similarity Description: How Are These Graphs Similar?
May 29, 2021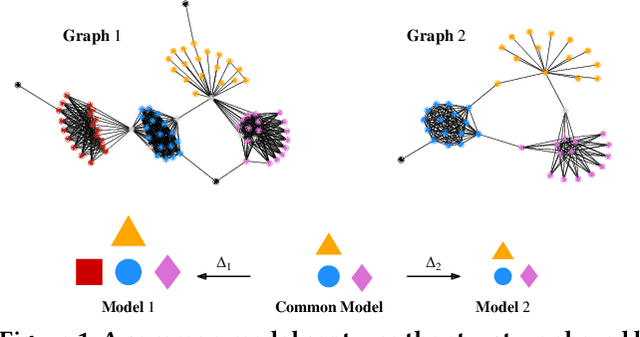
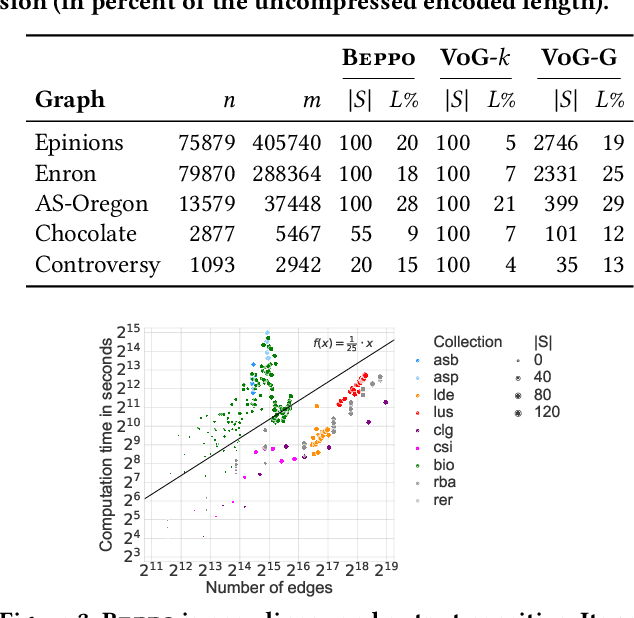
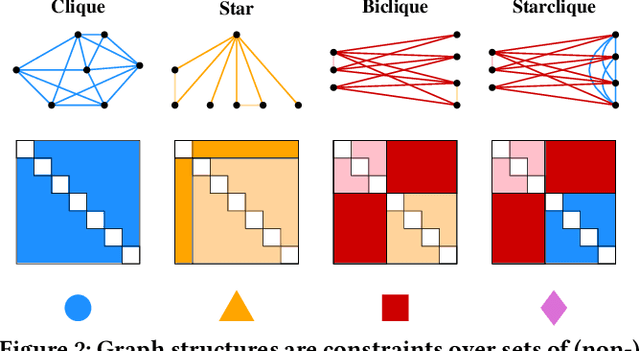

How do social networks differ across platforms? How do information networks change over time? Answering questions like these requires us to compare two or more graphs. This task is commonly treated as a measurement problem, but numerical answers give limited insight. Here, we argue that if the goal is to gain understanding, we should treat graph similarity assessment as a description problem instead. We formalize this problem as a model selection task using the Minimum Description Length principle, capturing the similarity of the input graphs in a common model and the differences between them in transformations to individual models. To discover good models, we propose Momo, which breaks the problem into two parts and introduces efficient algorithms for each. Through an extensive set of experiments on a wide range of synthetic and real-world graphs, we confirm that Momo works well in practice.
Deep Neural Network Modeling of Unknown Partial Differential Equations in Nodal Space
Jun 07, 2021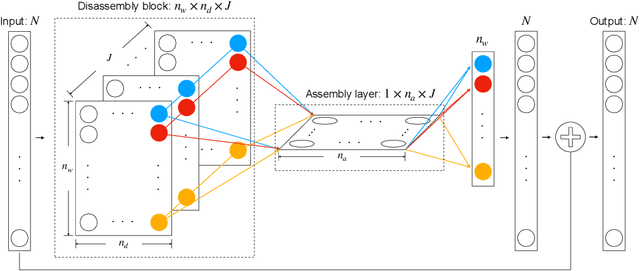

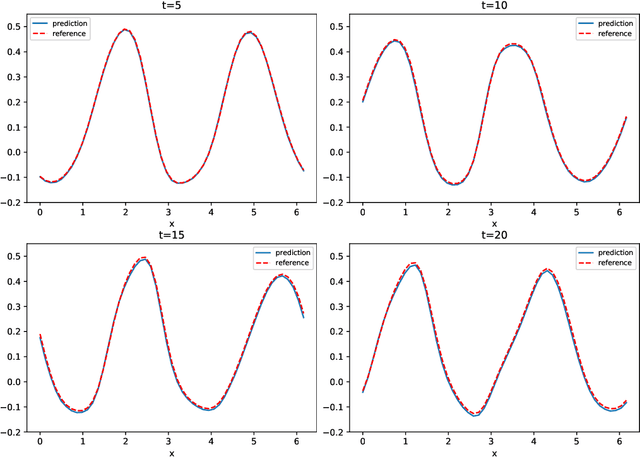
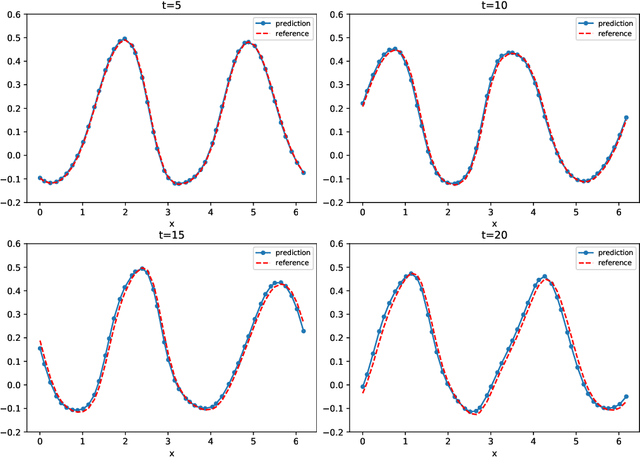
We present a numerical framework for deep neural network (DNN) modeling of unknown time-dependent partial differential equations (PDE) using their trajectory data. Unlike the recent work of [Wu and Xiu, J. Comput. Phys. 2020], where the learning takes place in modal/Fourier space, the current method conducts the learning and modeling in physical space and uses measurement data as nodal values. We present a DNN structure that has a direct correspondence to the evolution operator of the underlying PDE, thus establishing the existence of the DNN model. The DNN model also does not require any geometric information of the data nodes. Consequently, a trained DNN defines a predictive model for the underlying unknown PDE over structureless grids. A set of examples, including linear and nonlinear scalar PDE, system of PDEs, in both one dimension and two dimensions, over structured and unstructured grids, are presented to demonstrate the effectiveness of the proposed DNN modeling. Extension to other equations such as differential-integral equations is also discussed.
On the Theory of Reinforcement Learning with Once-per-Episode Feedback
May 29, 2021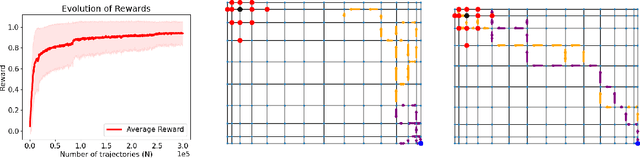
We introduce a theory of reinforcement learning (RL) in which the learner receives feedback only once at the end of an episode. While this is an extreme test case for theory, it is also arguably more representative of real-world applications than the traditional requirement in RL practice that the learner receive feedback at every time step. Indeed, in many real-world applications of reinforcement learning, such as self-driving cars and robotics, it is easier to evaluate whether a learner's complete trajectory was either "good" or "bad," but harder to provide a reward signal at each step. To show that learning is possible in this more challenging setting, we study the case where trajectory labels are generated by an unknown parametric model, and provide a statistically and computationally efficient algorithm that achieves sub-linear regret.
EventDrop: data augmentation for event-based learning
Jun 07, 2021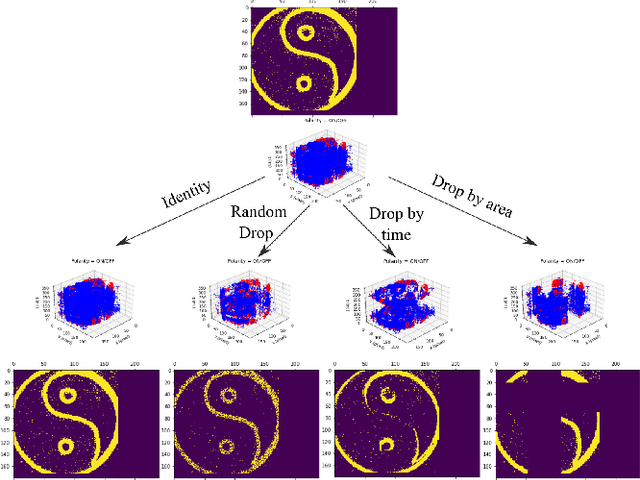
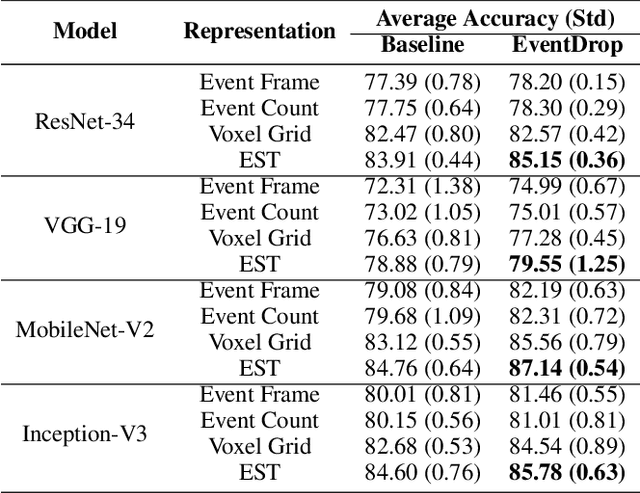
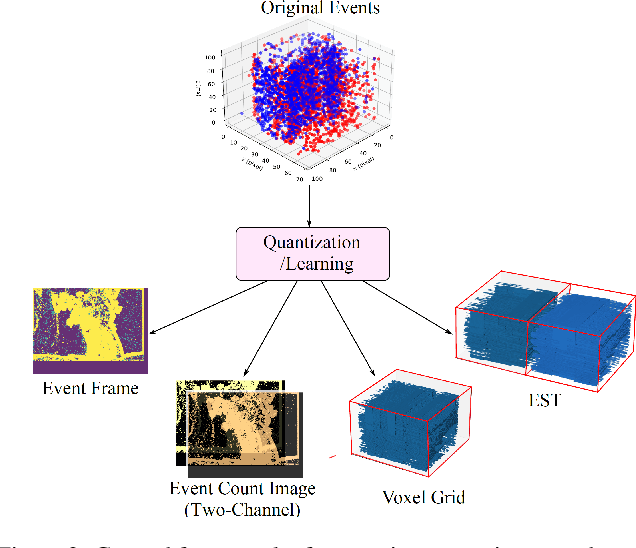
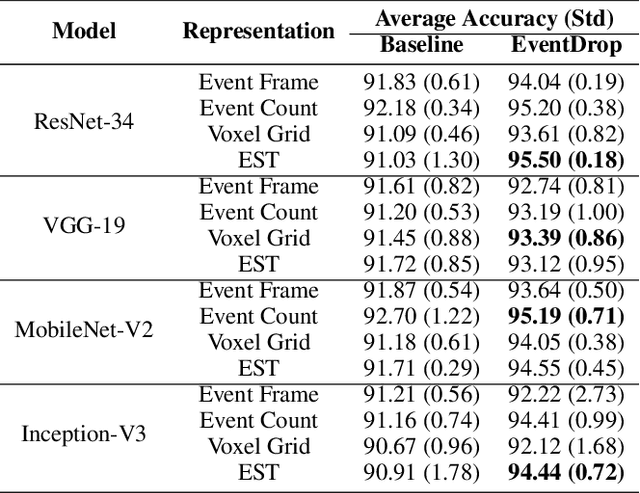
The advantages of event-sensing over conventional sensors (e.g., higher dynamic range, lower time latency, and lower power consumption) have spurred research into machine learning for event data. Unsurprisingly, deep learning has emerged as a competitive methodology for learning with event sensors; in typical setups, discrete and asynchronous events are first converted into frame-like tensors on which standard deep networks can be applied. However, over-fitting remains a challenge, particularly since event datasets remain small relative to conventional datasets (e.g., ImageNet). In this paper, we introduce EventDrop, a new method for augmenting asynchronous event data to improve the generalization of deep models. By dropping events selected with various strategies, we are able to increase the diversity of training data (e.g., to simulate various levels of occlusion). From a practical perspective, EventDrop is simple to implement and computationally low-cost. Experiments on two event datasets (N-Caltech101 and N-Cars) demonstrate that EventDrop can significantly improve the generalization performance across a variety of deep networks.
Simultaneous boundary shape estimation and velocity field de-noising in Magnetic Resonance Velocimetry using Physics-informed Neural Networks
Jul 16, 2021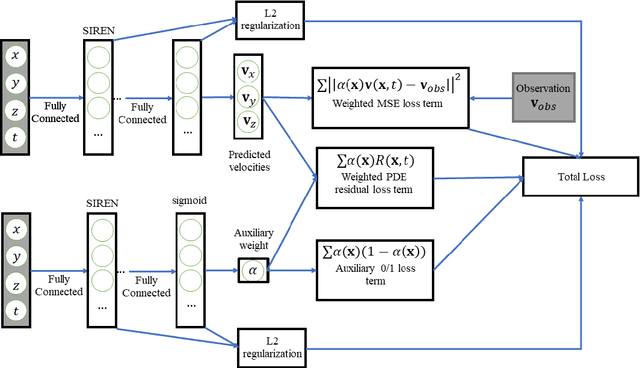
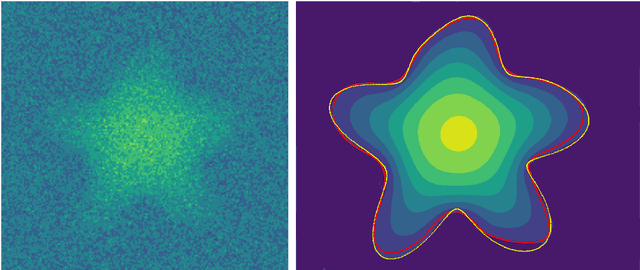
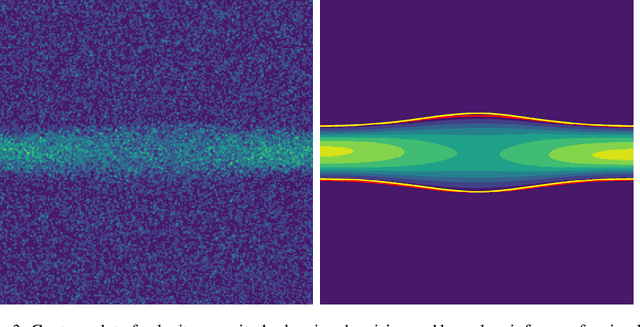
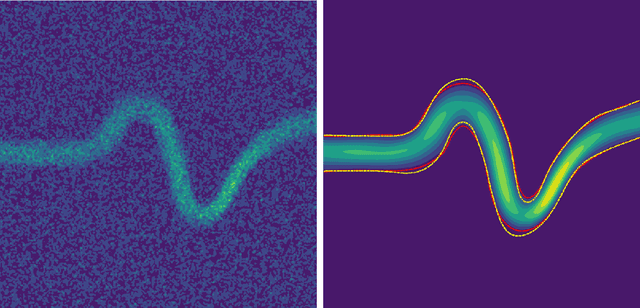
Magnetic resonance velocimetry (MRV) is a non-invasive experimental technique widely used in medicine and engineering to measure the velocity field of a fluid. These measurements are dense but have a low signal-to-noise ratio (SNR). The measurements can be de-noised by imposing physical constraints on the flow, which are encapsulated in governing equations for mass and momentum. Previous studies have required the shape of the boundary (for example, a blood vessel) to be known a priori. This, however, requires a set of additional measurements, which can be expensive to obtain. In this paper, we present a physics-informed neural network that instead uses the noisy MRV data alone to simultaneously infer the most likely boundary shape and de-noised velocity field. We achieve this by training an auxiliary neural network that takes the value 1.0 within the inferred domain of the governing PDE and 0.0 outside. This network is used to weight the PDE residual term in the loss function accordingly and implicitly learns the geometry of the system. We test our algorithm by assimilating both synthetic and real MRV measurements for flows that can be well modeled by the Poisson and Stokes equations. We find that we are able to reconstruct very noisy (SNR = 2.5) MRV signals and recover the ground truth with low reconstruction errors of 3.7 - 7.5%. The simplicity and flexibility of our physics-informed neural network approach can readily scale to assimilating MRV data with complex 3D geometries, time-varying 4D data, or unknown parameters in the physical model.