 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroVE: Brain-inspired Linear-Angular Velocity Estimation with Spiking Neural Networks
Aug 28, 2024



Vision-based ego-velocity estimation is a fundamental problem in robot state estimation. However, the constraints of frame-based cameras, including motion blur and insufficient frame rates in dynamic settings, readily lead to the failure of conventional velocity estimation techniques. Mammals exhibit a remarkable ability to accurately estimate their ego-velocity during aggressive movement. Hence, integrating this capability into robots shows great promise for addressing these challenges. In this paper, we propose a brain-inspired framework for linear-angular velocity estimation, dubbed NeuroVE. The NeuroVE framework employs an event camera to capture the motion information and implements spiking neural networks (SNNs) to simulate the brain's spatial cells' function for velocity estimation. We formulate the velocity estimation as a time-series forecasting problem. To this end, we design an Astrocyte Leaky Integrate-and-Fire (ALIF) neuron model to encode continuous values. Additionally, we have developed an Astrocyte Spiking Long Short-term Memory (ASLSTM) structure, which significantly improves the time-series forecasting capabilities, enabling an accurate estimate of ego-velocity. Results from both simulation and real-world experiments indicate that NeuroVE has achieved an approximate 60% increase in accuracy compared to other SNN-based approaches.
EventDrop: data augmentation for event-based learning
Jun 07, 2021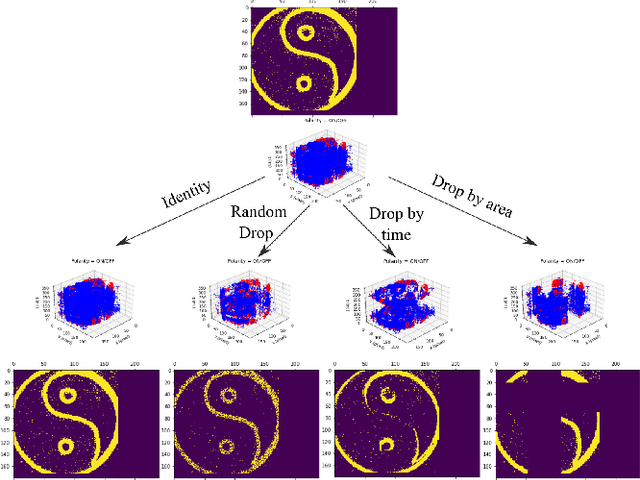
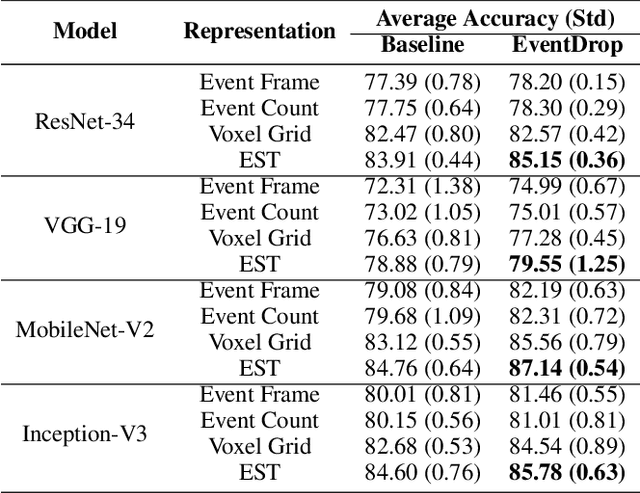
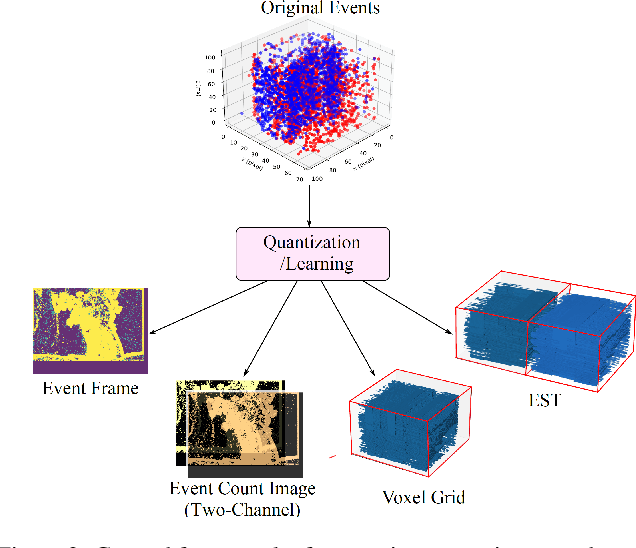
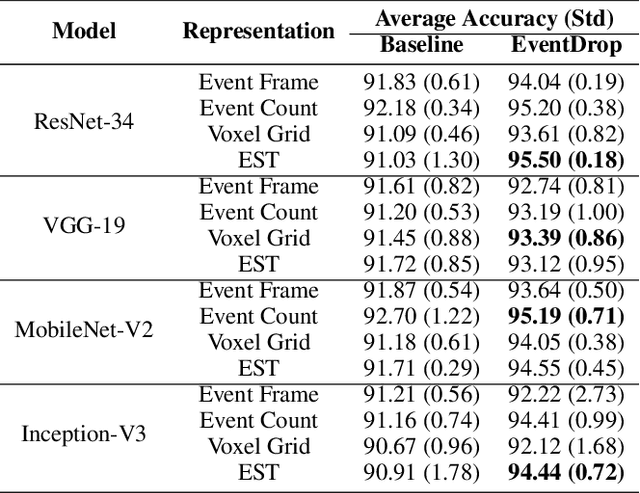
The advantages of event-sensing over conventional sensors (e.g., higher dynamic range, lower time latency, and lower power consumption) have spurred research into machine learning for event data. Unsurprisingly, deep learning has emerged as a competitive methodology for learning with event sensors; in typical setups, discrete and asynchronous events are first converted into frame-like tensors on which standard deep networks can be applied. However, over-fitting remains a challenge, particularly since event datasets remain small relative to conventional datasets (e.g., ImageNet). In this paper, we introduce EventDrop, a new method for augmenting asynchronous event data to improve the generalization of deep models. By dropping events selected with various strategies, we are able to increase the diversity of training data (e.g., to simulate various levels of occlusion). From a practical perspective, EventDrop is simple to implement and computationally low-cost. Experiments on two event datasets (N-Caltech101 and N-Cars) demonstrate that EventDrop can significantly improve the generalization performance across a variety of deep networks.
Camera Frame Misalignment in a Teleoperated Eye-in-Hand Robot: Effects and a Simple Correction Method
May 18, 2021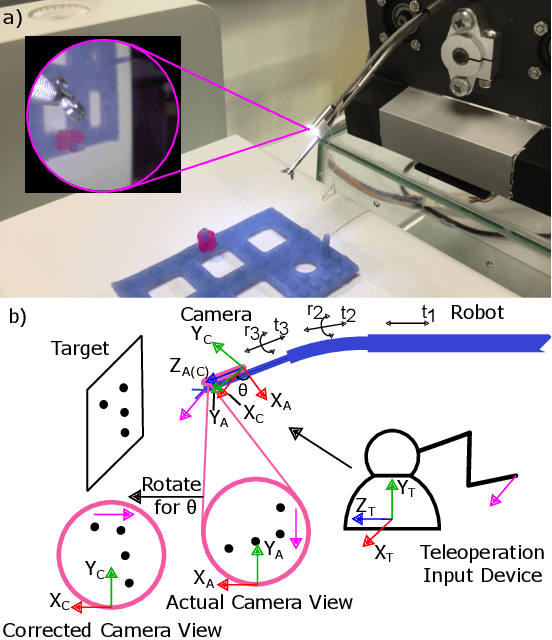
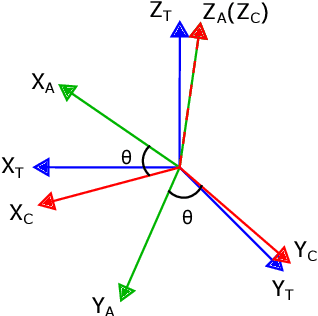
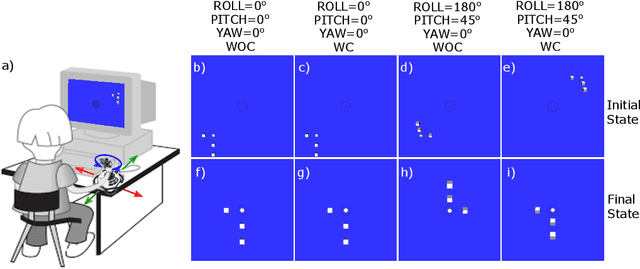
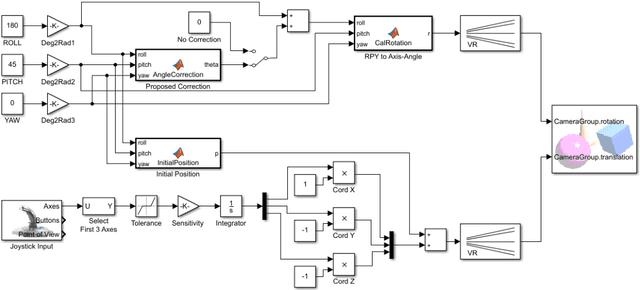
Misalignment between the camera frame and the operator frame is commonly seen in a teleoperated system and usually degrades the operation performance. The effects of such misalignment have not been fully investigated for eye-in-hand systems - systems that have the camera (eye) mounted to the end-effector (hand) to gain compactness in confined spaces such as in endoscopic surgery. This paper provides a systematic study on the effects of the camera frame misalignment in a teleoperated eye-in-hand robot and proposes a simple correction method in the view display. A simulation is designed to compare the effects of the misalignment under different conditions. Users are asked to move a rigid body from its initial position to the specified target position via teleoperation, with different levels of misalignment simulated. It is found that misalignment between the input motion and the output view is much more difficult to compensate by the operators when it is in the orthogonal direction (~40s) compared with the opposite direction (~20s). An experiment on a real concentric tube robot with an eye-in-hand configuration is also conducted. Users are asked to telemanipulate the robot to complete a pick-and-place task. Results show that with the correction enabled, there is a significant improvement in the operation performance in terms of completion time (mean 40.6%, median 38.6%), trajectory length (mean 34.3%, median 28.1%), difficulty (50.5%), unsteadiness (49.4%), and mental stress (60.9%).