 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Combine Per-Example Solutions for Neural Program Synthesis
Jun 14, 2021
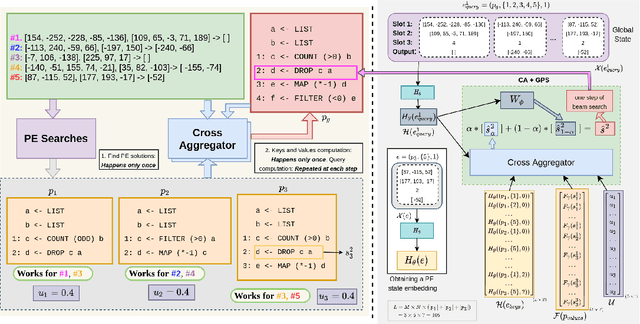

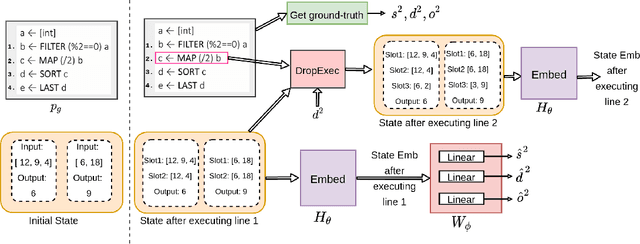
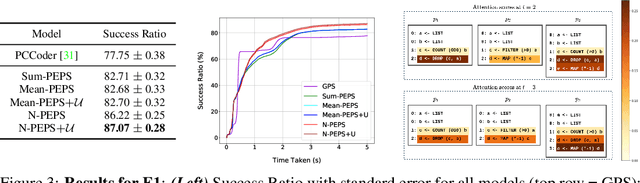
The goal of program synthesis from examples is to find a computer program that is consistent with a given set of input-output examples. Most learning-based approaches try to find a program that satisfies all examples at once. Our work, by contrast, considers an approach that breaks the problem into two stages: (a) find programs that satisfy only one example, and (b) leverage these per-example solutions to yield a program that satisfies all examples. We introduce the Cross Aggregator neural network module based on a multi-head attention mechanism that learns to combine the cues present in these per-example solutions to synthesize a global solution. Evaluation across programs of different lengths and under two different experimental settings reveal that when given the same time budget, our technique significantly improves the success rate over PCCoder arXiv:1809.04682v2 [cs.LG] and other ablation baselines. The code, data and trained models for our work can be found at https://github.com/shrivastavadisha/N-PEPS.
CFTrack: Center-based Radar and Camera Fusion for 3D Multi-Object Tracking
Jul 11, 2021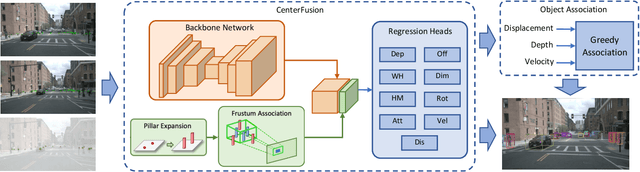
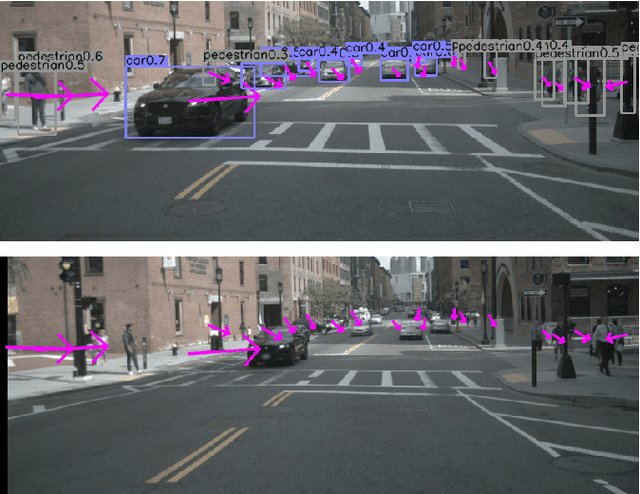
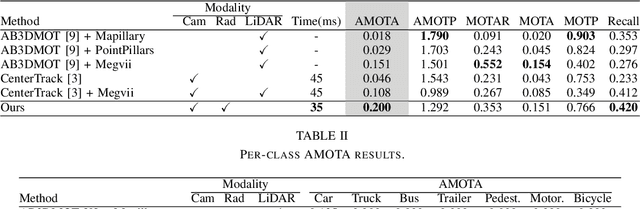
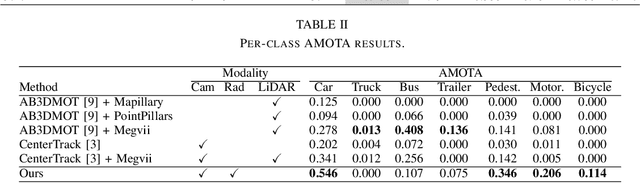
3D multi-object tracking is a crucial component in the perception system of autonomous driving vehicles. Tracking all dynamic objects around the vehicle is essential for tasks such as obstacle avoidance and path planning. Autonomous vehicles are usually equipped with different sensor modalities to improve accuracy and reliability. While sensor fusion has been widely used in object detection networks in recent years, most existing multi-object tracking algorithms either rely on a single input modality, or do not fully exploit the information provided by multiple sensing modalities. In this work, we propose an end-to-end network for joint object detection and tracking based on radar and camera sensor fusion. Our proposed method uses a center-based radar-camera fusion algorithm for object detection and utilizes a greedy algorithm for object association. The proposed greedy algorithm uses the depth, velocity and 2D displacement of the detected objects to associate them through time. This makes our tracking algorithm very robust to occluded and overlapping objects, as the depth and velocity information can help the network in distinguishing them. We evaluate our method on the challenging nuScenes dataset, where it achieves 20.0 AMOTA and outperforms all vision-based 3D tracking methods in the benchmark, as well as the baseline LiDAR-based method. Our method is online with a runtime of 35ms per image, making it very suitable for autonomous driving applications.
Neural Pharmacodynamic State Space Modeling
Feb 22, 2021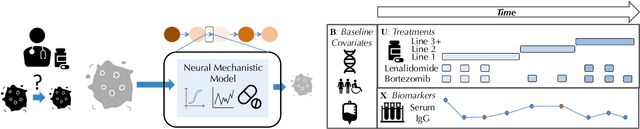
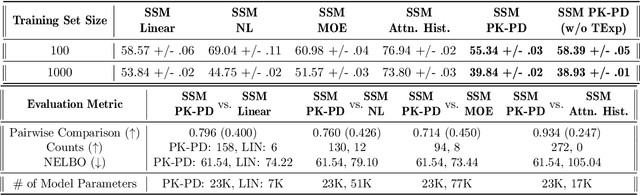
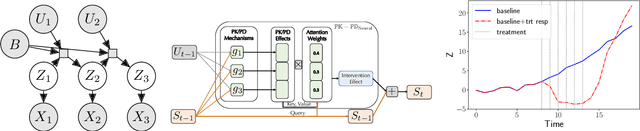
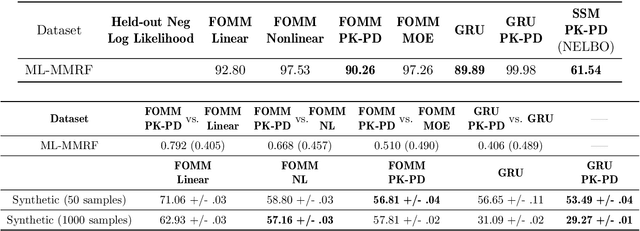
Modeling the time-series of high-dimensional, longitudinal data is important for predicting patient disease progression. However, existing neural network based approaches that learn representations of patient state, while very flexible, are susceptible to overfitting. We propose a deep generative model that makes use of a novel attention-based neural architecture inspired by the physics of how treatments affect disease state. The result is a scalable and accurate model of high-dimensional patient biomarkers as they vary over time. Our proposed model yields significant improvements in generalization and, on real-world clinical data, provides interpretable insights into the dynamics of cancer progression.
Dueling Bandits with Adversarial Sleeping
Jul 05, 2021
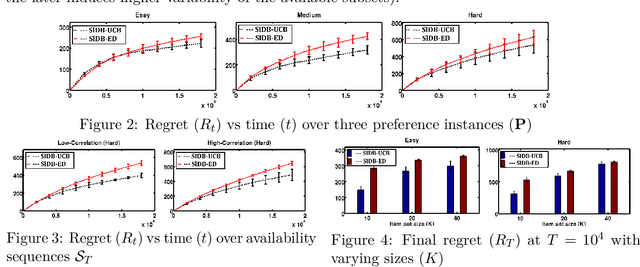
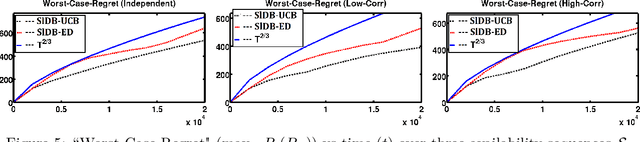
We introduce the problem of sleeping dueling bandits with stochastic preferences and adversarial availabilities (DB-SPAA). In almost all dueling bandit applications, the decision space often changes over time; eg, retail store management, online shopping, restaurant recommendation, search engine optimization, etc. Surprisingly, this `sleeping aspect' of dueling bandits has never been studied in the literature. Like dueling bandits, the goal is to compete with the best arm by sequentially querying the preference feedback of item pairs. The non-triviality however results due to the non-stationary item spaces that allow any arbitrary subsets items to go unavailable every round. The goal is to find an optimal `no-regret' policy that can identify the best available item at each round, as opposed to the standard `fixed best-arm regret objective' of dueling bandits. We first derive an instance-specific lower bound for DB-SPAA $\Omega( \sum_{i =1}^{K-1}\sum_{j=i+1}^K \frac{\log T}{\Delta(i,j)})$, where $K$ is the number of items and $\Delta(i,j)$ is the gap between items $i$ and $j$. This indicates that the sleeping problem with preference feedback is inherently more difficult than that for classical multi-armed bandits (MAB). We then propose two algorithms, with near optimal regret guarantees. Our results are corroborated empirically.
Self-Supervised Learning for Personalized Speech Enhancement
Apr 05, 2021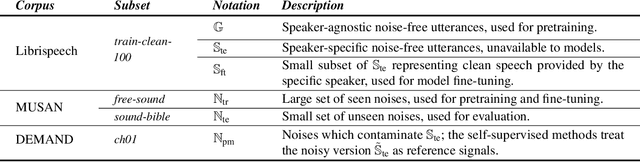


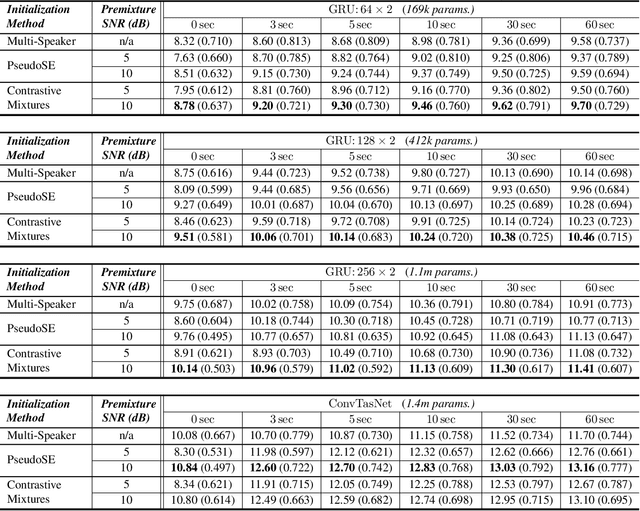
Speech enhancement systems can show improved performance by adapting the model towards a single test-time speaker. In this personalization context, the test-time user might only provide a small amount of noise-free speech data, likely insufficient for traditional fully-supervised learning. One way to overcome the lack of personal data is to transfer the model parameters from a speaker-agnostic model to initialize the personalized model, and then to finetune the model using the small amount of personal speech data. This baseline marginally adapts over the scarce clean speech data. Alternatively, we propose self-supervised methods that are designed specifically to learn personalized and discriminative features from abundant in-the-wild noisy, but still personal speech recordings. Our experiment shows that the proposed self-supervised learning methods initialize personalized speech enhancement models better than the baseline fully-supervised methods, yielding superior speech enhancement performance. The proposed methods also result in a more robust feature set under the real-world conditions: compressed model sizes and fewness of the labeled data.
A Deep Learning Approach for Real-Time 3D Human Action Recognition from Skeletal Data
Jul 08, 2019
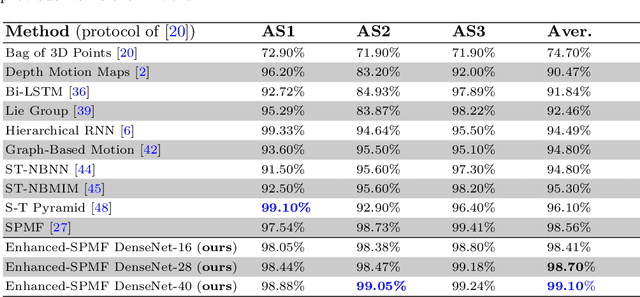

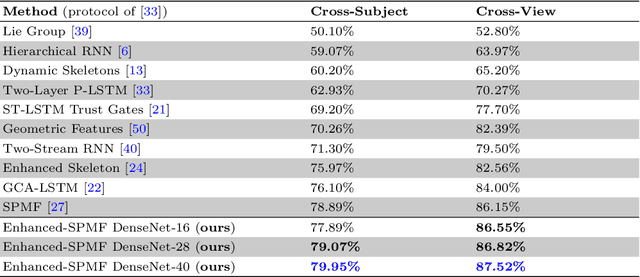
We present a new deep learning approach for real-time 3D human action recognition from skeletal data and apply it to develop a vision-based intelligent surveillance system. Given a skeleton sequence, we propose to encode skeleton poses and their motions into a single RGB image. An Adaptive Histogram Equalization (AHE) algorithm is then applied on the color images to enhance their local patterns and generate more discriminative features. For learning and classification tasks, we design Deep Neural Networks based on the Densely Connected Convolutional Architecture (DenseNet) to extract features from enhanced-color images and classify them into classes. Experimental results on two challenging datasets show that the proposed method reaches state-of-the-art accuracy, whilst requiring low computational time for training and inference. This paper also introduces CEMEST, a new RGB-D dataset depicting passenger behaviors in public transport. It consists of 203 untrimmed real-world surveillance videos of realistic normal and anomalous events. We achieve promising results on real conditions of this dataset with the support of data augmentation and transfer learning techniques. This enables the construction of real-world applications based on deep learning for enhancing monitoring and security in public transport.
Angel's Girl for Blind Painters: an Efficient Painting Navigation System Validated by Multimodal Evaluation Approach
Jul 27, 2021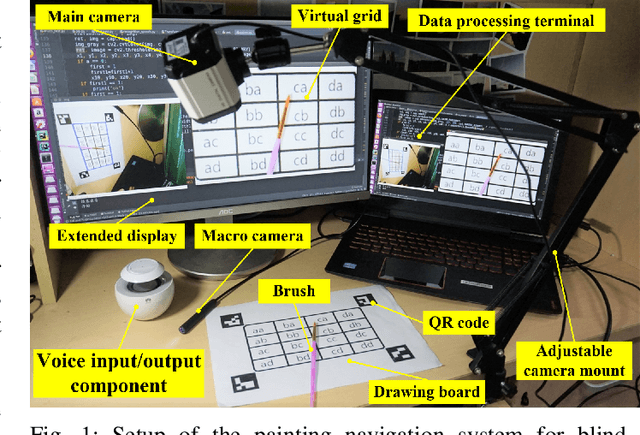
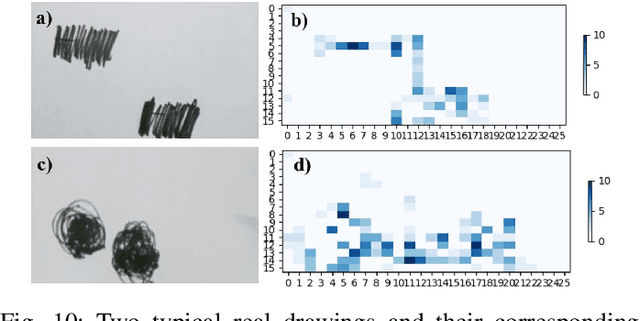
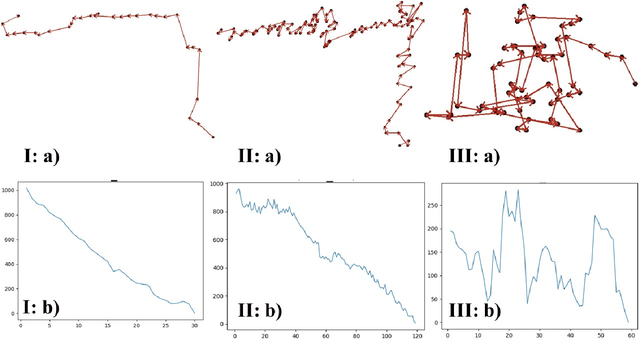

For people who ardently love painting but unfortunately have visual impairments, holding a paintbrush to create a work is a very difficult task. People in this special group are eager to pick up the paintbrush, like Leonardo da Vinci, to create and make full use of their own talents. Therefore, to maximally bridge this gap, we propose a painting navigation system to assist blind people in painting and artistic creation. The proposed system is composed of cognitive system and guidance system. The system adopts drawing board positioning based on QR code, brush navigation based on target detection and bush real-time positioning. Meanwhile, this paper uses human-computer interaction on the basis of voice and a simple but efficient position information coding rule. In addition, we design a criterion to efficiently judge whether the brush reaches the target or not. According to the experimental results, the thermal curves extracted from the faces of testers show that it is relatively well accepted by blindfolded and even blind testers. With the prompt frequency of 1s, the painting navigation system performs best with the completion degree of 89% with SD of 8.37% and overflow degree of 347% with SD of 162.14%. Meanwhile, the excellent and good types of brush tip trajectory account for 74%, and the relative movement distance is 4.21 with SD of 2.51. This work demonstrates that it is practicable for the blind people to feel the world through the brush in their hands. In the future, we plan to deploy Angle's Eyes on the phone to make it more portable. The demo video of the proposed painting navigation system is available at: https://doi.org/10.6084/m9.figshare.9760004.v1.
SinIR: Efficient General Image Manipulation with Single Image Reconstruction
Jun 14, 2021

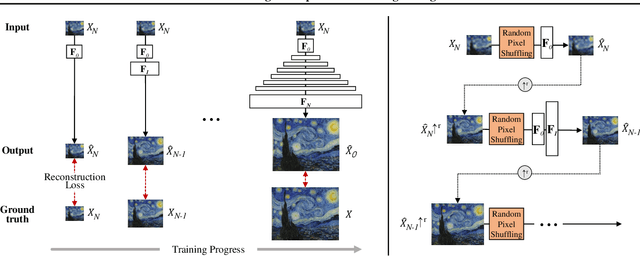
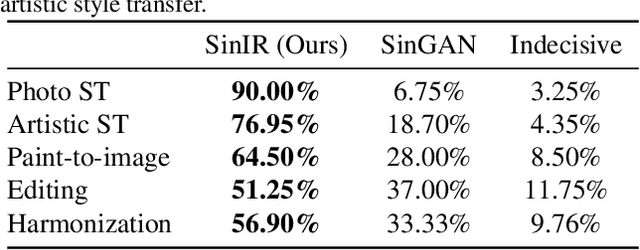
We propose SinIR, an efficient reconstruction-based framework trained on a single natural image for general image manipulation, including super-resolution, editing, harmonization, paint-to-image, photo-realistic style transfer, and artistic style transfer. We train our model on a single image with cascaded multi-scale learning, where each network at each scale is responsible for image reconstruction. This reconstruction objective greatly reduces the complexity and running time of training, compared to the GAN objective. However, the reconstruction objective also exacerbates the output quality. Therefore, to solve this problem, we further utilize simple random pixel shuffling, which also gives control over manipulation, inspired by the Denoising Autoencoder. With quantitative evaluation, we show that SinIR has competitive performance on various image manipulation tasks. Moreover, with a much simpler training objective (i.e., reconstruction), SinIR is trained 33.5 times faster than SinGAN (for 500 X 500 images) that solves similar tasks. Our code is publicly available at github.com/YooJiHyeong/SinIR.
Efficient inference of interventional distributions
Jul 27, 2021
We consider the problem of efficiently inferring interventional distributions in a causal Bayesian network from a finite number of observations. Let $\mathcal{P}$ be a causal model on a set $\mathbf{V}$ of observable variables on a given causal graph $G$. For sets $\mathbf{X},\mathbf{Y}\subseteq \mathbf{V}$, and setting ${\bf x}$ to $\mathbf{X}$, let $P_{\bf x}(\mathbf{Y})$ denote the interventional distribution on $\mathbf{Y}$ with respect to an intervention ${\bf x}$ to variables ${\bf x}$. Shpitser and Pearl (AAAI 2006), building on the work of Tian and Pearl (AAAI 2001), gave an exact characterization of the class of causal graphs for which the interventional distribution $P_{\bf x}({\mathbf{Y}})$ can be uniquely determined. We give the first efficient version of the Shpitser-Pearl algorithm. In particular, under natural assumptions, we give a polynomial-time algorithm that on input a causal graph $G$ on observable variables $\mathbf{V}$, a setting ${\bf x}$ of a set $\mathbf{X} \subseteq \mathbf{V}$ of bounded size, outputs succinct descriptions of both an evaluator and a generator for a distribution $\hat{P}$ that is $\varepsilon$-close (in total variation distance) to $P_{\bf x}({\mathbf{Y}})$ where $Y=\mathbf{V}\setminus \mathbf{X}$, if $P_{\bf x}(\mathbf{Y})$ is identifiable. We also show that when $\mathbf{Y}$ is an arbitrary set, there is no efficient algorithm that outputs an evaluator of a distribution that is $\varepsilon$-close to $P_{\bf x}({\mathbf{Y}})$ unless all problems that have statistical zero-knowledge proofs, including the Graph Isomorphism problem, have efficient randomized algorithms.
TSGN: Transaction Subgraph Networks for Identifying Ethereum Phishing Accounts
Apr 20, 2021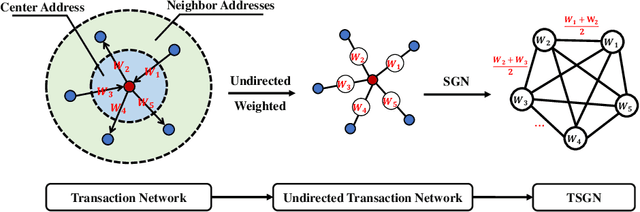
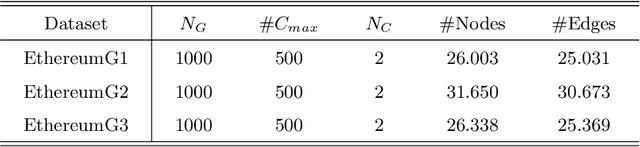
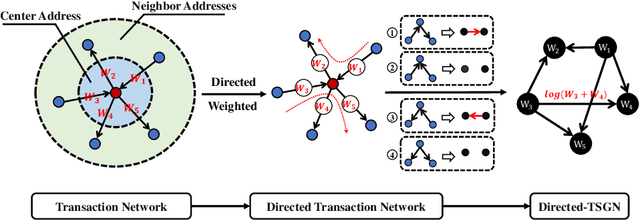
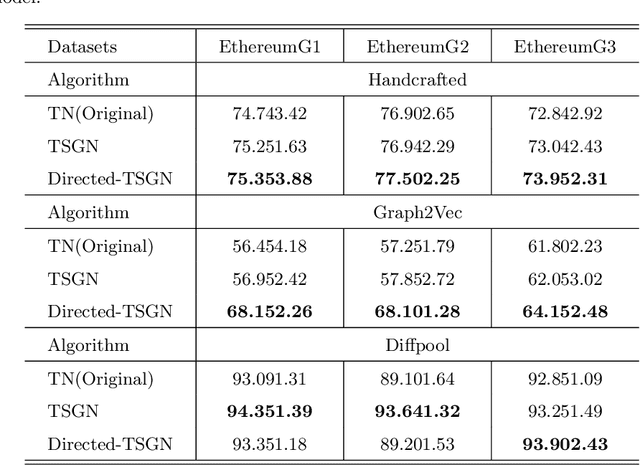
Blockchain technology and, in particular, blockchain-based transaction offers us information that has never been seen before in the financial world. In contrast to fiat currencies, transactions through virtual currencies like Bitcoin are completely public. And these transactions of cryptocurrencies are permanently recorded on Blockchain and are available at any time. Therefore, this allows us to build transaction networks (TN) to analyze illegal phenomenons such as phishing scams in blockchain from a network perspective. In this paper, we propose a Transaction SubGraph Network (TSGN) based classification model to identify phishing accounts in Ethereum. Firstly we extract transaction subgraphs for each address and then expand these subgraphs into corresponding TSGNs based on the different mapping mechanisms. We find that TSGNs can provide more potential information to benefit the identification of phishing accounts. Moreover, Directed-TSGNs, by introducing direction attributes, can retain the transaction flow information that captures the significant topological pattern of phishing scams. By comparing with the TSGN, Directed-TSGN indeed has much lower time complexity, benefiting the graph representation learning. Experimental results demonstrate that, combined with network representation algorithms, the TSGN model can capture more features to enhance the classification algorithm and improve phishing nodes' identification accuracy in the Ethereum networks.