 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On The State of Data In Computer Vision: Human Annotations Remain Indispensable for Developing Deep Learning Models
Jul 31, 2021
High-quality labeled datasets play a crucial role in fueling the development of machine learning (ML), and in particular the development of deep learning (DL). However, since the emergence of the ImageNet dataset and the AlexNet model in 2012, the size of new open-source labeled vision datasets has remained roughly constant. Consequently, only a minority of publications in the computer vision community tackle supervised learning on datasets that are orders of magnitude larger than Imagenet. In this paper, we survey computer vision research domains that study the effects of such large datasets on model performance across different vision tasks. We summarize the community's current understanding of those effects, and highlight some open questions related to training with massive datasets. In particular, we tackle: (a) The largest datasets currently used in computer vision research and the interesting takeaways from training on such datasets; (b) The effectiveness of pre-training on large datasets; (c) Recent advancements and hurdles facing synthetic datasets; (d) An overview of double descent and sample non-monotonicity phenomena; and finally, (e) A brief discussion of lifelong/continual learning and how it fares compared to learning from huge labeled datasets in an offline setting. Overall, our findings are that research on optimization for deep learning focuses on perfecting the training routine and thus making DL models less data hungry, while research on synthetic datasets aims to offset the cost of data labeling. However, for the time being, acquiring non-synthetic labeled data remains indispensable to boost performance.
End-to-end Deep Learning Pipeline for Microwave Kinetic Inductance Detector (MKID) Resonator Identification and Tuning
Apr 03, 2021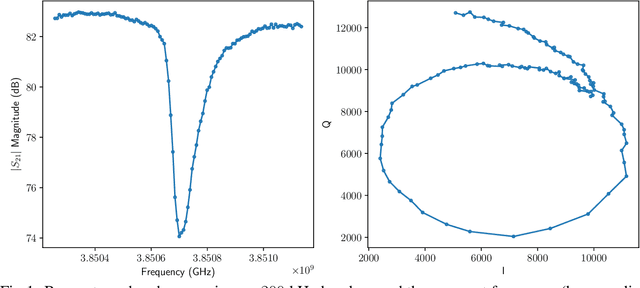

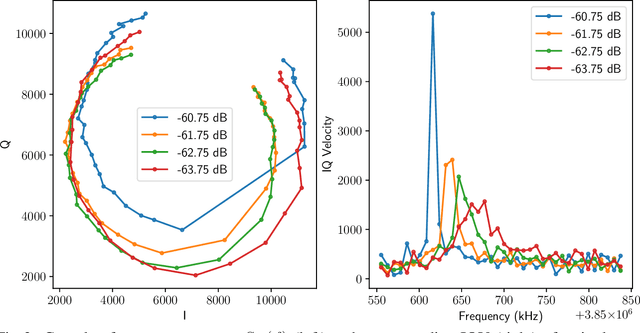

We present the development of a machine learning based pipeline to fully automate the calibration of the frequency comb used to read out optical/IR Microwave Kinetic Inductance Detector (MKID) arrays. This process involves determining the resonant frequency and optimal drive power of every pixel (i.e. resonator) in the array, which is typically done manually. Modern optical/IR MKID arrays, such as DARKNESS (DARK-speckle Near-infrared Energy-resolving Superconducting Spectrophotometer) and MEC (MKID Exoplanet Camera), contain 10-20,000 pixels, making the calibration process extremely time consuming; each 2000 pixel feedline requires 4-6 hours of manual tuning. Here we present a pipeline which uses a single convolutional neural network (CNN) to perform both resonator identification and tuning simultaneously. We find that our pipeline has performance equal to that of the manual tuning process, and requires just twelve minutes of computational time per feedline.
Guaranteed Fixed-Confidence Best Arm Identification in Multi-Armed Bandits: Simple Sequential Elimination Algorithms
Jun 18, 2021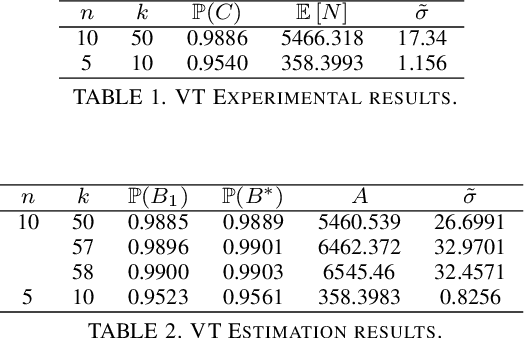
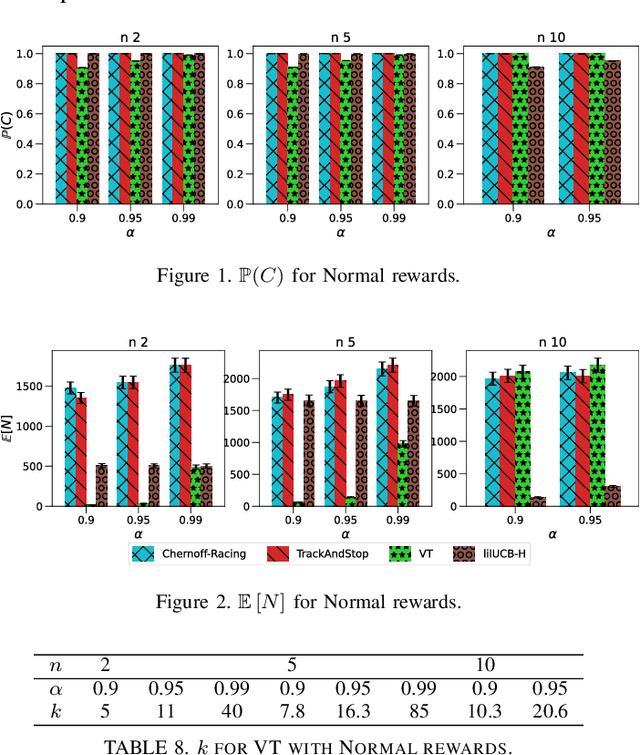
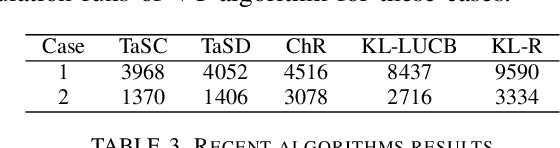
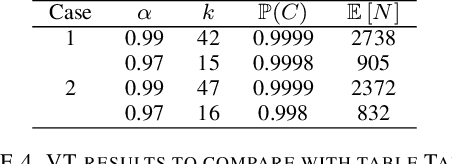
We consider the problem of finding, through adaptive sampling, which of n arms (arms) has the largest mean. Our objective is to determine a rule which identifies the best arm with a fixed minimum confidence using as few observations as possible, i.e. fixed-confidence (FC) best arm identification (BAI) in multi-armed bandits. We study such problems under the Bayesian setting with both Bernoulli and Gaussian arms. We propose to use the classical vector at a time (VT) rule, which samples each remaining arm once in each round. We show how VT can be implemented and analyzed in our Bayesian setting and be improved by early elimination. Our analysis show that these algorithms guarantee an optimal strategy under the prior. We also propose and analyze a variant of the classical play the winner (PW) algorithm. Numerical results show that these rules compare favorably with state-of-art algorithms.
KaFiStO: A Kalman Filtering Framework for Stochastic Optimization
Jul 07, 2021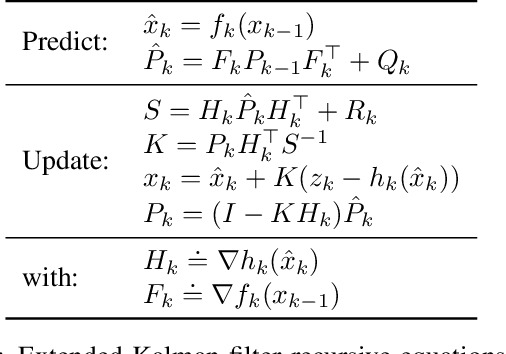
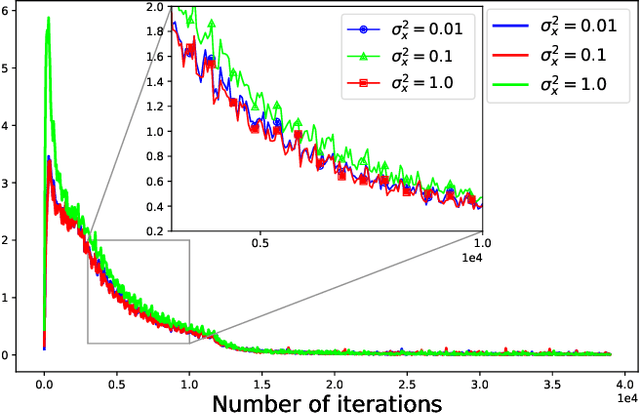
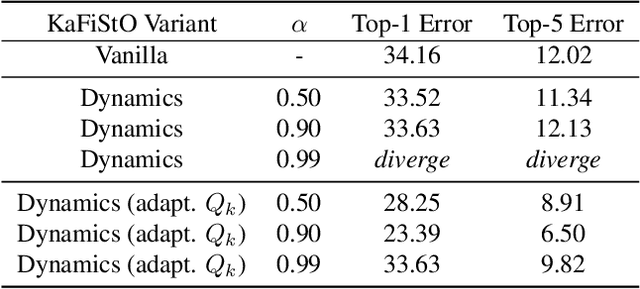
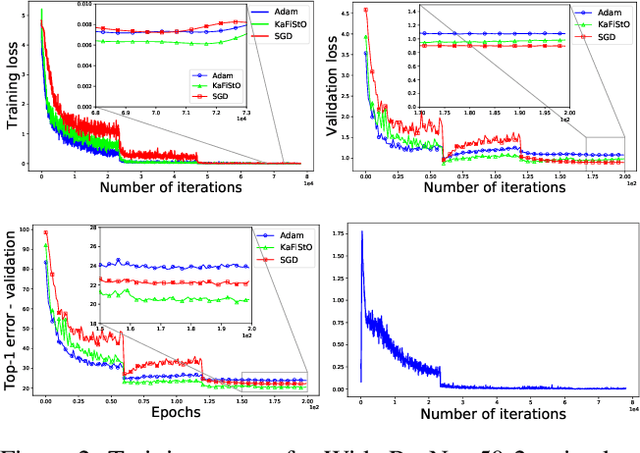
Optimization is often cast as a deterministic problem, where the solution is found through some iterative procedure such as gradient descent. However, when training neural networks the loss function changes over (iteration) time due to the randomized selection of a subset of the samples. This randomization turns the optimization problem into a stochastic one. We propose to consider the loss as a noisy observation with respect to some reference optimum. This interpretation of the loss allows us to adopt Kalman filtering as an optimizer, as its recursive formulation is designed to estimate unknown parameters from noisy measurements. Moreover, we show that the Kalman Filter dynamical model for the evolution of the unknown parameters can be used to capture the gradient dynamics of advanced methods such as Momentum and Adam. We call this stochastic optimization method KaFiStO. KaFiStO is an easy to implement, scalable, and efficient method to train neural networks. We show that it also yields parameter estimates that are on par with or better than existing optimization algorithms across several neural network architectures and machine learning tasks, such as computer vision and language modeling.
SoundStream: An End-to-End Neural Audio Codec
Jul 07, 2021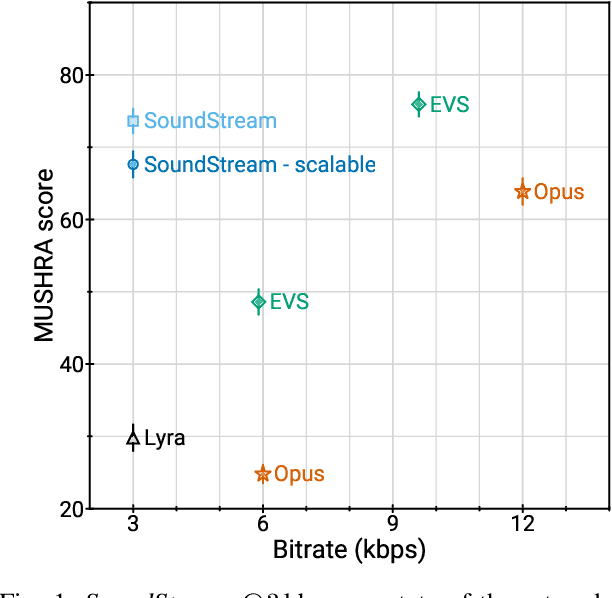
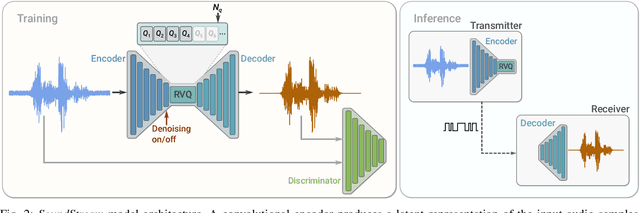
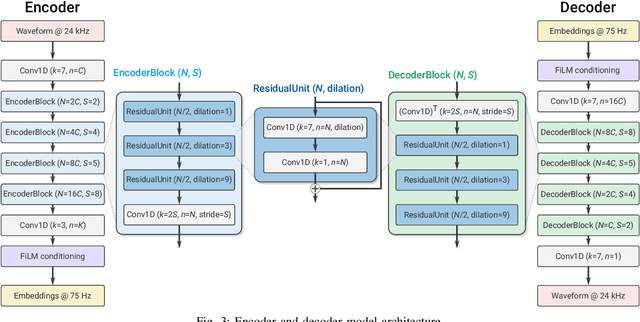
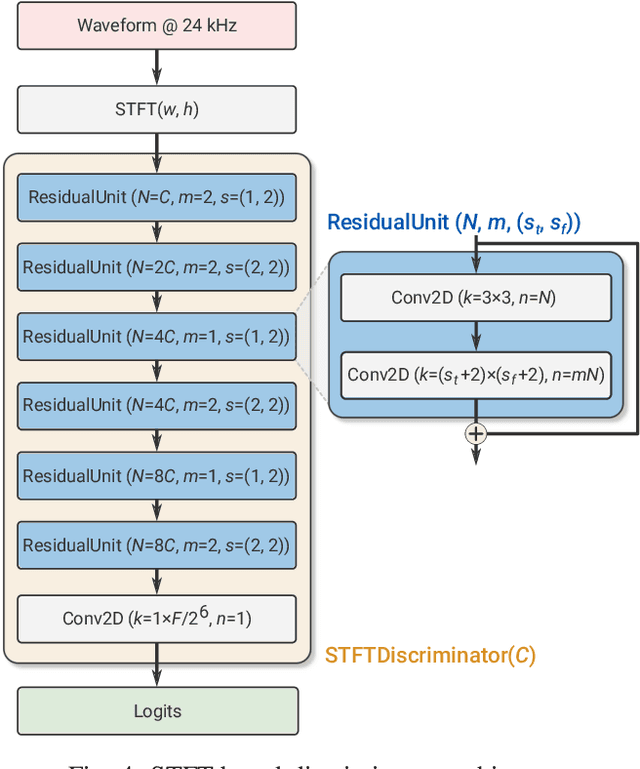
We present SoundStream, a novel neural audio codec that can efficiently compress speech, music and general audio at bitrates normally targeted by speech-tailored codecs. SoundStream relies on a model architecture composed by a fully convolutional encoder/decoder network and a residual vector quantizer, which are trained jointly end-to-end. Training leverages recent advances in text-to-speech and speech enhancement, which combine adversarial and reconstruction losses to allow the generation of high-quality audio content from quantized embeddings. By training with structured dropout applied to quantizer layers, a single model can operate across variable bitrates from 3kbps to 18kbps, with a negligible quality loss when compared with models trained at fixed bitrates. In addition, the model is amenable to a low latency implementation, which supports streamable inference and runs in real time on a smartphone CPU. In subjective evaluations using audio at 24kHz sampling rate, SoundStream at 3kbps outperforms Opus at 12kbps and approaches EVS at 9.6kbps. Moreover, we are able to perform joint compression and enhancement either at the encoder or at the decoder side with no additional latency, which we demonstrate through background noise suppression for speech.
Efficient Spatio-Temporal Recurrent Neural Network for Video Deblurring
Jun 30, 2021
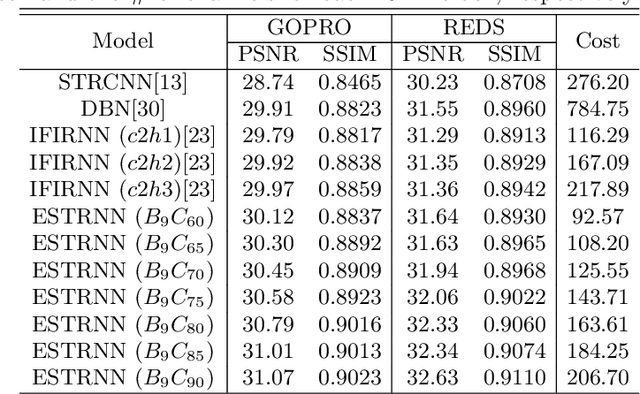
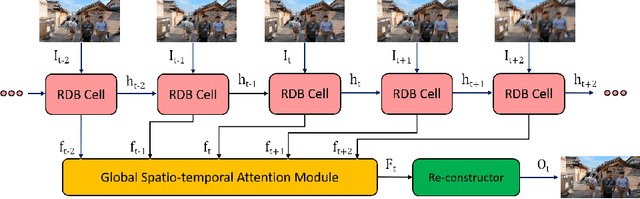
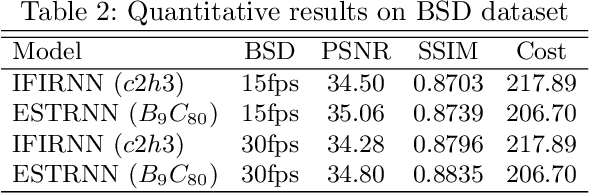
Real-time video deblurring still remains a challenging task due to the complexity of spatially and temporally varying blur itself and the requirement of low computational cost. To improve the network efficiency, we adopt residual dense blocks into RNN cells, so as to efficiently extract the spatial features of the current frame. Furthermore, a global spatio-temporal attention module is proposed to fuse the effective hierarchical features from past and future frames to help better deblur the current frame. Another issue needs to be addressed urgently is the lack of a real-world benchmark dataset. Thus, we contribute a novel dataset (BSD) to the community, by collecting paired blurry/sharp video clips using a co-axis beam splitter acquisition system. Experimental results show that the proposed method (ESTRNN) can achieve better deblurring performance both quantitatively and qualitatively with less computational cost against state-of-the-art video deblurring methods. In addition, cross-validation experiments between datasets illustrate the high generality of BSD over the synthetic datasets. The code and dataset are released at https://github.com/zzh-tech/ESTRNN.
Symplectic Gaussian Process Dynamics
Feb 02, 2021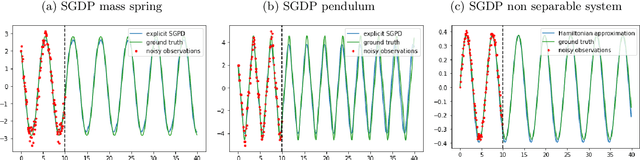
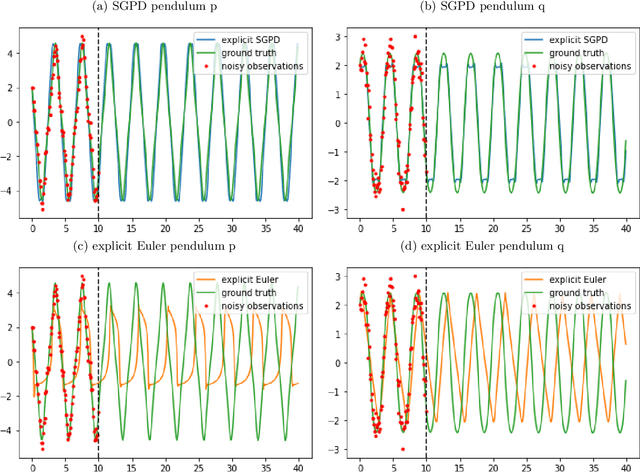

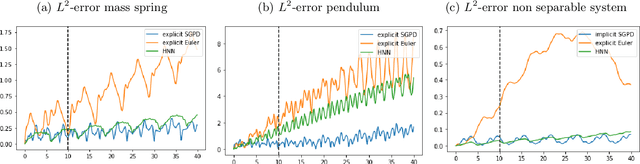
Dynamics model learning is challenging and at the same time an active field of research. Due to potential safety critical downstream applications, such as control tasks, there is a need for theoretical guarantees. While GPs induce rich theoretical guarantees as function approximators in space, they do not explicitly cope with the time aspect of dynamical systems. However, propagating system properties through time is exactly what classical numerical integrators were designed for. We introduce a recurrent sparse Gaussian process based variational inference scheme that is able to discretize the underlying system with any explicit or implicit single or multistep integrator, thus leveraging properties of numerical integrators. In particular we discuss Hamiltonian problems coupled with symplectic integrators producing volume preserving predictions.
Goal-Aware Neural SAT Solver
Jun 14, 2021Modern neural networks obtain information about the problem and calculate the output solely from the input values. We argue that it is not always optimal, and the network's performance can be significantly improved by augmenting it with a query mechanism that allows the network to make several solution trials at run time and get feedback on the loss value on each trial. To demonstrate the capabilities of the query mechanism, we formulate an unsupervised (not dependant on labels) loss function for Boolean Satisfiability Problem (SAT) and theoretically show that it allows the network to extract rich information about the problem. We then propose a neural SAT solver with a query mechanism called QuerySAT and show that it outperforms the neural baseline on a wide range of SAT tasks and the classical baselines on SHA-1 preimage attack and 3-SAT task.
Time-interval balancing in multi-processor scheduling of composite modular jobs (preliminary description)
Nov 11, 2018

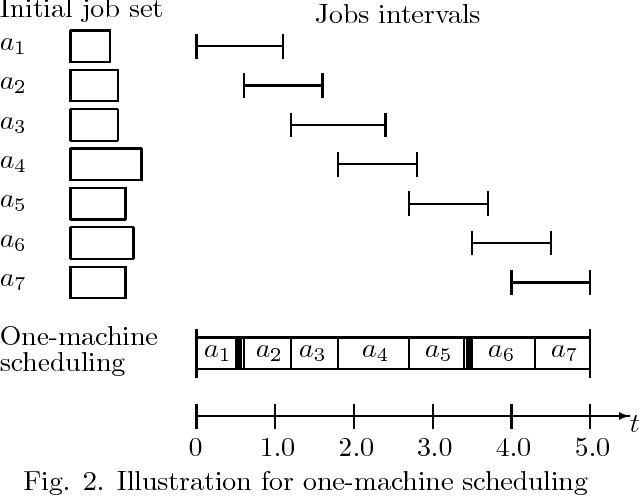
The article describes a special time-interval balancing in multi-processor scheduling of composite modular jobs. This scheduling problem is close to just-in-time planning approach. First, brief literature surveys are presented on just-in-time scheduling and due-data/due-window scheduling problems. Further, the problem and its formulation are proposed for the time-interval balanced scheduling of composite modular jobs. The illustrative real world planning example for modular home-building is described. Here, the main objective function consists in a balance between production of the typical building modules (details) and the assembly processes of the building(s) (by several teams). The assembly plan has to be modified to satisfy the balance requirements. The solving framework is based on the following: (i) clustering of initial set of modular detail types to obtain about ten basic detail types that correspond to main manufacturing conveyors; (ii) designing a preliminary plan of assembly for buildings; (iii) detection of unbalanced time periods, (iv) modification of the planning solution to improve the schedule balance. The framework implements a metaheuristic based on local optimization approach. Two other applications (supply chain management, information transmission systems) are briefly described.
NeRP: Neural Rearrangement Planning for Unknown Objects
Jun 04, 2021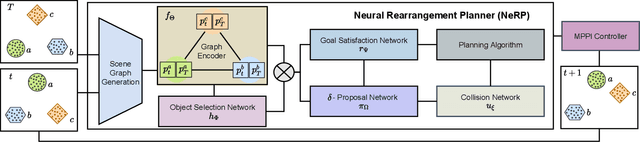



Robots will be expected to manipulate a wide variety of objects in complex and arbitrary ways as they become more widely used in human environments. As such, the rearrangement of objects has been noted to be an important benchmark for AI capabilities in recent years. We propose NeRP (Neural Rearrangement Planning), a deep learning based approach for multi-step neural object rearrangement planning which works with never-before-seen objects, that is trained on simulation data, and generalizes to the real world. We compare NeRP to several naive and model-based baselines, demonstrating that our approach is measurably better and can efficiently arrange unseen objects in fewer steps and with less planning time. Finally, we demonstrate it on several challenging rearrangement problems in the real world.