 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Physics-Informed Neural Nets-based Control
Apr 06, 2021
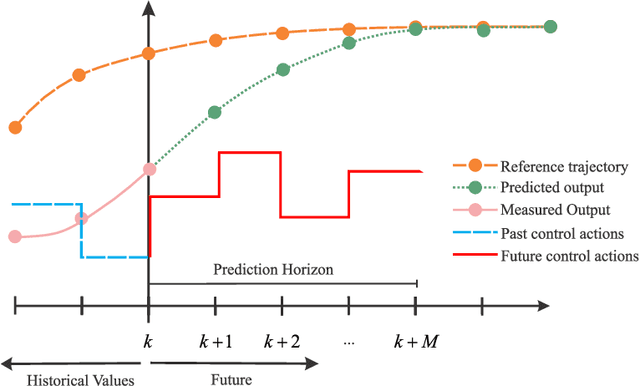
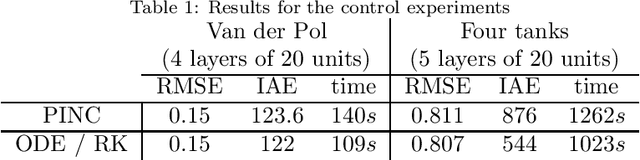
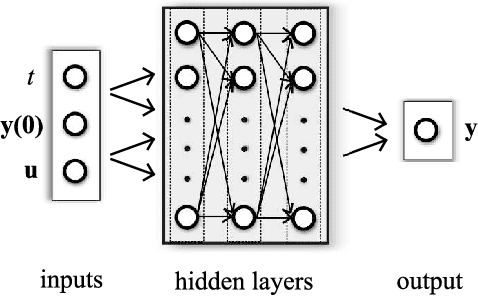
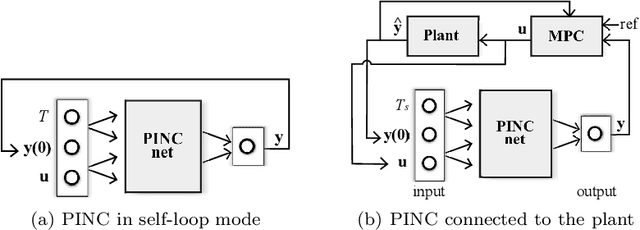
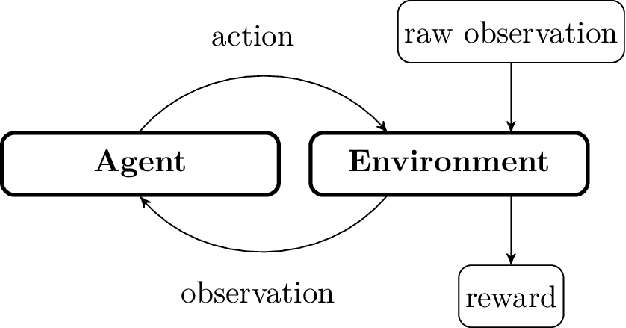
Physics-informed neural networks (PINNs) impose known physical laws into the learning of deep neural networks, making sure they respect the physics of the process while decreasing the demand of labeled data. For systems represented by Ordinary Differential Equations (ODEs), the conventional PINN has a continuous time input variable and outputs the solution of the corresponding ODE. In their original form, PINNs do not allow control inputs neither can they simulate for long-range intervals without serious degradation in their predictions. In this context, this work presents a new framework called Physics-Informed Neural Nets-based Control (PINC), which proposes a novel PINN-based architecture that is amenable to control problems and able to simulate for longer-range time horizons that are not fixed beforehand. First, the network is augmented with new inputs to account for the initial state of the system and the control action. Then, the response over the complete time horizon is split such that each smaller interval constitutes a solution of the ODE conditioned on the fixed values of initial state and control action. The complete response is formed by setting the initial state of the next interval to the terminal state of the previous one. The new methodology enables the optimal control of dynamic systems, making feasible to integrate a priori knowledge from experts and data collected from plants in control applications. We showcase our method in the control of two nonlinear dynamic systems: the Van der Pol oscillator and the four-tank system.
Low-cost Stereovision system (disparity map) for few dollars
Jun 02, 2021


The paper presents an analysis of the latest developments in the field of stereo vision in the low-cost segment, both for prototypes and for industrial designs. We described the theory of stereo vision and presented information about cameras and data transfer protocols and their compatibility with various devices. The theory in the field of image processing for stereo vision processes is considered and the calibration process is described in detail. Ultimately, we presented the developed stereo vision system and provided the main points that need to be considered when developing such systems. The final, we presented software for adjusting stereo vision parameters in real-time in the python language in the Windows operating system.
Road Roughness Estimation Using Machine Learning
Jul 02, 2021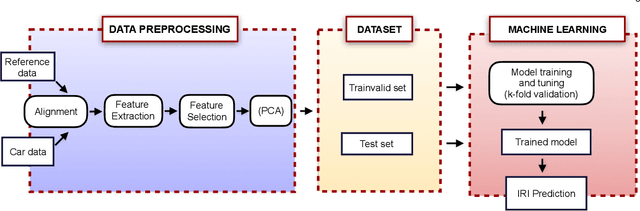

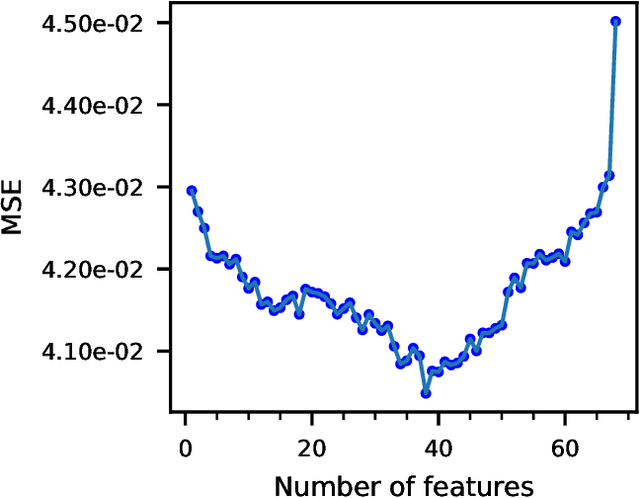
Road roughness is a very important road condition for the infrastructure, as the roughness affects both the safety and ride comfort of passengers. The roads deteriorate over time which means the road roughness must be continuously monitored in order to have an accurate understand of the condition of the road infrastructure. In this paper, we propose a machine learning pipeline for road roughness prediction using the vertical acceleration of the car and the car speed. We compared well-known supervised machine learning models such as linear regression, naive Bayes, k-nearest neighbor, random forest, support vector machine, and the multi-layer perceptron neural network. The models are trained on an optimally selected set of features computed in the temporal and statistical domain. The results demonstrate that machine learning methods can accurately predict road roughness, using the recordings of the cost approachable in-vehicle sensors installed in conventional passenger cars. Our findings demonstrate that the technology is well suited to meet future pavement condition monitoring, by enabling continuous monitoring of a wide road network.
Boosting the Convergence of Reinforcement Learning-based Auto-pruning Using Historical Data
Jul 16, 2021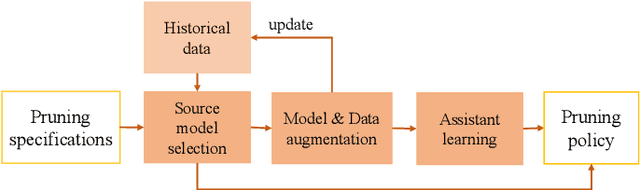
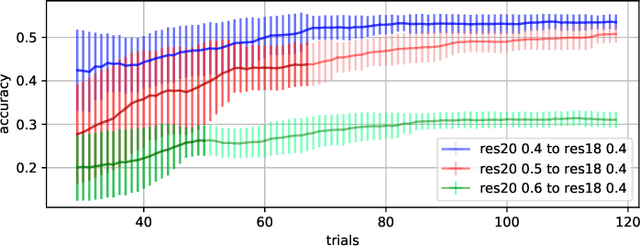
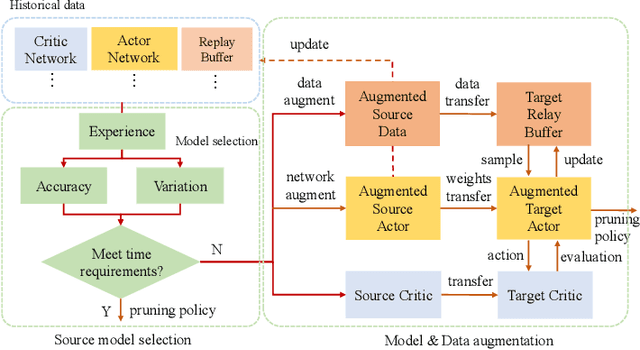
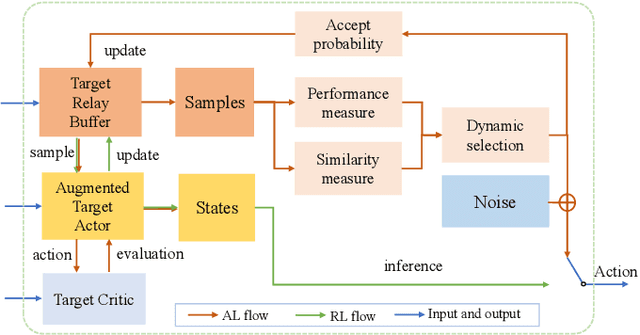
Recently, neural network compression schemes like channel pruning have been widely used to reduce the model size and computational complexity of deep neural network (DNN) for applications in power-constrained scenarios such as embedded systems. Reinforcement learning (RL)-based auto-pruning has been further proposed to automate the DNN pruning process to avoid expensive hand-crafted work. However, the RL-based pruner involves a time-consuming training process and the high expense of each sample further exacerbates this problem. These impediments have greatly restricted the real-world application of RL-based auto-pruning. Thus, in this paper, we propose an efficient auto-pruning framework which solves this problem by taking advantage of the historical data from the previous auto-pruning process. In our framework, we first boost the convergence of the RL-pruner by transfer learning. Then, an augmented transfer learning scheme is proposed to further speed up the training process by improving the transferability. Finally, an assistant learning process is proposed to improve the sample efficiency of the RL agent. The experiments have shown that our framework can accelerate the auto-pruning process by 1.5-2.5 times for ResNet20, and 1.81-2.375 times for other neural networks like ResNet56, ResNet18, and MobileNet v1.
Finding Failures in High-Fidelity Simulation using Adaptive Stress Testing and the Backward Algorithm
Jul 27, 2021
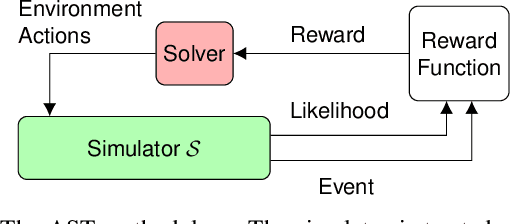

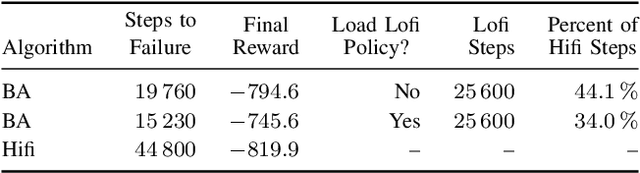
Validating the safety of autonomous systems generally requires the use of high-fidelity simulators that adequately capture the variability of real-world scenarios. However, it is generally not feasible to exhaustively search the space of simulation scenarios for failures. Adaptive stress testing (AST) is a method that uses reinforcement learning to find the most likely failure of a system. AST with a deep reinforcement learning solver has been shown to be effective in finding failures across a range of different systems. This approach generally involves running many simulations, which can be very expensive when using a high-fidelity simulator. To improve efficiency, we present a method that first finds failures in a low-fidelity simulator. It then uses the backward algorithm, which trains a deep neural network policy using a single expert demonstration, to adapt the low-fidelity failures to high-fidelity. We have created a series of autonomous vehicle validation case studies that represent some of the ways low-fidelity and high-fidelity simulators can differ, such as time discretization. We demonstrate in a variety of case studies that this new AST approach is able to find failures with significantly fewer high-fidelity simulation steps than are needed when just running AST directly in high-fidelity. As a proof of concept, we also demonstrate AST on NVIDIA's DriveSim simulator, an industry state-of-the-art high-fidelity simulator for finding failures in autonomous vehicles.
DUKweb: Diachronic word representations from the UK Web Archive corpus
Jul 02, 2021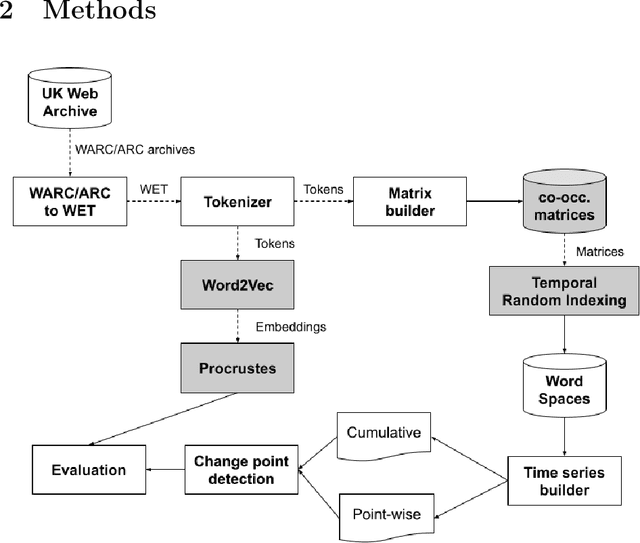
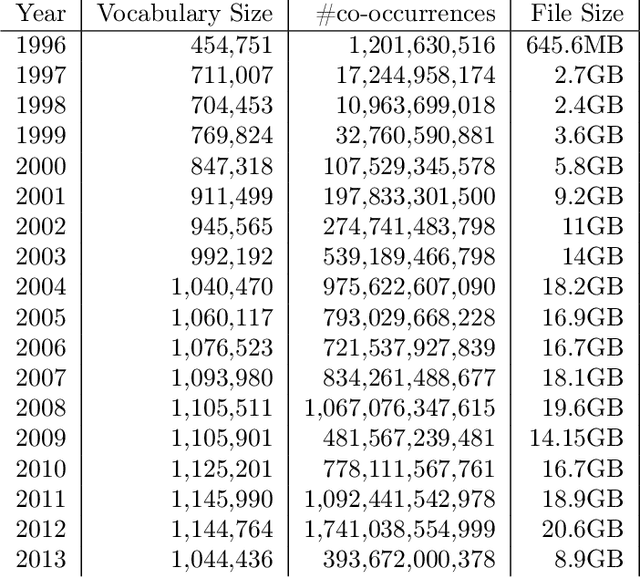

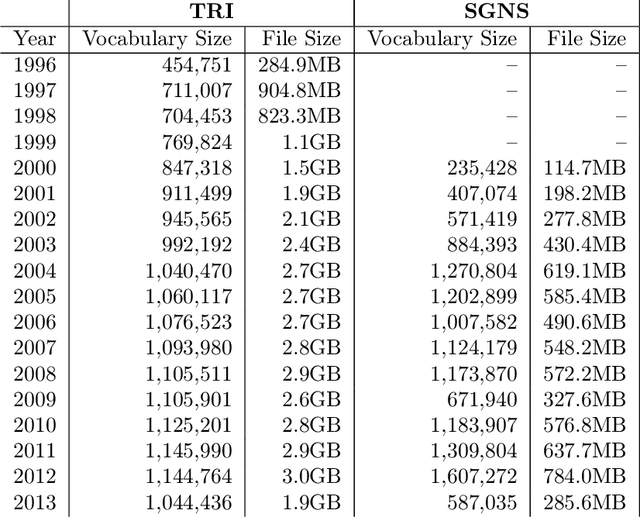
Lexical semantic change (detecting shifts in the meaning and usage of words) is an important task for social and cultural studies as well as for Natural Language Processing applications. Diachronic word embeddings (time-sensitive vector representations of words that preserve their meaning) have become the standard resource for this task. However, given the significant computational resources needed for their generation, very few resources exist that make diachronic word embeddings available to the scientific community. In this paper we present DUKweb, a set of large-scale resources designed for the diachronic analysis of contemporary English. DUKweb was created from the JISC UK Web Domain Dataset (1996-2013), a very large archive which collects resources from the Internet Archive that were hosted on domains ending in `.uk'. DUKweb consists of a series word co-occurrence matrices and two types of word embeddings for each year in the JISC UK Web Domain dataset. We show the reuse potential of DUKweb and its quality standards via a case study on word meaning change detection.
WAX-ML: A Python library for machine learning and feedback loops on streaming data
Jun 11, 2021
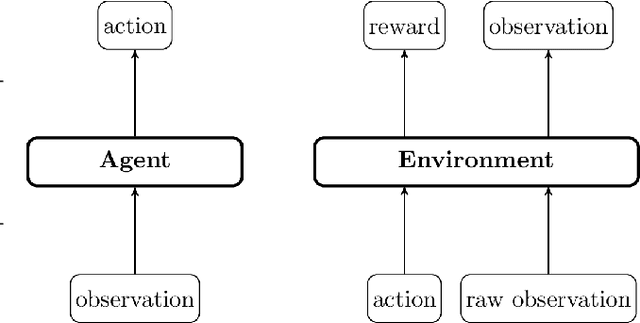
Wax is what you put on a surfboard to avoid slipping. It is an essential tool to go surfing... We introduce WAX-ML a research-oriented Python library providing tools to design powerful machine learning algorithms and feedback loops working on streaming data. It strives to complement JAX with tools dedicated to time series. WAX-ML makes JAX-based programs easy to use for end-users working with pandas and xarray for data manipulation. It provides a simple mechanism for implementing feedback loops, allows the implementation of online learning and reinforcement learning algorithms with functions, and makes them easy to integrate by end-users working with the object-oriented reinforcement learning framework from the Gym library. It is released with an Apache open-source license on GitHub at https://github.com/eserie/wax-ml.
RMQFMU: Bridging the Real World with Co-simulation Technical Report
Jul 02, 2021
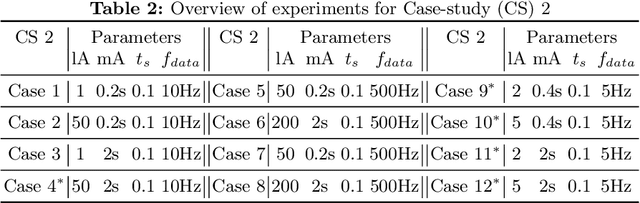
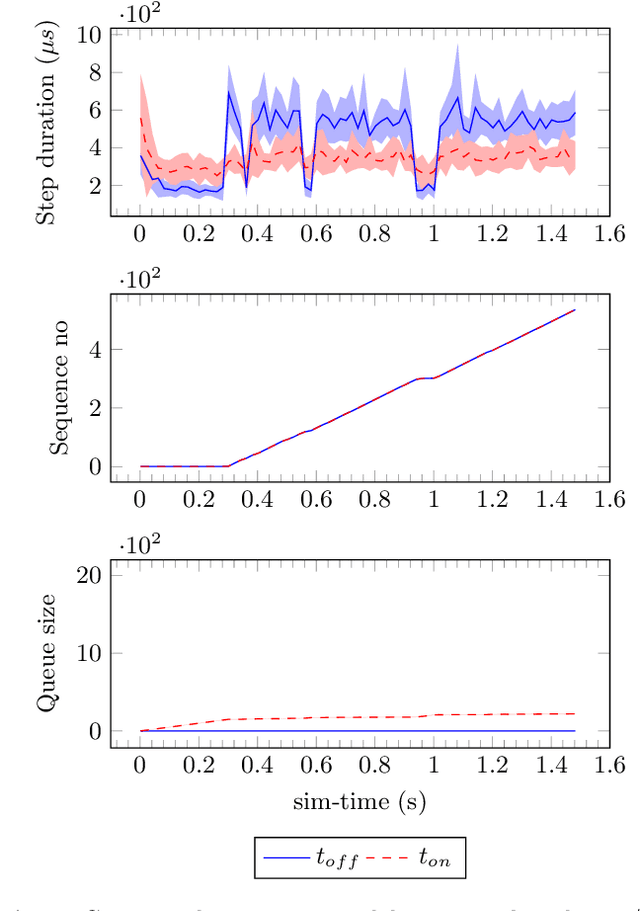
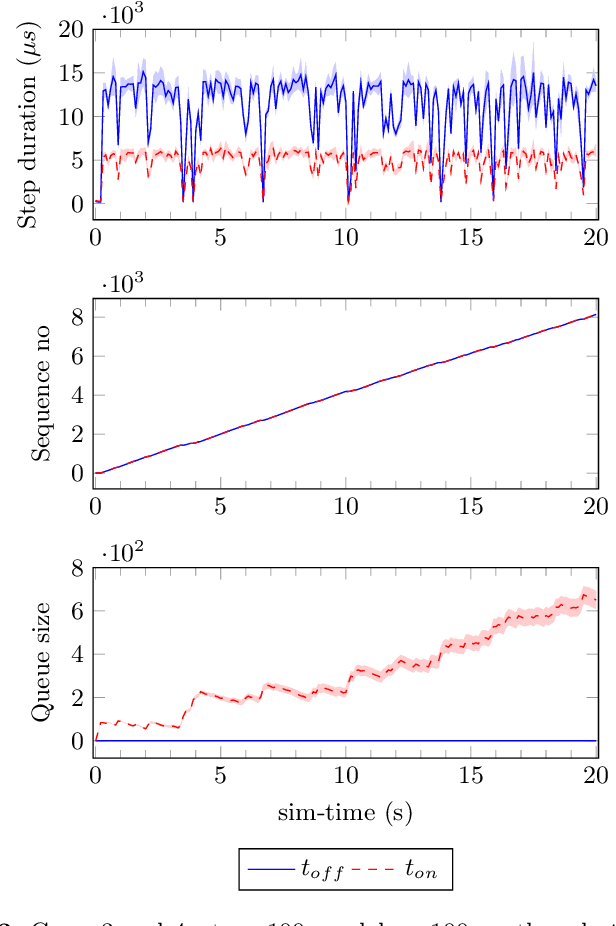
In this paper we present an experience report for the RMQ\-FMU, a plug and play tool, that enables feeding data to/from an FMI2-based co-simulation environment based on the AMQP protocol. Bridging the co-simulation to an external environment allows on one side to feed historical data to the co-simulation, serving different purposes, such as visualisation and/or data analysis. On the other side, such a tool facilitates the realisation of the digital twin concept by coupling co-simulation and hardware/robots close to real-time. In the paper we present limitations of the initial version of the RMQFMU with respect to the capability of bridging co-simulation with the real world. To provide the desired functionality of the tool, we present in a step-by-step fashion how these limitations, and subsequent limitations, are alleviated. We perform various experiments in order to give reason to the modifications carried out. Finally, we report on two case-studies where we have adopted the RMQFMU, and provide guidelines meant to aid practitioners in the use of the tool.
Optical Braille Recognition using Circular Hough Transform
Jul 02, 2021
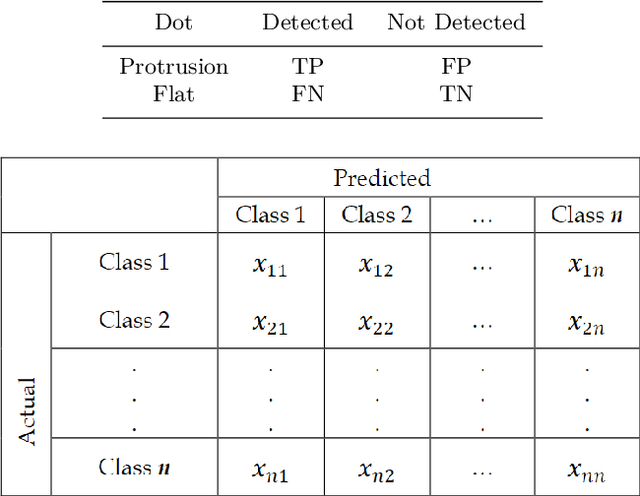


Braille has empowered visually challenged community to read and write. But at the same time, it has created a gap due to widespread inability of non-Braille users to understand Braille scripts. This gap has fuelled researchers to propose Optical Braille Recognition techniques to convert Braille documents to natural language. The main motivation of this work is to cement the communication gap at academic institutions by translating personal documents of blind students. This has been accomplished by proposing an economical and effective technique which digitizes Braille documents using a smartphone camera. For any given Braille image, a dot detection mechanism based on Hough transform is proposed which is invariant to skewness, noise and other deterrents. The detected dots are then clustered into Braille cells using distance-based clustering algorithm. In succession, the standard physical parameters of each Braille cells are estimated for feature extraction and classification as natural language characters. The comprehensive evaluation of this technique on the proposed dataset of 54 Braille scripts has yielded into accuracy of 98.71%.
Model-Based Reinforcement Learning via Latent-Space Collocation
Jun 24, 2021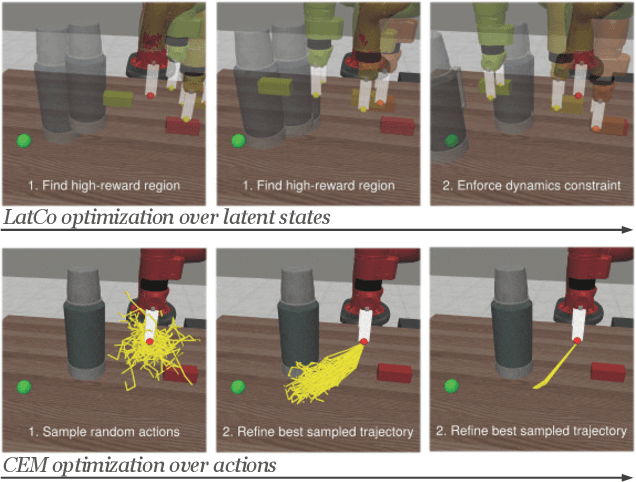
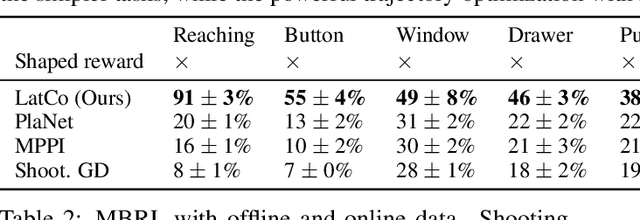
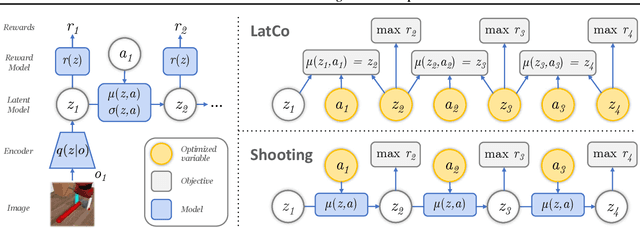

The ability to plan into the future while utilizing only raw high-dimensional observations, such as images, can provide autonomous agents with broad capabilities. Visual model-based reinforcement learning (RL) methods that plan future actions directly have shown impressive results on tasks that require only short-horizon reasoning, however, these methods struggle on temporally extended tasks. We argue that it is easier to solve long-horizon tasks by planning sequences of states rather than just actions, as the effects of actions greatly compound over time and are harder to optimize. To achieve this, we draw on the idea of collocation, which has shown good results on long-horizon tasks in optimal control literature, and adapt it to the image-based setting by utilizing learned latent state space models. The resulting latent collocation method (LatCo) optimizes trajectories of latent states, which improves over previously proposed shooting methods for visual model-based RL on tasks with sparse rewards and long-term goals. Videos and code at https://orybkin.github.io/latco/.