 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Unified Linear-Time Framework for Sentence-Level Discourse Parsing
May 14, 2019
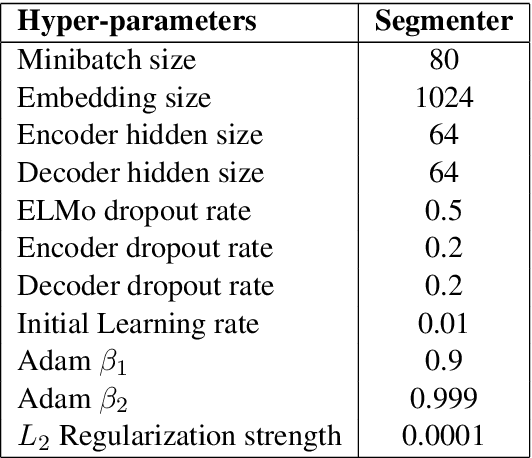
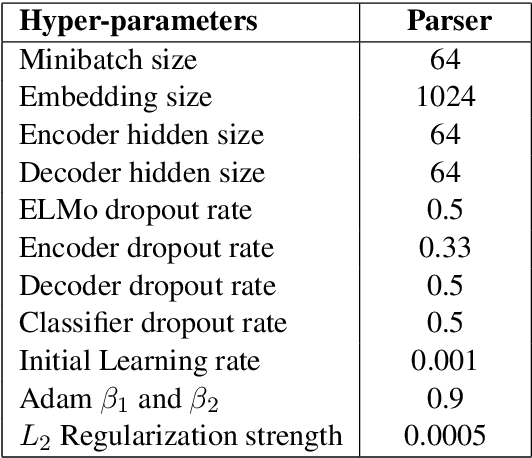
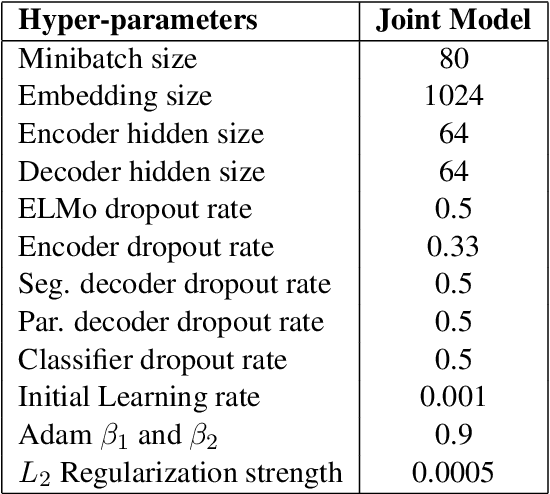
We propose an efficient neural framework for sentence-level discourse analysis in accordance with Rhetorical Structure Theory (RST). Our framework comprises a discourse segmenter to identify the elementary discourse units (EDU) in a text, and a discourse parser that constructs a discourse tree in a top-down fashion. Both the segmenter and the parser are based on Pointer Networks and operate in linear time. Our segmenter yields an $F_1$ score of 95.4, and our parser achieves an $F_1$ score of 81.7 on the aggregated labeled (relation) metric, surpassing previous approaches by a good margin and approaching human agreement on both tasks (98.3 and 83.0 $F_1$).
Multi-Graph Convolutional-Recurrent Neural Network (MGC-RNN) for Short-Term Forecasting of Transit Passenger Flow
Jul 28, 2021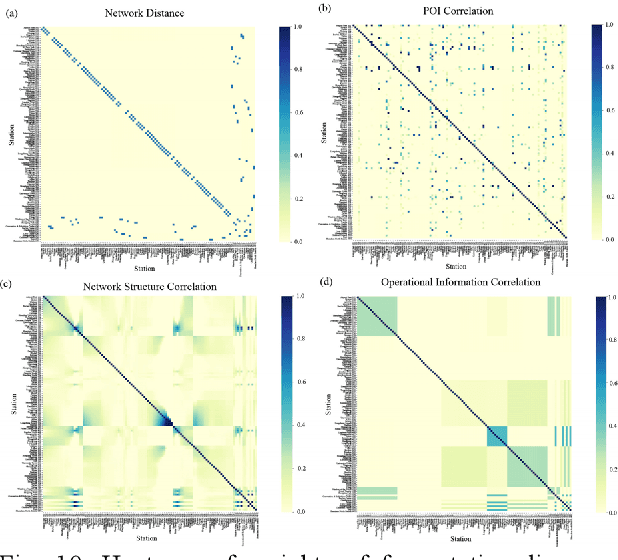
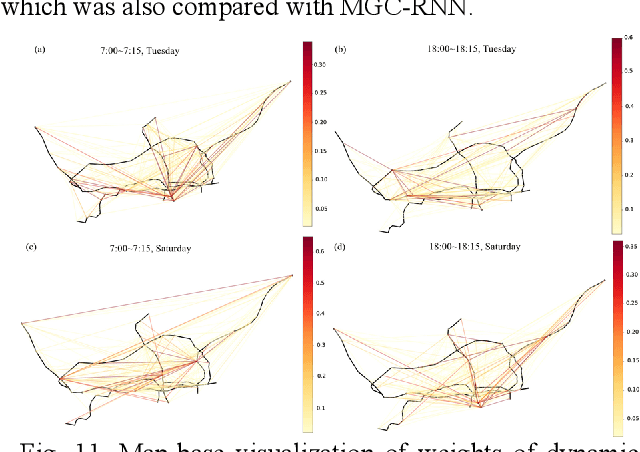
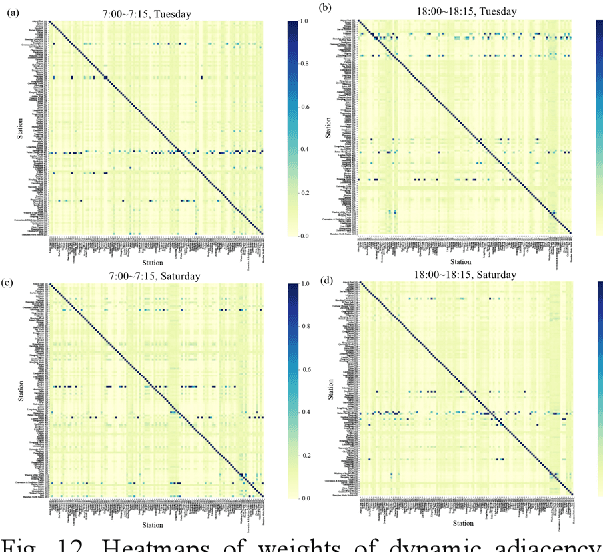
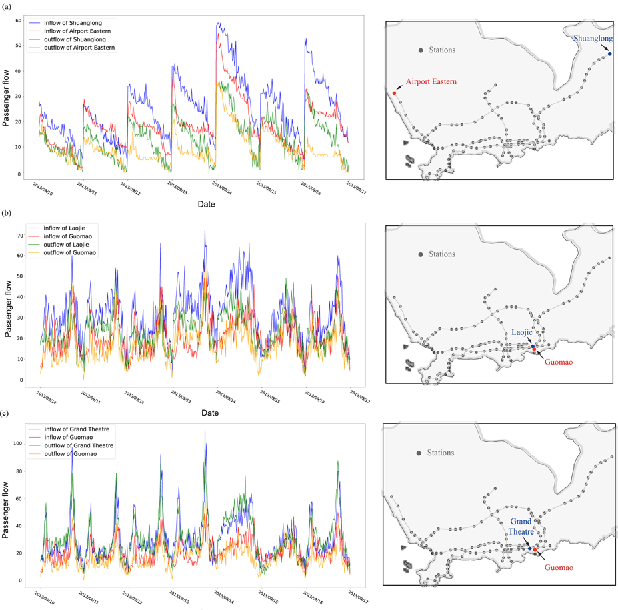
Short-term forecasting of passenger flow is critical for transit management and crowd regulation. Spatial dependencies, temporal dependencies, inter-station correlations driven by other latent factors, and exogenous factors bring challenges to the short-term forecasts of passenger flow of urban rail transit networks. An innovative deep learning approach, Multi-Graph Convolutional-Recurrent Neural Network (MGC-RNN) is proposed to forecast passenger flow in urban rail transit systems to incorporate these complex factors. We propose to use multiple graphs to encode the spatial and other heterogenous inter-station correlations. The temporal dynamics of the inter-station correlations are also modeled via the proposed multi-graph convolutional-recurrent neural network structure. Inflow and outflow of all stations can be collectively predicted with multiple time steps ahead via a sequence to sequence(seq2seq) architecture. The proposed method is applied to the short-term forecasts of passenger flow in Shenzhen Metro, China. The experimental results show that MGC-RNN outperforms the benchmark algorithms in terms of forecasting accuracy. Besides, it is found that the inter-station driven by network distance, network structure, and recent flow patterns are significant factors for passenger flow forecasting. Moreover, the architecture of LSTM-encoder-decoder can capture the temporal dependencies well. In general, the proposed framework could provide multiple views of passenger flow dynamics for fine prediction and exhibit a possibility for multi-source heterogeneous data fusion in the spatiotemporal forecast tasks.
Recovering lost and absent information in temporal networks
Jul 22, 2021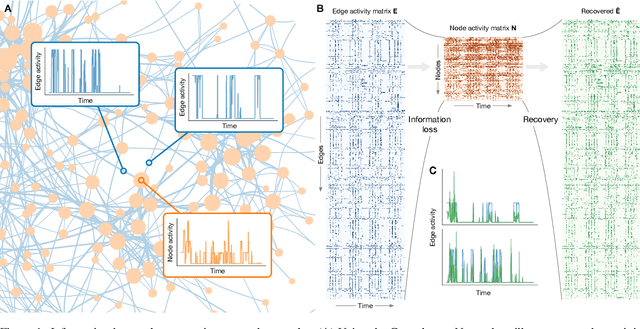
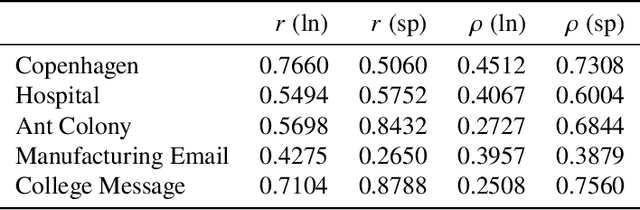
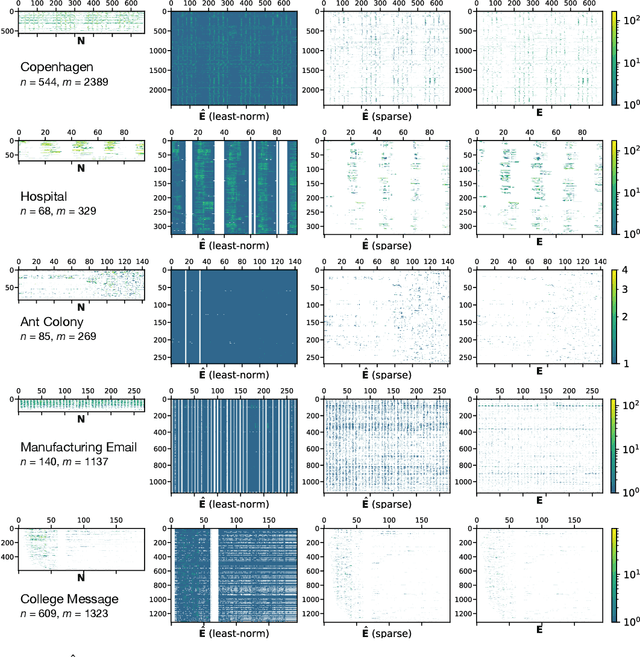
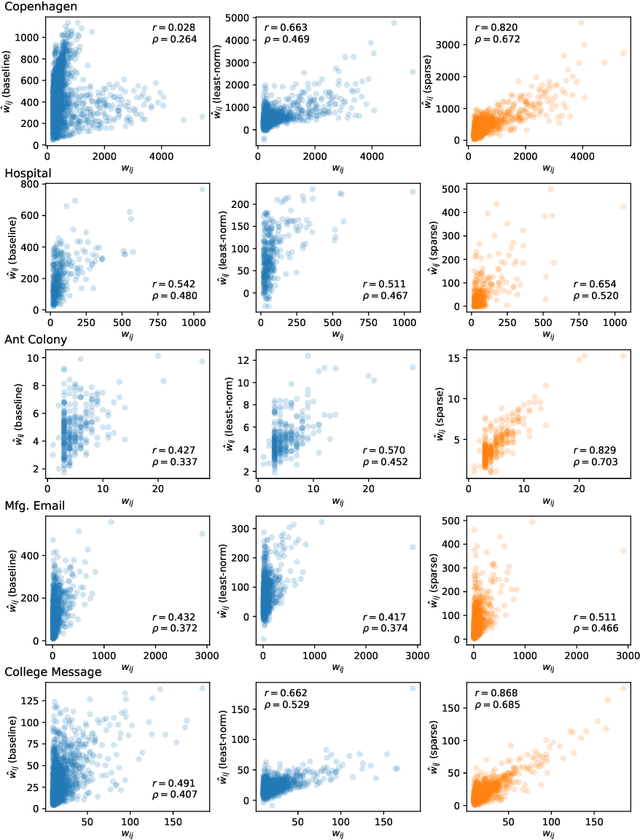
The full range of activity in a temporal network is captured in its edge activity data -- time series encoding the tie strengths or on-off dynamics of each edge in the network. However, in many practical applications, edge-level data are unavailable, and the network analyses must rely instead on node activity data which aggregates the edge-activity data and thus is less informative. This raises the question: Is it possible to use the static network to recover the richer edge activities from the node activities? Here we show that recovery is possible, often with a surprising degree of accuracy given how much information is lost, and that the recovered data are useful for subsequent network analysis tasks. Recovery is more difficult when network density increases, either topologically or dynamically, but exploiting dynamical and topological sparsity enables effective solutions to the recovery problem. We formally characterize the difficulty of the recovery problem both theoretically and empirically, proving the conditions under which recovery errors can be bounded and showing that, even when these conditions are not met, good quality solutions can still be derived. Effective recovery carries both promise and peril, as it enables deeper scientific study of complex systems but in the context of social systems also raises privacy concerns when social information can be aggregated across multiple data sources.
A New Robust Multivariate Mode Estimator for Eye-tracking Calibration
Jul 16, 2021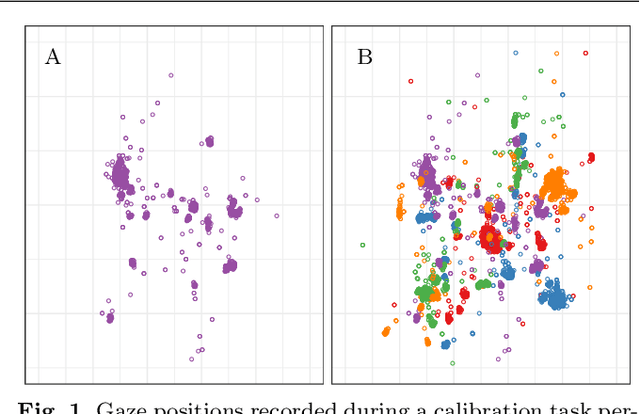
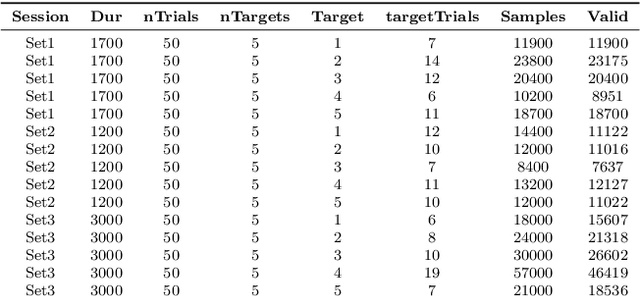
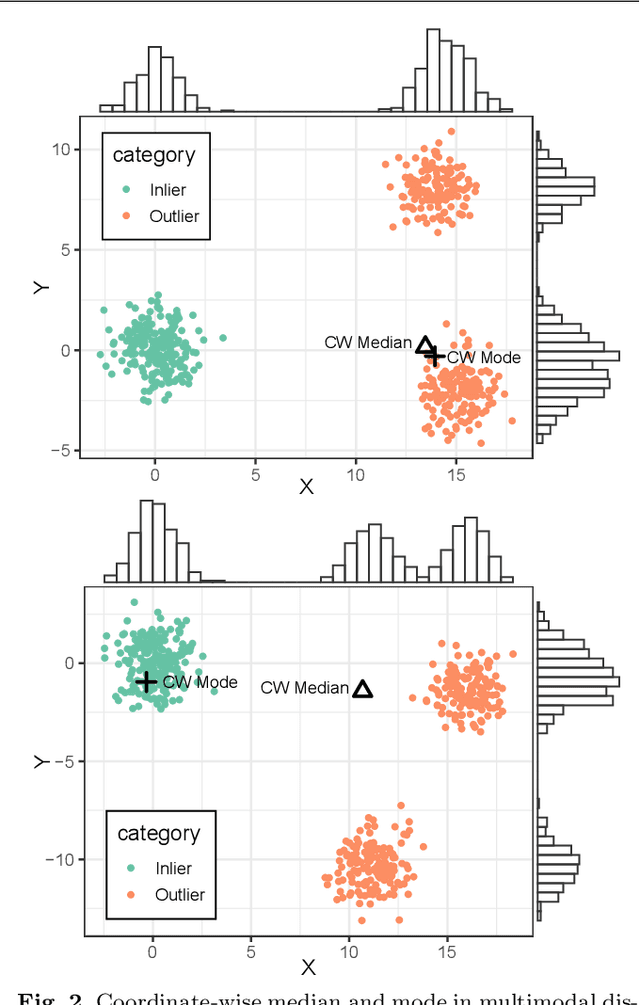
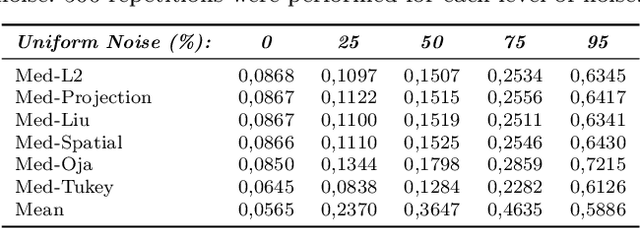
We propose in this work a new method for estimating the main mode of multivariate distributions, with application to eye-tracking calibrations. When performing eye-tracking experiments with poorly cooperative subjects, such as infants or monkeys, the calibration data generally suffer from high contamination. Outliers are typically organized in clusters, corresponding to the time intervals when subjects were not looking at the calibration points. In this type of multimodal distributions, most central tendency measures fail at estimating the principal fixation coordinates (the first mode), resulting in errors and inaccuracies when mapping the gaze to the screen coordinates. Here, we developed a new algorithm to identify the first mode of multivariate distributions, named BRIL, which rely on recursive depth-based filtering. This novel approach was tested on artificial mixtures of Gaussian and Uniform distributions, and compared to existing methods (conventional depth medians, robust estimators of location and scatter, and clustering-based approaches). We obtained outstanding performances, even for distributions containing very high proportions of outliers, both grouped in clusters and randomly distributed. Finally, we demonstrate the strength of our method in a real-world scenario using experimental data from eye-tracking calibrations with Capuchin monkeys, especially for distributions where other algorithms typically lack accuracy.
Robust Pooling through the Data Mode
Jun 21, 2021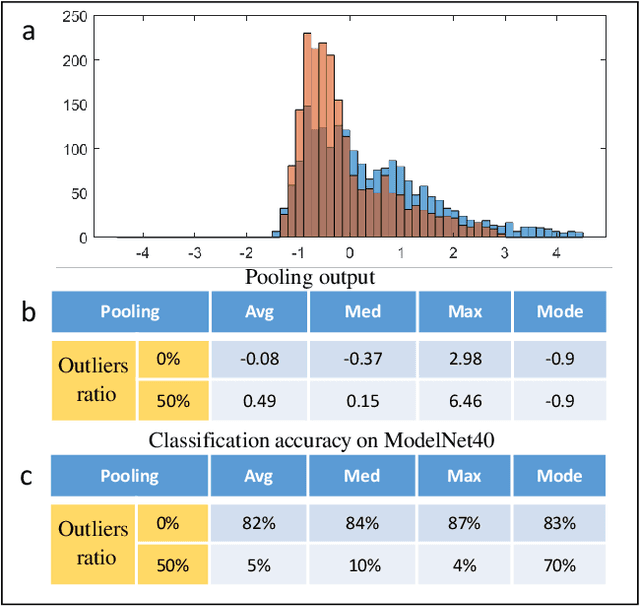
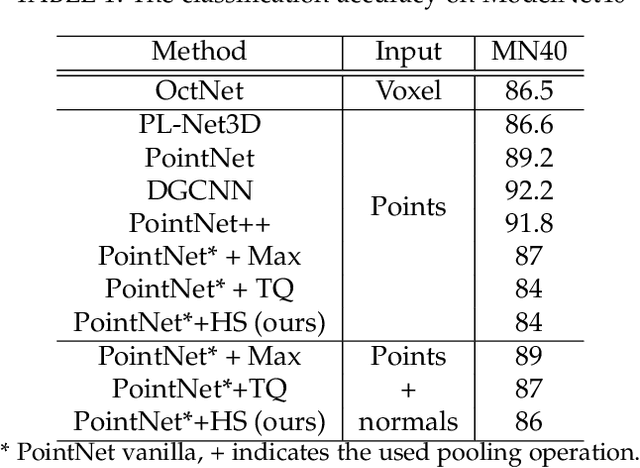
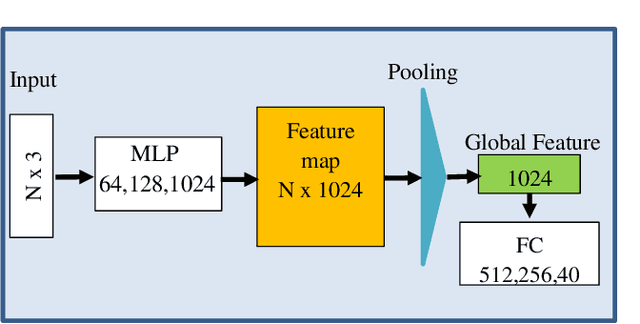
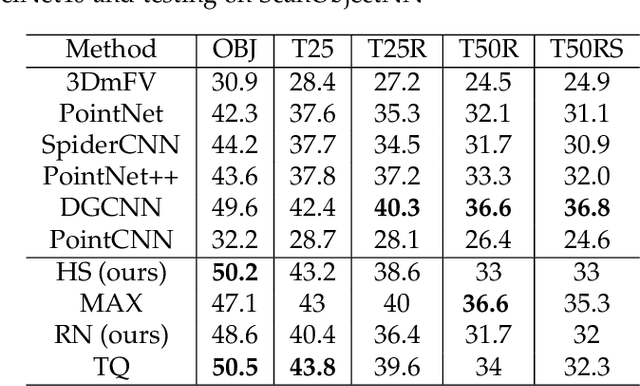
The task of learning from point cloud data is always challenging due to the often occurrence of noise and outliers in the data. Such data inaccuracies can significantly influence the performance of state-of-the-art deep learning networks and their ability to classify or segment objects. While there are some robust deep learning approaches, they are computationally too expensive for real-time applications. This paper proposes a deep learning solution that includes a novel robust pooling layer which greatly enhances network robustness and performs significantly faster than state-of-the-art approaches. The proposed pooling layer looks for data a mode/cluster using two methods, RANSAC, and histogram, as clusters are indicative of models. We tested the pooling layer into frameworks such as Point-based and graph-based neural networks, and the tests showed enhanced robustness as compared to robust state-of-the-art methods.
Deep Unfolded Recovery of Sub-Nyquist Sampled Ultrasound Image
Mar 01, 2021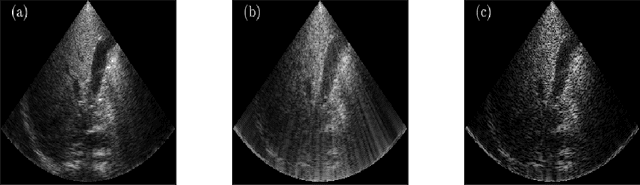
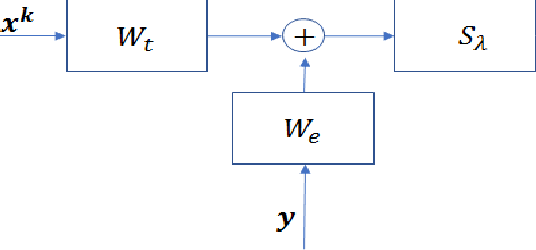
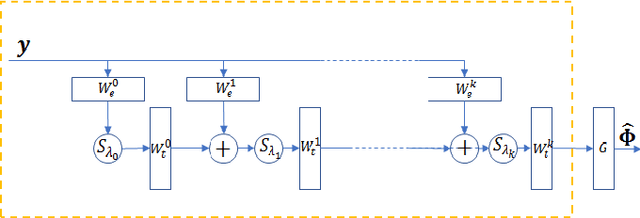
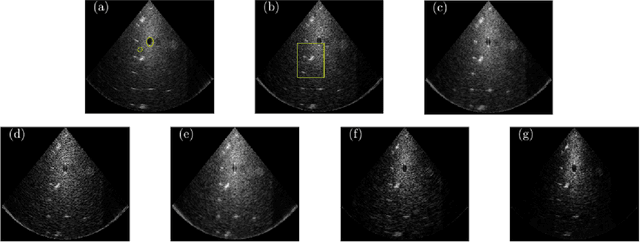
The most common technique for generating B-mode ultrasound (US) images is delay and sum (DAS) beamforming, where the signals received at the transducer array are sampled before an appropriate delay is applied. This necessitates sampling rates exceeding the Nyquist rate and the use of a large number of antenna elements to ensure sufficient image quality. Recently we proposed methods to reduce the sampling rate and the array size relying on image recovery using iterative algorithms, based on compressed sensing (CS) and the finite rate of innovation (FRI) frameworks. Iterative algorithms typically require a large number of iterations, making them difficult to use in real-time. Here, we propose a reconstruction method from sub-Nyquist samples in the time and spatial domain, that is based on unfolding the ISTA algorithm, resulting in an efficient and interpretable deep network. The inputs to our network are the subsampled beamformed signals after summation and delay in the frequency domain, requiring only a subset of the US signal to be stored for recovery. Our method allows reducing the number of array elements, sampling rate, and computational time while ensuring high quality imaging performance. Using \emph{in vivo} data we demonstrate that the proposed method yields high-quality images while reducing the data volume traditionally used up to 36 times. In terms of image resolution and contrast, our technique outperforms previously suggested methods as well as DAS and minimum-variance (MV) beamforming, paving the way to real-time applicable recovery methods.
Hoechst Is All You Need: Lymphocyte Classification with Deep Learning
Jul 16, 2021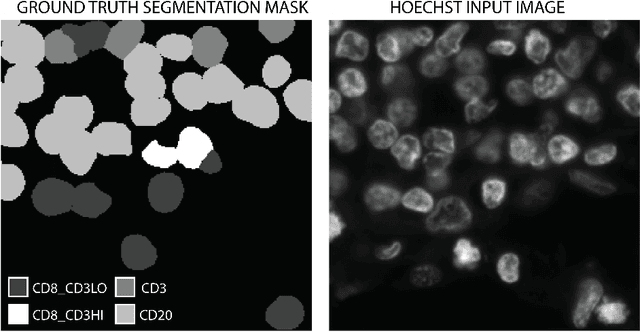

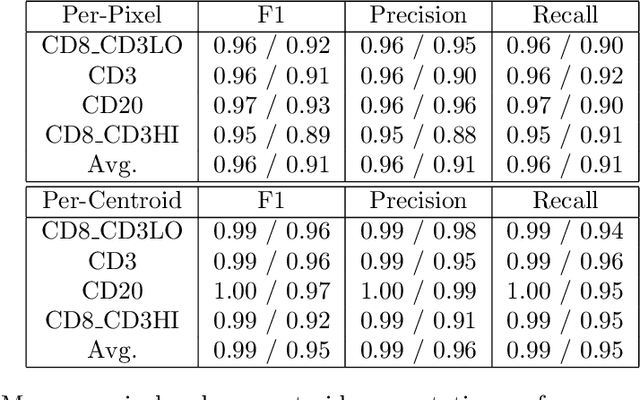
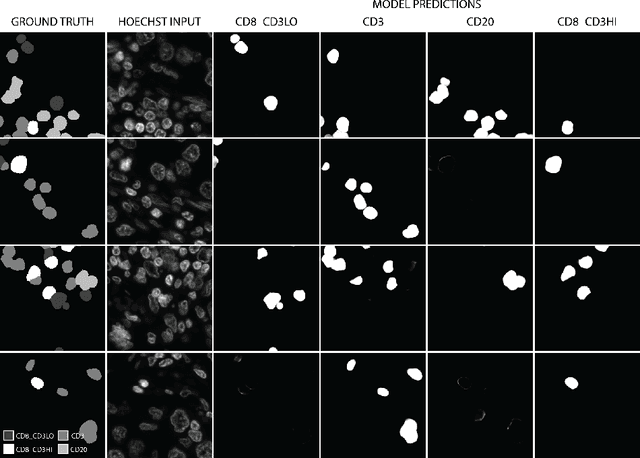
Multiplex immunofluorescence and immunohistochemistry benefit patients by allowing cancer pathologists to identify several proteins expressed on the surface of cells, enabling cell classification, better understanding of the tumour micro-environment, more accurate diagnoses, prognoses, and tailored immunotherapy based on the immune status of individual patients. However, they are expensive and time consuming processes which require complex staining and imaging techniques by expert technicians. Hoechst staining is much cheaper and easier to perform, but is not typically used in this case as it binds to DNA rather than to the proteins targeted by immunofluorescent techniques, and it was not previously thought possible to differentiate cells expressing these proteins based only on DNA morphology. In this work we show otherwise, training a deep convolutional neural network to identify cells expressing three proteins (T lymphocyte markers CD3 and CD8, and the B lymphocyte marker CD20) with greater than 90% precision and recall, from Hoechst 33342 stained tissue only. Our model learns previously unknown morphological features associated with expression of these proteins which can be used to accurately differentiate lymphocyte subtypes for use in key prognostic metrics such as assessment of immune cell infiltration,and thereby predict and improve patient outcomes without the need for costly multiplex immunofluorescence.
Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer
Apr 18, 2021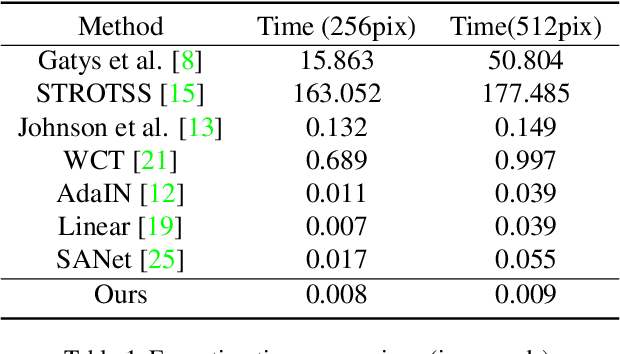
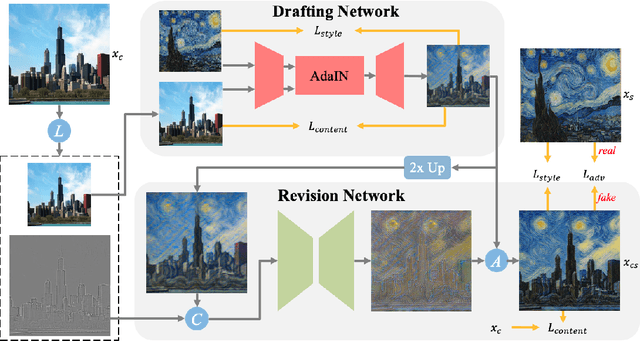
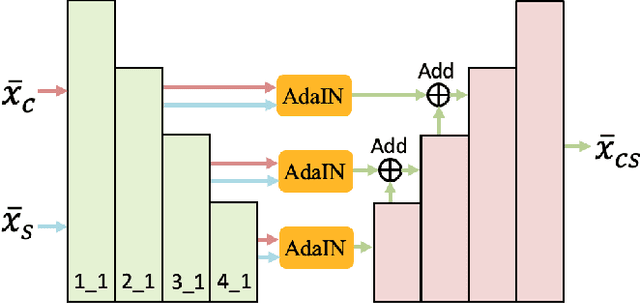
Artistic style transfer aims at migrating the style from an example image to a content image. Currently, optimization-based methods have achieved great stylization quality, but expensive time cost restricts their practical applications. Meanwhile, feed-forward methods still fail to synthesize complex style, especially when holistic global and local patterns exist. Inspired by the common painting process of drawing a draft and revising the details, we introduce a novel feed-forward method named Laplacian Pyramid Network (LapStyle). LapStyle first transfers global style patterns in low-resolution via a Drafting Network. It then revises the local details in high-resolution via a Revision Network, which hallucinates a residual image according to the draft and the image textures extracted by Laplacian filtering. Higher resolution details can be easily generated by stacking Revision Networks with multiple Laplacian pyramid levels. The final stylized image is obtained by aggregating outputs of all pyramid levels. %We also introduce a patch discriminator to better learn local patterns adversarially. Experiments demonstrate that our method can synthesize high quality stylized images in real time, where holistic style patterns are properly transferred.
Fast Low-Rank Tensor Decomposition by Ridge Leverage Score Sampling
Jul 22, 2021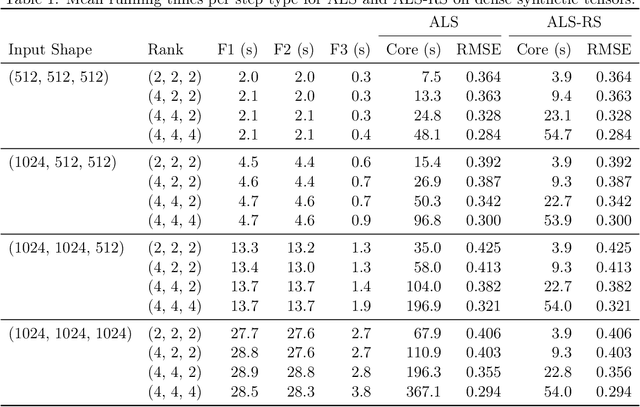
Low-rank tensor decomposition generalizes low-rank matrix approximation and is a powerful technique for discovering low-dimensional structure in high-dimensional data. In this paper, we study Tucker decompositions and use tools from randomized numerical linear algebra called ridge leverage scores to accelerate the core tensor update step in the widely-used alternating least squares (ALS) algorithm. Updating the core tensor, a severe bottleneck in ALS, is a highly-structured ridge regression problem where the design matrix is a Kronecker product of the factor matrices. We show how to use approximate ridge leverage scores to construct a sketched instance for any ridge regression problem such that the solution vector for the sketched problem is a $(1+\varepsilon)$-approximation to the original instance. Moreover, we show that classical leverage scores suffice as an approximation, which then allows us to exploit the Kronecker structure and update the core tensor in time that depends predominantly on the rank and the sketching parameters (i.e., sublinear in the size of the input tensor). We also give upper bounds for ridge leverage scores as rows are removed from the design matrix (e.g., if the tensor has missing entries), and we demonstrate the effectiveness of our approximate ridge regressioni algorithm for large, low-rank Tucker decompositions on both synthetic and real-world data.
Jointly Optimizing Query Encoder and Product Quantization to Improve Retrieval Performance
Aug 02, 2021
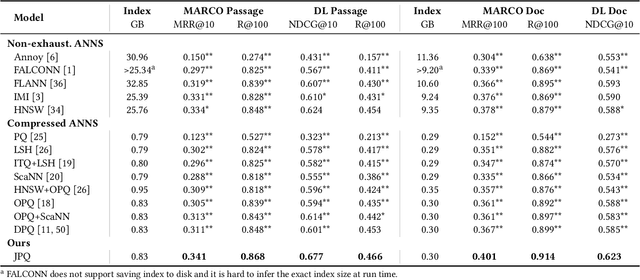
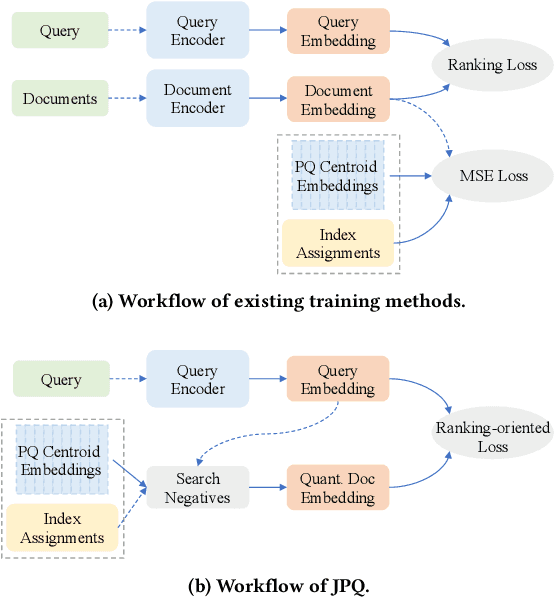
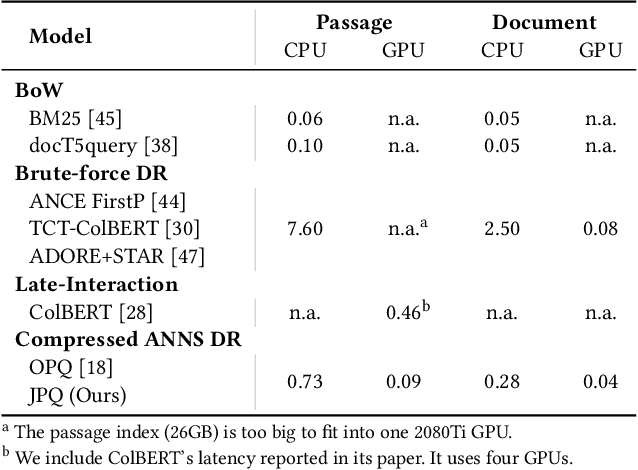
Recently, Information Retrieval community has witnessed fast-paced advances in Dense Retrieval (DR), which performs first-stage retrieval by encoding documents in a low-dimensional embedding space and querying them with embedding-based search. Despite the impressive ranking performance, previous studies usually adopt brute-force search to acquire candidates, which is prohibitive in practical Web search scenarios due to its tremendous memory usage and time cost. To overcome these problems, vector compression methods, a branch of Approximate Nearest Neighbor Search (ANNS), have been adopted in many practical embedding-based retrieval applications. One of the most popular methods is Product Quantization (PQ). However, although existing vector compression methods including PQ can help improve the efficiency of DR, they incur severely decayed retrieval performance due to the separation between encoding and compression. To tackle this problem, we present JPQ, which stands for Joint optimization of query encoding and Product Quantization. It trains the query encoder and PQ index jointly in an end-to-end manner based on three optimization strategies, namely ranking-oriented loss, PQ centroid optimization, and end-to-end negative sampling. We evaluate JPQ on two publicly available retrieval benchmarks. Experimental results show that JPQ significantly outperforms existing popular vector compression methods in terms of different trade-off settings. Compared with previous DR models that use brute-force search, JPQ almost matches the best retrieval performance with 30x compression on index size. The compressed index further brings 10x speedup on CPU and 2x speedup on GPU in query latency.