 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Energy Efficiency Optimization in Radar-Communication Spectrum Sharing
Apr 19, 2021
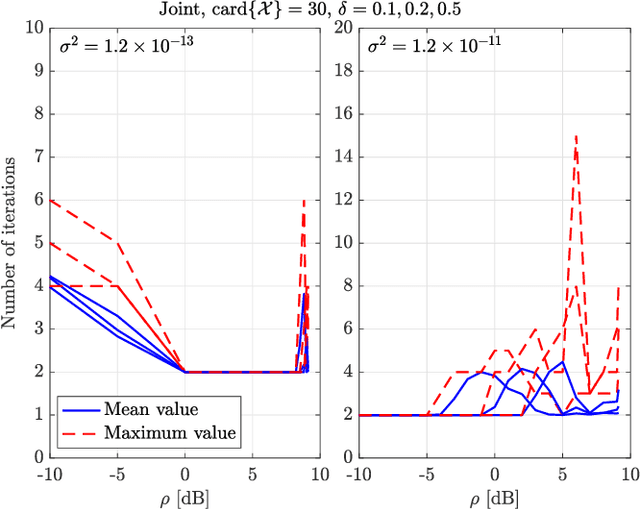
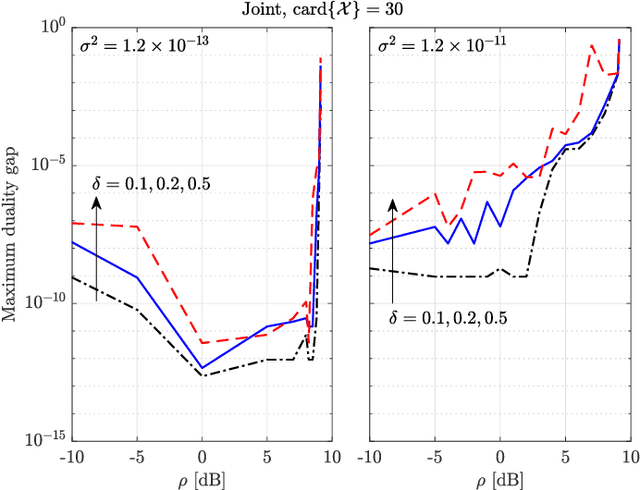
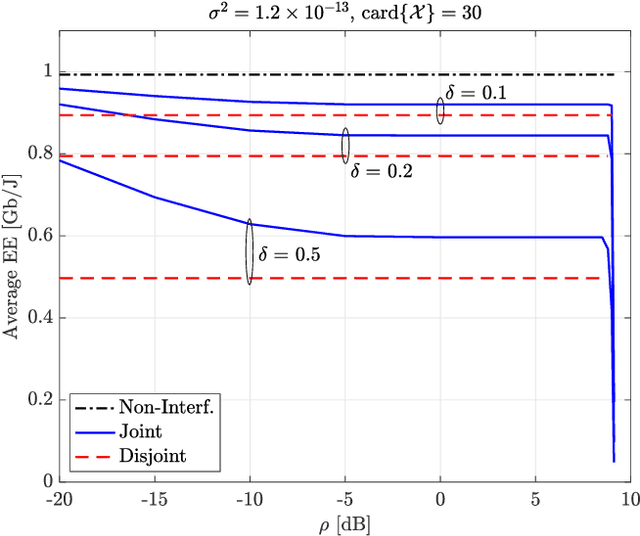
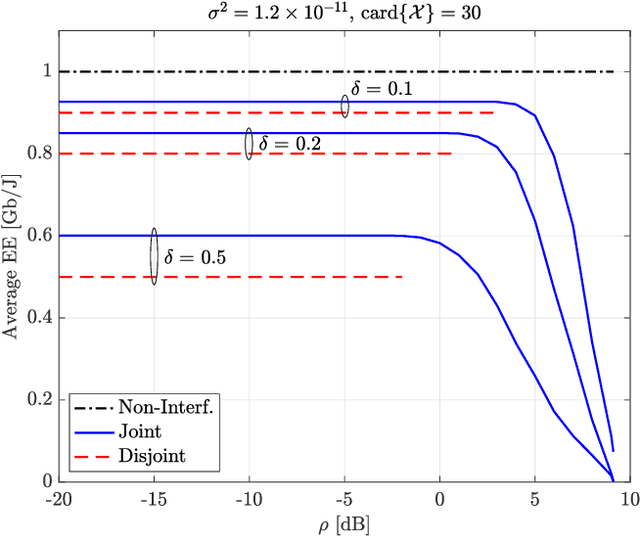
Energy efficiency, possibly coupled with cognition-based and spectrum-sharing architectures, is a key enabling technology for green communications in 5G-and-beyond standards. In this context, the present paper considers a multiple-input multiple-output communication system cooperatively coexisting with a surveillance radar: the objective function is the communication system energy efficiency, while radar operation is safeguarded by constraining the minimum received signal-to-disturbance ratio for a set of range-azimuth cells of the controlled scene, and no time synchronization between them is assumed. The degrees of freedom are the transmit powers of both systems, the space-time communication codebook and the linear filters at the radar receiver. The resulting optimization problem is non-convex, due to both the objective function and the presence of signal-dependent interference (clutter): we develop a block-coordinate-ascent approximate solution, and offer a thorough performance assessment, so as to elicit the merits of the proposed approach, along with the interplay among the achievable energy efficiency, the density of scatterers in the environment, and the size of the set of protected radar cells.
Object-Adaptive LSTM Network for Real-time Visual Tracking with Adversarial Data Augmentation
Feb 07, 2020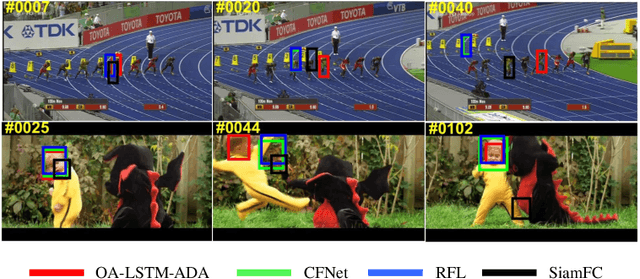
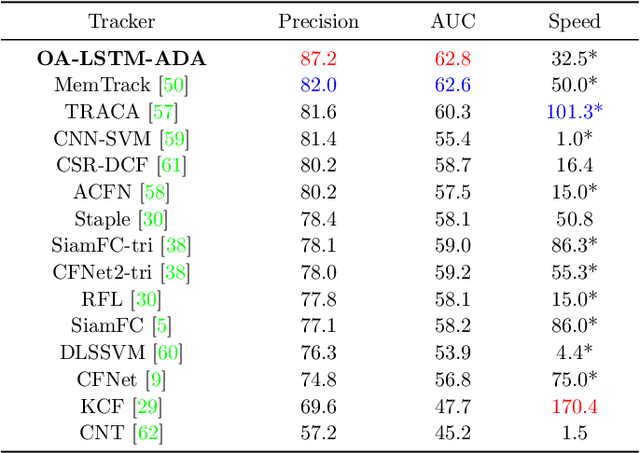
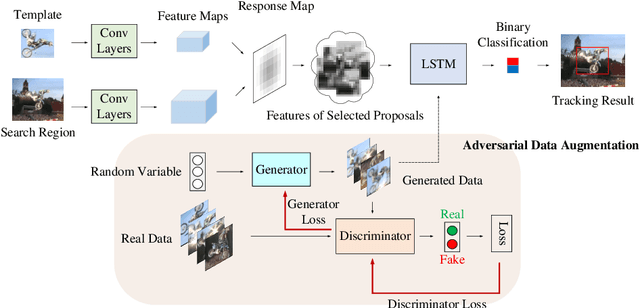
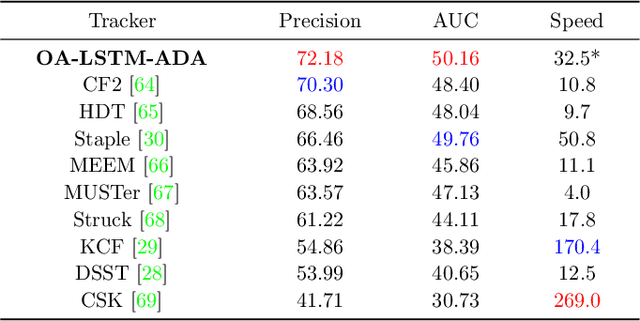
In recent years, deep learning based visual tracking methods have obtained great success owing to the powerful feature representation ability of Convolutional Neural Networks (CNNs). Among these methods, classification-based tracking methods exhibit excellent performance while their speeds are heavily limited by the expensive computation for massive proposal feature extraction. In contrast, matching-based tracking methods (such as Siamese networks) possess remarkable speed superiority. However, the absence of online updating renders these methods unadaptable to significant object appearance variations. In this paper, we propose a novel real-time visual tracking method, which adopts an object-adaptive LSTM network to effectively capture the video sequential dependencies and adaptively learn the object appearance variations. For high computational efficiency, we also present a fast proposal selection strategy, which utilizes the matching-based tracking method to pre-estimate dense proposals and selects high-quality ones to feed to the LSTM network for classification. This strategy efficiently filters out some irrelevant proposals and avoids the redundant computation for feature extraction, which enables our method to operate faster than conventional classification-based tracking methods. In addition, to handle the problems of sample inadequacy and class imbalance during online tracking, we adopt a data augmentation technique based on the Generative Adversarial Network (GAN) to facilitate the training of the LSTM network. Extensive experiments on four visual tracking benchmarks demonstrate the state-of-the-art performance of our method in terms of both tracking accuracy and speed, which exhibits great potentials of recurrent structures for visual tracking.
An Algorithm for Stochastic and Adversarial Bandits with Switching Costs
Feb 19, 2021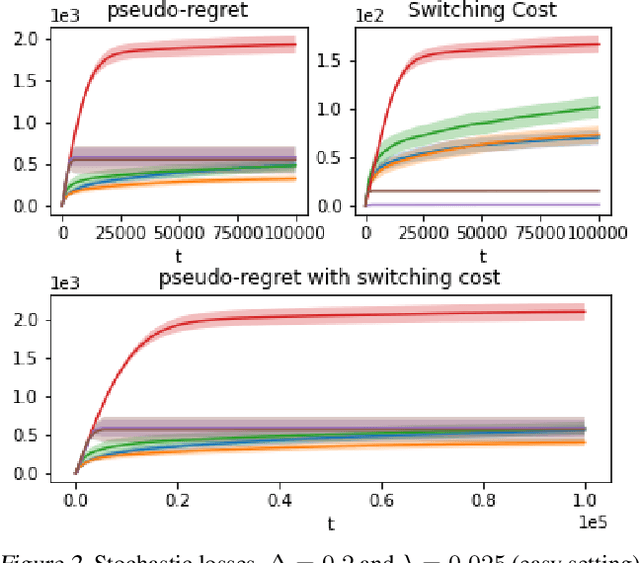
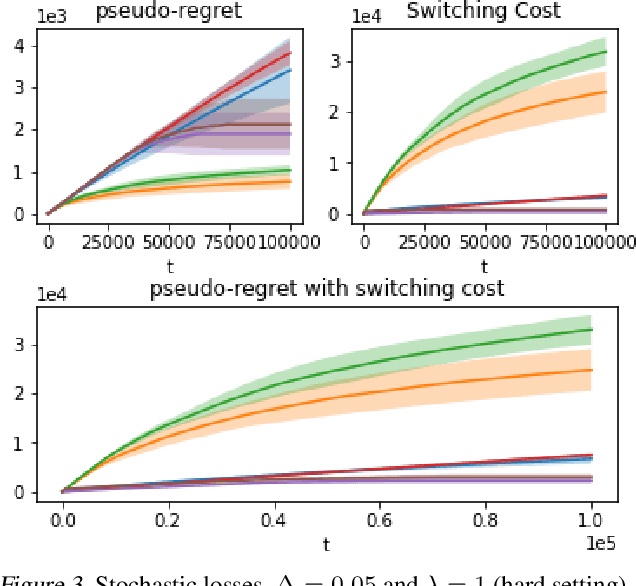
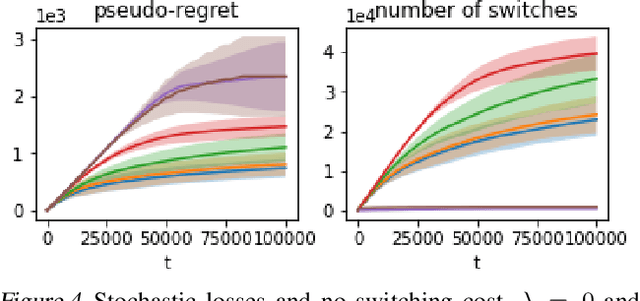
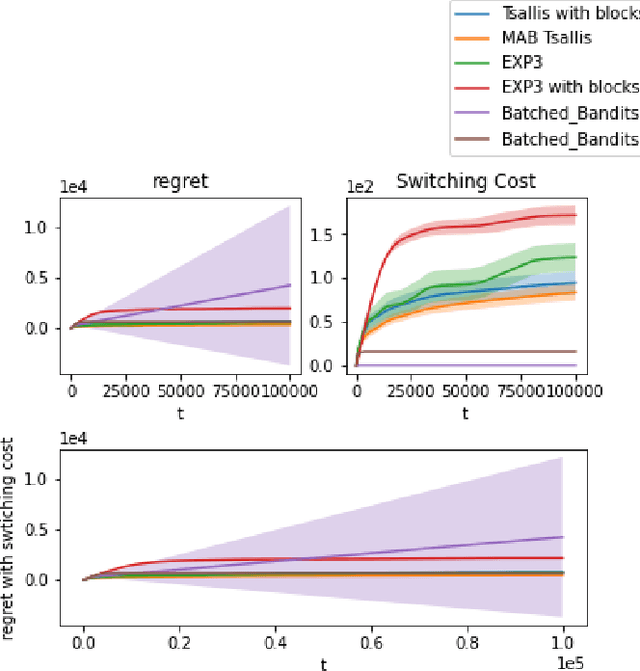
We propose an algorithm for stochastic and adversarial multiarmed bandits with switching costs, where the algorithm pays a price $\lambda$ every time it switches the arm being played. Our algorithm is based on adaptation of the Tsallis-INF algorithm of Zimmert and Seldin (2021) and requires no prior knowledge of the regime or time horizon. In the oblivious adversarial setting it achieves the minimax optimal regret bound of $O\big((\lambda K)^{1/3}T^{2/3} + \sqrt{KT}\big)$, where $T$ is the time horizon and $K$ is the number of arms. In the stochastically constrained adversarial regime, which includes the stochastic regime as a special case, it achieves a regret bound of $O\left(\big((\lambda K)^{2/3} T^{1/3} + \ln T\big)\sum_{i \neq i^*} \Delta_i^{-1}\right)$, where $\Delta_i$ are the suboptimality gaps and $i^*$ is a unique optimal arm. In the special case of $\lambda = 0$ (no switching costs), both bounds are minimax optimal within constants. We also explore variants of the problem, where switching cost is allowed to change over time. We provide experimental evaluation showing competitiveness of our algorithm with the relevant baselines in the stochastic, stochastically constrained adversarial, and adversarial regimes with fixed switching cost.
High dimensional regression for regenerative time-series: an application to road traffic modeling
Oct 29, 2019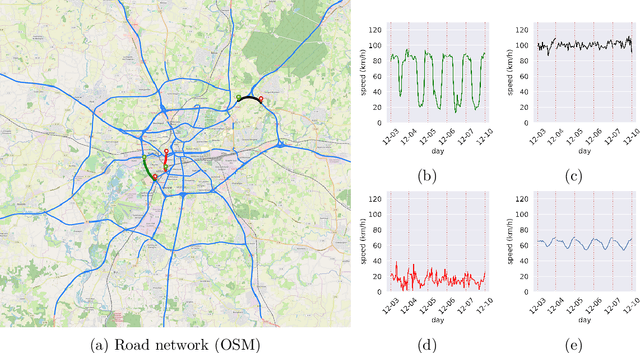

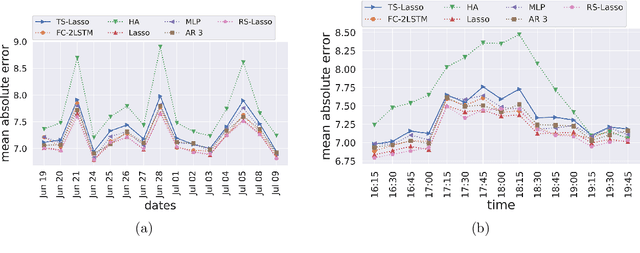
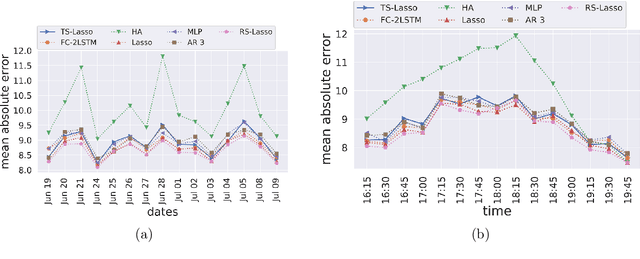
This paper investigates statistical models for road traffic modeling. The proposed methodology considers road traffic as a (i) highdimensional time-series for which (ii) regeneration occurs at the end of each day. Since (ii), prediction is based on a daily modeling of the road traffic using a vector autoregressive model that combines linearly the past observations of the day. Considering (i), the learning algorithm follows from an l1-penalization of the regression coefficients. Excess risk bounds are established under the high-dimensional framework in which the number of road sections goes to infinity with the number of observed days. Considering floating car data observed in an urban area, the approach is compared to state-of-the-art methods including neural networks. In addition of being very competitive in terms of prediction, it enables to identify the most determinant sections of the road network.
An Autonomous Drone for Search and Rescue in Forests using Airborne Optical Sectioning
May 10, 2021

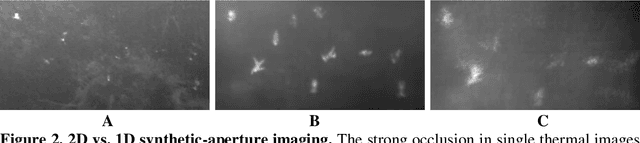
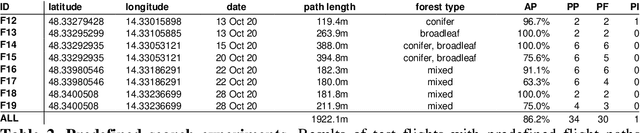
Drones will play an essential role in human-machine teaming in future search and rescue (SAR) missions. We present a first prototype that finds people fully autonomously in densely occluded forests. In the course of 17 field experiments conducted over various forest types and under different flying conditions, our drone found 38 out of 42 hidden persons; average precision was 86% for predefined flight paths, while adaptive path planning (where potential findings are double-checked) increased confidence by 15%. Image processing, classification, and dynamic flight-path adaptation are computed onboard in real-time and while flying. Our finding that deep-learning-based person classification is unaffected by sparse and error-prone sampling within one-dimensional synthetic apertures allows flights to be shortened and reduces recording requirements to one-tenth of the number of images needed for sampling using two-dimensional synthetic apertures. The goal of our adaptive path planning is to find people as reliably and quickly as possible, which is essential in time-critical applications, such as SAR. Our drone enables SAR operations in remote areas without stable network coverage, as it transmits to the rescue team only classification results that indicate detections and can thus operate with intermittent minimal-bandwidth connections (e.g., by satellite). Once received, these results can be visually enhanced for interpretation on remote mobile devices.
Fast and Efficient Model for Real-Time Tiger Detection In The Wild
Sep 03, 2019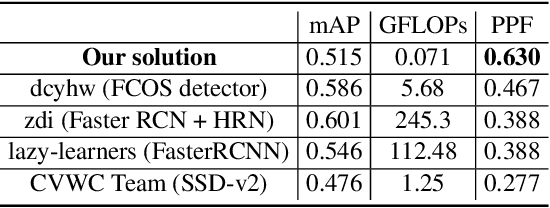
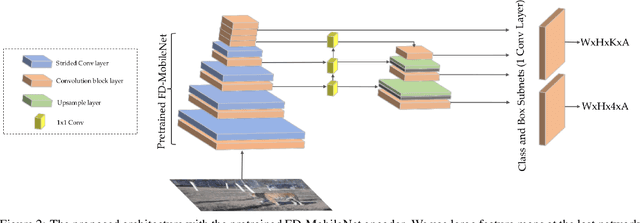


The highest accuracy object detectors to date are based either on a two-stage approach such as Fast R-CNN or one-stage detectors such as Retina-Net or SSD with deep and complex backbones. In this paper we present TigerNet - simple yet efficient FPN based network architecture for Amur Tiger Detection in the wild. The model has 600k parameters, requires 0.071 GFLOPs per image and can run on the edge devices (smart cameras) in near real time. In addition, we introduce a two-stage semi-supervised learning via pseudo-labelling learning approach to distill the knowledge from the larger networks. For ATRW-ICCV 2019 tiger detection sub-challenge, based on public leaderboard score, our approach shows superior performance in comparison to other methods.
Adaptive Encoding for Constrained Video Delivery in HEVC, VP9, AV1 and VVC Compression Standards and Adaptation to Video Content
Apr 26, 2021
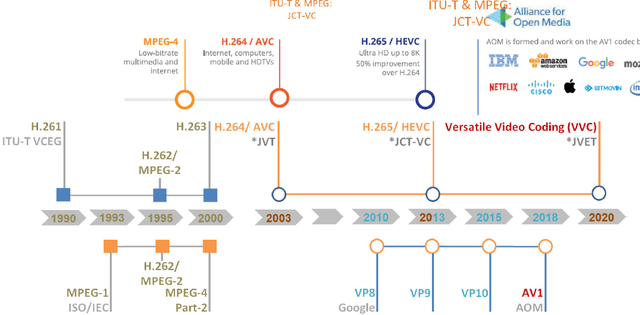

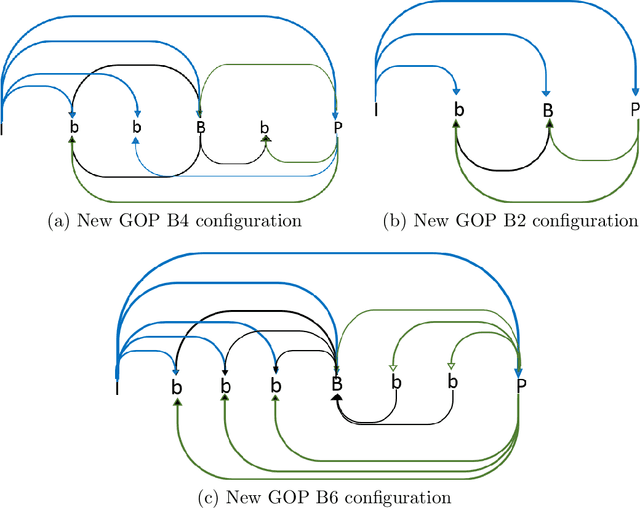
The dissertation proposes the use of a multi-objective optimization framework for designing and selecting among enhanced GOP configurations in video compression standards. The proposed methods achieve fine optimization over a set of general modes that include: (i) maximum video quality, (ii) minimum bitrate, (iii) maximum encoding rate (previously minimum encoding time mode) and (iv) can be shown to improve upon the YouTube/Netflix default encoder mode settings over a set of opposing constraints to guarantee satisfactory performance. The dissertation describes the implementation of a codec-agnostic approach using different video coding standards (x265, VP9, AV1) on a wide range of videos derived from different video datasets. The results demonstrate that the optimal encoding parameters obtained from the Pareto front space can provide significant bandwidth savings without sacrificing video quality. This is achieved by the use of effective regression models that allow for the selection of video encoding settings that are jointly optimal in the encoding time, bitrate, and video quality space. The dissertation applies the proposed methods to x265, VP9, AV1 and using new GOP configurations in x265, delivering over 40% of the optimal encodings in two standard reference videos.
Domain Adaptive YOLO for One-Stage Cross-Domain Detection
Jun 26, 2021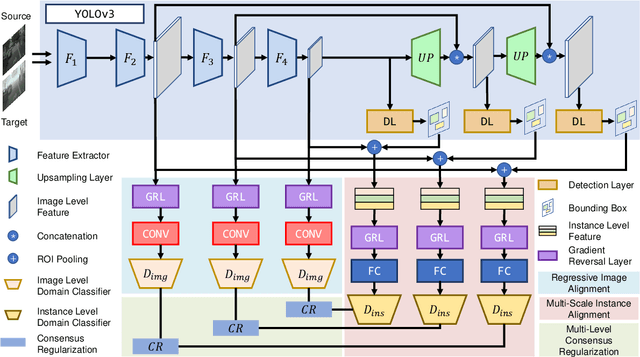
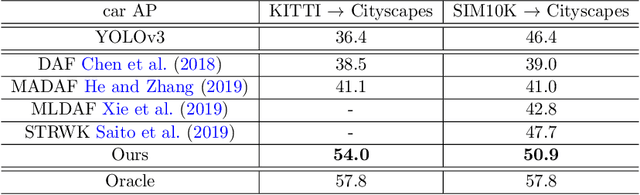


Domain shift is a major challenge for object detectors to generalize well to real world applications. Emerging techniques of domain adaptation for two-stage detectors help to tackle this problem. However, two-stage detectors are not the first choice for industrial applications due to its long time consumption. In this paper, a novel Domain Adaptive YOLO (DA-YOLO) is proposed to improve cross-domain performance for one-stage detectors. Image level features alignment is used to strictly match for local features like texture, and loosely match for global features like illumination. Multi-scale instance level features alignment is presented to reduce instance domain shift effectively , such as variations in object appearance and viewpoint. A consensus regularization to these domain classifiers is employed to help the network generate domain-invariant detections. We evaluate our proposed method on popular datasets like Cityscapes, KITTI, SIM10K and etc.. The results demonstrate significant improvement when tested under different cross-domain scenarios.
Spiking-YOLO: Spiking Neural Network for Real-time Object Detection
Mar 12, 2019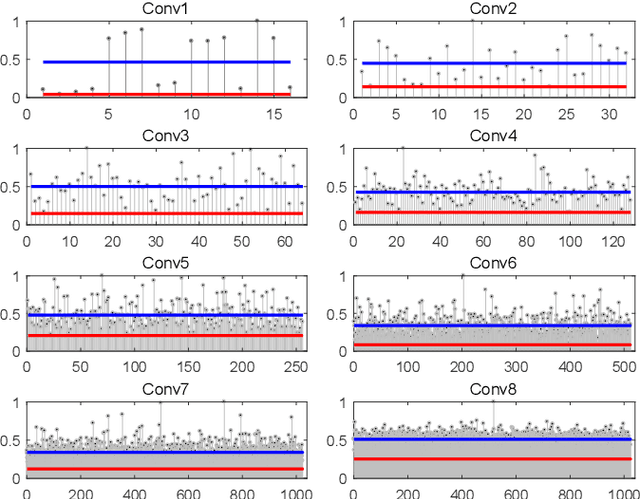
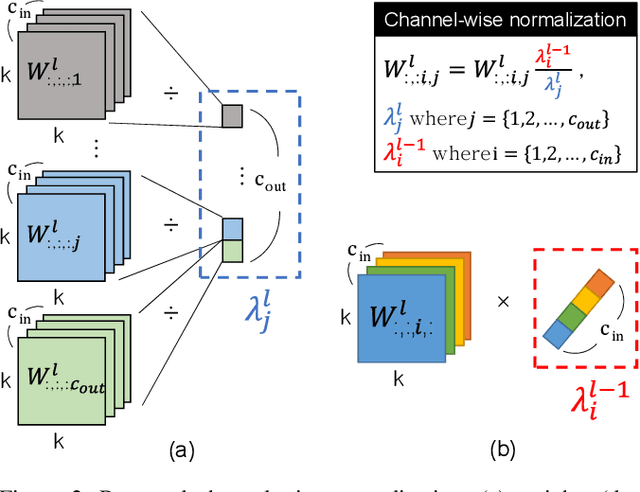
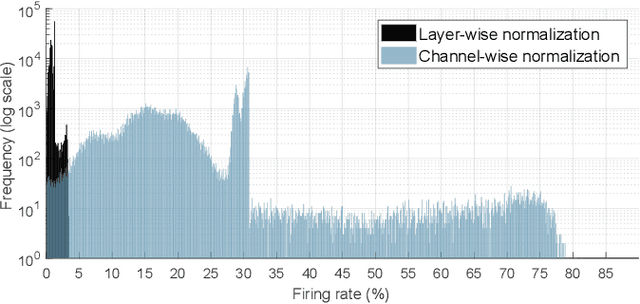
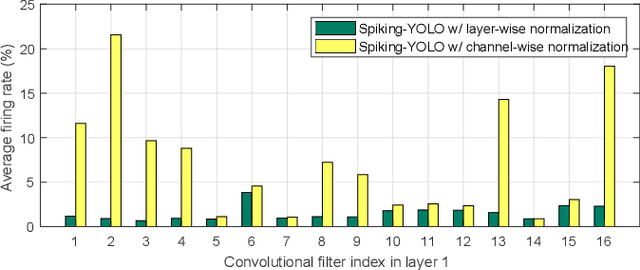
Over the past decade, deep neural networks (DNNs) have become a de-facto standard for solving machine learning problems. As we try to solve more advanced problems, growing demand for computing and power resources are inevitable, nearly impossible to employ DNNs on embedded systems, where available resources are limited. Given these circumstances, spiking neural networks (SNNs) are attracting widespread interest as the third generation of neural network, due to event-driven and low-powered nature. However, SNNs come at the cost of significant performance degradation largely due to complex dynamics of SNN neurons and non-differential spike operation. Thus, its application has been limited to relatively simple tasks such as image classification. In this paper, we investigate the performance degradation of SNNs in the much more challenging task of object detection. From our in-depth analysis, we introduce two novel methods to overcome a significant performance gap: channel-wise normalization and signed neuron with imbalanced threshold. Consequently, we present a spiked-based real-time object detection model, called Spiking-YOLO that provides near-lossless information transmission in a shorter period of time for deep SNN. Our experiments show that the Spiking-YOLO is able to achieve comparable results up to 97% of the original YOLO on a non-trivial dataset, PASCAL VOC.
Byzantine-robust Federated Learning through Spatial-temporal Analysis of Local Model Updates
Jul 03, 2021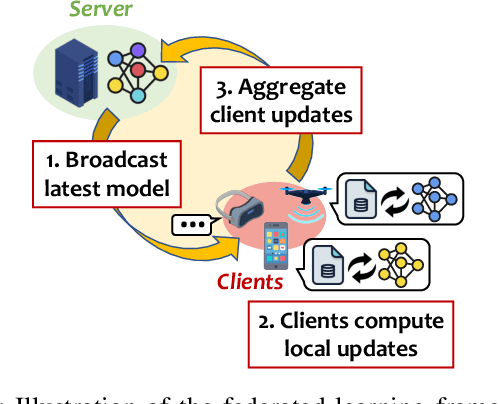
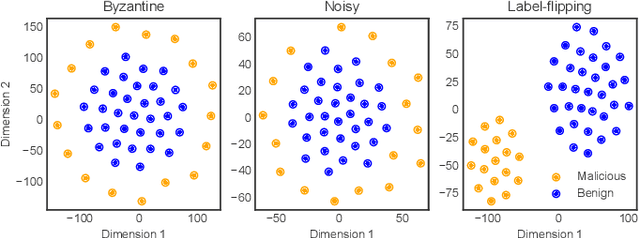
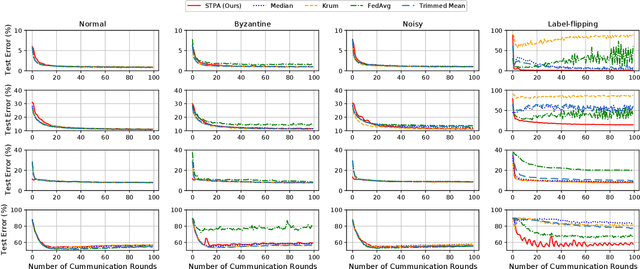
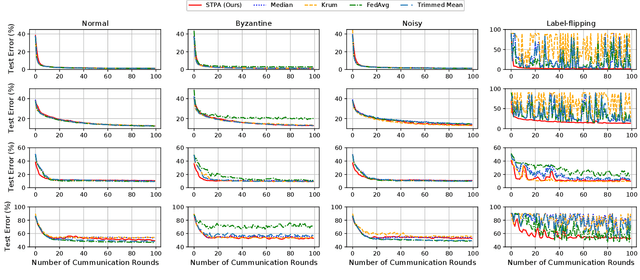
Federated Learning (FL) enables multiple distributed clients (e.g., mobile devices) to collaboratively train a centralized model while keeping the training data locally on the client. Compared to traditional centralized machine learning, FL offers many favorable features such as offloading operations which would usually be performed by a central server and reducing risks of serious privacy leakage. However, Byzantine clients that send incorrect or disruptive updates due to system failures or adversarial attacks may disturb the joint learning process, consequently degrading the performance of the resulting model. In this paper, we propose to mitigate these failures and attacks from a spatial-temporal perspective. Specifically, we use a clustering-based method to detect and exclude incorrect updates by leveraging their geometric properties in the parameter space. Moreover, to further handle malicious clients with time-varying behaviors, we propose to adaptively adjust the learning rate according to momentum-based update speculation. Extensive experiments on 4 public datasets demonstrate that our algorithm achieves enhanced robustness comparing to existing methods under both cross-silo and cross-device FL settings with faulty/malicious clients.