 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Practicality of Deterministic Epistemic Uncertainty
Jul 01, 2021
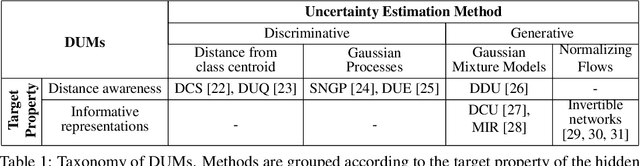
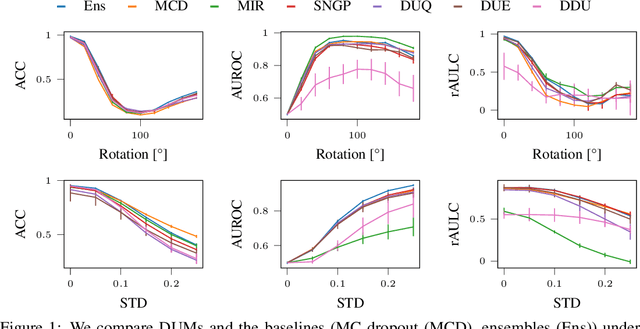
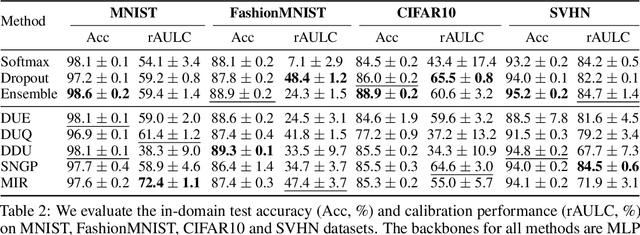
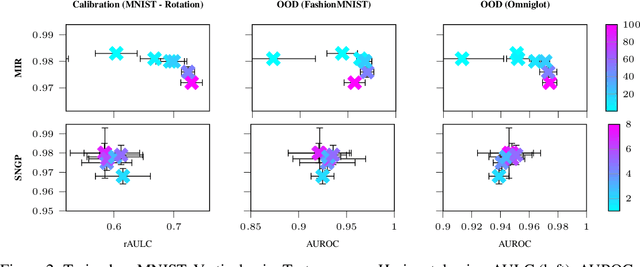
A set of novel approaches for estimating epistemic uncertainty in deep neural networks with a single forward pass has recently emerged as a valid alternative to Bayesian Neural Networks. On the premise of informative representations, these deterministic uncertainty methods (DUMs) achieve strong performance on detecting out-of-distribution (OOD) data while adding negligible computational costs at inference time. However, it remains unclear whether DUMs are well calibrated and can seamlessly scale to real-world applications - both prerequisites for their practical deployment. To this end, we first provide a taxonomy of DUMs, evaluate their calibration under continuous distributional shifts and their performance on OOD detection for image classification tasks. Then, we extend the most promising approaches to semantic segmentation. We find that, while DUMs scale to realistic vision tasks and perform well on OOD detection, the practicality of current methods is undermined by poor calibration under realistic distributional shifts.
Q-SMASH: Q-Learning-based Self-Adaptation of Human-Centered Internet of Things
Jul 13, 2021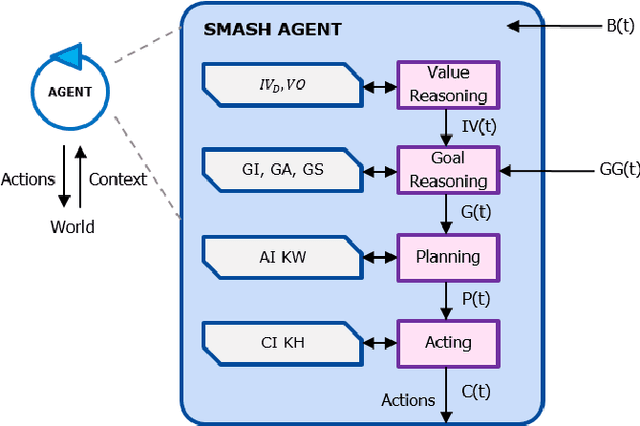

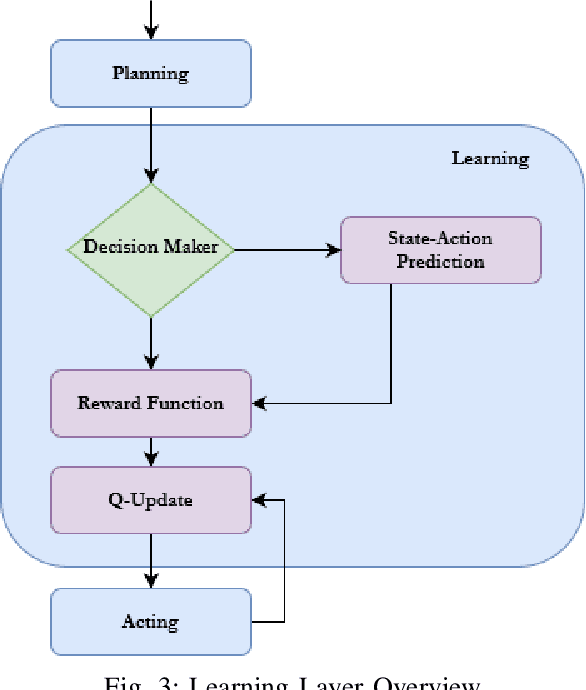
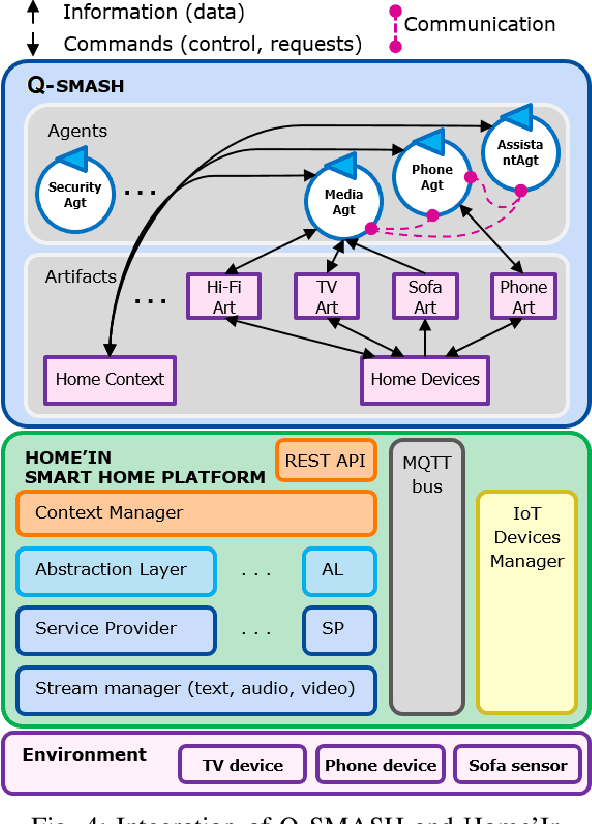
As the number of Human-Centered Internet of Things (HCIoT) applications increases, the self-adaptation of its services and devices is becoming a fundamental requirement for addressing the uncertainties of the environment in decision-making processes. Self-adaptation of HCIoT aims to manage run-time changes in a dynamic environment and to adjust the functionality of IoT objects in order to achieve desired goals during execution. SMASH is a semantic-enabled multi-agent system for self-adaptation of HCIoT that autonomously adapts IoT objects to uncertainties of their environment. SMASH addresses the self-adaptation of IoT applications only according to the human values of users, while the behavior of users is not addressed. This article presents Q-SMASH: a multi-agent reinforcement learning-based approach for self-adaptation of IoT objects in human-centered environments. Q-SMASH aims to learn the behaviors of users along with respecting human values. The learning ability of Q-SMASH allows it to adapt itself to the behavioral change of users and make more accurate decisions in different states and situations.
Energy-Efficient mm-Wave Backhauling via Frame Aggregation in Wide Area Networks
May 20, 2021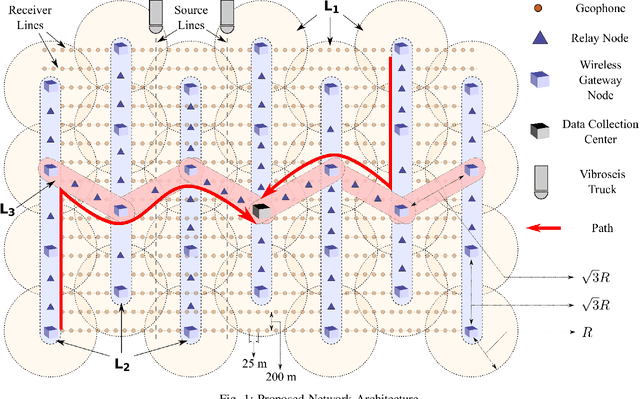
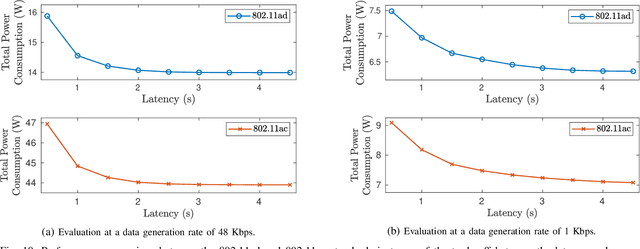
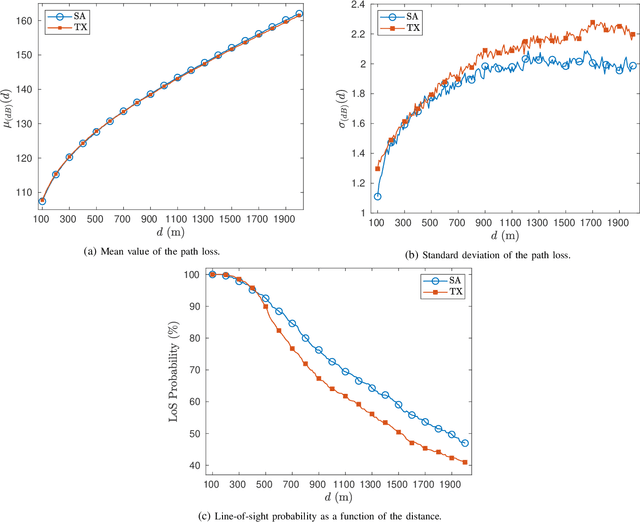
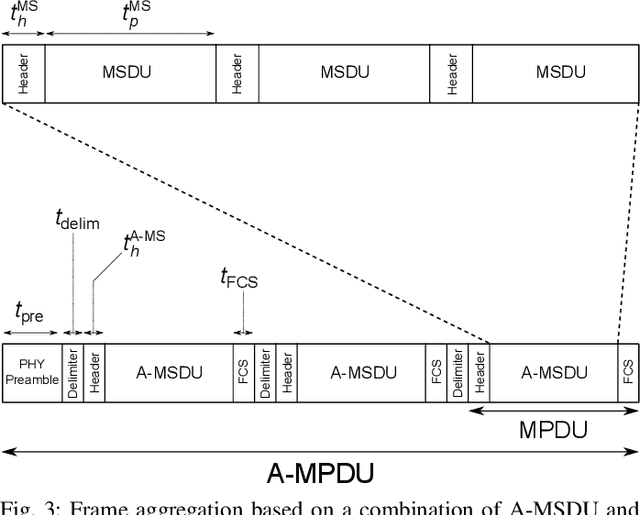
Wide area networks for surveying applications, such as seismic acquisition, have been witnessing a significant increase in node density and area, where large amounts of data have to be transferred in real-time. While cables can meet these requirements, they account for a majority of the equipment weight, maintenance, and labor costs. A novel wireless network architecture, compliant with the IEEE 802.11ad standard, is proposed for establishing scalable, energy-efficient, and gigabit-rate backhaul across very large areas. Statistical path-loss and line-of-sight models are derived using real-world topographic data in well-known seismic regions. Additionally, a cross-layer analytical model is derived for 802.11 systems that can characterize the overall latency and power consumption under the impact of co-channel interference. On the basis of these models, a Frame Aggregation Power-Saving Backhaul (FA-PSB) scheme is proposed for near-optimal power conservation under a latency constraint, through a duty-cycled approach. A performance evaluation with respect to the survey size and data generation rate reveals that the proposed architecture and the FA-PSB scheme can support real-time acquisition in large-scale high-density scenarios while operating with minimal power consumption, thereby enhancing the lifetime of wireless seismic surveys. The FA-PSB scheme can be applied to cellular backhaul and sensor networks as well.
Structure-Preserving Multi-Domain Stain Color Augmentation using Style-Transfer with Disentangled Representations
Jul 26, 2021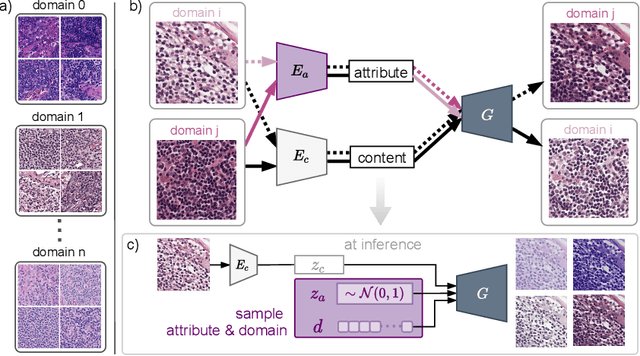
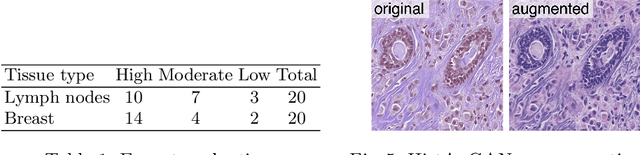
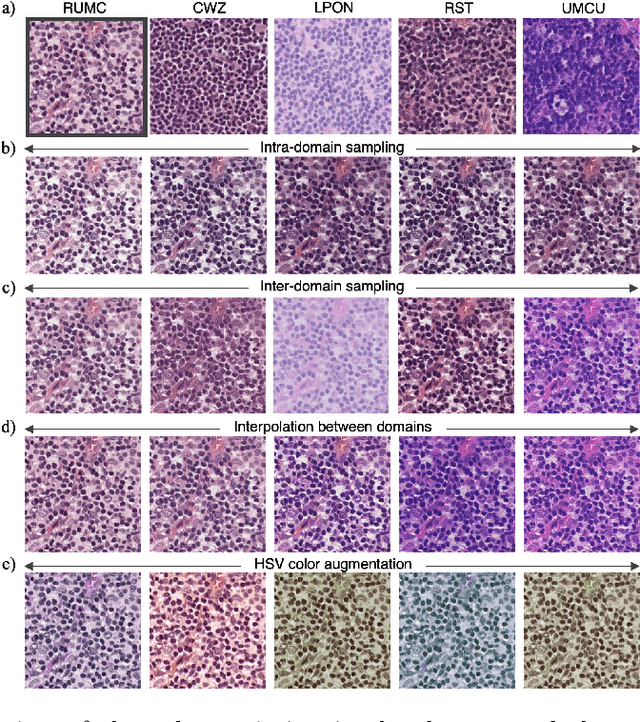
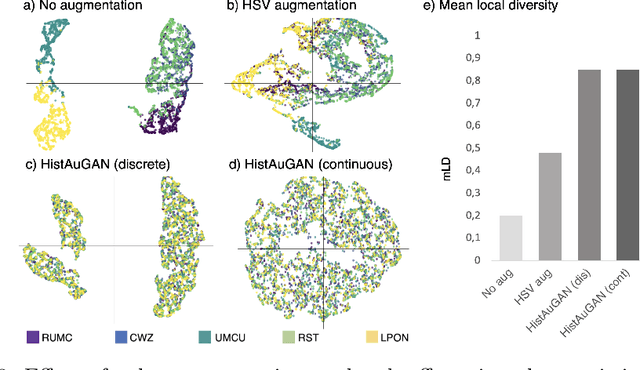
In digital pathology, different staining procedures and scanners cause substantial color variations in whole-slide images (WSIs), especially across different laboratories. These color shifts result in a poor generalization of deep learning-based methods from the training domain to external pathology data. To increase test performance, stain normalization techniques are used to reduce the variance between training and test domain. Alternatively, color augmentation can be applied during training leading to a more robust model without the extra step of color normalization at test time. We propose a novel color augmentation technique, HistAuGAN, that can simulate a wide variety of realistic histology stain colors, thus making neural networks stain-invariant when applied during training. Based on a generative adversarial network (GAN) for image-to-image translation, our model disentangles the content of the image, i.e., the morphological tissue structure, from the stain color attributes. It can be trained on multiple domains and, therefore, learns to cover different stain colors as well as other domain-specific variations introduced in the slide preparation and imaging process. We demonstrate that HistAuGAN outperforms conventional color augmentation techniques on a classification task on the publicly available dataset Camelyon17 and show that it is able to mitigate present batch effects.
Finite Time Adaptive Stabilization of LQ Systems
Jul 22, 2018Stabilization of linear systems with unknown dynamics is a canonical problem in adaptive control. Since the lack of knowledge of system parameters can cause it to become destabilized, an adaptive stabilization procedure is needed prior to regulation. Therefore, the adaptive stabilization needs to be completed in finite time. In order to achieve this goal, asymptotic approaches are not very helpful. There are only a few existing non-asymptotic results and a full treatment of the problem is not currently available. In this work, leveraging the novel method of random linear feedbacks, we establish high probability guarantees for finite time stabilization. Our results hold for remarkably general settings because we carefully choose a minimal set of assumptions. These include stabilizability of the underlying system and restricting the degree of heaviness of the noise distribution. To derive our results, we also introduce a number of new concepts and technical tools to address regularity and instability of the closed-loop matrix.
3D Iterative Spatiotemporal Filtering for Classification of Multitemporal Satellite Data Sets
Jul 01, 2021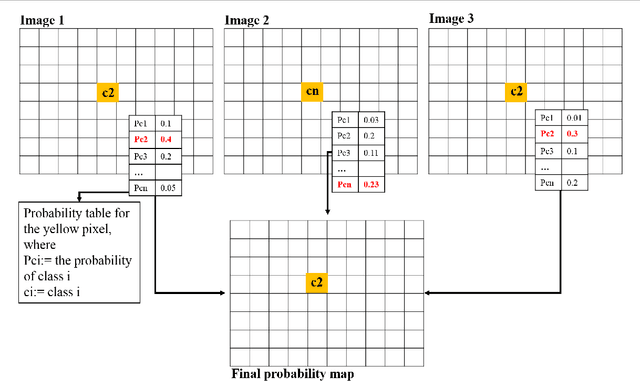

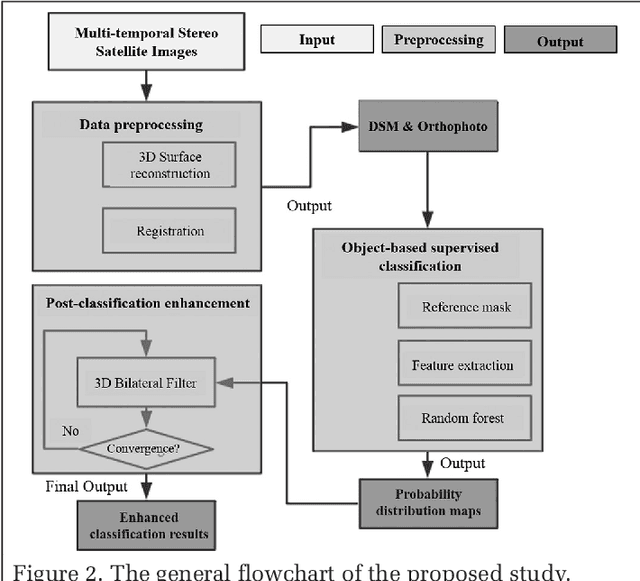
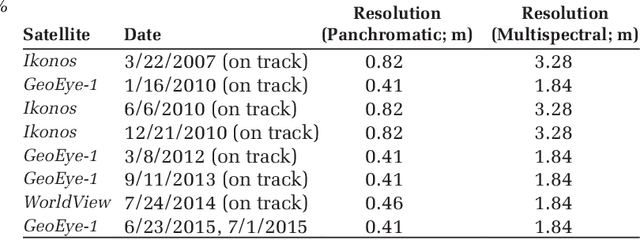
The current practice in land cover/land use change analysis relies heavily on the individually classified maps of the multitemporal data set. Due to varying acquisition conditions (e.g., illumination, sensors, seasonal differences), the classification maps yielded are often inconsistent through time for robust statistical analysis. 3D geometric features have been shown to be stable for assessing differences across the temporal data set. Therefore, in this article we investigate he use of a multitemporal orthophoto and digital surface model derived from satellite data for spatiotemporal classification. Our approach consists of two major steps: generating per-class probability distribution maps using the random-forest classifier with limited training samples, and making spatiotemporal inferences using an iterative 3D spatiotemporal filter operating on per-class probability maps. Our experimental results demonstrate that the proposed methods can consistently improve the individual classification results by 2%-6% and thus can be an important postclassification refinement approach.
High-Power and High-Capacity Mobile Optical SWIPT
Jul 20, 2021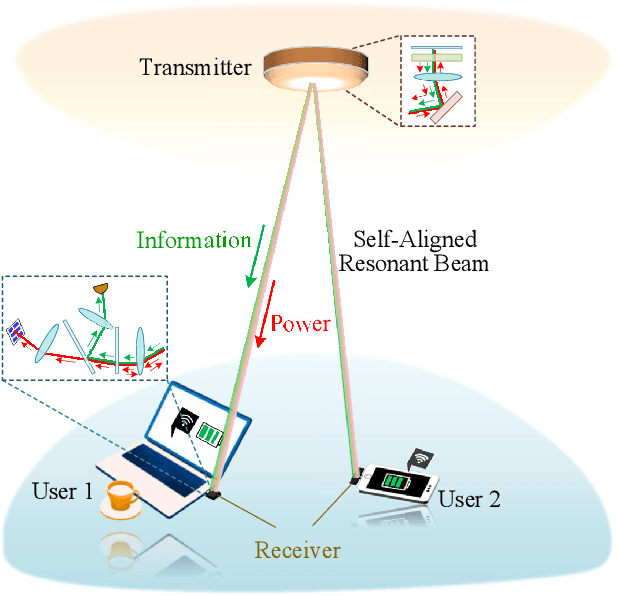
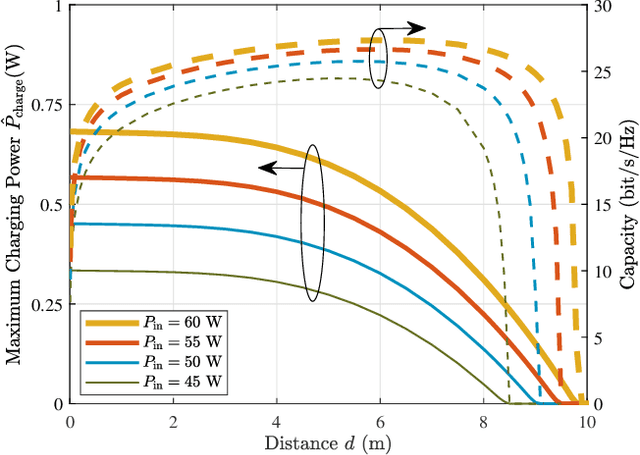
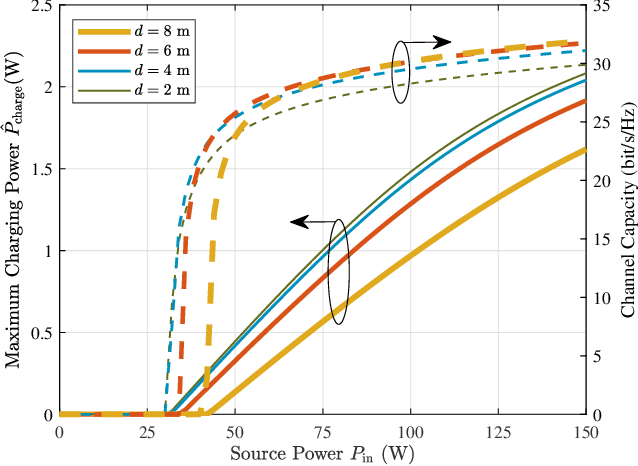
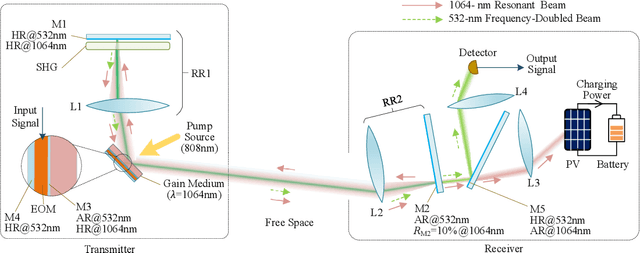
The increasing demands of power supply and data rate for mobile devices promote the research of simultaneous information and power transfer (SWIPT). Optical SWIPT, as known as simultaneous light information and power transfer (SLIPT), can provide high-capacity communication and high-power charging. However, light emitting diodes (LEDs)-based SLIPT technologies have low efficiency due to energy dissipation over the air. Laser-based SLIPT technologies face the challenge in mobility, as it needs accurate positioning, fast beam steering, and real-time tracking. In this paper, we propose a mobile SLIPT scheme based on spatially separated laser resonator (SSLR) and intra-cavity second harmonic generation (SHG). The power and data are transferred via separated frequencies, while they share the same self-aligned resonant beam path, without the needs of receiver positioning and beam steering. We establish the analysis model of the resonant beam power and its second harmonic power. We also evaluate the system performance on deliverable power and channel capacity. Numerical results show that the proposed system can achieve watt-level battery charging power and above 20-bit/s/Hz communication capacity over 8-m distance, which satisfies the requirements of most indoor mobile devices.
From Implicit to Explicit feedback: A deep neural network for modeling sequential behaviours and long-short term preferences of online users
Jul 26, 2021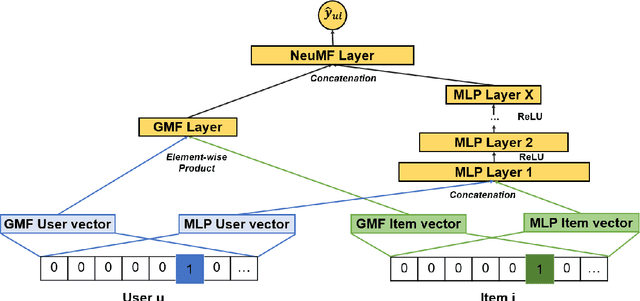
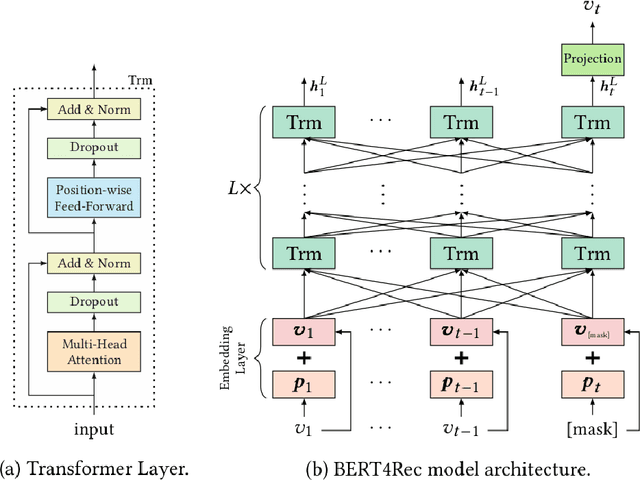
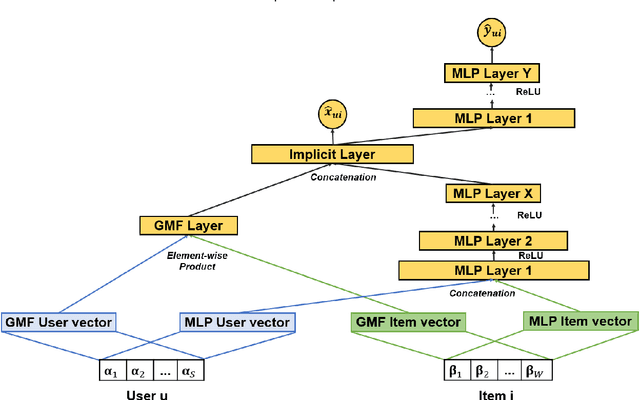
In this work, we examine the advantages of using multiple types of behaviour in recommendation systems. Intuitively, each user has to do some implicit actions (e.g., click) before making an explicit decision (e.g., purchase). Previous studies showed that implicit and explicit feedback have different roles for a useful recommendation. However, these studies either exploit implicit and explicit behaviour separately or ignore the semantic of sequential interactions between users and items. In addition, we go from the hypothesis that a user's preference at a time is a combination of long-term and short-term interests. In this paper, we propose some Deep Learning architectures. The first one is Implicit to Explicit (ITE), to exploit users' interests through the sequence of their actions. And two versions of ITE with Bidirectional Encoder Representations from Transformers based (BERT-based) architecture called BERT-ITE and BERT-ITE-Si, which combine users' long- and short-term preferences without and with side information to enhance user representation. The experimental results show that our models outperform previous state-of-the-art ones and also demonstrate our views on the effectiveness of exploiting the implicit to explicit order as well as combining long- and short-term preferences in two large-scale datasets.
A Multimodal Deep Learning Model for Cardiac Resynchronisation Therapy Response Prediction
Jul 20, 2021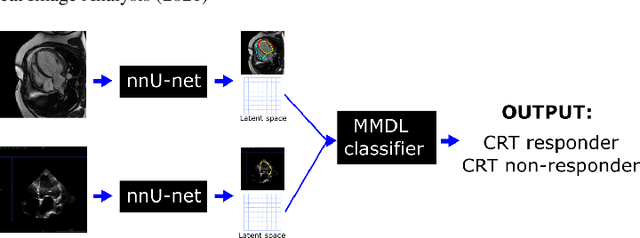
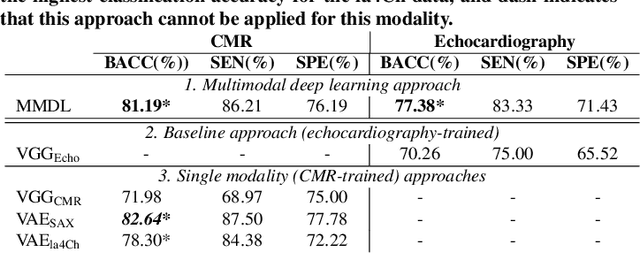
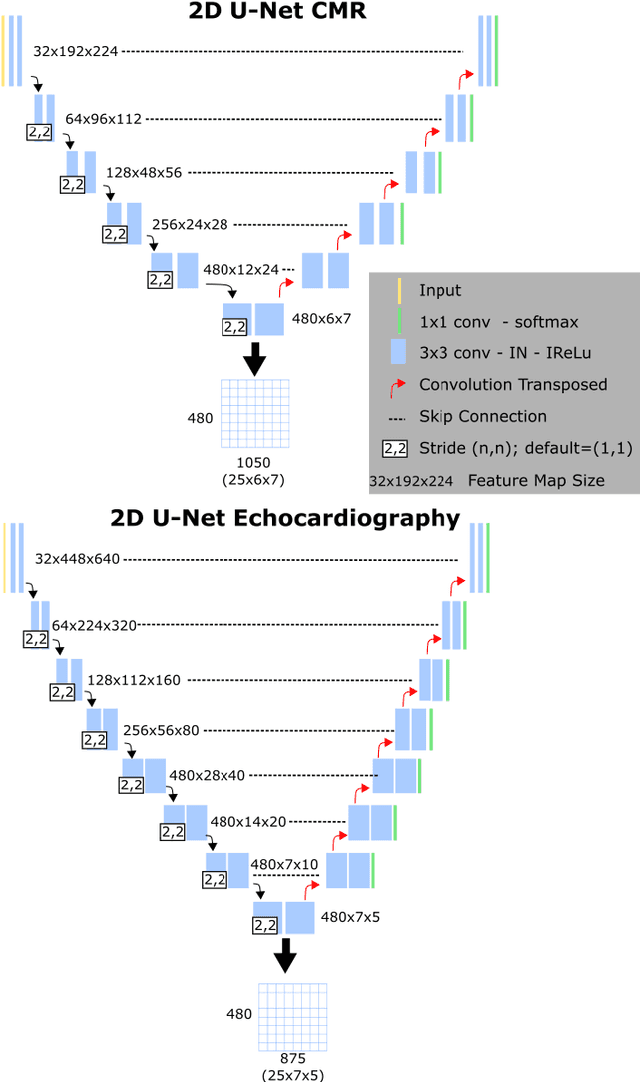
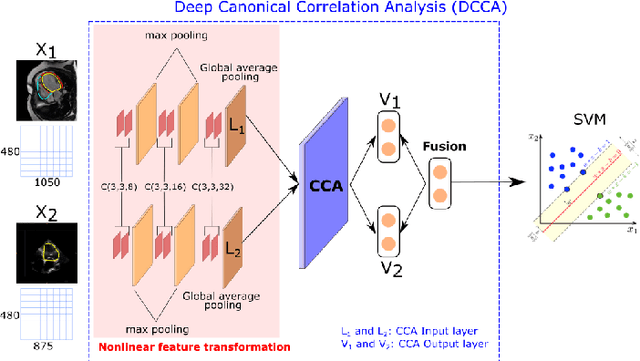
We present a novel multimodal deep learning framework for cardiac resynchronisation therapy (CRT) response prediction from 2D echocardiography and cardiac magnetic resonance (CMR) data. The proposed method first uses the `nnU-Net' segmentation model to extract segmentations of the heart over the full cardiac cycle from the two modalities. Next, a multimodal deep learning classifier is used for CRT response prediction, which combines the latent spaces of the segmentation models of the two modalities. At inference time, this framework can be used with 2D echocardiography data only, whilst taking advantage of the implicit relationship between CMR and echocardiography features learnt from the model. We evaluate our pipeline on a cohort of 50 CRT patients for whom paired echocardiography/CMR data were available, and results show that the proposed multimodal classifier results in a statistically significant improvement in accuracy compared to the baseline approach that uses only 2D echocardiography data. The combination of multimodal data enables CRT response to be predicted with 77.38% accuracy (83.33% sensitivity and 71.43% specificity), which is comparable with the current state-of-the-art in machine learning-based CRT response prediction. Our work represents the first multimodal deep learning approach for CRT response prediction.
Highly Efficient Knowledge Graph Embedding Learning with Orthogonal Procrustes Analysis
Apr 17, 2021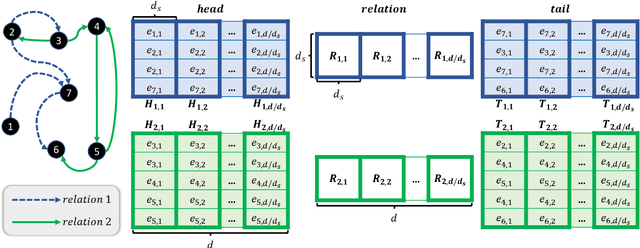
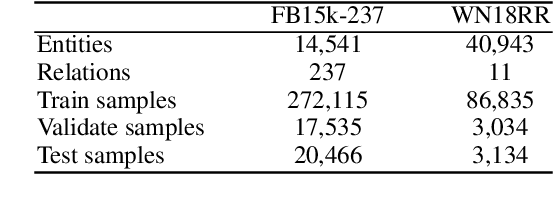
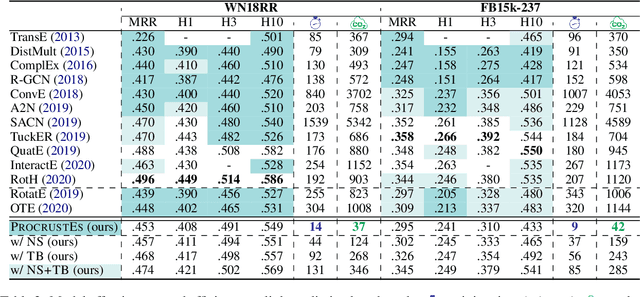
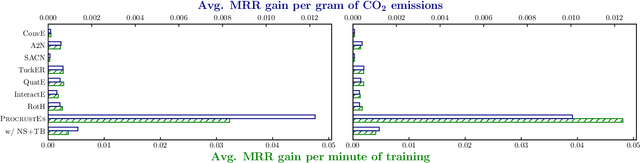
Knowledge Graph Embeddings (KGEs) have been intensively explored in recent years due to their promise for a wide range of applications. However, existing studies focus on improving the final model performance without acknowledging the computational cost of the proposed approaches, in terms of execution time and environmental impact. This paper proposes a simple yet effective KGE framework which can reduce the training time and carbon footprint by orders of magnitudes compared with state-of-the-art approaches, while producing competitive performance. We highlight three technical innovations: full batch learning via relational matrices, closed-form Orthogonal Procrustes Analysis for KGEs, and non-negative-sampling training. In addition, as the first KGE method whose entity embeddings also store full relation information, our trained models encode rich semantics and are highly interpretable. Comprehensive experiments and ablation studies involving 13 strong baselines and two standard datasets verify the effectiveness and efficiency of our algorithm.