 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavTrust: Benchmarking Trustworthiness for Embodied Navigation
Mar 19, 2026There are two major categories of embodied navigation: Vision-Language Navigation (VLN), where agents navigate by following natural language instructions; and Object-Goal Navigation (OGN), where agents navigate to a specified target object. However, existing work primarily evaluates model performance under nominal conditions, overlooking the potential corruptions that arise in real-world settings. To address this gap, we present NavTrust, a unified benchmark that systematically corrupts input modalities, including RGB, depth, and instructions, in realistic scenarios and evaluates their impact on navigation performance. To our best knowledge, NavTrust is the first benchmark that exposes embodied navigation agents to diverse RGB-Depth corruptions and instruction variations in a unified framework. Our extensive evaluation of seven state-of-the-art approaches reveals substantial performance degradation under realistic corruptions, which highlights critical robustness gaps and provides a roadmap toward more trustworthy embodied navigation systems. Furthermore, we systematically evaluate four distinct mitigation strategies to enhance robustness against RGB-Depth and instructions corruptions. Our base models include Uni-NaVid and ETPNav. We deployed them on a real mobile robot and observed improved robustness to corruptions. The project website is: https://navtrust.github.io.
RLHF: A comprehensive Survey for Cultural, Multimodal and Low Latency Alignment Methods
Nov 06, 2025Reinforcement Learning from Human Feedback (RLHF) is the standard for aligning Large Language Models (LLMs), yet recent progress has moved beyond canonical text-based methods. This survey synthesizes the new frontier of alignment research by addressing critical gaps in multi-modal alignment, cultural fairness, and low-latency optimization. To systematically explore these domains, we first review foundational algo- rithms, including PPO, DPO, and GRPO, before presenting a detailed analysis of the latest innovations. By providing a comparative synthesis of these techniques and outlining open challenges, this work serves as an essential roadmap for researchers building more robust, efficient, and equitable AI systems.
Structure-Preserving Multi-Domain Stain Color Augmentation using Style-Transfer with Disentangled Representations
Jul 26, 2021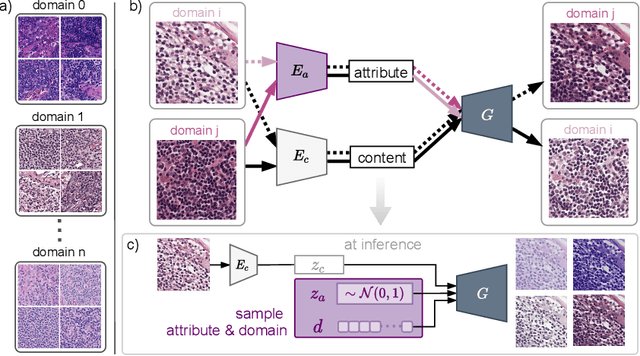
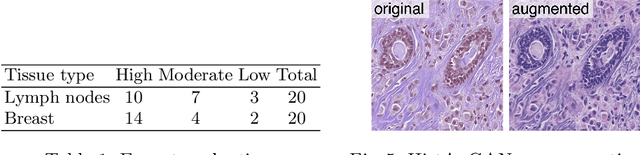
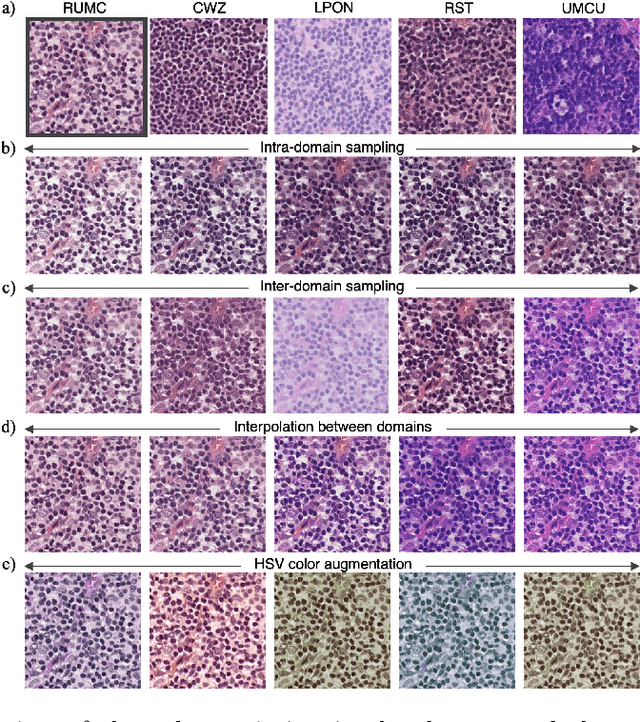
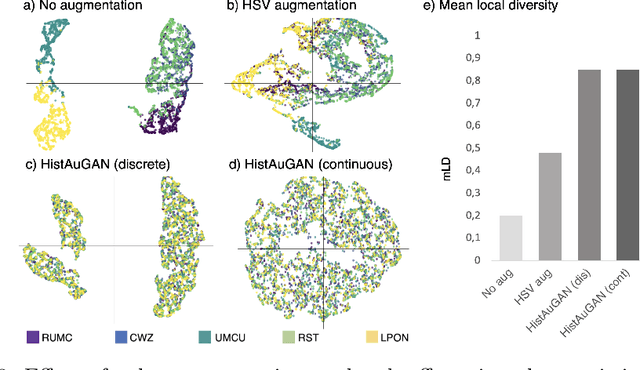
In digital pathology, different staining procedures and scanners cause substantial color variations in whole-slide images (WSIs), especially across different laboratories. These color shifts result in a poor generalization of deep learning-based methods from the training domain to external pathology data. To increase test performance, stain normalization techniques are used to reduce the variance between training and test domain. Alternatively, color augmentation can be applied during training leading to a more robust model without the extra step of color normalization at test time. We propose a novel color augmentation technique, HistAuGAN, that can simulate a wide variety of realistic histology stain colors, thus making neural networks stain-invariant when applied during training. Based on a generative adversarial network (GAN) for image-to-image translation, our model disentangles the content of the image, i.e., the morphological tissue structure, from the stain color attributes. It can be trained on multiple domains and, therefore, learns to cover different stain colors as well as other domain-specific variations introduced in the slide preparation and imaging process. We demonstrate that HistAuGAN outperforms conventional color augmentation techniques on a classification task on the publicly available dataset Camelyon17 and show that it is able to mitigate present batch effects.