 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Application of Time Series Analysis to Traffic Accidents in Los Angeles
Nov 28, 2019
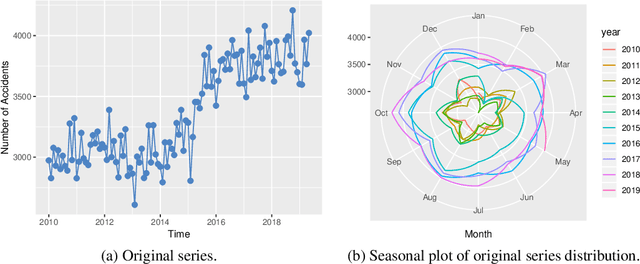

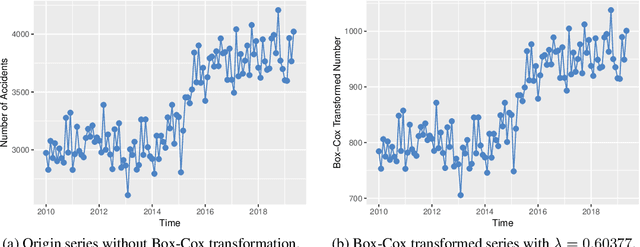

With the improvements of Los Angeles in many aspects, people in mounting numbers tend to live or travel to the city. The primary objective of this paper is to apply a set of methods for the time series analysis of traffic accidents in Los Angeles in the past few years. The number of traffic accidents, collected from 2010 to 2019 monthly reveals that the traffic accident happens seasonally and increasing with fluctuation. This paper utilizes the ensemble methods to combine several different methods to model the data from various perspectives, which can lead to better forecasting accuracy. The IMA(1, 1), ETS(A, N, A), and two models with Fourier items are failed in independence assumption checking. However, the Online Gradient Descent (OGD) model generated by the ensemble method shows the perfect fit in the data modeling, which is the state-of-the-art model among our candidate models. Therefore, it can be easier to accurately forecast future traffic accidents based on previous data through our model, which can help designers to make better plans.
On Single and Multiple Representations in Dense Passage Retrieval
Aug 19, 2021
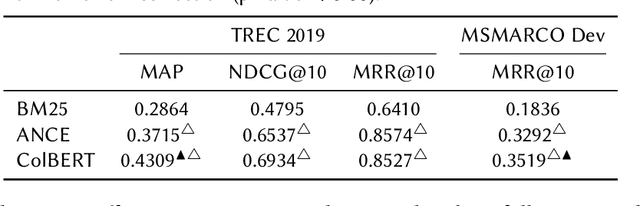
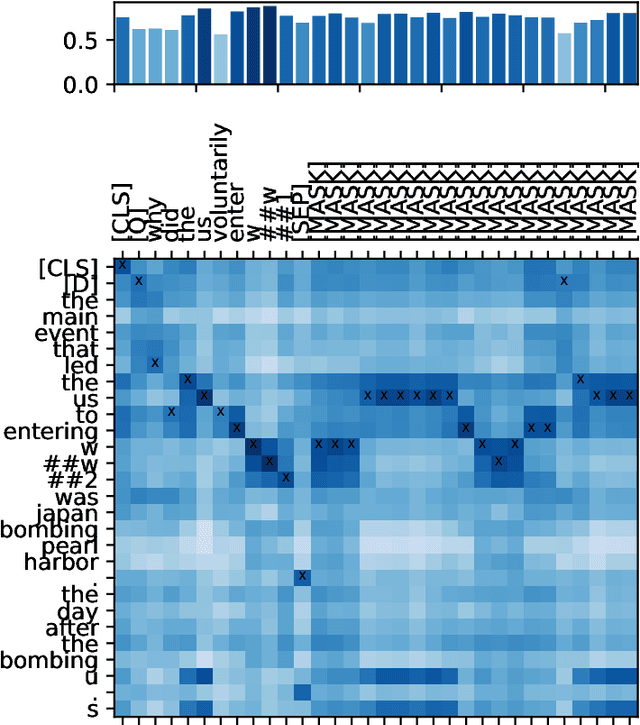
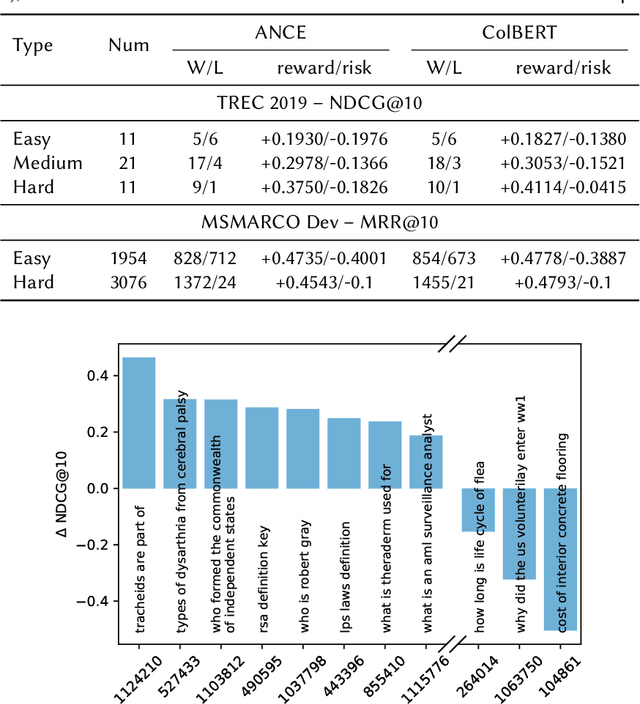
The advent of contextualised language models has brought gains in search effectiveness, not just when applied for re-ranking the output of classical weighting models such as BM25, but also when used directly for passage indexing and retrieval, a technique which is called dense retrieval. In the existing literature in neural ranking, two dense retrieval families have become apparent: single representation, where entire passages are represented by a single embedding (usually BERT's [CLS] token, as exemplified by the recent ANCE approach), or multiple representations, where each token in a passage is represented by its own embedding (as exemplified by the recent ColBERT approach). These two families have not been directly compared. However, because of the likely importance of dense retrieval moving forward, a clear understanding of their advantages and disadvantages is paramount. To this end, this paper contributes a direct study on their comparative effectiveness, noting situations where each method under/over performs w.r.t. each other, and w.r.t. a BM25 baseline. We observe that, while ANCE is more efficient than ColBERT in terms of response time and memory usage, multiple representations are statistically more effective than the single representations for MAP and MRR@10. We also show that multiple representations obtain better improvements than single representations for queries that are the hardest for BM25, as well as for definitional queries, and those with complex information needs.
Arduino Controlled Spy Robo Car using Wireless Camera With live Streaming
Aug 07, 2021
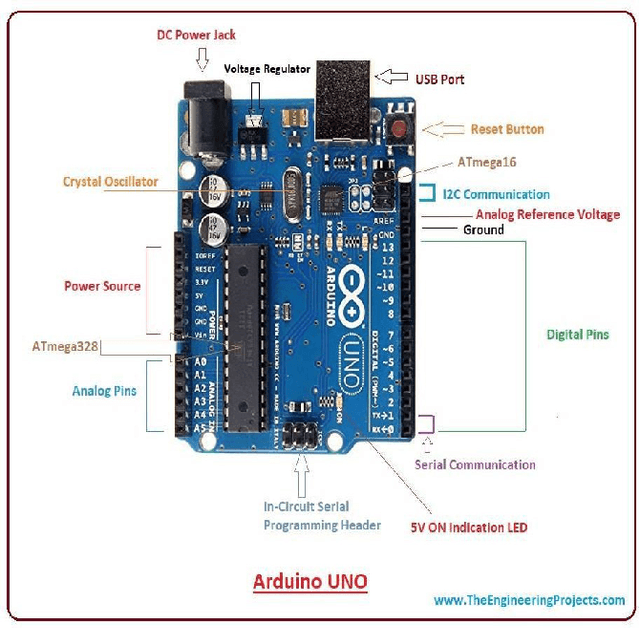
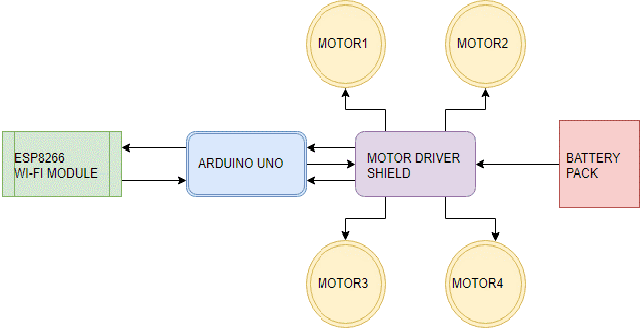
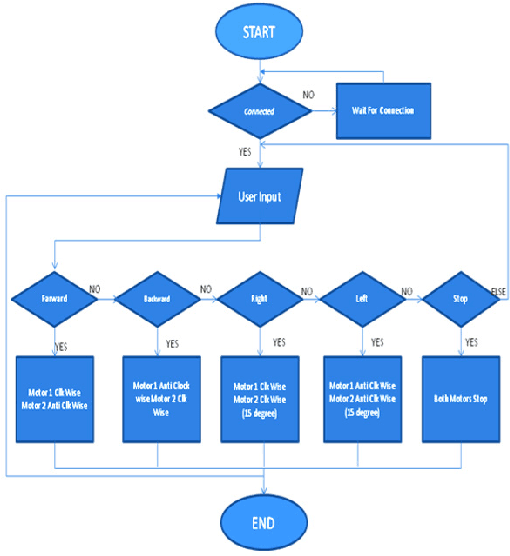
Nowadays, the technological and digital world is developing very fast. Everything is getting smart, so we are talking about the technological world the devices like home appliances and other things are getting control by mobile applications, and this only happens by the device Arduino Uno / raspberry pi3 and many others. Still, in our research we have used Arduino Uno to create a Wi-Fi controlled car with camera-top on it to monitor everything in its surrounding, we have seen many similar projects which using Arduino to makes things easy to use and its saving time and energy too. Automation is used for operating an electronic device such as the remote control car, home lighting system, and other useful things or reduced human invention. This report proposes a design and implementation of a remote-controlled camera car by Wi-Fi technology mobile devices. In this analysis work, radio code and hardware technologies area unit used, like the wireless module of ESP8266 for (transmitter and receiver), Arduino Uno as microcontroller, associate H-bridge L293D IC for motor controller and 2 electrical DC motors are used to move the car, & a Camera attached on the top of the vehicle.
Real-Time Emotion Recognition via Attention Gated Hierarchical Memory Network
Nov 20, 2019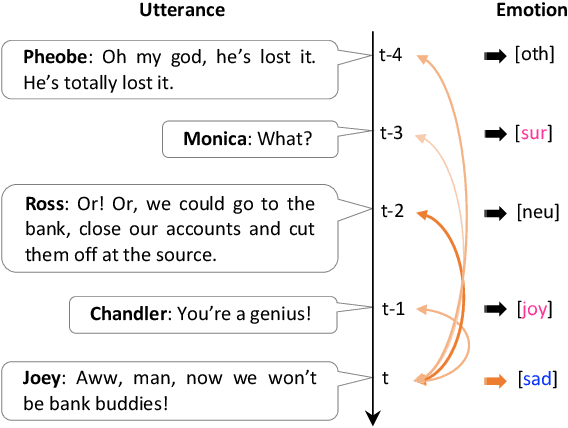
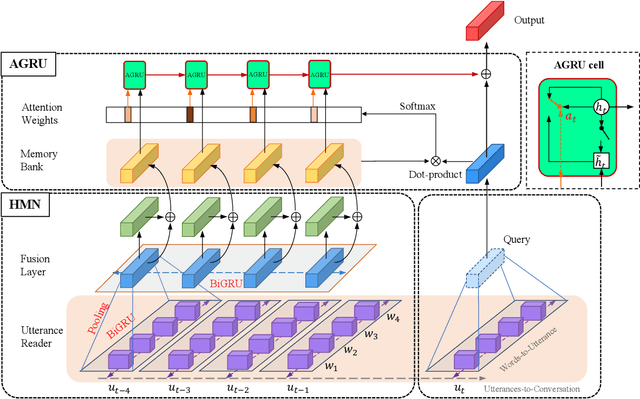
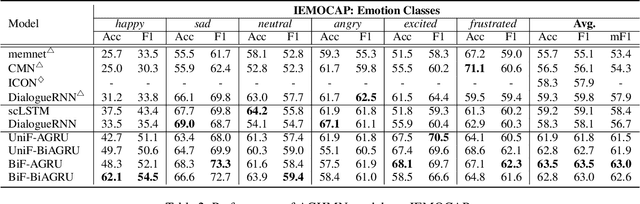
Real-time emotion recognition (RTER) in conversations is significant for developing emotionally intelligent chatting machines. Without the future context in RTER, it becomes critical to build the memory bank carefully for capturing historical context and summarize the memories appropriately to retrieve relevant information. We propose an Attention Gated Hierarchical Memory Network (AGHMN) to address the problems of prior work: (1) Commonly used convolutional neural networks (CNNs) for utterance feature extraction are less compatible in the memory modules; (2) Unidirectional gated recurrent units (GRUs) only allow each historical utterance to have context before it, preventing information propagation in the opposite direction; (3) The Soft Attention for summarizing loses the positional and ordering information of memories, regardless of how the memory bank is built. Particularly, we propose a Hierarchical Memory Network (HMN) with a bidirectional GRU (BiGRU) as the utterance reader and a BiGRU fusion layer for the interaction between historical utterances. For memory summarizing, we propose an Attention GRU (AGRU) where we utilize the attention weights to update the internal state of GRU. We further promote the AGRU to a bidirectional variant (BiAGRU) to balance the contextual information from recent memories and that from distant memories. We conduct experiments on two emotion conversation datasets with extensive analysis, demonstrating the efficacy of our AGHMN models.
Fast Passage Re-ranking with Contextualized Exact Term Matching and Efficient Passage Expansion
Aug 19, 2021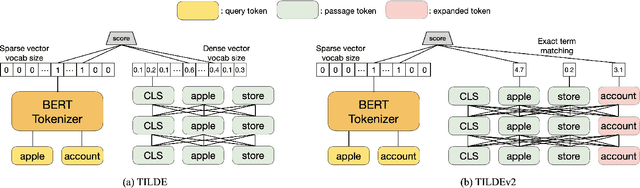
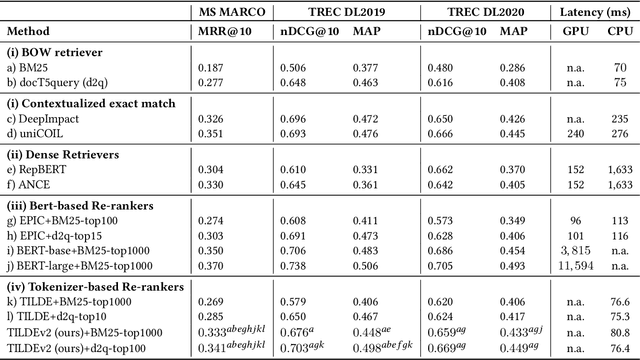
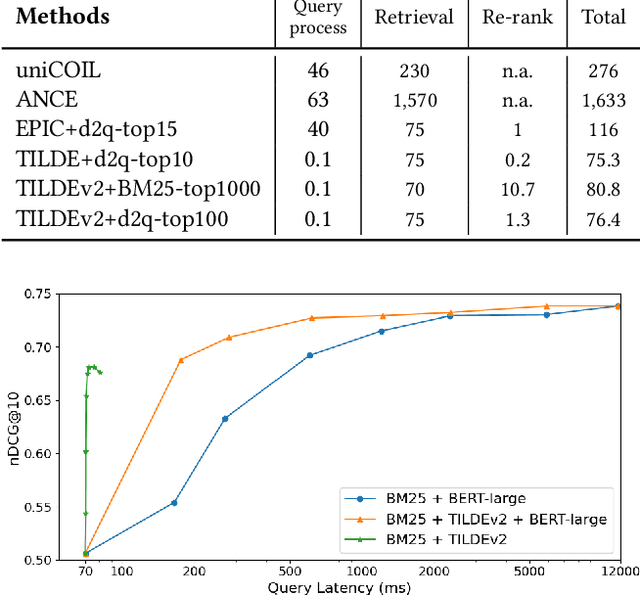

BERT-based information retrieval models are expensive, in both time (query latency) and computational resources (energy, hardware cost), making many of these models impractical especially under resource constraints. The reliance on a query encoder that only performs tokenization and on the pre-processing of passage representations at indexing, has allowed the recently proposed TILDE method to overcome the high query latency issue typical of BERT-based models. This however is at the expense of a lower effectiveness compared to other BERT-based re-rankers and dense retrievers. In addition, the original TILDE method is characterised by indexes with a very high memory footprint, as it expands each passage into the size of the BERT vocabulary. In this paper, we propose TILDEv2, a new model that stems from the original TILDE but that addresses its limitations. TILDEv2 relies on contextualized exact term matching with expanded passages. This requires to only store in the index the score of tokens that appear in the expanded passages (rather than all the vocabulary), thus producing indexes that are 99% smaller than those of TILDE. This matching mechanism also improves ranking effectiveness by 24%, without adding to the query latency. This makes TILDEv2 the state-of-the-art passage re-ranking method for CPU-only environments, capable of maintaining query latency below 100ms on commodity hardware.
Learning-Based UAV Trajectory Optimization with Collision Avoidance and Connectivity Constraints
Apr 15, 2021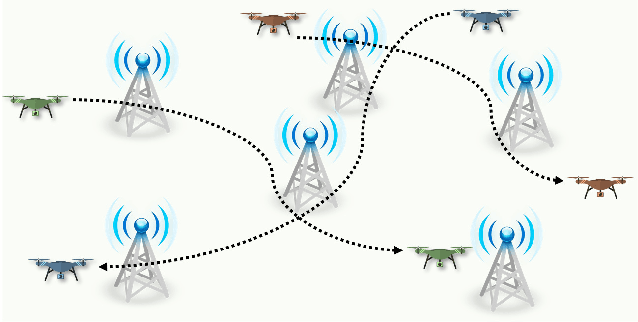
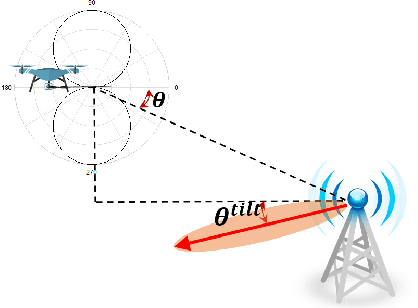
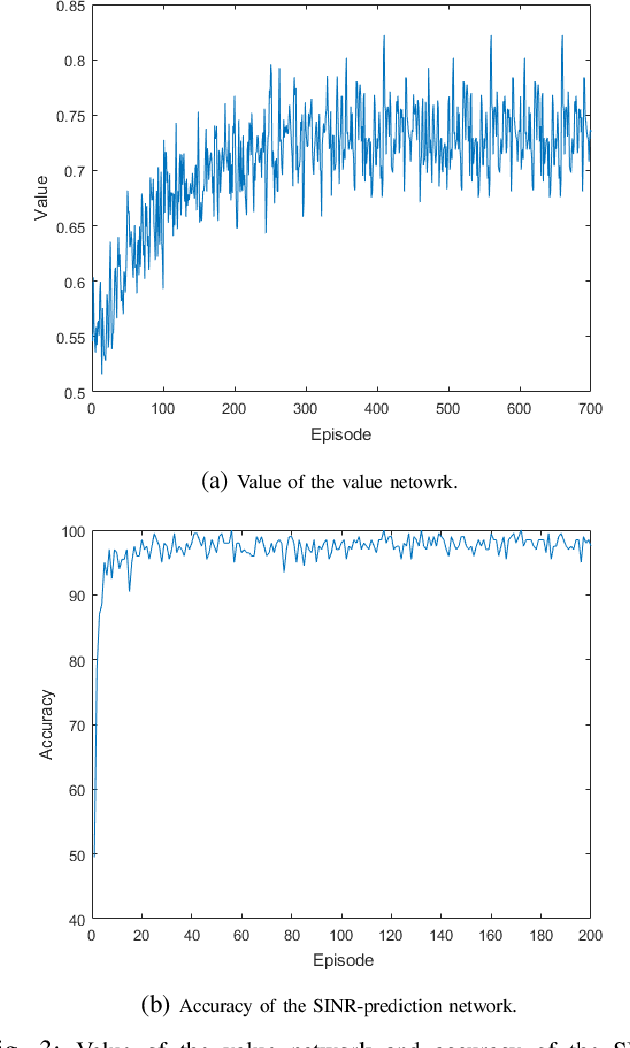
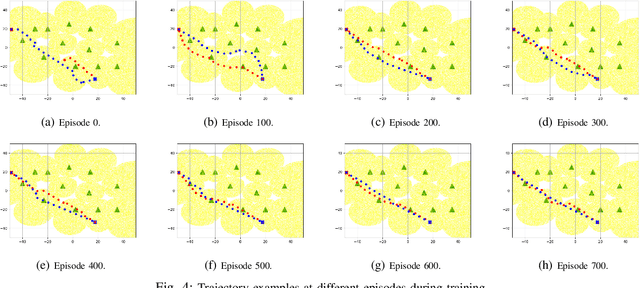
Unmanned aerial vehicles (UAVs) are expected to be an integral part of wireless networks, and determining collision-free trajectories for multiple UAVs while satisfying requirements of connectivity with ground base stations (GBSs) is a challenging task. In this paper, we first reformulate the multi-UAV trajectory optimization problem with collision avoidance and wireless connectivity constraints as a sequential decision making problem in the discrete time domain. We, then, propose a decentralized deep reinforcement learning approach to solve the problem. More specifically, a value network is developed to encode the expected time to destination given the agent's joint state (including the agent's information, the nearby agents' observable information, and the locations of the nearby GBSs). A signal-to-interference-plus-noise ratio (SINR)-prediction neural network is also designed, using accumulated SINR measurements obtained when interacting with the cellular network, to map the GBSs' locations into the SINR levels in order to predict the UAV's SINR. Numerical results show that with the value network and SINR-prediction network, real-time navigation for multi-UAVs can be efficiently performed in various environments with high success rate.
Continuous Learning and Adaptation with Membrane Potential and Activation Threshold Homeostasis
May 08, 2021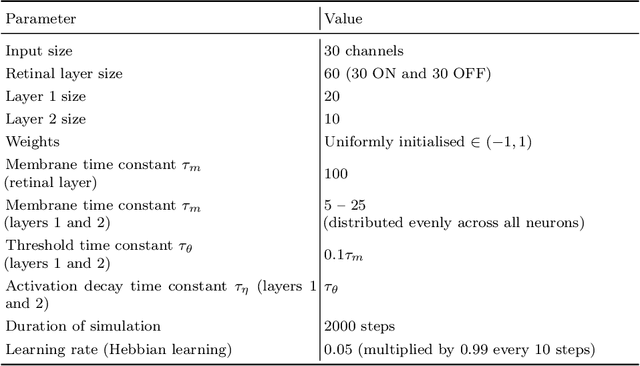
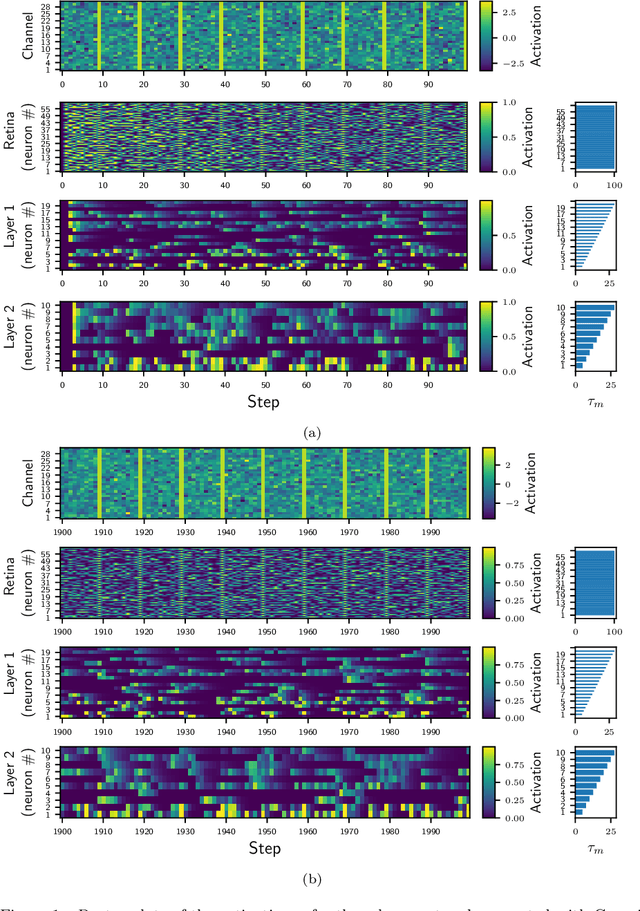
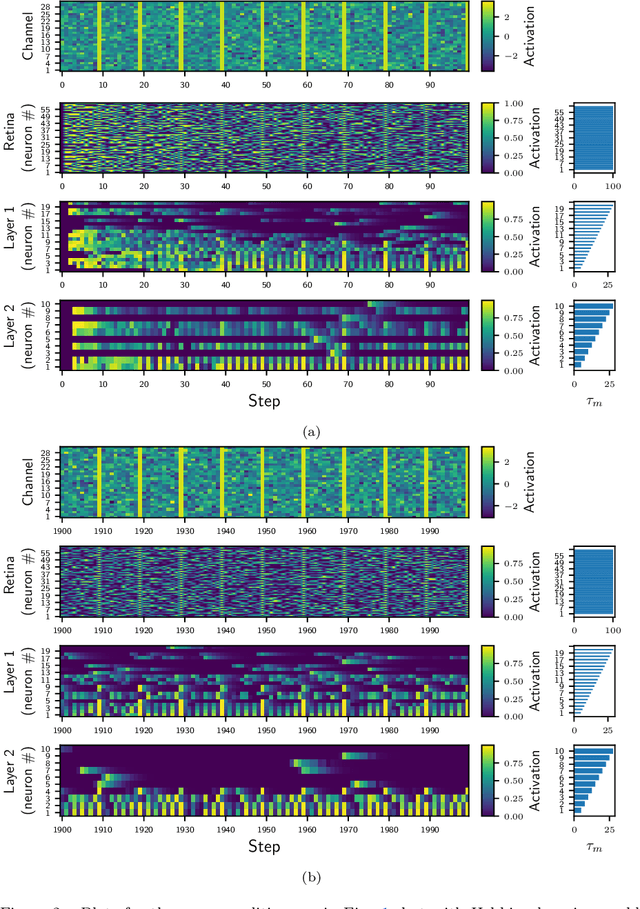
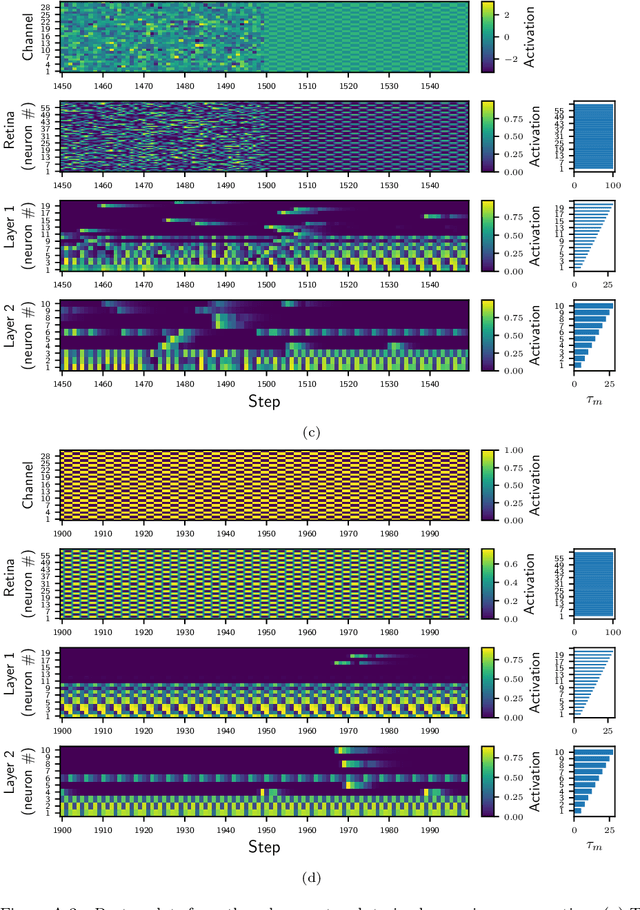
Most classical (non-spiking) neural network models disregard internal neuron dynamics and treat neurons as simple input integrators. However, biological neurons have an internal state governed by complex dynamics that plays a crucial role in learning, adaptation and the overall network activity and behaviour. This paper presents the Membrane Potential and Activation Threshold Homeostasis (MPATH) neuron model, which combines several biologically inspired mechanisms to efficiently simulate internal neuron dynamics with a single parameter analogous to the membrane time constant in biological neurons. The model allows neurons to maintain a form of dynamic equilibrium by automatically regulating their activity when presented with fluctuating input. One consequence of the MPATH model is that it imbues neurons with a sense of time without recurrent connections, paving the way for modelling processes that depend on temporal aspects of neuron activity. Experiments demonstrate the model's ability to adapt to and continually learn from its input.
Opening the Blackbox: Accelerating Neural Differential Equations by Regularizing Internal Solver Heuristics
May 09, 2021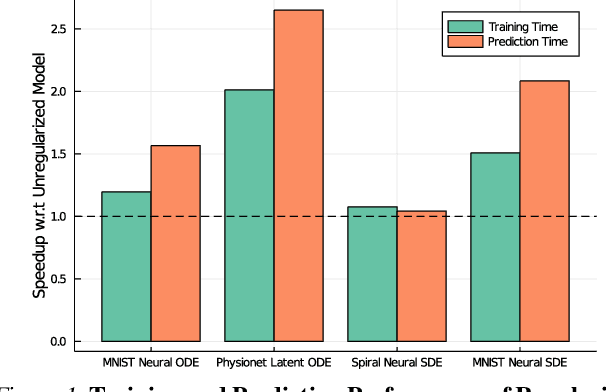
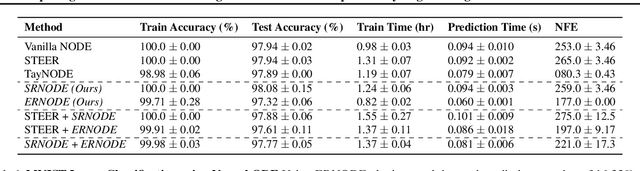
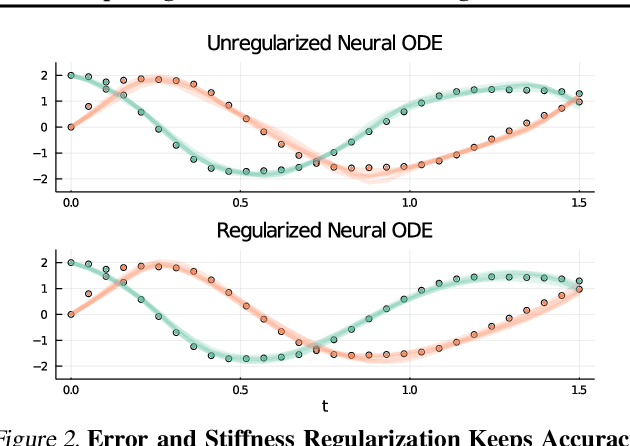
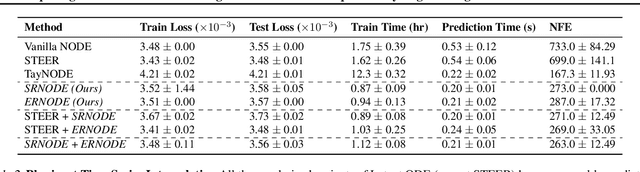
Democratization of machine learning requires architectures that automatically adapt to new problems. Neural Differential Equations (NDEs) have emerged as a popular modeling framework by removing the need for ML practitioners to choose the number of layers in a recurrent model. While we can control the computational cost by choosing the number of layers in standard architectures, in NDEs the number of neural network evaluations for a forward pass can depend on the number of steps of the adaptive ODE solver. But, can we force the NDE to learn the version with the least steps while not increasing the training cost? Current strategies to overcome slow prediction require high order automatic differentiation, leading to significantly higher training time. We describe a novel regularization method that uses the internal cost heuristics of adaptive differential equation solvers combined with discrete adjoint sensitivities to guide the training process towards learning NDEs that are easier to solve. This approach opens up the blackbox numerical analysis behind the differential equation solver's algorithm and directly uses its local error estimates and stiffness heuristics as cheap and accurate cost estimates. We incorporate our method without any change in the underlying NDE framework and show that our method extends beyond Ordinary Differential Equations to accommodate Neural Stochastic Differential Equations. We demonstrate how our approach can halve the prediction time and, unlike other methods which can increase the training time by an order of magnitude, we demonstrate similar reduction in training times. Together this showcases how the knowledge embedded within state-of-the-art equation solvers can be used to enhance machine learning.
HiFT: Hierarchical Feature Transformer for Aerial Tracking
Jul 31, 2021
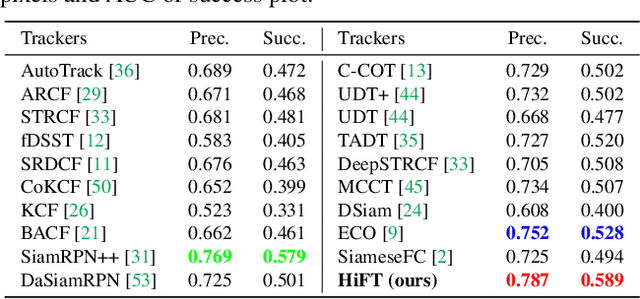
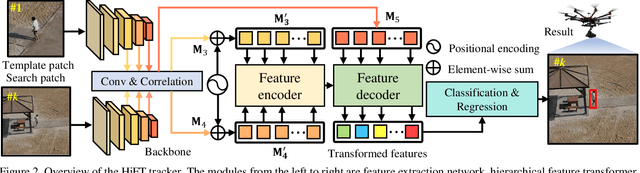
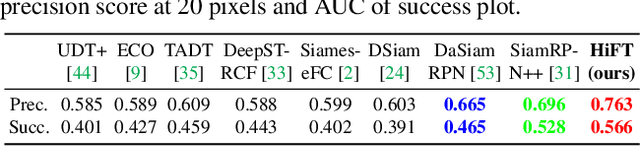
Most existing Siamese-based tracking methods execute the classification and regression of the target object based on the similarity maps. However, they either employ a single map from the last convolutional layer which degrades the localization accuracy in complex scenarios or separately use multiple maps for decision making, introducing intractable computations for aerial mobile platforms. Thus, in this work, we propose an efficient and effective hierarchical feature transformer (HiFT) for aerial tracking. Hierarchical similarity maps generated by multi-level convolutional layers are fed into the feature transformer to achieve the interactive fusion of spatial (shallow layers) and semantics cues (deep layers). Consequently, not only the global contextual information can be raised, facilitating the target search, but also our end-to-end architecture with the transformer can efficiently learn the interdependencies among multi-level features, thereby discovering a tracking-tailored feature space with strong discriminability. Comprehensive evaluations on four aerial benchmarks have proven the effectiveness of HiFT. Real-world tests on the aerial platform have strongly validated its practicability with a real-time speed. Our code is available at https://github.com/vision4robotics/HiFT.
NPBDREG: A Non-parametric Bayesian Deep-Learning Based Approach for Diffeomorphic Brain MRI Registration
Aug 29, 2021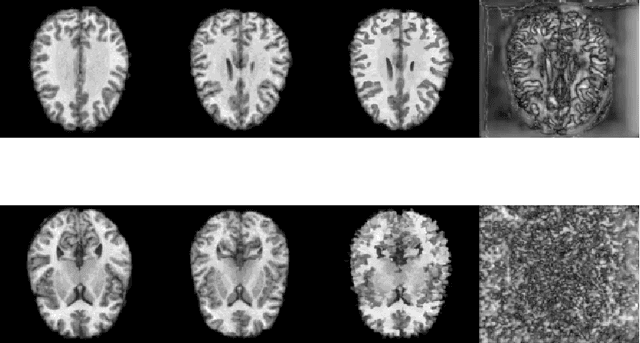
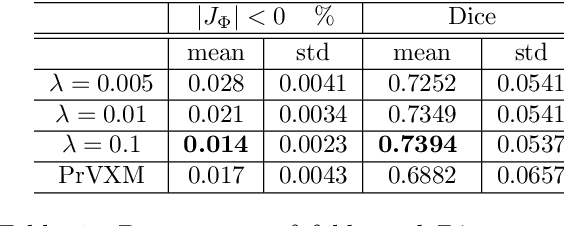
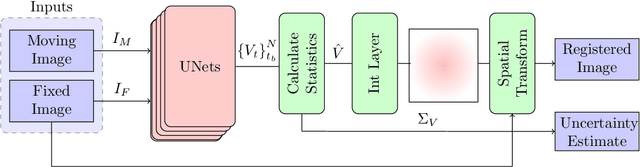

Quantification of uncertainty in deep-neural-networks (DNN) based image registration algorithms plays an important role in the safe deployment of real-world medical applications and research-oriented processing pipelines, and in improving generalization capabilities. Currently available approaches for uncertainty estimation, including the variational encoder-decoder architecture and the inference-time dropout approach, require specific network architectures and assume parametric distribution of the latent space which may result in sub-optimal characterization of the posterior distribution for the predicted deformation-fields. We introduce the NPBDREG, a fully non-parametric Bayesian framework for unsupervised DNN-based deformable image registration by combining an \texttt{Adam} optimizer with stochastic gradient Langevin dynamics (SGLD) to characterize the true posterior distribution through posterior sampling. The NPBDREG provides a principled non-parametric way to characterize the true posterior distribution, thus providing improved uncertainty estimates and confidence measures in a theoretically well-founded and computationally efficient way. We demonstrated the added-value of NPBDREG, compared to the baseline probabilistic \texttt{VoxelMorph} unsupervised model (PrVXM), on brain MRI images registration using $390$ image pairs from four publicly available databases: MGH10, CMUC12, ISBR18 and LPBA40. The NPBDREG shows a slight improvement in the registration accuracy compared to PrVXM (Dice score of $0.73$ vs. $0.68$, $p \ll 0.01$), a better generalization capability for data corrupted by a mixed structure noise (e.g Dice score of $0.729$ vs. $0.686$ for $\alpha=0.2$) and last but foremost, a significantly better correlation of the predicted uncertainty with out-of-distribution data ($r>0.95$ vs. $r<0.5$).