 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Single and Multiple Representations in Dense Passage Retrieval
Paper and Code

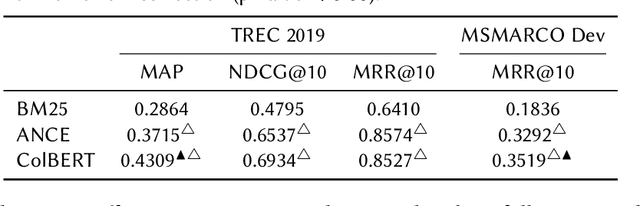
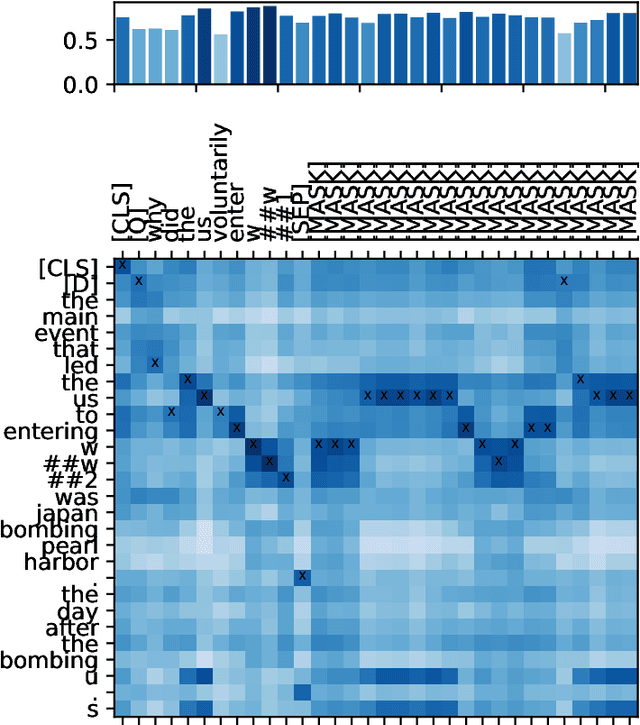
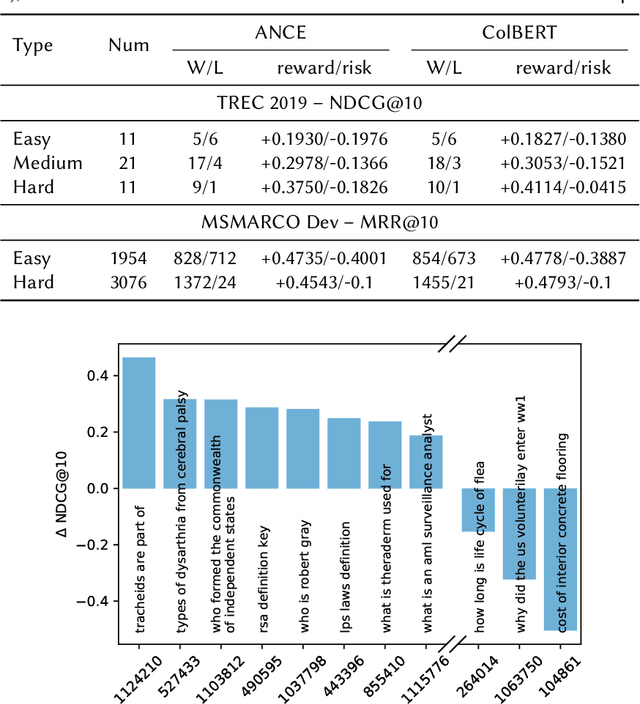
The advent of contextualised language models has brought gains in search effectiveness, not just when applied for re-ranking the output of classical weighting models such as BM25, but also when used directly for passage indexing and retrieval, a technique which is called dense retrieval. In the existing literature in neural ranking, two dense retrieval families have become apparent: single representation, where entire passages are represented by a single embedding (usually BERT's [CLS] token, as exemplified by the recent ANCE approach), or multiple representations, where each token in a passage is represented by its own embedding (as exemplified by the recent ColBERT approach). These two families have not been directly compared. However, because of the likely importance of dense retrieval moving forward, a clear understanding of their advantages and disadvantages is paramount. To this end, this paper contributes a direct study on their comparative effectiveness, noting situations where each method under/over performs w.r.t. each other, and w.r.t. a BM25 baseline. We observe that, while ANCE is more efficient than ColBERT in terms of response time and memory usage, multiple representations are statistically more effective than the single representations for MAP and MRR@10. We also show that multiple representations obtain better improvements than single representations for queries that are the hardest for BM25, as well as for definitional queries, and those with complex information needs.