 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deformable Image Registration using Neural ODEs
Aug 07, 2021




Deformable image registration, aiming to find spatial correspondence between a given image pair, is one of the most critical problems in the domain of medical image analysis. In this paper, we present a generic, fast, and accurate diffeomorphic image registration framework that leverages neural ordinary differential equations (NODEs). We model each voxel as a moving particle and consider the set of all voxels in a 3D image as a high-dimensional dynamical system whose trajectory determines the targeted deformation field. Compared with traditional optimization-based methods, our framework reduces the running time from tens of minutes to tens of seconds. Compared with recent data-driven deep learning methods, our framework is more accessible since it does not require large amounts of training data. Our experiments show that the registration results of our method outperform state-of-the-arts under various metrics, indicating that our modeling approach is well fitted for the task of deformable image registration.
DISCO : efficient unsupervised decoding for discrete natural language problems via convex relaxation
Jul 07, 2021
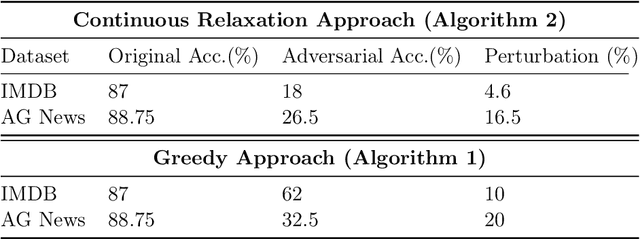
In this paper we study test time decoding; an ubiquitous step in almost all sequential text generation task spanning across a wide array of natural language processing (NLP) problems. Our main contribution is to develop a continuous relaxation framework for the combinatorial NP-hard decoding problem and propose Disco - an efficient algorithm based on standard first order gradient based. We provide tight analysis and show that our proposed algorithm linearly converges to within $\epsilon$ neighborhood of the optima. Finally, we perform preliminary experiments on the task of adversarial text generation and show superior performance of Disco over several popular decoding approaches.
Amortized Neural Networks for Low-Latency Speech Recognition
Aug 03, 2021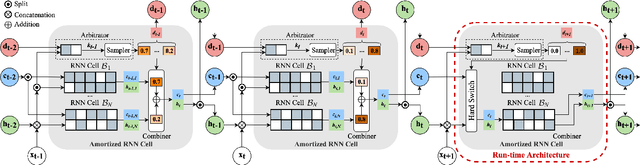
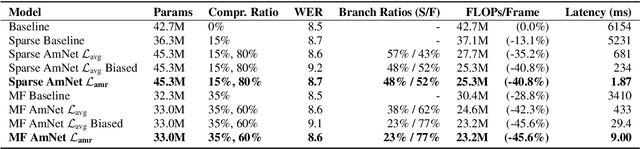
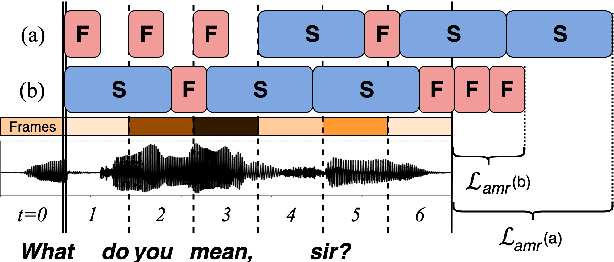
We introduce Amortized Neural Networks (AmNets), a compute cost- and latency-aware network architecture particularly well-suited for sequence modeling tasks. We apply AmNets to the Recurrent Neural Network Transducer (RNN-T) to reduce compute cost and latency for an automatic speech recognition (ASR) task. The AmNets RNN-T architecture enables the network to dynamically switch between encoder branches on a frame-by-frame basis. Branches are constructed with variable levels of compute cost and model capacity. Here, we achieve variable compute for two well-known candidate techniques: one using sparse pruning and the other using matrix factorization. Frame-by-frame switching is determined by an arbitrator network that requires negligible compute overhead. We present results using both architectures on LibriSpeech data and show that our proposed architecture can reduce inference cost by up to 45\% and latency to nearly real-time without incurring a loss in accuracy.
Accelerating Neural Network Training with Distributed Asynchronous and Selective Optimization (DASO)
Apr 15, 2021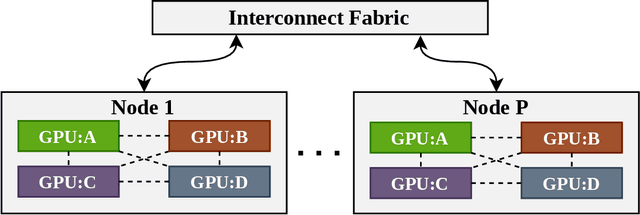
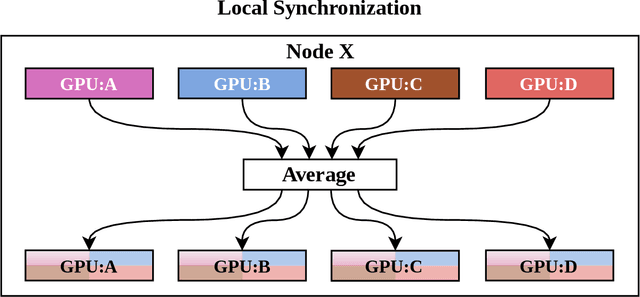

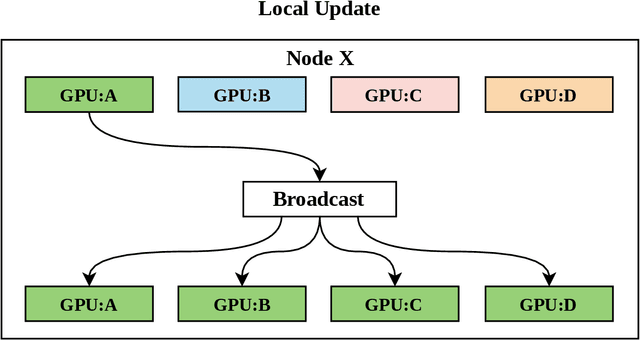
With increasing data and model complexities, the time required to train neural networks has become prohibitively large. To address the exponential rise in training time, users are turning to data parallel neural networks (DPNN) to utilize large-scale distributed resources on computer clusters. Current DPNN approaches implement the network parameter updates by synchronizing and averaging gradients across all processes with blocking communication operations. This synchronization is the central algorithmic bottleneck. To combat this, we introduce the Distributed Asynchronous and Selective Optimization (DASO) method which leverages multi-GPU compute node architectures to accelerate network training. DASO uses a hierarchical and asynchronous communication scheme comprised of node-local and global networks while adjusting the global synchronization rate during the learning process. We show that DASO yields a reduction in training time of up to 34% on classical and state-of-the-art networks, as compared to other existing data parallel training methods.
Personalized Federated Learning over non-IID Data for Indoor Localization
Jul 21, 2021
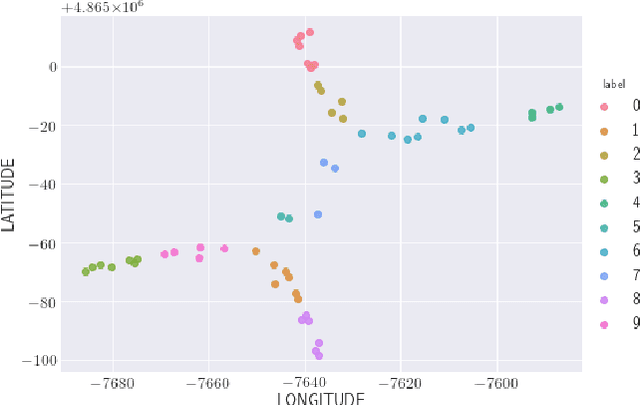
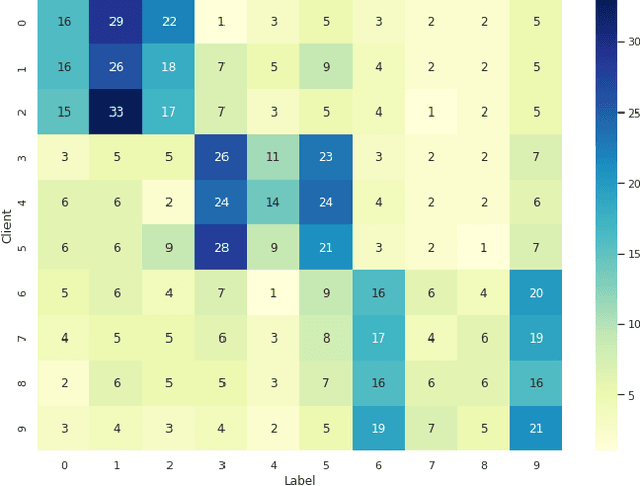
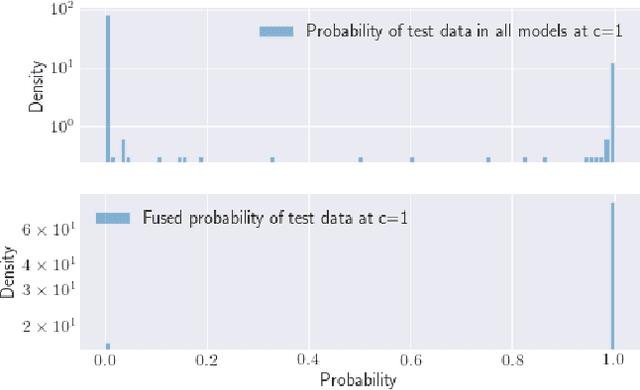
Localization and tracking of objects using data-driven methods is a popular topic due to the complexity in characterizing the physics of wireless channel propagation models. In these modeling approaches, data needs to be gathered to accurately train models, at the same time that user's privacy is maintained. An appealing scheme to cooperatively achieve these goals is known as Federated Learning (FL). A challenge in FL schemes is the presence of non-independent and identically distributed (non-IID) data, caused by unevenly exploration of different areas. In this paper, we consider the use of recent FL schemes to train a set of personalized models that are then optimally fused through Bayesian rules, which makes it appropriate in the context of indoor localization.
Weakly Supervised Continual Learning
Aug 14, 2021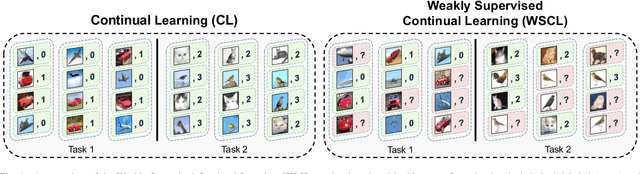
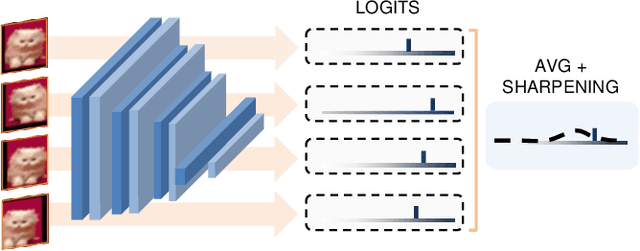
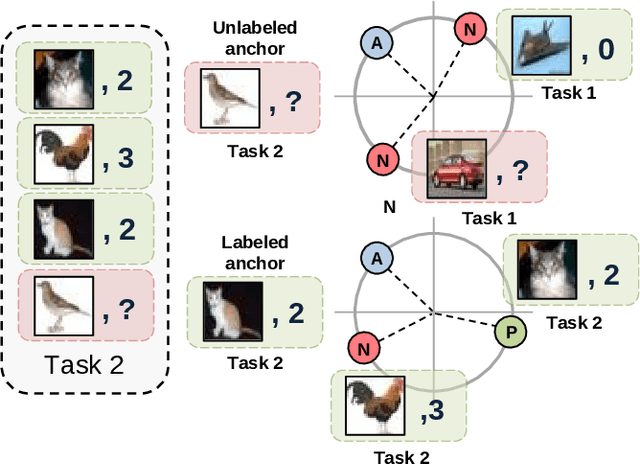
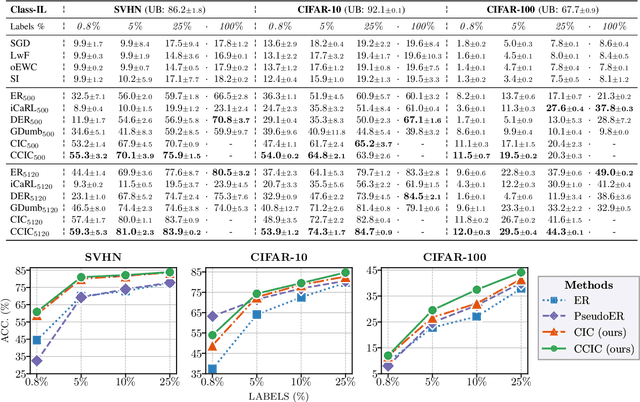
Continual Learning (CL) investigates how to train Deep Networks on a stream of tasks without incurring catastrophic forgetting. CL settings proposed in the literature assume that every incoming example is paired with ground-truth annotations. However, this clashes with many real-world applications: gathering labeled data, which is in itself tedious and expensive, becomes indeed infeasible when data flow as a stream and must be consumed in real-time. This work explores Weakly Supervised Continual Learning (WSCL): here, only a small fraction of labeled input examples are shown to the learner. We assess how current CL methods (e.g.: EWC, LwF, iCaRL, ER, GDumb, DER) perform in this novel and challenging scenario, in which overfitting entangles forgetting. Subsequently, we design two novel WSCL methods which exploit metric learning and consistency regularization to leverage unsupervised data while learning. In doing so, we show that not only our proposals exhibit higher flexibility when supervised information is scarce, but also that less than 25% labels can be enough to reach or even outperform SOTA methods trained under full supervision.
Predicting Power Electronics Device Reliability under Extreme Conditions with Machine Learning Algorithms
Jul 21, 2021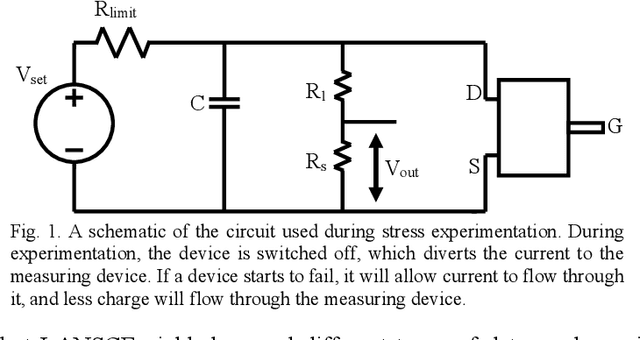
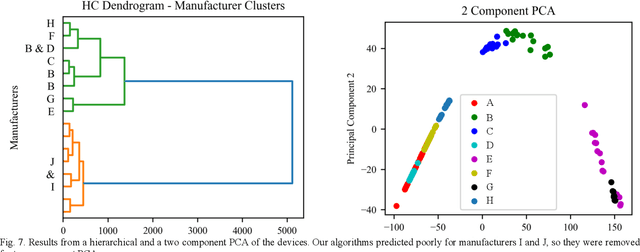
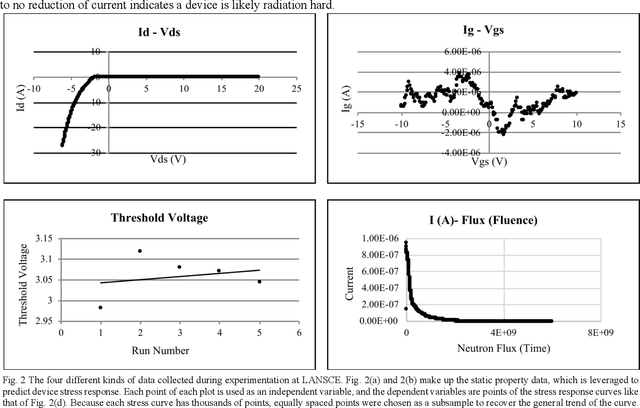
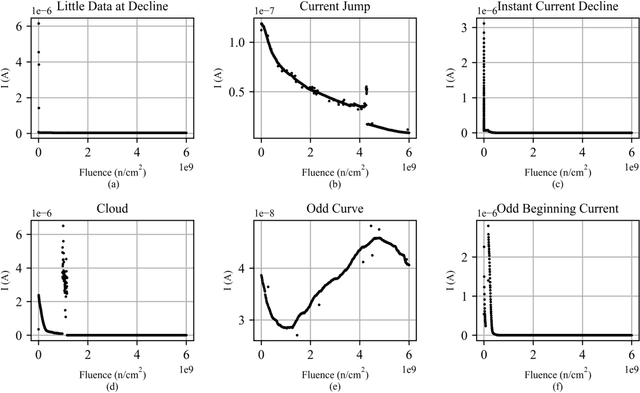
Power device reliability is a major concern during operation under extreme environments, as doing so reduces the operational lifetime of any power system or sensing infrastructure. Due to a potential for system failure, devices must be experimentally validated before implementation, which is expensive and time-consuming. In this paper, we have utilized machine learning algorithms to predict device reliability, significantly reducing the need for conducting experiments. To train the models, we have tested 224 power devices from 10 different manufacturers. First, we describe a method to process the data for modeling purposes. Based on the in-house testing data, we implemented various ML models and observed that computational models such as Gradient Boosting and LSTM encoder-decoder networks can predict power device failure with high accuracy.
Efficient Algorithms for Learning Depth-2 Neural Networks with General ReLU Activations
Jul 21, 2021We present polynomial time and sample efficient algorithms for learning an unknown depth-2 feedforward neural network with general ReLU activations, under mild non-degeneracy assumptions. In particular, we consider learning an unknown network of the form $f(x) = {a}^{\mathsf{T}}\sigma({W}^\mathsf{T}x+b)$, where $x$ is drawn from the Gaussian distribution, and $\sigma(t) := \max(t,0)$ is the ReLU activation. Prior works for learning networks with ReLU activations assume that the bias $b$ is zero. In order to deal with the presence of the bias terms, our proposed algorithm consists of robustly decomposing multiple higher order tensors arising from the Hermite expansion of the function $f(x)$. Using these ideas we also establish identifiability of the network parameters under minimal assumptions.
Faster Learning by Reduction of Data Access Time
Jul 25, 2018
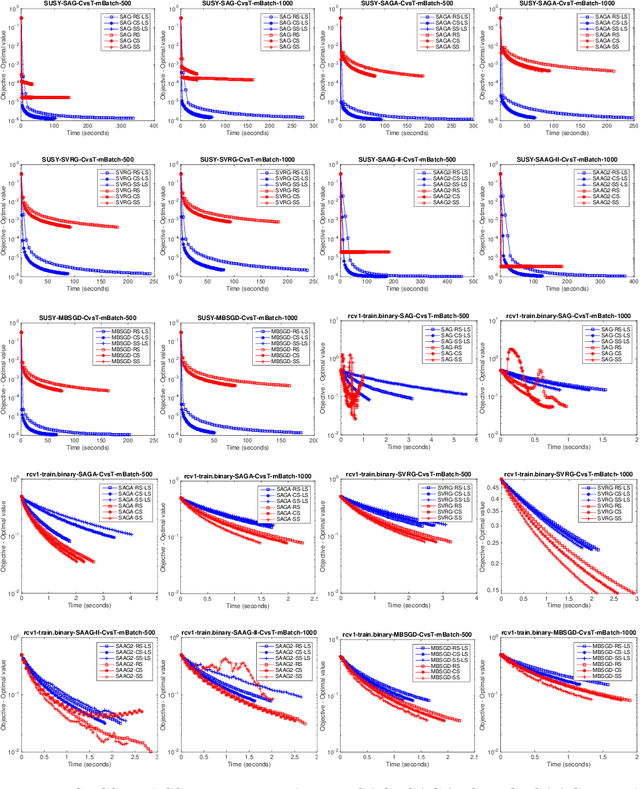
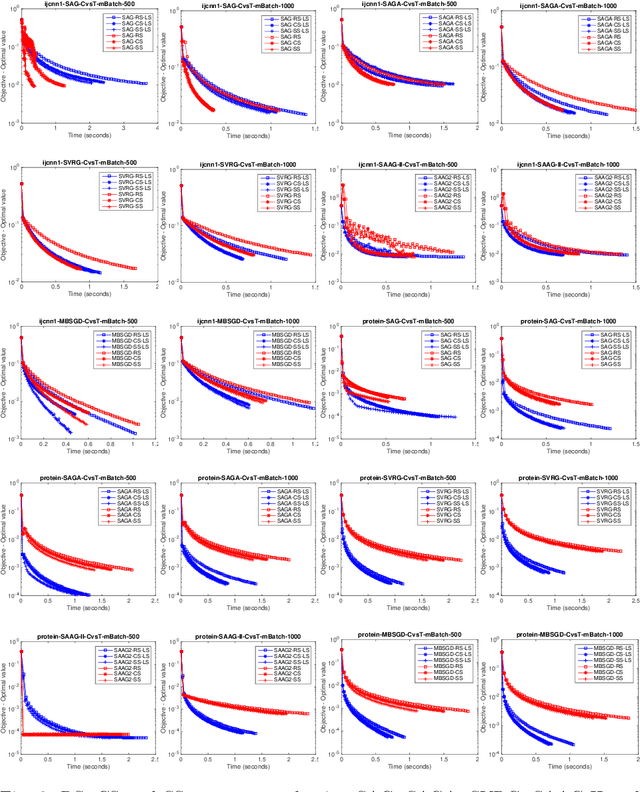
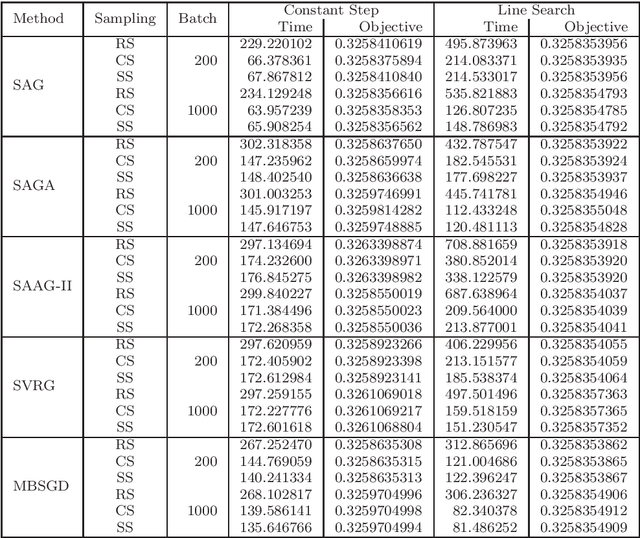
Nowadays, the major challenge in machine learning is the Big Data challenge. The big data problems due to large number of data points or large number of features in each data point, or both, the training of models have become very slow. The training time has two major components: Time to access the data and time to process (learn from) the data. So far, the research has focused only on the second part, i.e., learning from the data. In this paper, we have proposed one possible solution to handle the big data problems in machine learning. The idea is to reduce the training time through reducing data access time by proposing systematic sampling and cyclic/sequential sampling to select mini-batches from the dataset. To prove the effectiveness of proposed sampling techniques, we have used Empirical Risk Minimization, which is commonly used machine learning problem, for strongly convex and smooth case. The problem has been solved using SAG, SAGA, SVRG, SAAG-II and MBSGD (Mini-batched SGD), each using two step determination techniques, namely, constant step size and backtracking line search method. Theoretical results prove the same convergence for systematic sampling, cyclic sampling and the widely used random sampling technique, in expectation. Experimental results with bench marked datasets prove the efficacy of the proposed sampling techniques and show up to six times faster training.
* 80 figures, final journal version
Point Cloud Pre-training by Mixing and Disentangling
Sep 16, 2021
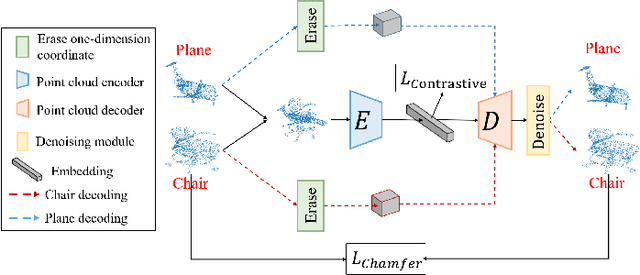
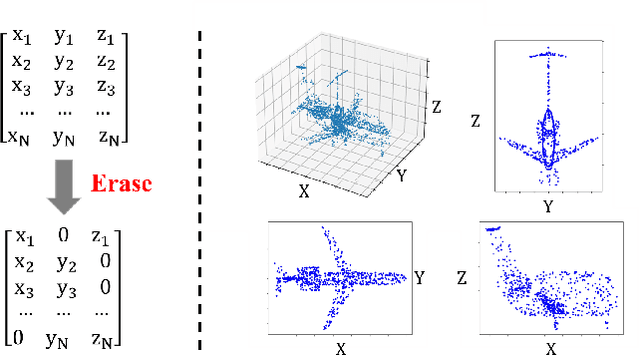
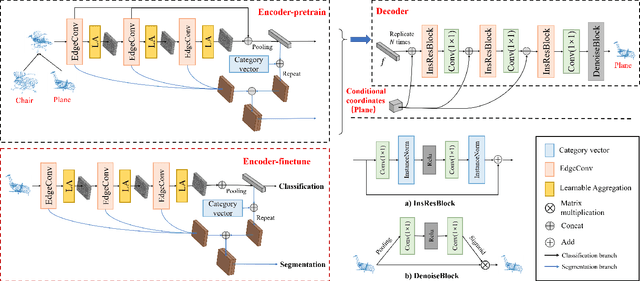
The annotation for large-scale point clouds is still time-consuming and unavailable for many real-world tasks. Point cloud pre-training is one potential solution for obtaining a scalable model for fast adaptation. Therefore, in this paper, we investigate a new self-supervised learning approach, called Mixing and Disentangling (MD), for point cloud pre-training. As the name implies, we explore how to separate the original point cloud from the mixed point cloud, and leverage this challenging task as a pretext optimization objective for model training. Considering the limited training data in the original dataset, which is much less than prevailing ImageNet, the mixing process can efficiently generate more high-quality samples. We build one baseline network to verify our intuition, which simply contains two modules, encoder and decoder. Given a mixed point cloud, the encoder is first pre-trained to extract the semantic embedding. Then an instance-adaptive decoder is harnessed to disentangle the point clouds according to the embedding. Albeit simple, the encoder is inherently able to capture the point cloud keypoints after training and can be fast adapted to downstream tasks including classification and segmentation by the pre-training and fine-tuning paradigm. Extensive experiments on two datasets show that the encoder + ours (MD) significantly surpasses that of the encoder trained from scratch and converges quickly. In ablation studies, we further study the effect of each component and discuss the advantages of the proposed self-supervised learning strategy. We hope this self-supervised learning attempt on point clouds can pave the way for reducing the deeply-learned model dependence on large-scale labeled data and saving a lot of annotation costs in the future.