 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataless Weight Disentanglement in Task Arithmetic via Kronecker-Factored Approximate Curvature
Feb 19, 2026Task Arithmetic yields a modular, scalable way to adapt foundation models. Combining multiple task vectors, however, can lead to cross-task interference, causing representation drift and degraded performance. Representation drift regularization provides a natural remedy to disentangle task vectors; however, existing approaches typically require external task data, conflicting with modularity and data availability constraints (e.g., privacy requirements). We propose a dataless approach by framing regularization against representation drift as a curvature matrix approximation problem. This allows us to leverage well-established techniques; in particular, we adopt Kronecker-Factored Approximate Curvature and obtain a practical regularizer that achieves state-of-the-art results in task addition and negation. Our method has constant complexity in the number of tasks and promotes robustness to task vector rescaling, eliminating the need for held-out tuning.
Intrinsic Training Signals for Federated Learning Aggregation
Jul 09, 2025Federated Learning (FL) enables collaborative model training across distributed clients while preserving data privacy. While existing approaches for aggregating client-specific classification heads and adapted backbone parameters require architectural modifications or loss function changes, our method uniquely leverages intrinsic training signals already available during standard optimization. We present LIVAR (Layer Importance and VARiance-based merging), which introduces: i) a variance-weighted classifier aggregation scheme using naturally emergent feature statistics, and ii) an explainability-driven LoRA merging technique based on SHAP analysis of existing update parameter patterns. Without any architectural overhead, LIVAR achieves state-of-the-art performance on multiple benchmarks while maintaining seamless integration with existing FL methods. This work demonstrates that effective model merging can be achieved solely through existing training signals, establishing a new paradigm for efficient federated model aggregation. The code will be made publicly available upon acceptance.
Closed-form merging of parameter-efficient modules for Federated Continual Learning
Oct 23, 2024



Model merging has emerged as a crucial technique in Deep Learning, enabling the integration of multiple models into a unified system while preserving performance and scalability. In this respect, the compositional properties of low-rank adaptation techniques (e.g., LoRA) have proven beneficial, as simple averaging LoRA modules yields a single model that mostly integrates the capabilities of all individual modules. Building on LoRA, we take a step further by imposing that the merged model matches the responses of all learned modules. Solving this objective in closed form yields an indeterminate system with A and B as unknown variables, indicating the existence of infinitely many closed-form solutions. To address this challenge, we introduce LoRM, an alternating optimization strategy that trains one LoRA matrix at a time. This allows solving for each unknown variable individually, thus finding a unique solution. We apply our proposed methodology to Federated Class-Incremental Learning (FCIL), ensuring alignment of model responses both between clients and across tasks. Our method demonstrates state-of-the-art performance across a range of FCIL scenarios.
CLIP with Generative Latent Replay: a Strong Baseline for Incremental Learning
Jul 22, 2024



With the emergence of Transformers and Vision-Language Models (VLMs) such as CLIP, large pre-trained models have become a common strategy to enhance performance in Continual Learning scenarios. This led to the development of numerous prompting strategies to effectively fine-tune transformer-based models without succumbing to catastrophic forgetting. However, these methods struggle to specialize the model on domains significantly deviating from the pre-training and preserving its zero-shot capabilities. In this work, we propose Continual Generative training for Incremental prompt-Learning, a novel approach to mitigate forgetting while adapting a VLM, which exploits generative replay to align prompts to tasks. We also introduce a new metric to evaluate zero-shot capabilities within CL benchmarks. Through extensive experiments on different domains, we demonstrate the effectiveness of our framework in adapting to new tasks while improving zero-shot capabilities. Further analysis reveals that our approach can bridge the gap with joint prompt tuning. The codebase is available at https://github.com/aimagelab/mammoth.
Reducing Bias in Federated Class-Incremental Learning with Hierarchical Generative Prototypes
Jun 04, 2024Federated Learning (FL) aims at unburdening the training of deep models by distributing computation across multiple devices (clients) while safeguarding data privacy. On top of that, Federated Continual Learning (FCL) also accounts for data distribution evolving over time, mirroring the dynamic nature of real-world environments. In this work, we shed light on the Incremental and Federated biases that naturally emerge in FCL. While the former is a known problem in Continual Learning, stemming from the prioritization of recently introduced classes, the latter (i.e., the bias towards local distributions) remains relatively unexplored. Our proposal constrains both biases in the last layer by efficiently fine-tuning a pre-trained backbone using learnable prompts, resulting in clients that produce less biased representations and more biased classifiers. Therefore, instead of solely relying on parameter aggregation, we also leverage generative prototypes to effectively balance the predictions of the global model. Our method improves on the current State Of The Art, providing an average increase of +7.9% in accuracy.
Trajectory Forecasting through Low-Rank Adaptation of Discrete Latent Codes
May 31, 2024



Trajectory forecasting is crucial for video surveillance analytics, as it enables the anticipation of future movements for a set of agents, e.g. basketball players engaged in intricate interactions with long-term intentions. Deep generative models offer a natural learning approach for trajectory forecasting, yet they encounter difficulties in achieving an optimal balance between sampling fidelity and diversity. We address this challenge by leveraging Vector Quantized Variational Autoencoders (VQ-VAEs), which utilize a discrete latent space to tackle the issue of posterior collapse. Specifically, we introduce an instance-based codebook that allows tailored latent representations for each example. In a nutshell, the rows of the codebook are dynamically adjusted to reflect contextual information (i.e., past motion patterns extracted from the observed trajectories). In this way, the discretization process gains flexibility, leading to improved reconstructions. Notably, instance-level dynamics are injected into the codebook through low-rank updates, which restrict the customization of the codebook to a lower dimension space. The resulting discrete space serves as the basis of the subsequent step, which regards the training of a diffusion-based predictive model. We show that such a two-fold framework, augmented with instance-level discretization, leads to accurate and diverse forecasts, yielding state-of-the-art performance on three established benchmarks.
A Second-Order perspective on Compositionality and Incremental Learning
May 25, 2024



The fine-tuning of deep pre-trained models has recently revealed compositional properties. This enables the arbitrary composition of multiple specialized modules into a single, multi-task model. However, identifying the conditions that promote compositionality remains an open issue, with recent efforts concentrating mainly on linearized networks. We conduct a theoretical study that attempts to demystify compositionality in standard non-linear networks through the second-order Taylor approximation of the loss function. The proposed formulation highlights the importance of staying within the pre-training basin for achieving composable modules. Moreover, it provides the basis for two dual incremental training algorithms: the one from the perspective of multiple models trained individually, while the other aims to optimize the composed model as a whole. We probe their application in incremental classification tasks and highlight some valuable skills. In fact, the pool of incrementally learned modules not only supports the creation of an effective multi-task model but also enables unlearning and specialization in specific tasks.
Class-Incremental Continual Learning into the eXtended DER-verse
Jan 03, 2022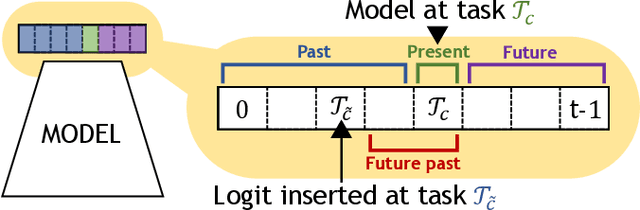
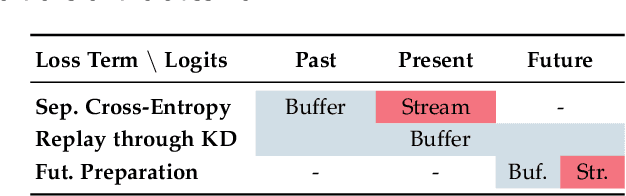

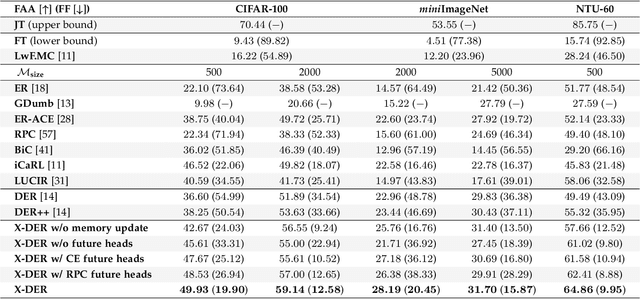
The staple of human intelligence is the capability of acquiring knowledge in a continuous fashion. In stark contrast, Deep Networks forget catastrophically and, for this reason, the sub-field of Class-Incremental Continual Learning fosters methods that learn a sequence of tasks incrementally, blending sequentially-gained knowledge into a comprehensive prediction. This work aims at assessing and overcoming the pitfalls of our previous proposal Dark Experience Replay (DER), a simple and effective approach that combines rehearsal and Knowledge Distillation. Inspired by the way our minds constantly rewrite past recollections and set expectations for the future, we endow our model with the abilities to i) revise its replay memory to welcome novel information regarding past data ii) pave the way for learning yet unseen classes. We show that the application of these strategies leads to remarkable improvements; indeed, the resulting method - termed eXtended-DER (X-DER) - outperforms the state of the art on both standard benchmarks (such as CIFAR-100 and miniImagenet) and a novel one here introduced. To gain a better understanding, we further provide extensive ablation studies that corroborate and extend the findings of our previous research (e.g. the value of Knowledge Distillation and flatter minima in continual learning setups).
Weakly Supervised Continual Learning
Aug 14, 2021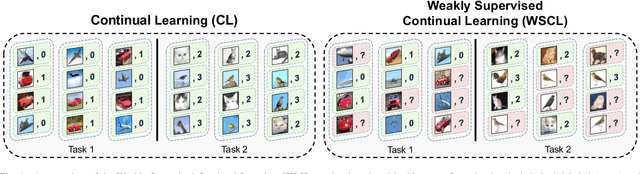
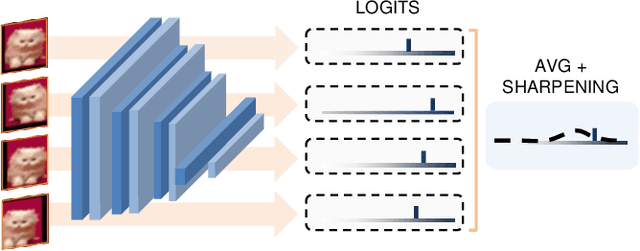
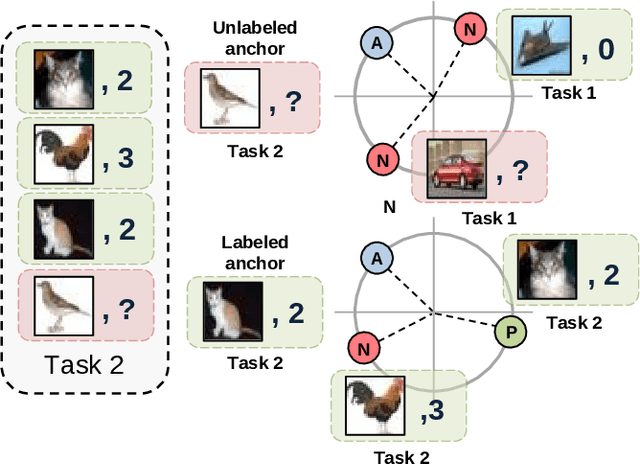
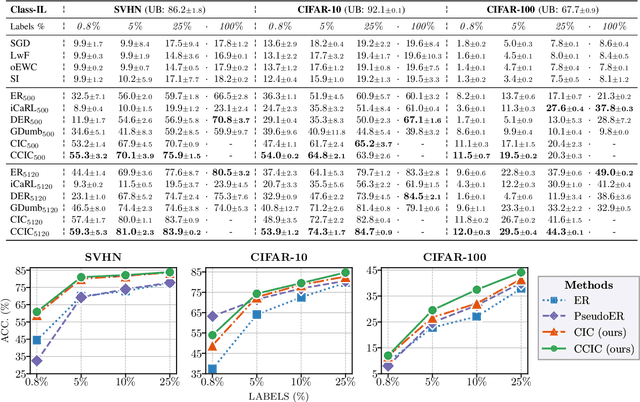
Continual Learning (CL) investigates how to train Deep Networks on a stream of tasks without incurring catastrophic forgetting. CL settings proposed in the literature assume that every incoming example is paired with ground-truth annotations. However, this clashes with many real-world applications: gathering labeled data, which is in itself tedious and expensive, becomes indeed infeasible when data flow as a stream and must be consumed in real-time. This work explores Weakly Supervised Continual Learning (WSCL): here, only a small fraction of labeled input examples are shown to the learner. We assess how current CL methods (e.g.: EWC, LwF, iCaRL, ER, GDumb, DER) perform in this novel and challenging scenario, in which overfitting entangles forgetting. Subsequently, we design two novel WSCL methods which exploit metric learning and consistency regularization to leverage unsupervised data while learning. In doing so, we show that not only our proposals exhibit higher flexibility when supervised information is scarce, but also that less than 25% labels can be enough to reach or even outperform SOTA methods trained under full supervision.
Rethinking Experience Replay: a Bag of Tricks for Continual Learning
Oct 12, 2020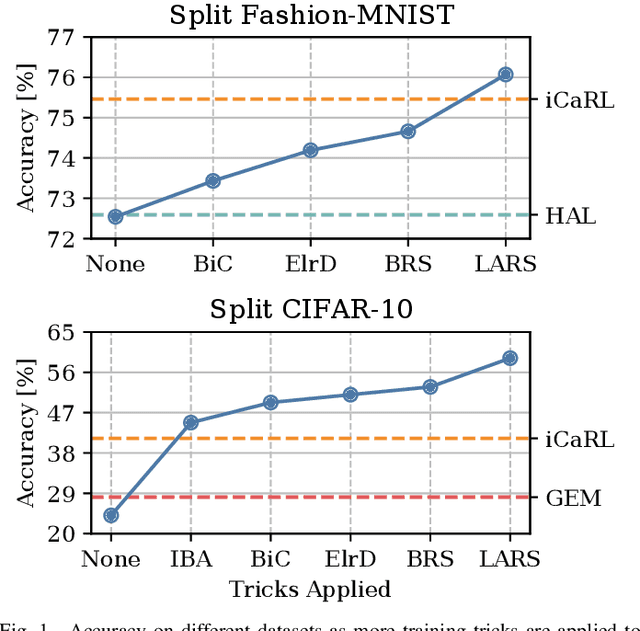
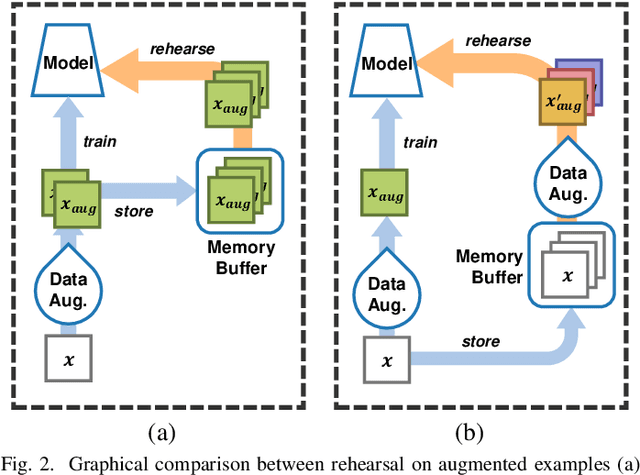

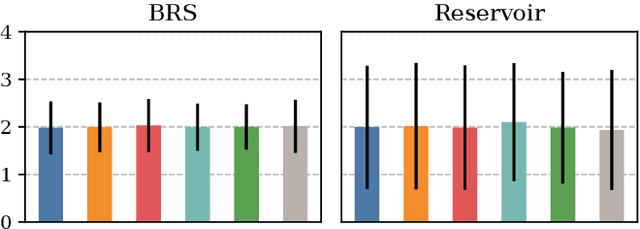
In Continual Learning, a Neural Network is trained on a stream of data whose distribution shifts over time. Under these assumptions, it is especially challenging to improve on classes appearing later in the stream while remaining accurate on previous ones. This is due to the infamous problem of catastrophic forgetting, which causes a quick performance degradation when the classifier focuses on learning new categories. Recent literature proposed various approaches to tackle this issue, often resorting to very sophisticated techniques. In this work, we show that naive rehearsal can be patched to achieve similar performance. We point out some shortcomings that restrain Experience Replay (ER) and propose five tricks to mitigate them. Experiments show that ER, thus enhanced, displays an accuracy gain of 51.2 and 26.9 percentage points on the CIFAR-10 and CIFAR-100 datasets respectively (memory buffer size 1000). As a result, it surpasses current state-of-the-art rehearsal-based methods.