 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
User-Centric Semi-Automated Infographics Authoring and Recommendation
Aug 27, 2021



Designing infographics can be a tedious process for non-experts and time-consuming even for professional designers. Based on the literature and a formative study, we propose a flexible framework for automated and semi-automated infographics design. This framework captures the main design components in infographics and streamlines the generation workflow into three steps, allowing users to control and optimize each aspect independently. Based on the framework, we also propose an interactive tool, \name{}, for assisting novice designers with creating high-quality infographics from an input in a markdown format by offering recommendations of different design components of infographics. Simultaneously, more experienced designers can provide custom designs and layout ideas to the tool using a canvas to control the automated generation process partially. As part of our work, we also contribute an individual visual group (VG) and connection designs dataset (in SVG), along with a 1k complete infographic image dataset with segmented VGs. This dataset plays a crucial role in diversifying the infographic designs created by our framework. We evaluate our approach with a comparison against similar tools, a user study with novice and expert designers, and a case study. Results confirm that our framework and \name{} excel in creating customized infographics and exploring a large variety of designs.
Learning stochastic decision trees
May 08, 2021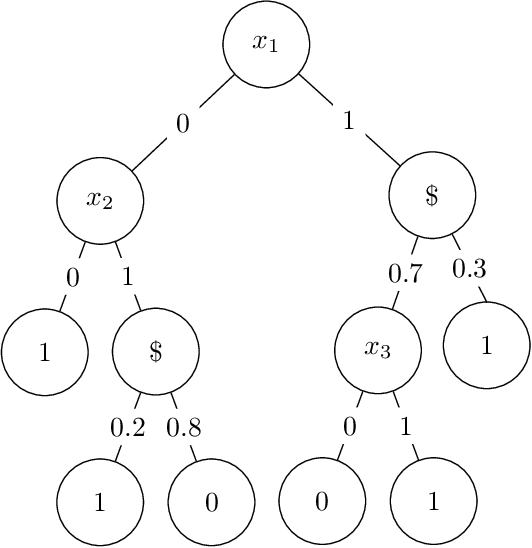
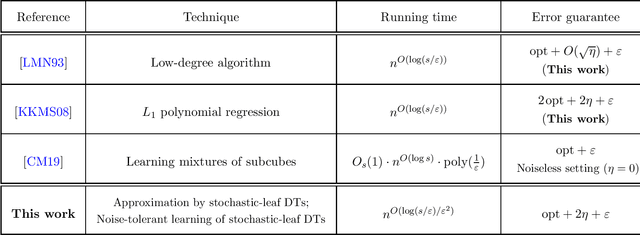

We give a quasipolynomial-time algorithm for learning stochastic decision trees that is optimally resilient to adversarial noise. Given an $\eta$-corrupted set of uniform random samples labeled by a size-$s$ stochastic decision tree, our algorithm runs in time $n^{O(\log(s/\varepsilon)/\varepsilon^2)}$ and returns a hypothesis with error within an additive $2\eta + \varepsilon$ of the Bayes optimal. An additive $2\eta$ is the information-theoretic minimum. Previously no non-trivial algorithm with a guarantee of $O(\eta) + \varepsilon$ was known, even for weaker noise models. Our algorithm is furthermore proper, returning a hypothesis that is itself a decision tree; previously no such algorithm was known even in the noiseless setting.
Best Axes Composition: Multiple Gyroscopes IMU Sensor Fusion to Reduce Systematic Error
Jul 22, 2021
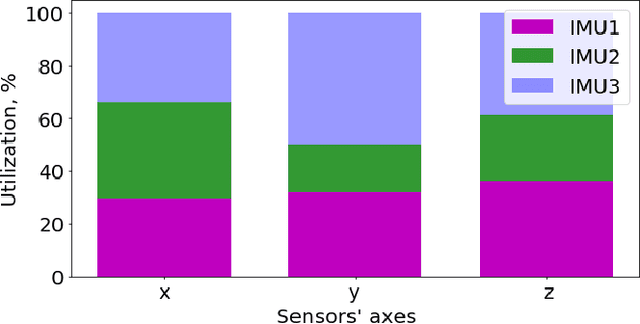
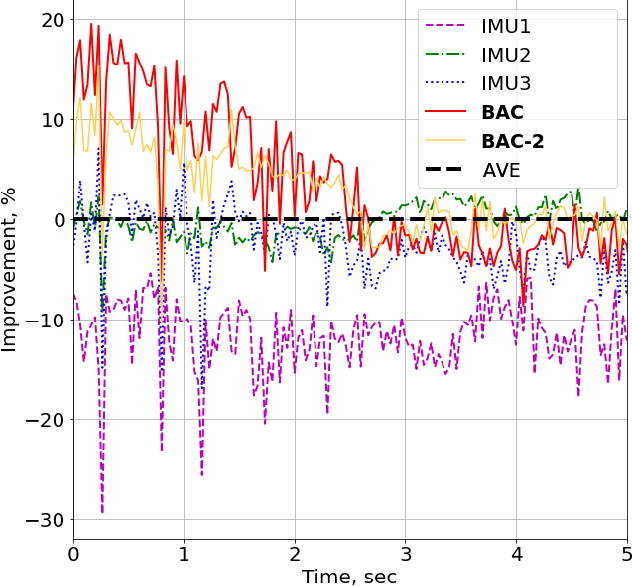
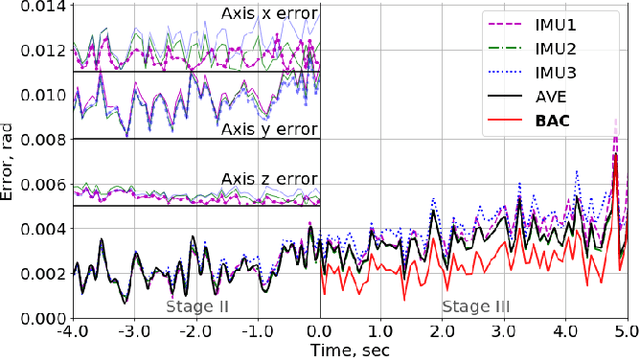
In this paper, we propose an algorithm to combine multiple cheap Inertial Measurement Unit (IMU) sensors to calculate 3D-orientations accurately. Our approach takes into account the inherent and non-negligible systematic error in the gyroscope model and provides a solution based on the error observed during previous instants of time. Our algorithm, the Best Axes Composition (BAC), chooses dynamically the most fitted axes among IMUs to improve the estimation performance. We compare our approach with a probabilistic Multiple IMU (MIMU) approach, and we validate our algorithm in our collected dataset. As a result, it only takes as few as 2 IMUs to significantly improve accuracy, while other MIMU approaches need a higher number of sensors to achieve the same results.
Systematic Clinical Evaluation of A Deep Learning Method for Medical Image Segmentation: Radiosurgery Application
Aug 21, 2021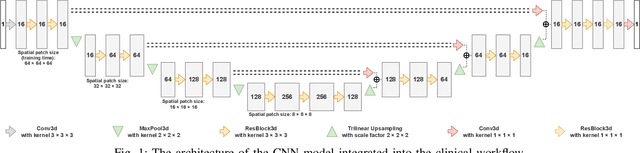
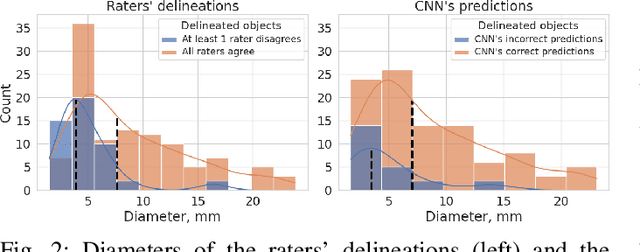
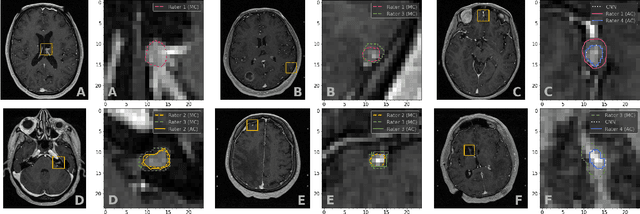
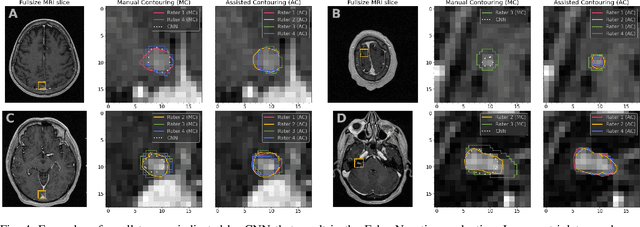
We systematically evaluate a Deep Learning (DL) method in a 3D medical image segmentation task. Our segmentation method is integrated into the radiosurgery treatment process and directly impacts the clinical workflow. With our method, we address the relative drawbacks of manual segmentation: high inter-rater contouring variability and high time consumption of the contouring process. The main extension over the existing evaluations is the careful and detailed analysis that could be further generalized on other medical image segmentation tasks. Firstly, we analyze the changes in the inter-rater detection agreement. We show that the segmentation model reduces the ratio of detection disagreements from 0.162 to 0.085 (p < 0.05). Secondly, we show that the model improves the inter-rater contouring agreement from 0.845 to 0.871 surface Dice Score (p < 0.05). Thirdly, we show that the model accelerates the delineation process in between 1.6 and 2.0 times (p < 0.05). Finally, we design the setup of the clinical experiment to either exclude or estimate the evaluation biases, thus preserve the significance of the results. Besides the clinical evaluation, we also summarize the intuitions and practical ideas for building an efficient DL-based model for 3D medical image segmentation.
A Technical Survey and Evaluation of Traditional Point Cloud Clustering Methods for LiDAR Panoptic Segmentation
Aug 21, 2021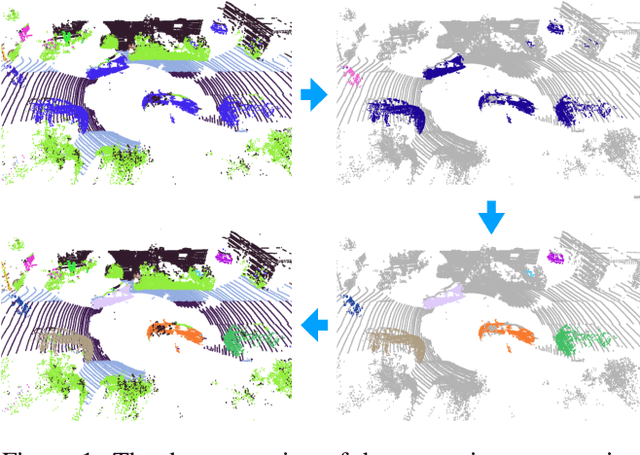
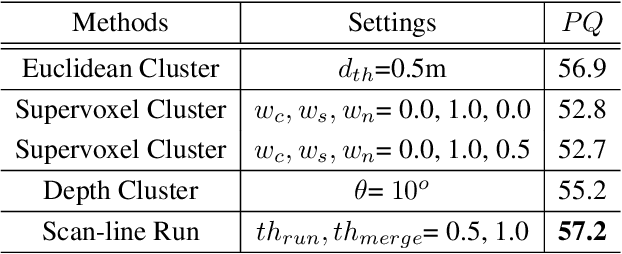
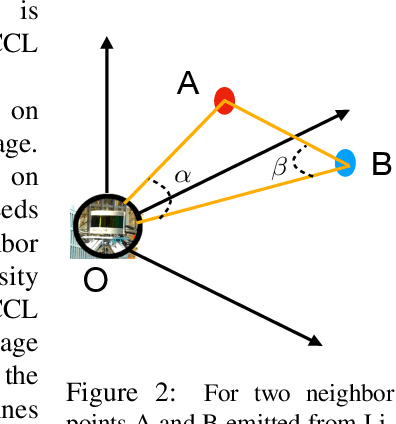
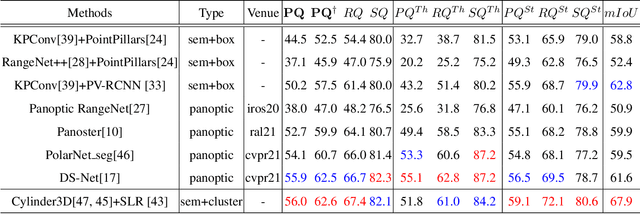
LiDAR panoptic segmentation is a newly proposed technical task for autonomous driving. In contrast to popular end-to-end deep learning solutions, we propose a hybrid method with an existing semantic segmentation network to extract semantic information and a traditional LiDAR point cloud cluster algorithm to split each instance object. We argue geometry-based traditional clustering algorithms are worth being considered by showing a state-of-the-art performance among all published end-to-end deep learning solutions on the panoptic segmentation leaderboard of the SemanticKITTI dataset. To our best knowledge, we are the first to attempt the point cloud panoptic segmentation with clustering algorithms. Therefore, instead of working on new models, we give a comprehensive technical survey in this paper by implementing four typical cluster methods and report their performances on the benchmark. Those four cluster methods are the most representative ones with real-time running speed. They are implemented with C++ in this paper and then wrapped as a python function for seamless integration with the existing deep learning frameworks. We release our code for peer researchers who might be interested in this problem.
Short-term forecast of EV charging stations occupancy probability using big data streaming analysis
Apr 26, 2021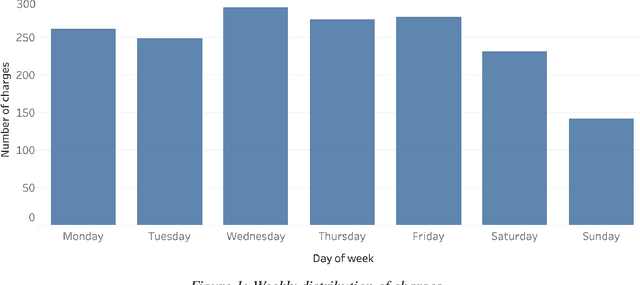
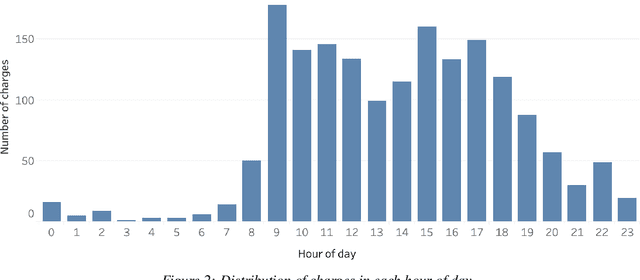
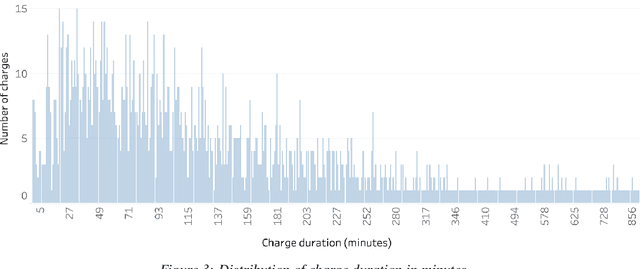
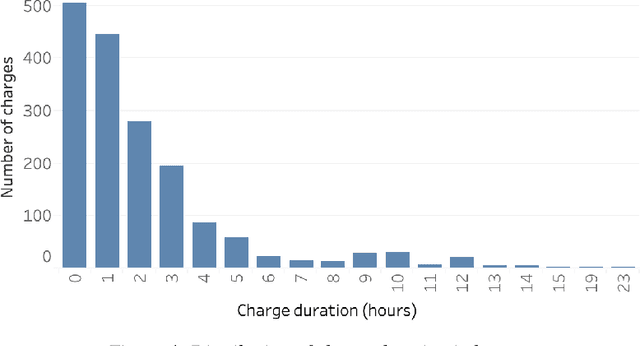
The widespread diffusion of electric mobility requires a contextual expansion of the charging infrastructure. An extended collection and processing of information regarding charging of electric vehicles may turn each electric vehicle charging station into a valuable source of streaming data. Charging point operators may profit from all these data for optimizing their operation and planning activities. In such a scenario, big data and machine learning techniques would allow valorizing real-time data coming from electric vehicle charging stations. This paper presents an architecture able to deal with data streams from a charging infrastructure, with the final aim to forecast electric charging station availability after a set amount of minutes from present time. Both batch data regarding past charges and real-time data streams are used to train a streaming logistic regression model, to take into account recurrent past situations and unexpected actual events. The streaming model performs better than a model trained only using historical data. The results highlight the importance of constantly updating the predictive model parameters in order to adapt to changing conditions and always provide accurate forecasts.
Complex Spectral Mapping With Attention Based Convolution Recrrent Neural Network for Speech Enhancement
Apr 12, 2021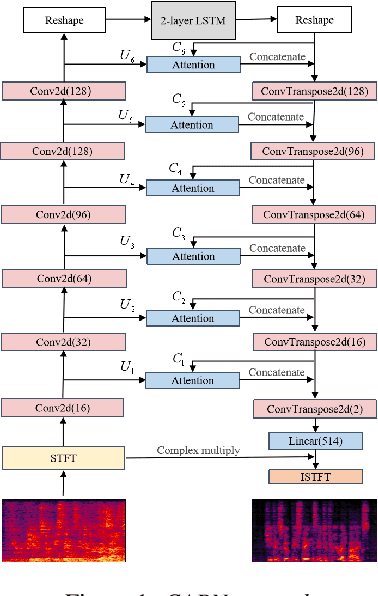
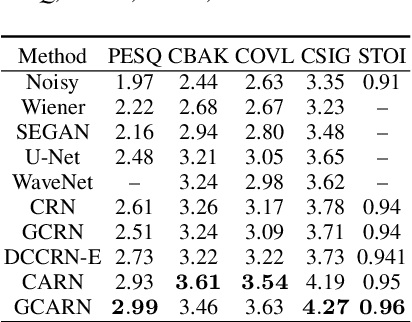
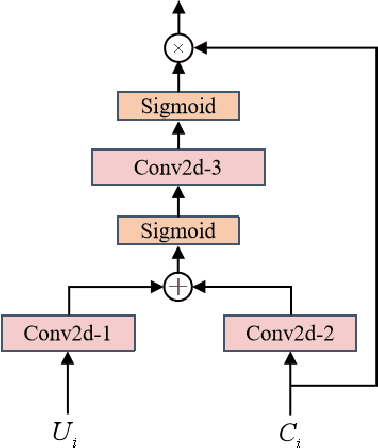
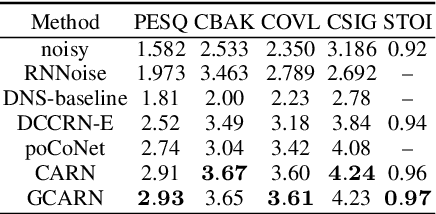
Speech enhancement has benefited from the success of deep learning in terms of intelligibility and perceptual quality. Conventional time-frequency (TF) domain methods focus on predicting TF-masks or speech spectrum,via a naive convolution neural network or recurrent neural network.Some recent studies were based on Complex spectral Mapping convolution recurrent neural network (CRN) . These models skiped directly from encoder layers' output and decoder layers' input ,which maybe thoughtless. We proposed an attention mechanism based skip connection between encoder and decoder layers,namely Complex Spectral Mapping With Attention Based Convolution Recurrent Neural Network (CARN).Compared with CRN model,the proposed CARN model improved more than 10% relatively at several metrics such as PESQ,CBAK,COVL,CSIG and son,and outperformed the place 1st model in both real time and non-real time track of the DNS Challenge 2020 at these metrics.
Predicting vehicles parking behaviour in shared premises for aggregated EV electricity demand response programs
Sep 20, 2021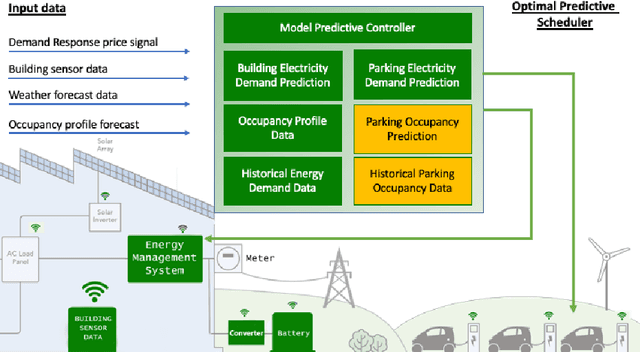
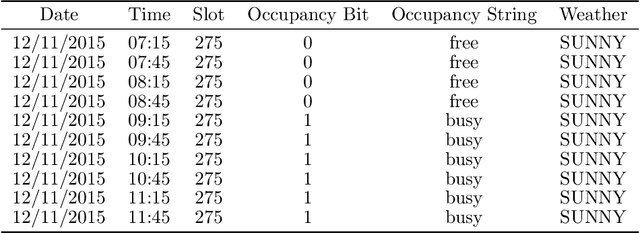
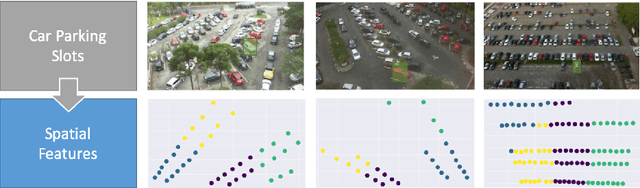
The global electric car sales in 2020 continued to exceed the expectations climbing to over 3 millions and reaching a market share of over 4%. However, uncertainty of generation caused by higher penetration of renewable energies and the advent of Electrical Vehicles (EV) with their additional electricity demand could cause strains to the power system, both at distribution and transmission levels. Demand response aggregation and load control will enable greater grid stability and greater penetration of renewable energies into the grid. The present work fits this context in supporting charging optimization for EV in parking premises assuming a incumbent high penetration of EVs in the system. We propose a methodology to predict an estimation of the parking duration in shared parking premises with the objective of estimating the energy requirement of a specific parking lot, evaluate optimal EVs charging schedule and integrate the scheduling into a smart controller. We formalize the prediction problem as a supervised machine learning task to predict the duration of the parking event before the car leaves the slot. This predicted duration feeds the energy management system that will allocate the power over the duration reducing the overall peak electricity demand. We structure our experiments inspired by two research questions aiming to discover the accuracy of the proposed machine learning approach and the most relevant features for the prediction models. We experiment different algorithms and features combination for 4 datasets from 2 different campus facilities in Italy and Brazil. Using both contextual and time of the day features, the overall results of the models shows an higher accuracy compared to a statistical analysis based on frequency, indicating a viable route for the development of accurate predictors for sharing parking premises energy management systems
DySMHO: Data-Driven Discovery of Governing Equations for Dynamical Systems via Moving Horizon Optimization
Jul 30, 2021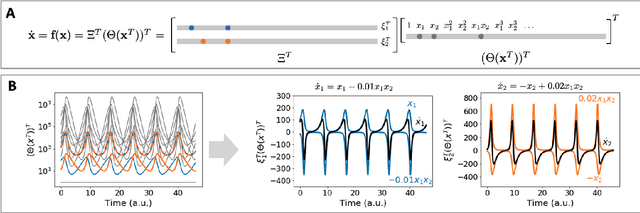
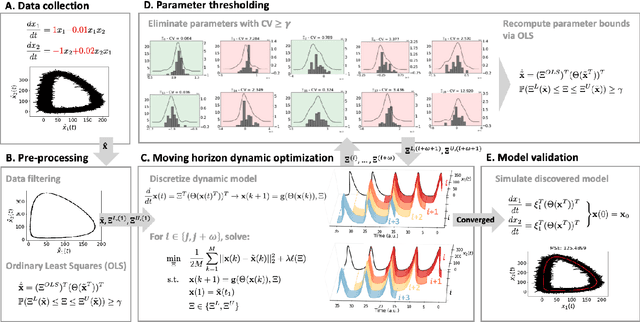
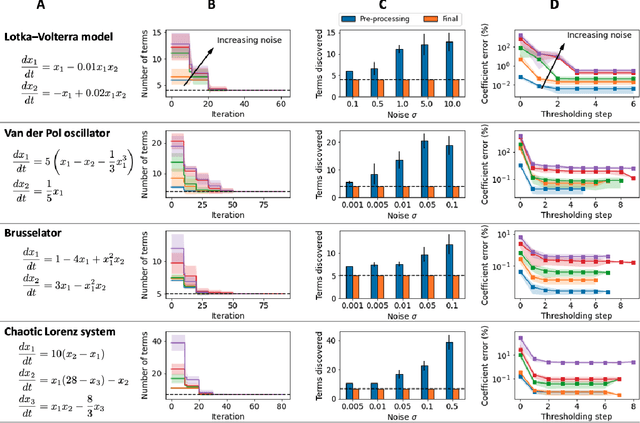
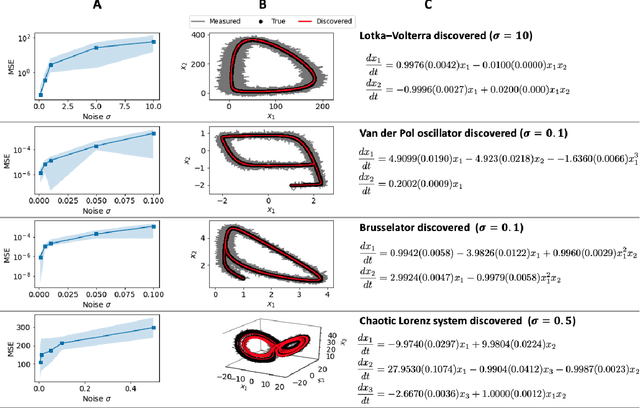
Discovering the governing laws underpinning physical and chemical phenomena is a key step towards understanding and ultimately controlling systems in science and engineering. We introduce Discovery of Dynamical Systems via Moving Horizon Optimization (DySMHO), a scalable machine learning framework for identifying governing laws in the form of differential equations from large-scale noisy experimental data sets. DySMHO consists of a novel moving horizon dynamic optimization strategy that sequentially learns the underlying governing equations from a large dictionary of basis functions. The sequential nature of DySMHO allows leveraging statistical arguments for eliminating irrelevant basis functions, avoiding overfitting to recover accurate and parsimonious forms of the governing equations. Canonical nonlinear dynamical system examples are used to demonstrate that DySMHO can accurately recover the governing laws, is robust to high levels of measurement noise and that it can handle challenges such as multiple time scale dynamics.
T-GAP: Learning to Walk across Time for Temporal Knowledge Graph Completion
Dec 19, 2020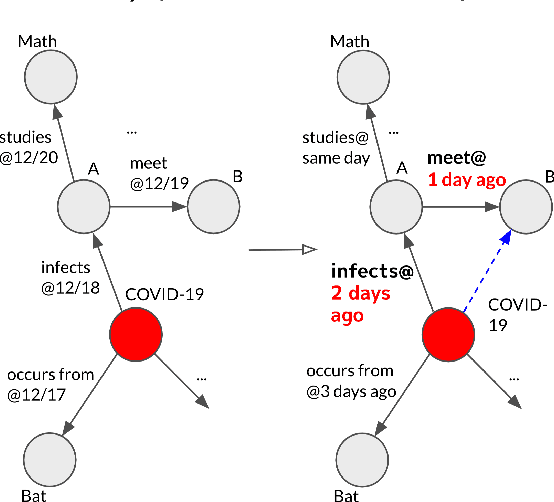
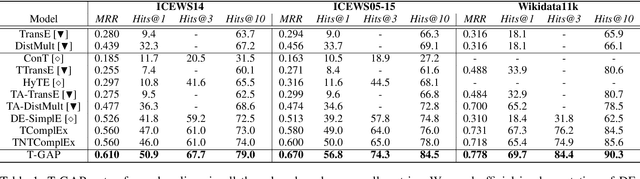
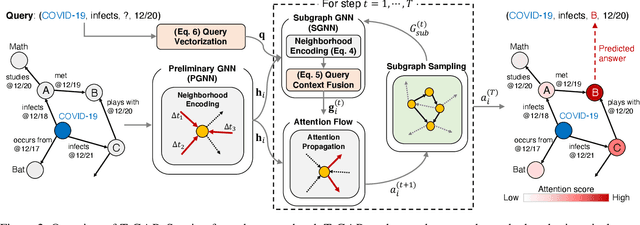
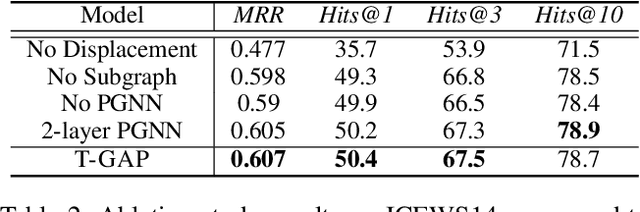
Temporal knowledge graphs (TKGs) inherently reflect the transient nature of real-world knowledge, as opposed to static knowledge graphs. Naturally, automatic TKG completion has drawn much research interests for a more realistic modeling of relational reasoning. However, most of the existing mod-els for TKG completion extend static KG embeddings that donot fully exploit TKG structure, thus lacking in 1) account-ing for temporally relevant events already residing in the lo-cal neighborhood of a query, and 2) path-based inference that facilitates multi-hop reasoning and better interpretability. In this paper, we propose T-GAP, a novel model for TKG completion that maximally utilizes both temporal information and graph structure in its encoder and decoder. T-GAP encodes query-specific substructure of TKG by focusing on the temporal displacement between each event and the query times-tamp, and performs path-based inference by propagating attention through the graph. Our empirical experiments demonstrate that T-GAP not only achieves superior performance against state-of-the-art baselines, but also competently generalizes to queries with unseen timestamps. Through extensive qualitative analyses, we also show that T-GAP enjoys from transparent interpretability, and follows human intuition in its reasoning process.