 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Performance Evaluation of Deep Transfer Learning on Multiclass Identification of Common Weed Species in Cotton Production Systems
Oct 11, 2021
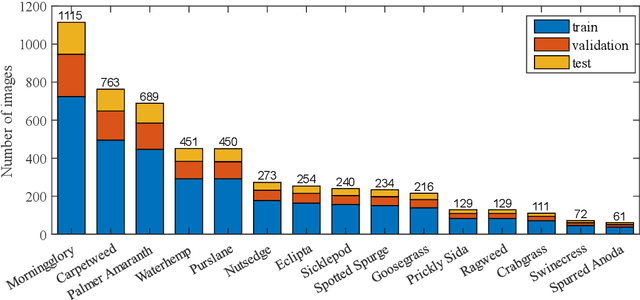
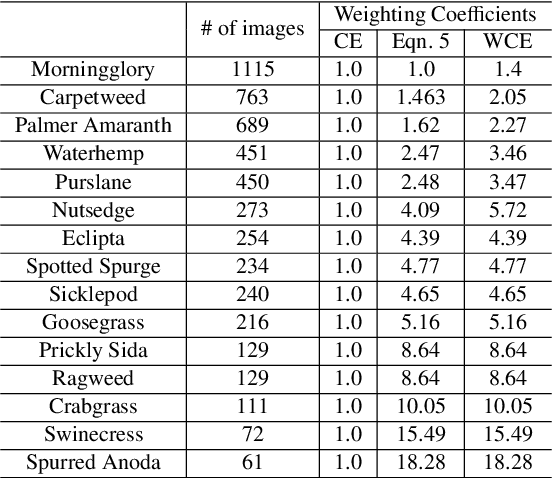

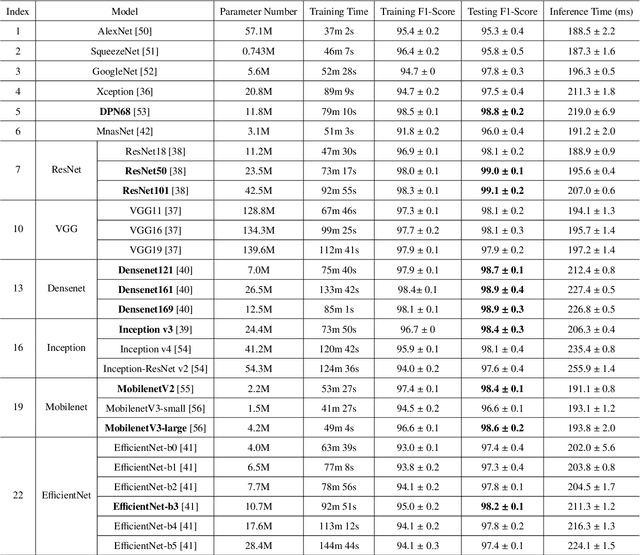
Precision weed management offers a promising solution for sustainable cropping systems through the use of chemical-reduced/non-chemical robotic weeding techniques, which apply suitable control tactics to individual weeds. Therefore, accurate identification of weed species plays a crucial role in such systems to enable precise, individualized weed treatment. This paper makes a first comprehensive evaluation of deep transfer learning (DTL) for identifying common weeds specific to cotton production systems in southern United States. A new dataset for weed identification was created, consisting of 5187 color images of 15 weed classes collected under natural lighting conditions and at varied weed growth stages, in cotton fields during the 2020 and 2021 field seasons. We evaluated 27 state-of-the-art deep learning models through transfer learning and established an extensive benchmark for the considered weed identification task. DTL achieved high classification accuracy of F1 scores exceeding 95%, requiring reasonably short training time (less than 2.5 hours) across models. ResNet101 achieved the best F1-score of 99.1% whereas 14 out of the 27 models achieved F1 scores exceeding 98.0%. However, the performance on minority weed classes with few training samples was less satisfactory for models trained with a conventional, unweighted cross entropy loss function. To address this issue, a weighted cross entropy loss function was adopted, which achieved substantially improved accuracies for minority weed classes. Furthermore, a deep learning-based cosine similarity metrics was employed to analyze the similarity among weed classes, assisting in the interpretation of classifications. Both the codes for model benchmarking and the weed dataset are made publicly available, which expect to be be a valuable resource for future research in weed identification and beyond.
Generative Zero-Shot Learning for Semantic Segmentation of 3D Point Cloud
Aug 13, 2021
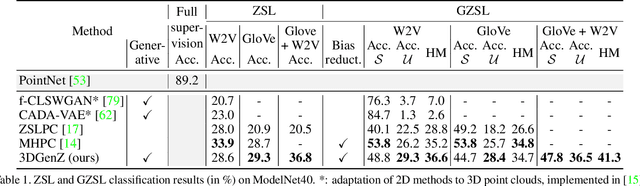
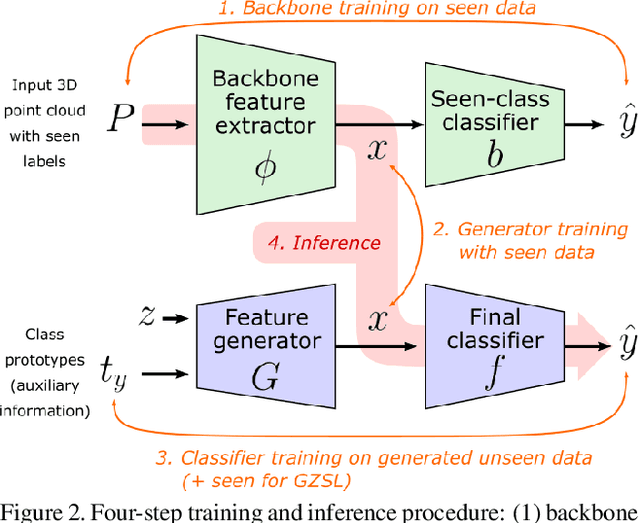
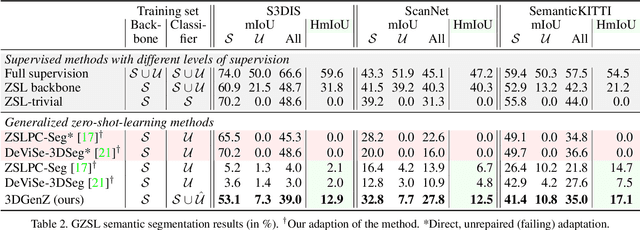
While there has been a number of studies on Zero-Shot Learning (ZSL) for 2D images, its application to 3D data is still recent and scarce, with just a few methods limited to classification. We present the first generative approach for both ZSL and Generalized ZSL (GZSL) on 3D data, that can handle both classification and, for the first time, semantic segmentation. We show that it reaches or outperforms the state of the art on ModelNet40 classification for both inductive ZSL and inductive GZSL. For semantic segmentation, we created three benchmarks for evaluating this new ZSL task, using S3DIS, ScanNet and SemanticKITTI. Our experiments show that our method outperforms strong baselines, which we additionally propose for this task.
Distributed Optimization of Graph Convolutional Network using Subgraph Variance
Oct 06, 2021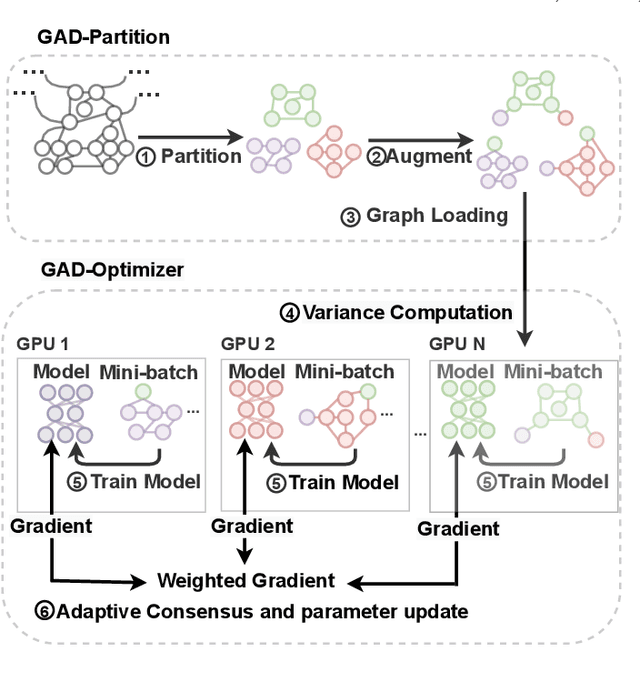

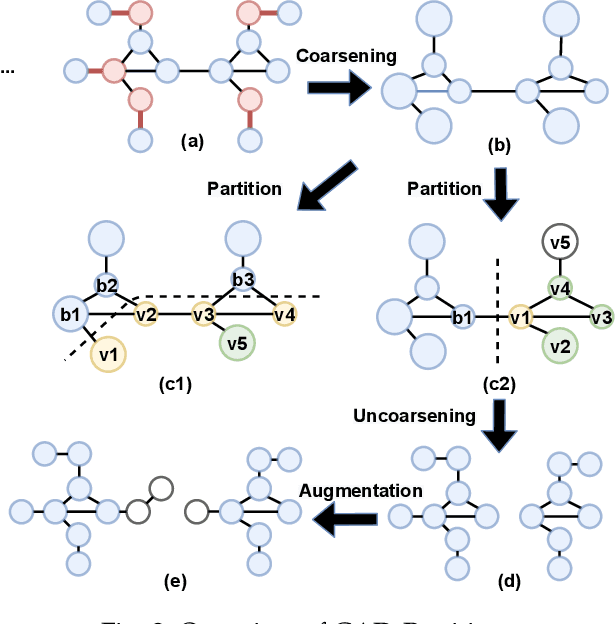
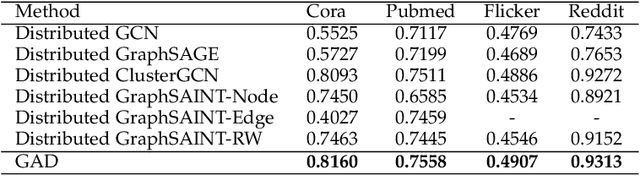
In recent years, Graph Convolutional Networks (GCNs) have achieved great success in learning from graph-structured data. With the growing tendency of graph nodes and edges, GCN training by single processor cannot meet the demand for time and memory, which led to a boom into distributed GCN training frameworks research. However, existing distributed GCN training frameworks require enormous communication costs between processors since multitudes of dependent nodes and edges information need to be collected and transmitted for GCN training from other processors. To address this issue, we propose a Graph Augmentation based Distributed GCN framework(GAD). In particular, GAD has two main components, GAD-Partition and GAD-Optimizer. We first propose a graph augmentation-based partition (GAD-Partition) that can divide original graph into augmented subgraphs to reduce communication by selecting and storing as few significant nodes of other processors as possible while guaranteeing the accuracy of the training. In addition, we further design a subgraph variance-based importance calculation formula and propose a novel weighted global consensus method, collectively referred to as GAD-Optimizer. This optimizer adaptively reduces the importance of subgraphs with large variances for the purpose of reducing the effect of extra variance introduced by GAD-Partition on distributed GCN training. Extensive experiments on four large-scale real-world datasets demonstrate that our framework significantly reduces the communication overhead (50%), improves the convergence speed (2X) of distributed GCN training, and slight gain in accuracy (0.45%) based on minimal redundancy compared to the state-of-the-art methods.
Warming-up recurrent neural networks to maximize reachable multi-stability greatly improves learning
Jun 02, 2021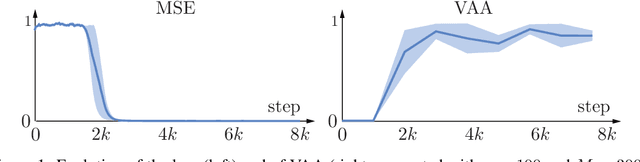
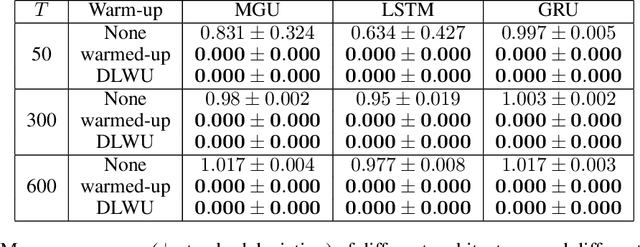

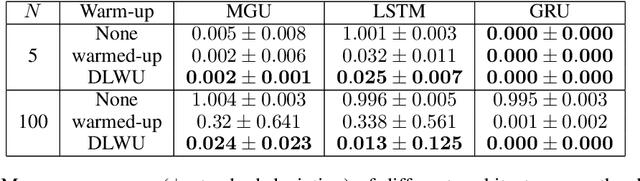
Training recurrent neural networks is known to be difficult when time dependencies become long. Consequently, training standard gated cells such as gated recurrent units and long-short term memory on benchmarks where long-term memory is required remains an arduous task. In this work, we propose a general way to initialize any recurrent network connectivity through a process called "warm-up" to improve its capability to learn arbitrarily long time dependencies. This initialization process is designed to maximize network reachable multi-stability, i.e. the number of attractors within the network that can be reached through relevant input trajectories. Warming-up is performed before training, using stochastic gradient descent on a specifically designed loss. We show that warming-up greatly improves recurrent neural network performance on long-term memory benchmarks for multiple recurrent cell types, but can sometimes impede precision. We therefore introduce a parallel recurrent network structure with partial warm-up that is shown to greatly improve learning on long time-series while maintaining high levels of precision. This approach provides a general framework for improving learning abilities of any recurrent cell type when long-term memory is required.
Extended Version of GTGraffiti: Spray Painting Graffiti Art from Human Painting Motions with a Cable Driven Parallel Robot
Sep 16, 2021
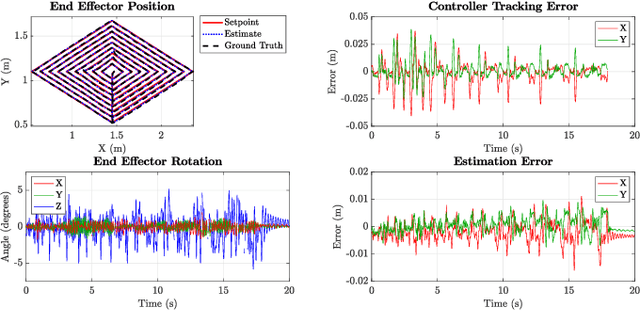


We present GTGraffiti, a graffiti painting system from Georgia Tech that tackles challenges in art, hardware, and human-robot collaboration. The problem of painting graffiti in a human style is particularly challenging and requires a system-level approach because the robotics and art must be designed around each other. The robot must be highly dynamic over a large workspace while the artist must work within the robot's limitations. Our approach consists of three stages: artwork capture, robot hardware, and planning & control. We use motion capture to capture collaborator painting motions which are then composed and processed into a time-varying linear feedback controller for a cable-driven parallel robot (CDPR) to execute. In this work, we will describe the capturing process, the design and construction of a purpose-built CDPR, and the software for turning an artist's vision into control commands. Our work represents an important step towards faithfully recreating human graffiti artwork by demonstrating that we can reproduce artist motions up to 2m/s and 20m/s$^2$ within 9.3mm RMSE to paint artworks. Added material not in the original work is colored in red.
Ranking Scientific Papers Using Preference Learning
Sep 02, 2021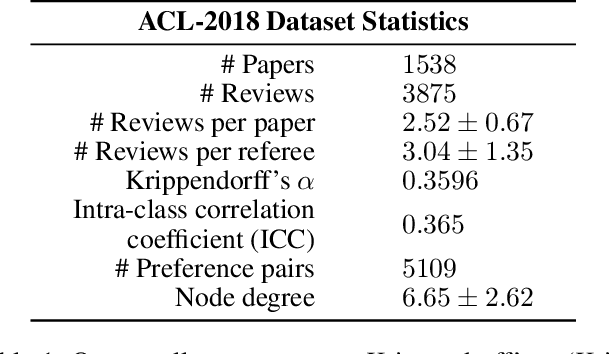
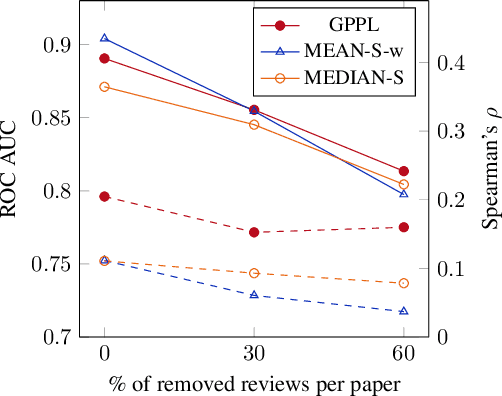
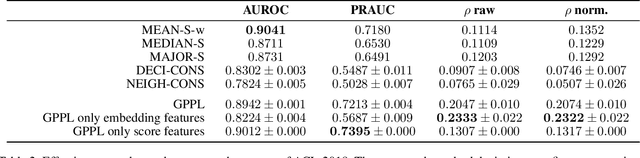
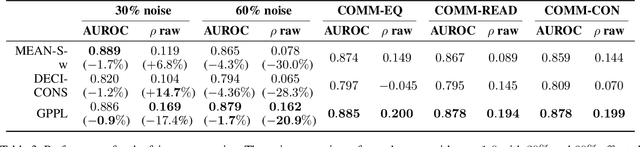
Peer review is the main quality control mechanism in academia. Quality of scientific work has many dimensions; coupled with the subjective nature of the reviewing task, this makes final decision making based on the reviews and scores therein very difficult and time-consuming. To assist with this important task, we cast it as a paper ranking problem based on peer review texts and reviewer scores. We introduce a novel, multi-faceted generic evaluation framework for making final decisions based on peer reviews that takes into account effectiveness, efficiency and fairness of the evaluated system. We propose a novel approach to paper ranking based on Gaussian Process Preference Learning (GPPL) and evaluate it on peer review data from the ACL-2018 conference. Our experiments demonstrate the superiority of our GPPL-based approach over prior work, while highlighting the importance of using both texts and review scores for paper ranking during peer review aggregation.
8-bit Optimizers via Block-wise Quantization
Oct 06, 2021



Stateful optimizers maintain gradient statistics over time, e.g., the exponentially smoothed sum (SGD with momentum) or squared sum (Adam) of past gradient values. This state can be used to accelerate optimization compared to plain stochastic gradient descent but uses memory that might otherwise be allocated to model parameters, thereby limiting the maximum size of models trained in practice. In this paper, we develop the first optimizers that use 8-bit statistics while maintaining the performance levels of using 32-bit optimizer states. To overcome the resulting computational, quantization, and stability challenges, we develop block-wise dynamic quantization. Block-wise quantization divides input tensors into smaller blocks that are independently quantized. Each block is processed in parallel across cores, yielding faster optimization and high precision quantization. To maintain stability and performance, we combine block-wise quantization with two additional changes: (1) dynamic quantization, a form of non-linear optimization that is precise for both large and small magnitude values, and (2) a stable embedding layer to reduce gradient variance that comes from the highly non-uniform distribution of input tokens in language models. As a result, our 8-bit optimizers maintain 32-bit performance with a small fraction of the memory footprint on a range of tasks, including 1.5B parameter language modeling, GLUE finetuning, ImageNet classification, WMT'14 machine translation, MoCo v2 contrastive ImageNet pretraining+finetuning, and RoBERTa pretraining, without changes to the original optimizer hyperparameters. We open-source our 8-bit optimizers as a drop-in replacement that only requires a two-line code change.
Detection of Deepfake Videos Using Long Distance Attention
Jun 24, 2021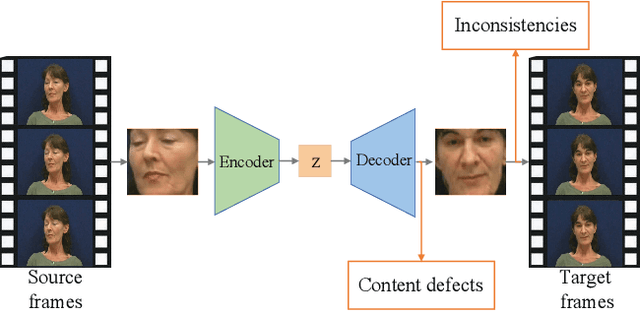
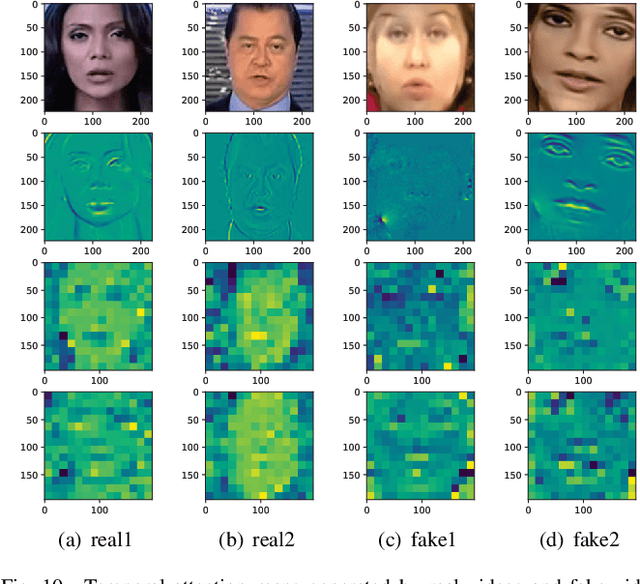
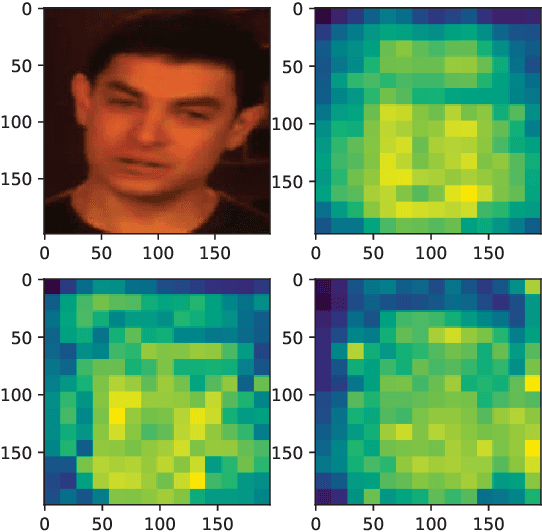

With the rapid progress of deepfake techniques in recent years, facial video forgery can generate highly deceptive video contents and bring severe security threats. And detection of such forgery videos is much more urgent and challenging. Most existing detection methods treat the problem as a vanilla binary classification problem. In this paper, the problem is treated as a special fine-grained classification problem since the differences between fake and real faces are very subtle. It is observed that most existing face forgery methods left some common artifacts in the spatial domain and time domain, including generative defects in the spatial domain and inter-frame inconsistencies in the time domain. And a spatial-temporal model is proposed which has two components for capturing spatial and temporal forgery traces in global perspective respectively. The two components are designed using a novel long distance attention mechanism. The one component of the spatial domain is used to capture artifacts in a single frame, and the other component of the time domain is used to capture artifacts in consecutive frames. They generate attention maps in the form of patches. The attention method has a broader vision which contributes to better assembling global information and extracting local statistic information. Finally, the attention maps are used to guide the network to focus on pivotal parts of the face, just like other fine-grained classification methods. The experimental results on different public datasets demonstrate that the proposed method achieves the state-of-the-art performance, and the proposed long distance attention method can effectively capture pivotal parts for face forgery.
Coast Sargassum Level Estimation from Smartphone Pictures
Sep 21, 2021
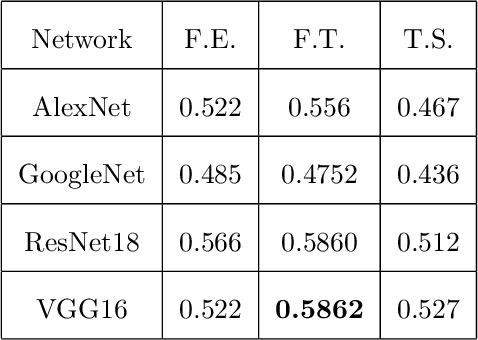
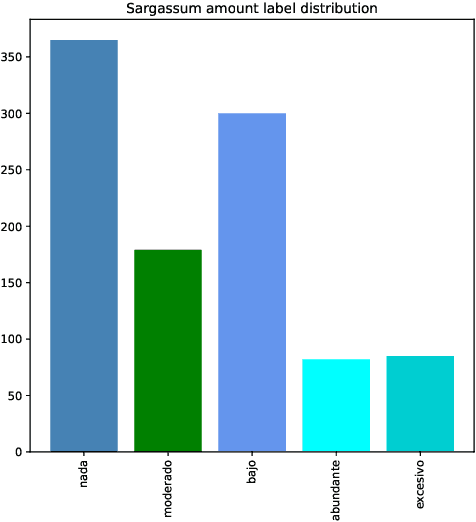
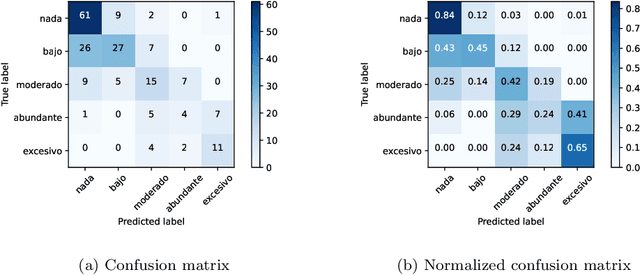
Since 2011, significant and atypical arrival of two species of surface dwelling algae, Sargassum natans and Sargassum Fluitans, have been detected in the Mexican Caribbean. This massive accumulation of algae has had a great environmental and economic impact. Therefore, for the government, ecologists, and local businesses, it is important to keep track of the amount of sargassum that arrives on the Caribbean coast. High-resolution satellite imagery is expensive or may be time delayed. Therefore, we propose to estimate the amount of sargassum based on ground-level smartphone photographs. From the computer vision perspective, the problem is quite difficult since no information about the 3D world is provided, in consequence, we have to model it as a classification problem, where a set of five labels define the amount. For this purpose, we have built a dataset with more than one thousand examples from public forums such as Facebook or Instagram and we have tested several state-of-the-art convolutional networks. As a result, the VGG network trained under fine-tuning showed the best performance. Even though the reached accuracy could be improved with more examples, the current prediction distribution is narrow, so the predictions are adequate for keeping a record and taking quick ecological actions.
WHO-Hand Hygiene Gesture Classification System
Oct 06, 2021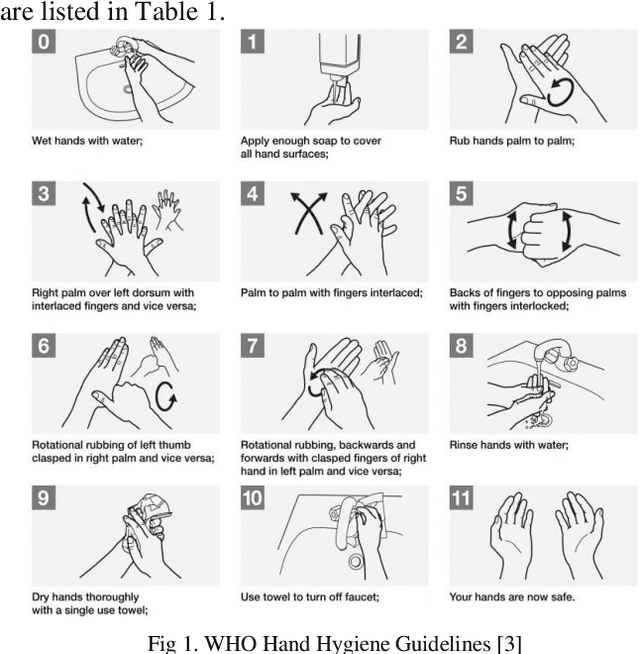
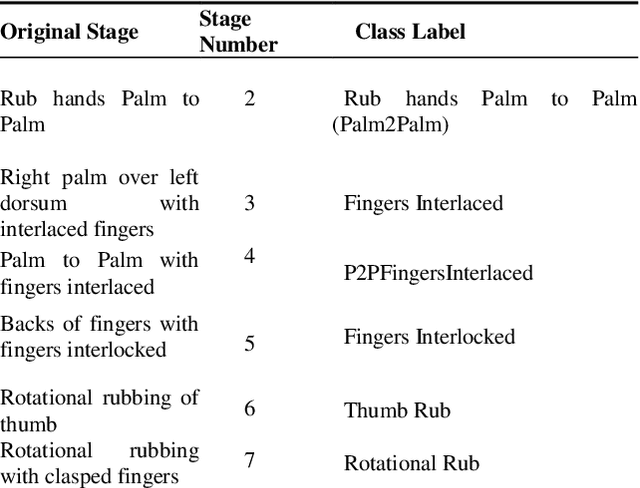

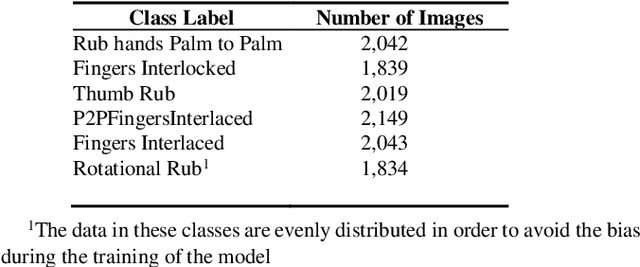
The recent ongoing coronavirus pandemic highlights the importance of hand hygiene practices in our daily lives, with governments and worldwide health authorities promoting good hand hygiene practices. More than one million cases of hospital-acquired infections occur in Europe annually. Hand hygiene compliance may reduce the risk of transmission by reducing the number of infections as well as healthcare expenditures. In this paper, the World Health Organization, hand hygiene gestures are recorded and analyzed with the construction of an aluminum frame, placed at the laboratory sink. The hand hygiene gestures are recorded for thirty participants after conducting a training session about hand hygiene gestures demonstration. The video recordings are converted into image files and are organized into six different hand hygiene classes. The Resnet50 framework selection for the classification of multiclass hand hygiene stages. The model is trained with the first set of classes; Fingers Interlaced, P2PFingers Interlaced, and Rotational Rub for 25 epochs. An accuracy of 44 percent for the first set of experiments with a loss score greater than 1.5 in the validation set is achieved. The training steps for the second set of classes; Rub hands palm to palm, Fingers Interlocked, Thumb Rub are 50 epochs. An accuracy of 72 percent is achieved for the second set with a loss score of less than 0.8 for the validation set. In this work, a preliminary analysis of a robust hand hygiene dataset with transfer learning takes place. The future aim for deploying a hand hygiene prediction system for healthcare workers in real-time.