 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Multistability for Horizon Generalization in Reinforcement Learning
May 12, 2026In reinforcement learning (RL), agents acting in partially observable Markov decision processes (POMDPs) must rely on memory, typically encoded in a recurrent neural network (RNN), to integrate information from past observations. Long-horizon POMDPs, in which the relevant observation and the optimal action are separated by many time steps (called the horizon), are particularly challenging: training suffers from poor generalization, severe sample inefficiency, and prohibitive exploration costs. Ideally, an agent trained on short horizons would retain optimal behavior at arbitrarily longer ones, but no formal framework currently characterizes when this is achievable. To fill this gap, we formalized temporal horizon generalization, the property that a policy remains optimal for all horizons, derived a necessary and sufficient condition for it, and experimentally evaluated the ability of nonlinear and parallelizable RNN variants to achieve it. This paper presents the resulting theoretical framework, the empirical evaluation, and the dynamical interpretation linking RNN behavior to temporal horizon generalization. Our analyses reveal that multistability is necessary for temporal horizon generalization and, in simple tasks, sufficient; more complex tasks further require transient dynamics. In contrast, modern parallelizable architectures, namely state space models and gated linear RNNs, are monostable by construction and consequently fail to generalize across temporal horizons. We conclude that multistability and transient dynamics are two essential and complementary dynamical regimes for horizon generalization, and that no current parallelizable RNN exhibits both. Designing parallelizable architectures that combine these regimes thus emerges as a key direction for scalable long-horizon RL.
Improving the Performance and Learning Stability of Parallelizable RNNs Designed for Ultra-Low Power Applications
May 12, 2026Sequence learning is dominated by Transformers and parallelizable recurrent neural networks (RNNs) such as state-space models, yet learning long-term dependencies remains challenging, and state-of-the-art designs trade power consumption for performance. The Bistable Memory Recurrent Unit (BMRU) was introduced to enable hardware-software co-design of ultra-low power RNNs: quantized states with hysteresis provide persistent memory while mapping directly to analog primitives. However, BMRU performance lags behind parallelizable RNNs on complex sequential tasks. In this paper, we identify gradient blocking during state updates as a key limitation and propose a cumulative update formulation that restores gradient flow while preserving persistent memory, creating skip-connections through time. This leads to the Cumulative Memory Recurrent Unit (CMRU) and its relaxed variant, the $α$CMRU. Experiments show that the cumulative formulation dramatically improves convergence stability and reduces initialization sensitivity. The CMRU and $α$CMRU match or outperform Linear Recurrent Units (LRUs) and minimal Gated Recurrent Units (minGRUs) across diverse benchmarks at small model sizes, with particular advantages on tasks requiring discrete long-range retention, while the CMRU retains quantized states, persistent memory, and noise-resilient dynamics essential for analog implementation.
Energy-Efficient Implementation of Spiking Recurrent Cells on FPGA
May 11, 2026Spiking Neural Networks (SNNs) can reduce energy consumption compared to conventional Artificial Neural Networks (ANNs) when spiking activity is sparse and the neuron model is hardware-friendly. However, biologically faithful models are often too costly to implement on FPGAs, whereas very simple models (e.g., IR/LIF) sacrifice part of the neuronal dynamics. In this work, we present an FPGA accelerator for an SNN using Spiking Recurrent Cell (SRC) neurons, providing a trade-off between biological plausibility and hardware cost. We propose a set of mathematical simplifications that remove costly unary operators (\textit{tanh}, \textit{exp}) and avoid floating-point arithmetic through scaling and piecewise-defined approximations. The complete network is implemented in VHDL and validated using spiking traces derived from the MNIST dataset. The weight matrices computed off-line are stored directly in LUT-registers without any adaptation. This demonstrates the robustness of SRC cells. Experiments were conducted on an Artix-7 XC7A200T clocked at 100 MHz. The reference implementation achieves 96.31\% accuracy with a 220-image spiking trace and a processing time of 1.7424 ms per digit. We then investigate accuracy/energy trade-offs by reducing the spiking trace length and quantizing synaptic weights down to 4 bits, achieving 93.32\% accuracy at 0.55 mJ per digit (55 images, 5-bit weights) and 92.89\% at 0.45 mJ (44 images, 4-bit weights). These results show that SRC-based SNNs can deliver competitive performance with reduced energy consumption, while preserving richer neuronal dynamics than standard LIF/IR models.
Context-dependent manifold learning: A neuromodulated constrained autoencoder approach
Mar 12, 2026Constrained autoencoders (cAE) provide a successful path towards interpretable dimensionality reduction by enforcing geometric structure on latent spaces. However, standard cAEs cannot adapt to varying physical parameters or environmental conditions without conflating these contextual shifts with the primary input. To address this, we integrated a neuromodulatory mechanism into the cAE framework to allow for context-dependent manifold learning. This paper introduces the Neuromodulated Constrained Autoencoder (NcAE), which adaptively parameterizes geometric constraints via gain and bias tuning conditioned on static contextual information. Experimental results on dynamical systems show that the NcAE accurately captures how manifold geometry varies across different regimes while maintaining rigorous projection properties. These results demonstrate that neuromodulation effectively decouples global contextual parameters from local manifold representations. This architecture provides a foundation for developing more flexible, physics-informed representations in systems subject to (non-stationary) environmental constraints.
Parallelizable memory recurrent units
Jan 14, 2026With the emergence of massively parallel processing units, parallelization has become a desirable property for new sequence models. The ability to parallelize the processing of sequences with respect to the sequence length during training is one of the main factors behind the uprising of the Transformer architecture. However, Transformers lack efficiency at sequence generation, as they need to reprocess all past timesteps at every generation step. Recently, state-space models (SSMs) emerged as a more efficient alternative. These new kinds of recurrent neural networks (RNNs) keep the efficient update of the RNNs while gaining parallelization by getting rid of nonlinear dynamics (or recurrence). SSMs can reach state-of-the art performance through the efficient training of potentially very large networks, but still suffer from limited representation capabilities. In particular, SSMs cannot exhibit persistent memory, or the capacity of retaining information for an infinite duration, because of their monostability. In this paper, we introduce a new family of RNNs, the memory recurrent units (MRUs), that combine the persistent memory capabilities of nonlinear RNNs with the parallelizable computations of SSMs. These units leverage multistability as a source of persistent memory, while getting rid of transient dynamics for efficient computations. We then derive a specific implementation as proof-of-concept: the bistable memory recurrent unit (BMRU). This new RNN is compatible with the parallel scan algorithm. We show that BMRU achieves good results in tasks with long-term dependencies, and can be combined with state-space models to create hybrid networks that are parallelizable and have transient dynamics as well as persistent memory.
Fast reconstruction of degenerate populations of conductance-based neuron models from spike times
Sep 16, 2025



Neurons communicate through spikes, and spike timing is a crucial part of neuronal processing. Spike times can be recorded experimentally both intracellularly and extracellularly, and are the main output of state-of-the-art neural probes. On the other hand, neuronal activity is controlled at the molecular level by the currents generated by many different transmembrane proteins called ion channels. Connecting spike timing to ion channel composition remains an arduous task to date. To address this challenge, we developed a method that combines deep learning with a theoretical tool called Dynamic Input Conductances (DICs), which reduce the complexity of ion channel interactions into three interpretable components describing how neurons spike. Our approach uses deep learning to infer DICs directly from spike times and then generates populations of "twin" neuron models that replicate the observed activity while capturing natural variability in membrane channel composition. The method is fast, accurate, and works using only spike recordings. We also provide open-source software with a graphical interface, making it accessible to researchers without programming expertise.
Spike-based computation using classical recurrent neural networks
Jun 06, 2023Spiking neural networks are a type of artificial neural networks in which communication between neurons is only made of events, also called spikes. This property allows neural networks to make asynchronous and sparse computations and therefore to drastically decrease energy consumption when run on specialized hardware. However, training such networks is known to be difficult, mainly due to the non-differentiability of the spike activation, which prevents the use of classical backpropagation. This is because state-of-the-art spiking neural networks are usually derived from biologically-inspired neuron models, to which are applied machine learning methods for training. Nowadays, research about spiking neural networks focuses on the design of training algorithms whose goal is to obtain networks that compete with their non-spiking version on specific tasks. In this paper, we attempt the symmetrical approach: we modify the dynamics of a well-known, easily trainable type of recurrent neural network to make it event-based. This new RNN cell, called the Spiking Recurrent Cell, therefore communicates using events, i.e. spikes, while being completely differentiable. Vanilla backpropagation can thus be used to train any network made of such RNN cell. We show that this new network can achieve performance comparable to other types of spiking networks in the MNIST benchmark and its variants, the Fashion-MNIST and the Neuromorphic-MNIST. Moreover, we show that this new cell makes the training of deep spiking networks achievable.
Warming-up recurrent neural networks to maximize reachable multi-stability greatly improves learning
Jun 02, 2021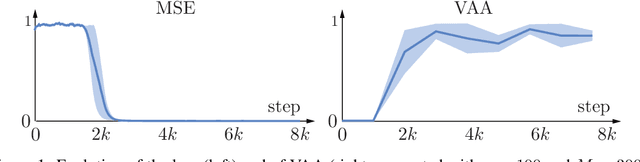
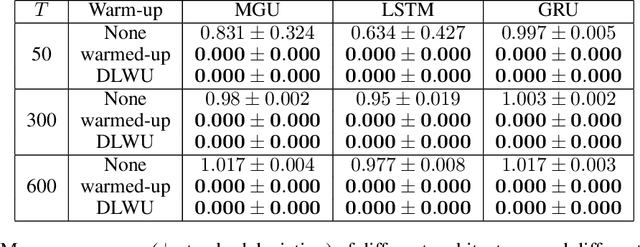

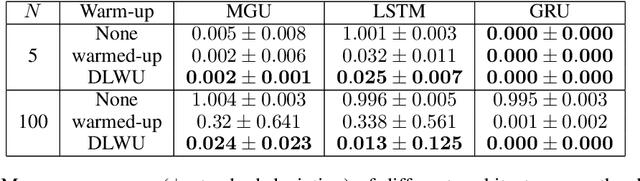
Training recurrent neural networks is known to be difficult when time dependencies become long. Consequently, training standard gated cells such as gated recurrent units and long-short term memory on benchmarks where long-term memory is required remains an arduous task. In this work, we propose a general way to initialize any recurrent network connectivity through a process called "warm-up" to improve its capability to learn arbitrarily long time dependencies. This initialization process is designed to maximize network reachable multi-stability, i.e. the number of attractors within the network that can be reached through relevant input trajectories. Warming-up is performed before training, using stochastic gradient descent on a specifically designed loss. We show that warming-up greatly improves recurrent neural network performance on long-term memory benchmarks for multiple recurrent cell types, but can sometimes impede precision. We therefore introduce a parallel recurrent network structure with partial warm-up that is shown to greatly improve learning on long time-series while maintaining high levels of precision. This approach provides a general framework for improving learning abilities of any recurrent cell type when long-term memory is required.
A bio-inspired bistable recurrent cell allows for long-lasting memory
Jun 09, 2020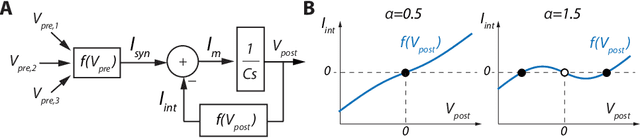

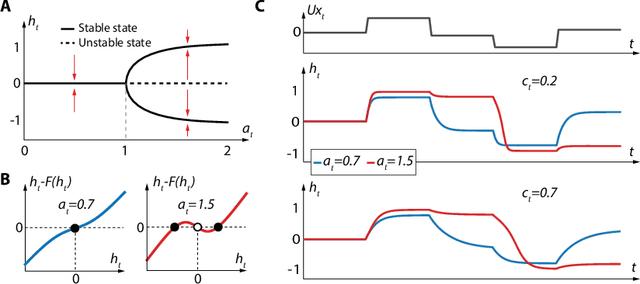

Recurrent neural networks (RNNs) provide state-of-the-art performances in a wide variety of tasks that require memory. These performances can often be achieved thanks to gated recurrent cells such as gated recurrent units (GRU) and long short-term memory (LSTM). Standard gated cells share a layer internal state to store information at the network level, and long term memory is shaped by network-wide recurrent connection weights. Biological neurons on the other hand are capable of holding information at the cellular level for an arbitrary long amount of time through a process called bistability. Through bistability, cells can stabilize to different stable states depending on their own past state and inputs, which permits the durable storing of past information in neuron state. In this work, we take inspiration from biological neuron bistability to embed RNNs with long-lasting memory at the cellular level. This leads to the introduction of a new bistable biologically-inspired recurrent cell that is shown to strongly improves RNN performance on time-series which require very long memory, despite using only cellular connections (all recurrent connections are from neurons to themselves, i.e. a neuron state is not influenced by the state of other neurons). Furthermore, equipping this cell with recurrent neuromodulation permits to link them to standard GRU cells, taking a step towards the biological plausibility of GRU.
Introducing Neuromodulation in Deep Neural Networks to Learn Adaptive Behaviours
Jan 02, 2019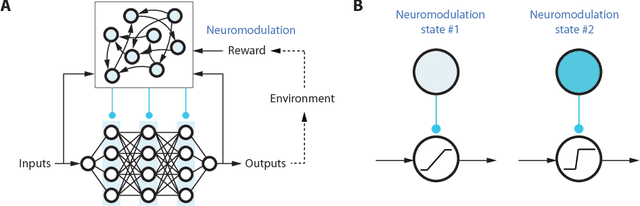

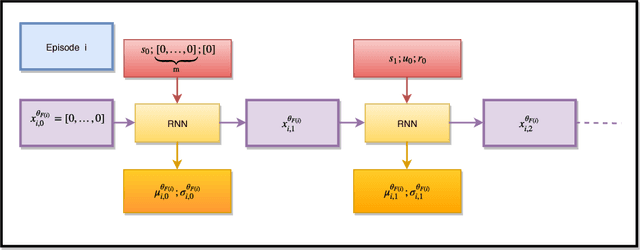

In this paper, we propose a new deep neural network architecture, called NMD net, that has been specifically designed to learn adaptive behaviours. This architecture exploits a biological mechanism called neuromodulation that sustains adaptation in biological organisms. This architecture has been introduced in a deep-reinforcement learning architecture for interacting with Markov decision processes in a meta-reinforcement learning setting where the action space is continuous. The deep-reinforcement learning architecture is trained using an advantage actor-critic algorithm. Experiments are carried on several test problems. Results show that the neural network architecture with neuromodulation provides significantly better results than state-of-the-art recurrent neural networks which do not exploit this mechanism.