 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Toward Efficient Federated Learning in Multi-Channeled Mobile Edge Network with Layerd Gradient Compression
Sep 18, 2021
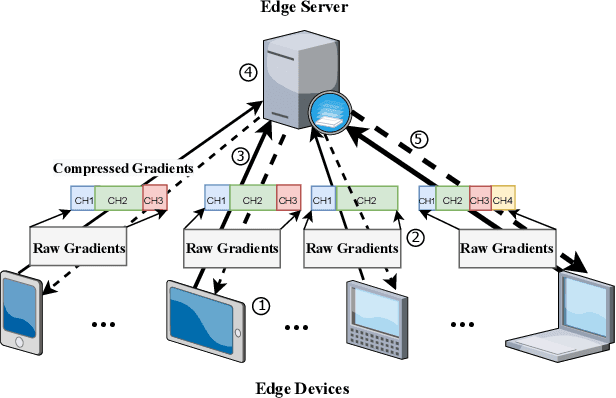

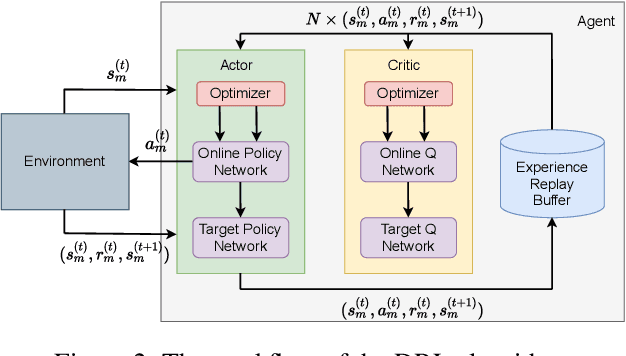
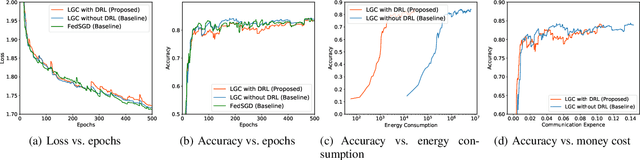
A fundamental issue for federated learning (FL) is how to achieve optimal model performance under highly dynamic communication environments. This issue can be alleviated by the fact that modern edge devices usually can connect to the edge FL server via multiple communication channels (e.g., 4G, LTE and 5G). However, having an edge device send copies of local models to the FL server along multiple channels is redundant, time-consuming, and would waste resources (e.g., bandwidth, battery life and monetary cost). In this paper, motivated by the layered coding techniques in video streaming, we propose a novel FL framework called layered gradient compression (LGC). Specifically, in LGC, local gradients from a device is coded into several layers and each layer is sent to the FL server along a different channel. The FL server aggregates the received layers of local gradients from devices to update the global model, and sends the result back to the devices. We prove the convergence of LGC, and formally define the problem of resource-efficient federated learning with LGC. We then propose a learning based algorithm for each device to dynamically adjust its local computation (i.e., the number of local stochastic descent) and communication decisions (i.e.,the compression level of different layers and the layer to channel mapping) in each iteration. Results from extensive experiments show that using our algorithm, LGC significantly reduces the training time, improves the resource utilization, while achieving a similar accuracy, compared with well-known FL mechanisms.
Diffusion Schrödinger Bridge with Applications to Score-Based Generative Modeling
Jun 01, 2021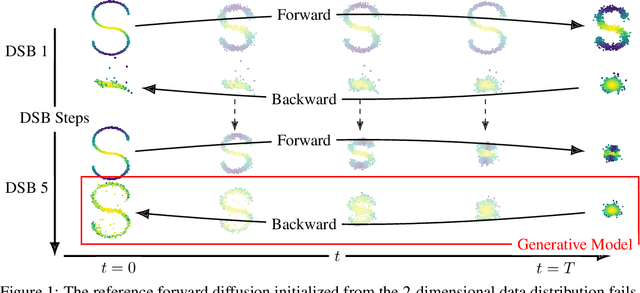
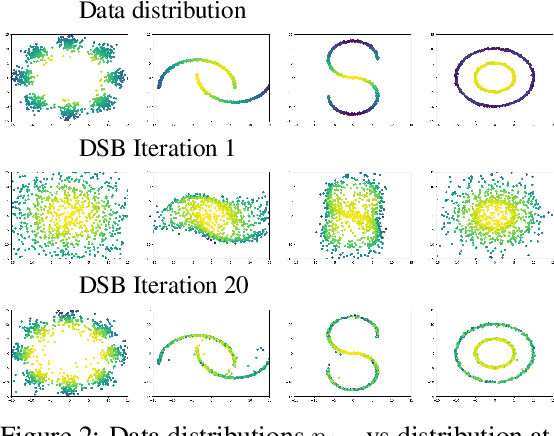
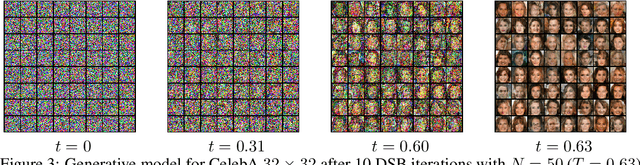
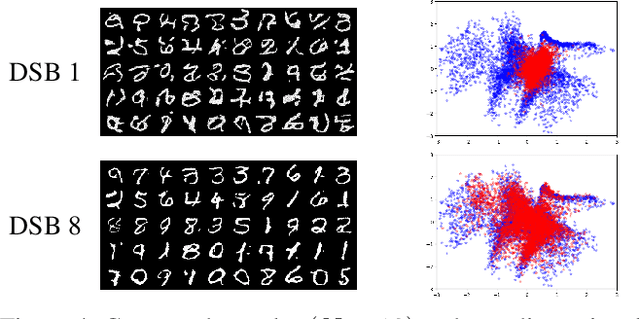
Progressively applying Gaussian noise transforms complex data distributions to approximately Gaussian. Reversing this dynamic defines a generative model. When the forward noising process is given by a Stochastic Differential Equation (SDE), Song et al. (2021) demonstrate how the time inhomogeneous drift of the associated reverse-time SDE may be estimated using score-matching. A limitation of this approach is that the forward-time SDE must be run for a sufficiently long time for the final distribution to be approximately Gaussian. In contrast, solving the Schr\"odinger Bridge problem (SB), i.e. an entropy-regularized optimal transport problem on path spaces, yields diffusions which generate samples from the data distribution in finite time. We present Diffusion SB (DSB), an original approximation of the Iterative Proportional Fitting (IPF) procedure to solve the SB problem, and provide theoretical analysis along with generative modeling experiments. The first DSB iteration recovers the methodology proposed by Song et al. (2021), with the flexibility of using shorter time intervals, as subsequent DSB iterations reduce the discrepancy between the final-time marginal of the forward (resp. backward) SDE with respect to the prior (resp. data) distribution. Beyond generative modeling, DSB offers a widely applicable computational optimal transport tool as the continuous state-space analogue of the popular Sinkhorn algorithm (Cuturi, 2013).
Beyond Classification: Knowledge Distillation using Multi-Object Impressions
Oct 27, 2021



Knowledge Distillation (KD) utilizes training data as a transfer set to transfer knowledge from a complex network (Teacher) to a smaller network (Student). Several works have recently identified many scenarios where the training data may not be available due to data privacy or sensitivity concerns and have proposed solutions under this restrictive constraint for the classification task. Unlike existing works, we, for the first time, solve a much more challenging problem, i.e., "KD for object detection with zero knowledge about the training data and its statistics". Our proposed approach prepares pseudo-targets and synthesizes corresponding samples (termed as "Multi-Object Impressions"), using only the pretrained Faster RCNN Teacher network. We use this pseudo-dataset as a transfer set to conduct zero-shot KD for object detection. We demonstrate the efficacy of our proposed method through several ablations and extensive experiments on benchmark datasets like KITTI, Pascal and COCO. Our approach with no training samples, achieves a respectable mAP of 64.2% and 55.5% on the student with same and half capacity while performing distillation from a Resnet-18 Teacher of 73.3% mAP on KITTI.
CenterAtt: Fast 2-stage Center Attention Network
Jun 19, 2021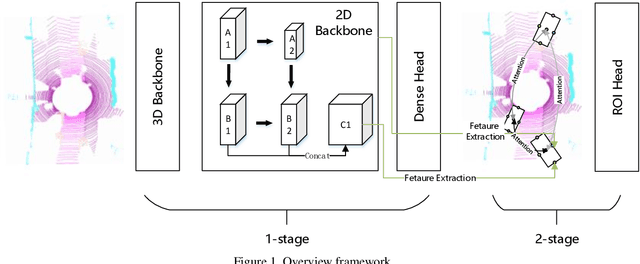
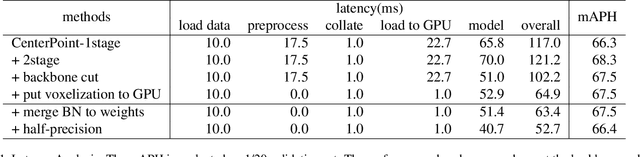


In this technical report, we introduce the methods of HIKVISION_LiDAR_Det in the challenge of waymo open dataset real-time 3D detection. Our solution for the competition are built upon Centerpoint 3D detection framework. Several variants of CenterPoint are explored, including center attention head and feature pyramid network neck. In order to achieve real time detection, methods like batchnorm merge, half-precision floating point network and GPU-accelerated voxelization process are adopted. By using these methods, our team ranks 6th among all the methods on real-time 3D detection challenge in the waymo open dataset.
Real-Time Monitoring and Driver Feedback to Promote Fuel Efficient Driving
Jul 03, 2020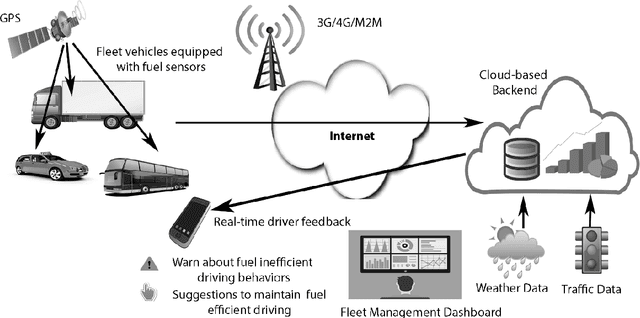
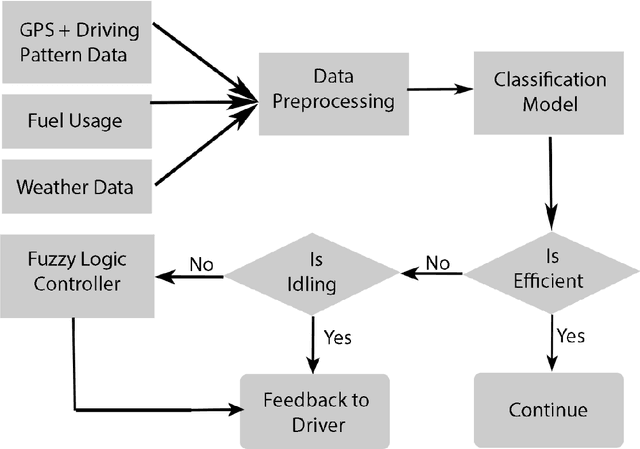
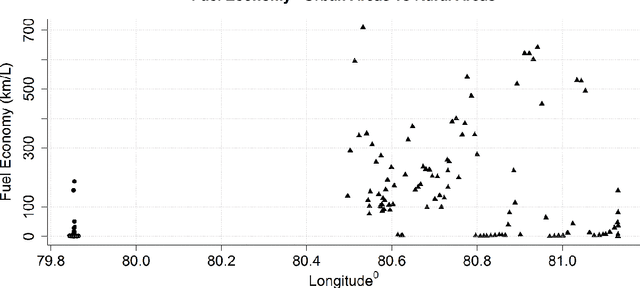
Improving the fuel efficiency of vehicles is imperative to reduce costs and protect the environment. While the efficient engine and vehicle designs, as well as intelligent route planning, are well-known solutions to enhance the fuel efficiency, research has also demonstrated that the adoption of fuel-efficient driving behaviors could lead to further savings. In this work, we propose a novel framework to promote fuel-efficient driving behaviors through real-time automatic monitoring and driver feedback. In this framework, a random-forest based classification model developed using historical data to identifies fuel-inefficient driving behaviors. The classifier considers driver-dependent parameters such as speed and acceleration/deceleration pattern, as well as environmental parameters such as traffic, road topography, and weather to evaluate the fuel efficiency of one-minute driving events. When an inefficient driving action is detected, a fuzzy logic inference system is used to determine what the driver should do to maintain fuel-efficient driving behavior. The decided action is then conveyed to the driver via a smartphone in a non-intrusive manner. Using a dataset from a long-distance bus, we demonstrate that the proposed classification model yields an accuracy of 85.2% while increasing the fuel efficiency up to 16.4%.
Encoder-Decoder Networks for Analyzing Thermal and Power Delivery Networks
Oct 27, 2021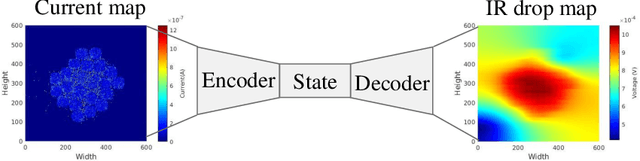
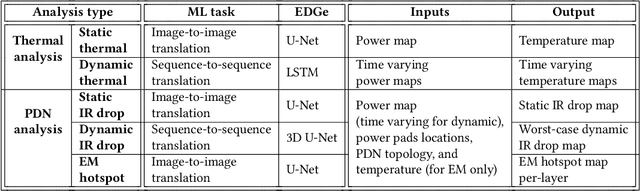
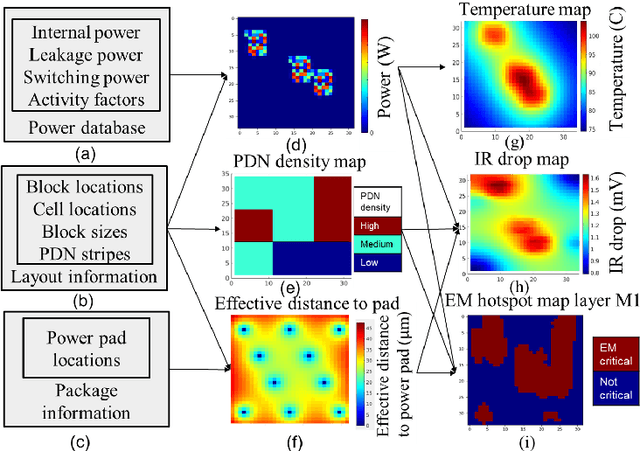
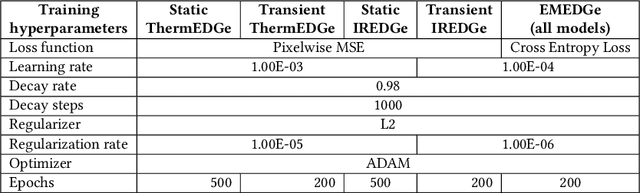
Power delivery network (PDN) analysis and thermal analysis are computationally expensive tasks that are essential for successful IC design. Algorithmically, both these analyses have similar computational structure and complexity as they involve the solution to a partial differential equation of the same form. This paper converts these analyses into image-to-image and sequence-to-sequence translation tasks, which allows leveraging a class of machine learning models with an encoder-decoder-based generative (EDGe) architecture to address the time-intensive nature of these tasks. For PDN analysis, we propose two networks: (i) IREDGe: a full-chip static and dynamic IR drop predictor and (ii) EMEDGe: electromigration (EM) hotspot classifier based on input power, power grid distribution, and power pad distribution patterns. For thermal analysis, we propose ThermEDGe, a full-chip static and dynamic temperature estimator based on input power distribution patterns for thermal analysis. These networks are transferable across designs synthesized within the same technology and packing solution. The networks predict on-chip IR drop, EM hotspot locations, and temperature in milliseconds with negligibly small errors against commercial tools requiring several hours.
Mixed Supervised Object Detection by Transferring Mask Prior and Semantic Similarity
Oct 27, 2021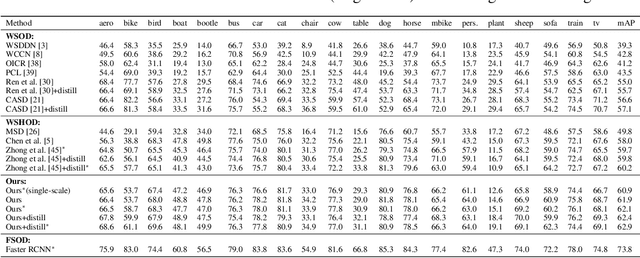
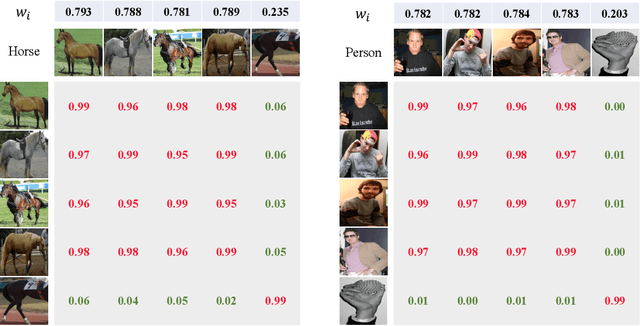
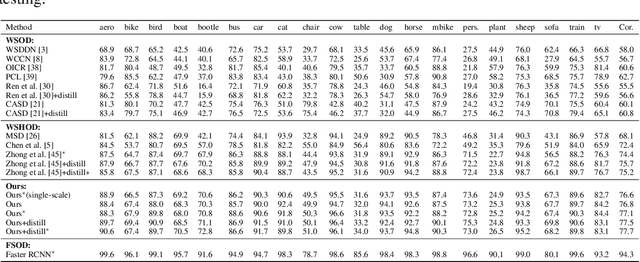

Object detection has achieved promising success, but requires large-scale fully-annotated data, which is time-consuming and labor-extensive. Therefore, we consider object detection with mixed supervision, which learns novel object categories using weak annotations with the help of full annotations of existing base object categories. Previous works using mixed supervision mainly learn the class-agnostic objectness from fully-annotated categories, which can be transferred to upgrade the weak annotations to pseudo full annotations for novel categories. In this paper, we further transfer mask prior and semantic similarity to bridge the gap between novel categories and base categories. Specifically, the ability of using mask prior to help detect objects is learned from base categories and transferred to novel categories. Moreover, the semantic similarity between objects learned from base categories is transferred to denoise the pseudo full annotations for novel categories. Experimental results on three benchmark datasets demonstrate the effectiveness of our method over existing methods. Codes are available at https://github.com/bcmi/TraMaS-Weak-Shot-Object-Detection.
Rheumatoid Arthritis: Automated Scoring of Radiographic Joint Damage
Oct 17, 2021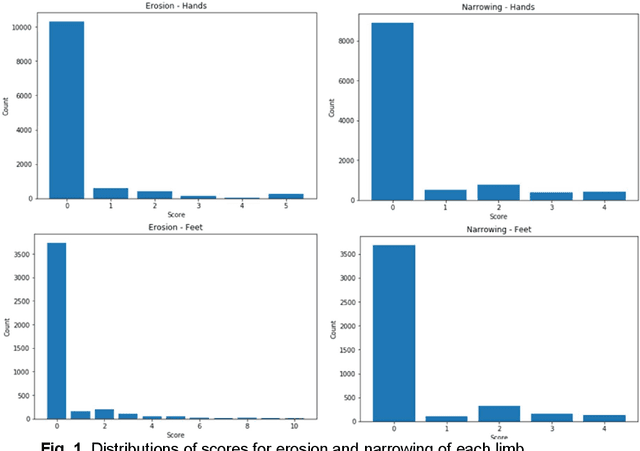

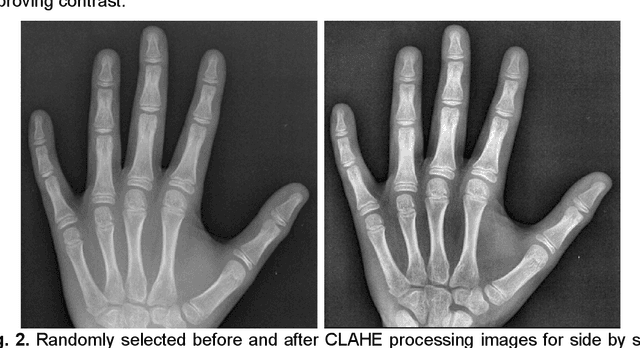
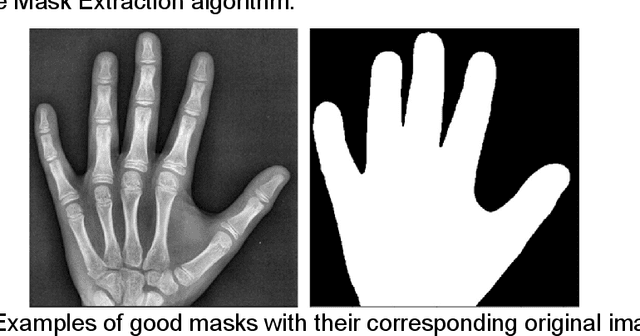
Rheumatoid arthritis is an autoimmune disease that causes joint damage due to inflammation in the soft tissue lining the joints known as the synovium. It is vital to identify joint damage as soon as possible to provide necessary treatment early and prevent further damage to the bone structures. Radiographs are often used to assess the extent of the joint damage. Currently, the scoring of joint damage from the radiograph takes expertise, effort, and time. Joint damage associated with rheumatoid arthritis is also not quantitated in clinical practice and subjective descriptors are used. In this work, we describe a pipeline of deep learning models to automatically identify and score rheumatoid arthritic joint damage from a radiographic image. Our automatic tool was shown to produce scores with extremely high balanced accuracy within a couple of minutes and utilizing this would remove the subjectivity of the scores between human reviewers.
Low-Resource Spoken Language Identification Using Self-Attentive Pooling and Deep 1D Time-Channel Separable Convolutions
May 31, 2021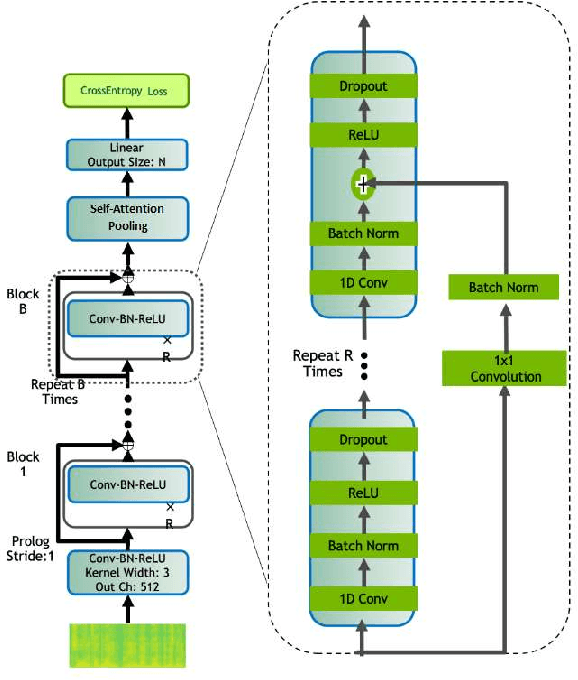

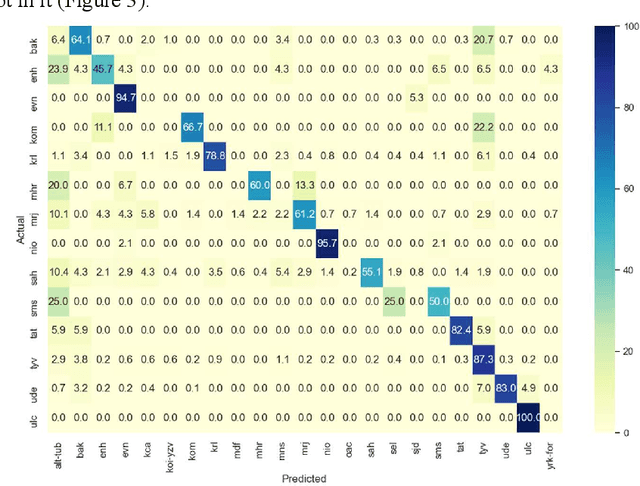
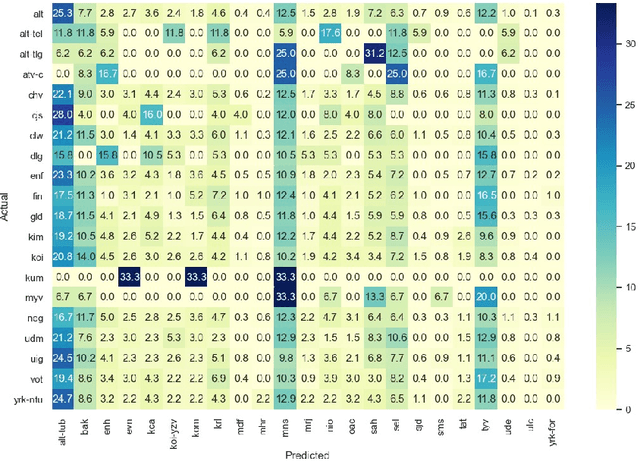
This memo describes NTR/TSU winning submission for Low Resource ASR challenge at Dialog2021 conference, language identification track. Spoken Language Identification (LID) is an important step in a multilingual Automated Speech Recognition (ASR) system pipeline. Traditionally, the ASR task requires large volumes of labeled data that are unattainable for most of the world's languages, including most of the languages of Russia. In this memo, we show that a convolutional neural network with a Self-Attentive Pooling layer shows promising results in low-resource setting for the language identification task and set up a SOTA for the Low Resource ASR challenge dataset. Additionally, we compare the structure of confusion matrices for this and significantly more diverse VoxForge dataset and state and substantiate the hypothesis that whenever the dataset is diverse enough so that the other classification factors, like gender, age etc. are well-averaged, the confusion matrix for LID system bears the language similarity measure.
Investigating Entropy for Extractive Document Summarization
Sep 22, 2021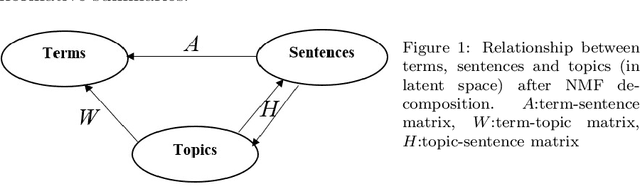

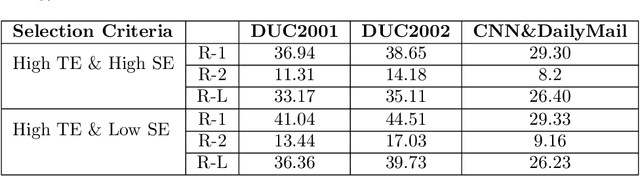
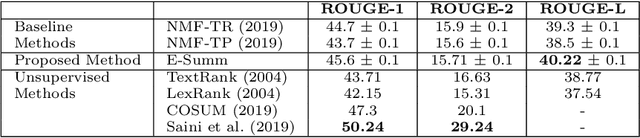
Automatic text summarization aims to cut down readers time and cognitive effort by reducing the content of a text document without compromising on its essence. Ergo, informativeness is the prime attribute of document summary generated by an algorithm, and selecting sentences that capture the essence of a document is the primary goal of extractive document summarization. In this paper, we employ Shannon entropy to capture informativeness of sentences. We employ Non-negative Matrix Factorization (NMF) to reveal probability distributions for computing entropy of terms, topics, and sentences in latent space. We present an information theoretic interpretation of the computed entropy, which is the bedrock of the proposed E-Summ algorithm, an unsupervised method for extractive document summarization. The algorithm systematically applies information theoretic principle for selecting informative sentences from important topics in the document. The proposed algorithm is generic and fast, and hence amenable to use for summarization of documents in real time. Furthermore, it is domain-, collection-independent and agnostic to the language of the document. Benefiting from strictly positive NMF factor matrices, E-Summ algorithm is transparent and explainable too. We use standard ROUGE toolkit for performance evaluation of the proposed method on four well known public data-sets. We also perform quantitative assessment of E-Summ summary quality by computing its semantic similarity w.r.t the original document. Our investigation reveals that though using NMF and information theoretic approach for document summarization promises efficient, explainable, and language independent text summarization, it needs to be bolstered to match the performance of deep neural methods.