 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Text Temperature
Jan 05, 2026Autoregressive language models typically use temperature parameter at inference to shape the probability distribution and control the randomness of the text generated. After the text was generated, this parameter can be estimated using maximum likelihood approach. Following it, we propose a procedure to estimate the temperature of any text, including ones written by humans, with respect to a given language model. We evaluate the temperature estimation capability of a wide selection of small-to-medium LLMs. We then use the best-performing Qwen3 14B to estimate temperatures of popular corpora.
States of LLM-generated Texts and Phase Transitions between them
Mar 08, 2025It is known for some time that autocorrelations of words in human-written texts decay according to a power law. Recent works have also shown that the autocorrelations decay in texts generated by LLMs is qualitatively different from the literary texts. Solid state physics tie the autocorrelations decay laws to the states of matter. In this work, we empirically demonstrate that, depending on the temperature parameter, LLMs can generate text that can be classified as solid, critical state or gas.
Long Text Generation Challenge
Jun 04, 2023We propose a shared task of human-like long text generation, LTG Challenge, that asks models to output a consistent human-like long text (a Harry Potter generic audience fanfic in English), given a prompt of about 1000 tokens. We suggest a novel statistical metric of the text structuredness, GloVe Autocorrelations Power/ Exponential Law Mean Absolute Percentage Error Ratio (GAPELMAPER) and a human evaluation protocol. We hope that LTG can open new avenues for researchers to investigate sampling approaches, prompting strategies, autoregressive and non-autoregressive text generation architectures and break the barrier to generate consistent long (40K+ token) texts.
Autocorrelations Decay in Texts and Applicability Limits of Language Models
May 11, 2023We show that the laws of autocorrelations decay in texts are closely related to applicability limits of language models. Using distributional semantics we empirically demonstrate that autocorrelations of words in texts decay according to a power law. We show that distributional semantics provides coherent autocorrelations decay exponents for texts translated to multiple languages. The autocorrelations decay in generated texts is quantitatively and often qualitatively different from the literary texts. We conclude that language models exhibiting Markov behavior, including large autoregressive language models, may have limitations when applied to long texts, whether analysis or generation.
On Unsupervised Training of Link Grammar Based Language Models
Aug 27, 2022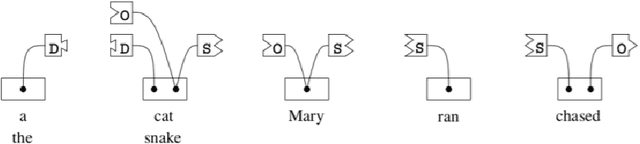
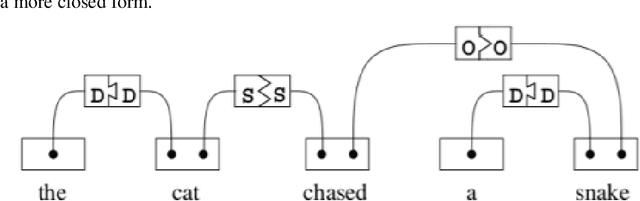
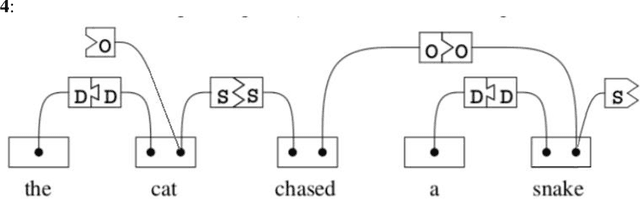
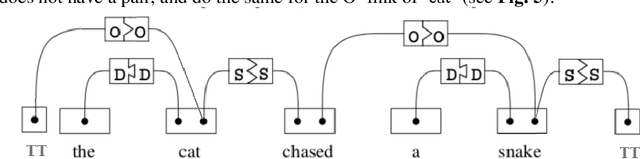
In this short note we explore what is needed for the unsupervised training of graph language models based on link grammars. First, we introduce the ter-mination tags formalism required to build a language model based on a link grammar formalism of Sleator and Temperley [21] and discuss the influence of context on the unsupervised learning of link grammars. Second, we pro-pose a statistical link grammar formalism, allowing for statistical language generation. Third, based on the above formalism, we show that the classical dissertation of Yuret [25] on discovery of linguistic relations using lexical at-traction ignores contextual properties of the language, and thus the approach to unsupervised language learning relying just on bigrams is flawed. This correlates well with the unimpressive results in unsupervised training of graph language models based on bigram approach of Yuret.
Lib-SibGMU -- A University Library Circulation Dataset for Recommender Systems Developmen
Aug 25, 2022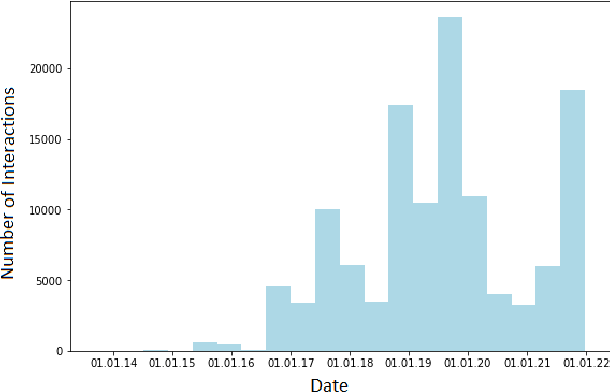
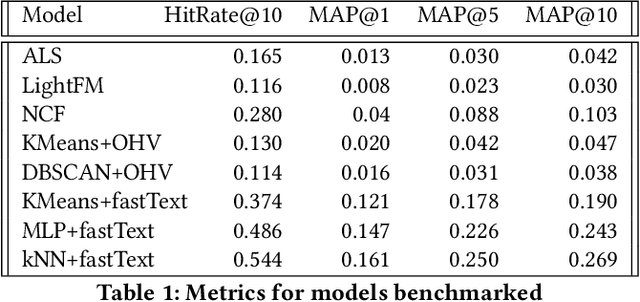
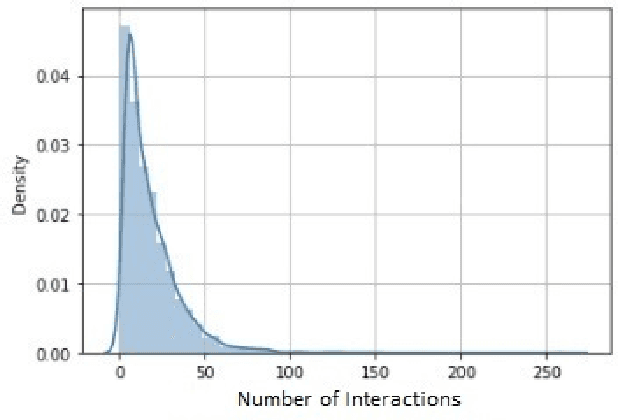
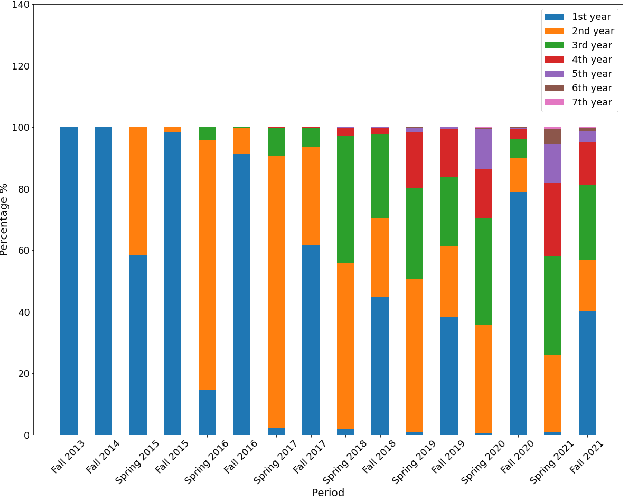
We opensource under CC BY 4.0 license Lib-SibGMU - a university library circulation dataset - for a wide research community, and benchmark major algorithms for recommender systems on this dataset. For a recommender architecture that consists of a vectorizer that turns the history of the books borrowed into a vector, and a neighborhood-based recommender, trained separately, we show that using the fastText model as a vectorizer delivers competitive results.
Using a Language Model in a Kiosk Recommender System at Fast-Food Restaurants
Feb 08, 2022

Kiosks are a popular self-service option in many fast-food restaurants, they save time for the visitors and save labor for the fast-food chains. In this paper, we propose an effective design of a kiosk shopping cart recommender system that combines a language model as a vectorizer and a neural network-based classifier. The model performs better than other models in offline tests and exhibits performance comparable to the best models in A/B/C tests.
Low-Resource Spoken Language Identification Using Self-Attentive Pooling and Deep 1D Time-Channel Separable Convolutions
May 31, 2021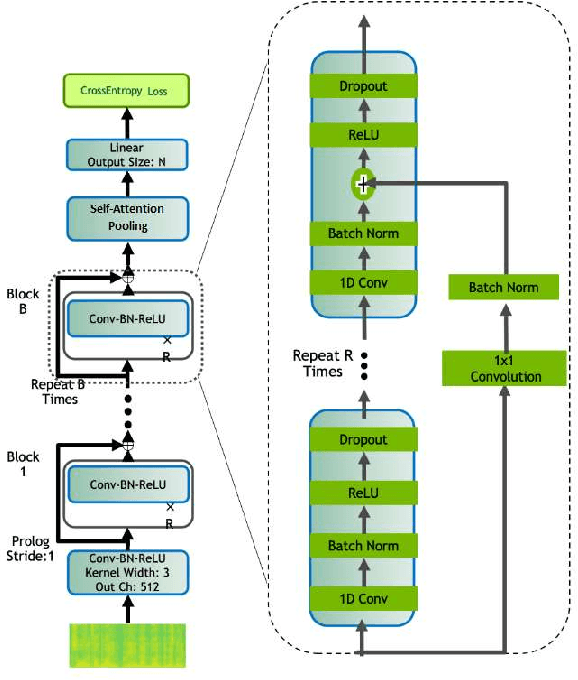

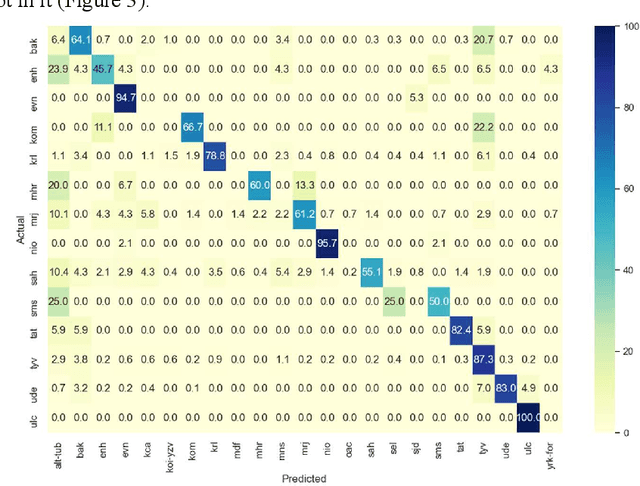
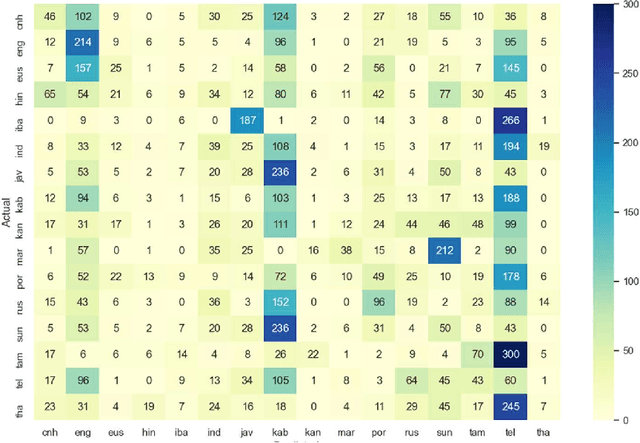
This memo describes NTR/TSU winning submission for Low Resource ASR challenge at Dialog2021 conference, language identification track. Spoken Language Identification (LID) is an important step in a multilingual Automated Speech Recognition (ASR) system pipeline. Traditionally, the ASR task requires large volumes of labeled data that are unattainable for most of the world's languages, including most of the languages of Russia. In this memo, we show that a convolutional neural network with a Self-Attentive Pooling layer shows promising results in low-resource setting for the language identification task and set up a SOTA for the Low Resource ASR challenge dataset. Additionally, we compare the structure of confusion matrices for this and significantly more diverse VoxForge dataset and state and substantiate the hypothesis that whenever the dataset is diverse enough so that the other classification factors, like gender, age etc. are well-averaged, the confusion matrix for LID system bears the language similarity measure.
Language ID Prediction from Speech Using Self-Attentive Pooling and 1D-Convolutions
Apr 24, 2021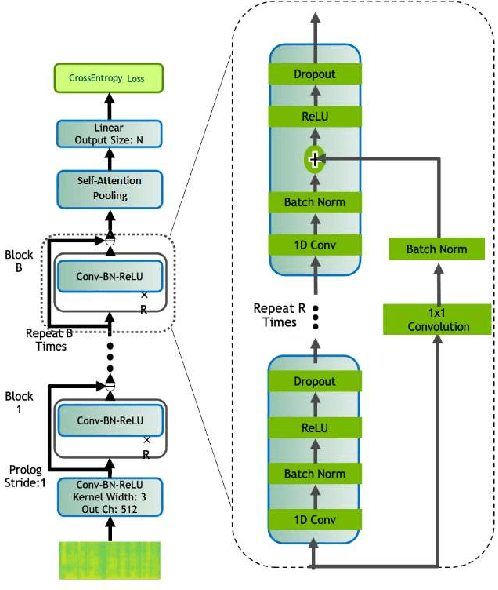
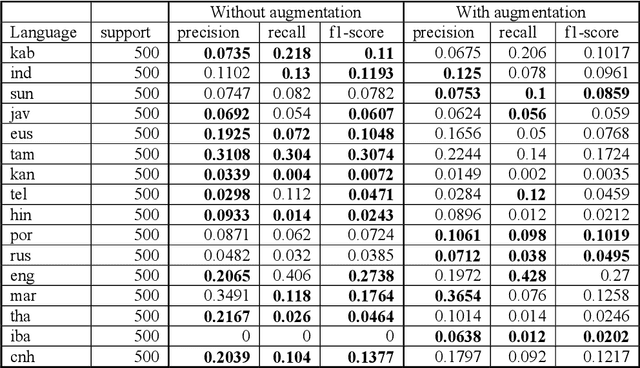
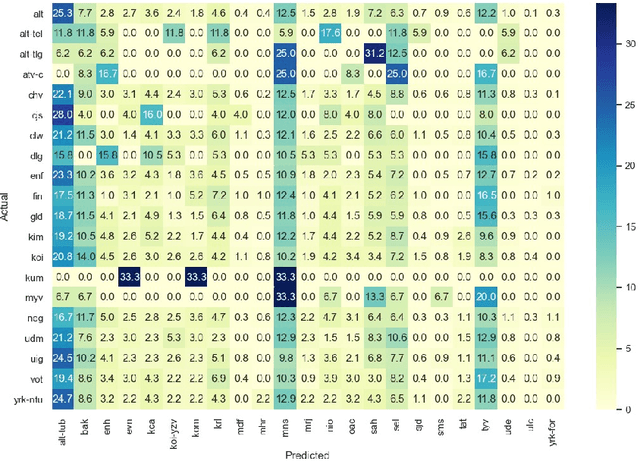
This memo describes NTR-TSU submission for SIGTYP 2021 Shared Task on predicting language IDs from speech. Spoken Language Identification (LID) is an important step in a multilingual Automated Speech Recognition (ASR) system pipeline. For many low-resource and endangered languages, only single-speaker recordings may be available, demanding a need for domain and speaker-invariant language ID systems. In this memo, we show that a convolutional neural network with a Self-Attentive Pooling layer shows promising results for the language identification task.
MediaSpeech: Multilanguage ASR Benchmark and Dataset
Mar 30, 2021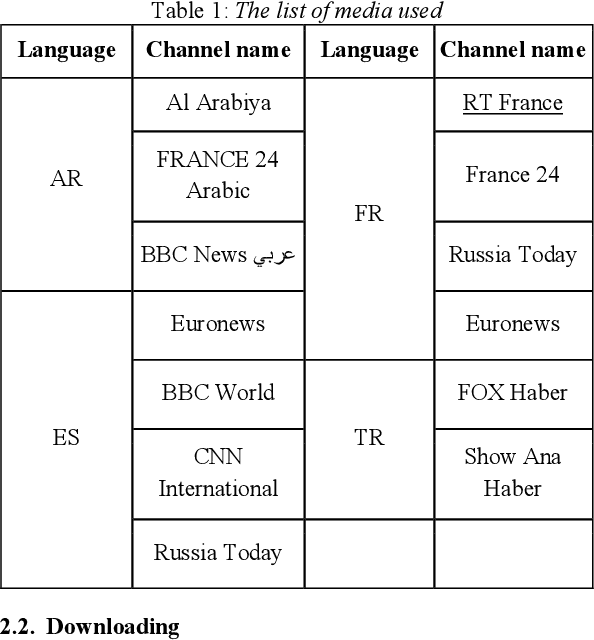
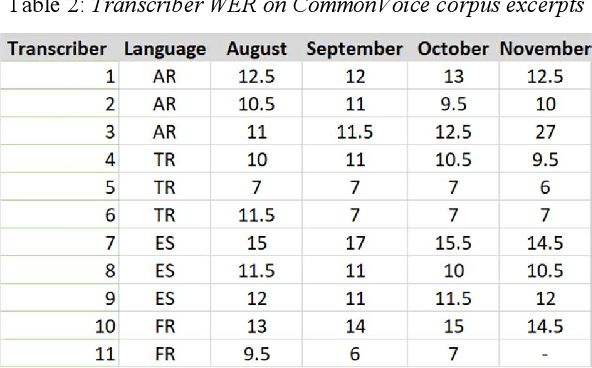
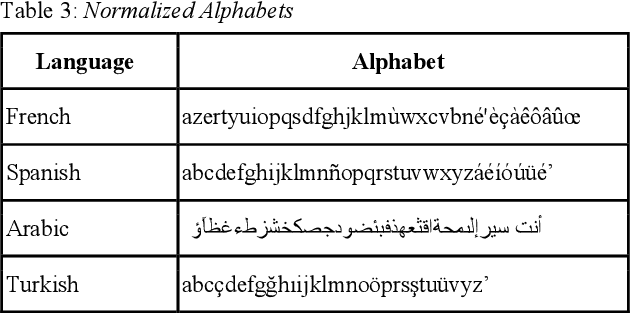
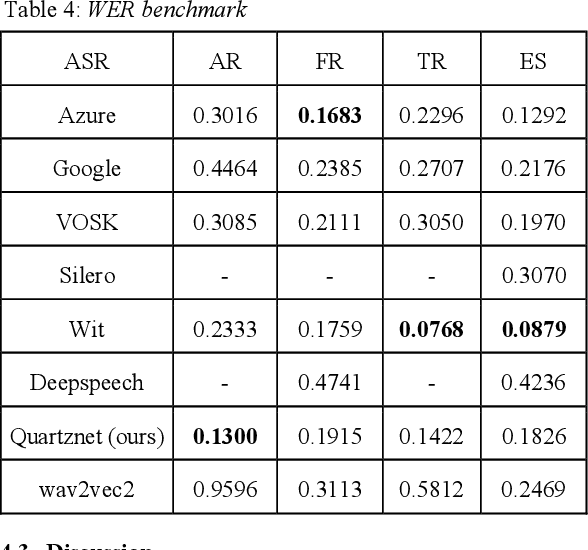
The performance of automated speech recognition (ASR) systems is well known to differ for varied application domains. At the same time, vendors and research groups typically report ASR quality results either for limited use simplistic domains (audiobooks, TED talks), or proprietary datasets. To fill this gap, we provide an open-source 10-hour ASR system evaluation dataset NTR MediaSpeech for 4 languages: Spanish, French, Turkish and Arabic. The dataset was collected from the official youtube channels of media in the respective languages, and manually transcribed. We estimate that the WER of the dataset is under 5%. We have benchmarked many ASR systems available both commercially and freely, and provide the benchmark results. We also open-source baseline QuartzNet models for each language.