 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Spoken Language Identification Using Self-Attentive Pooling and Deep 1D Time-Channel Separable Convolutions
May 31, 2021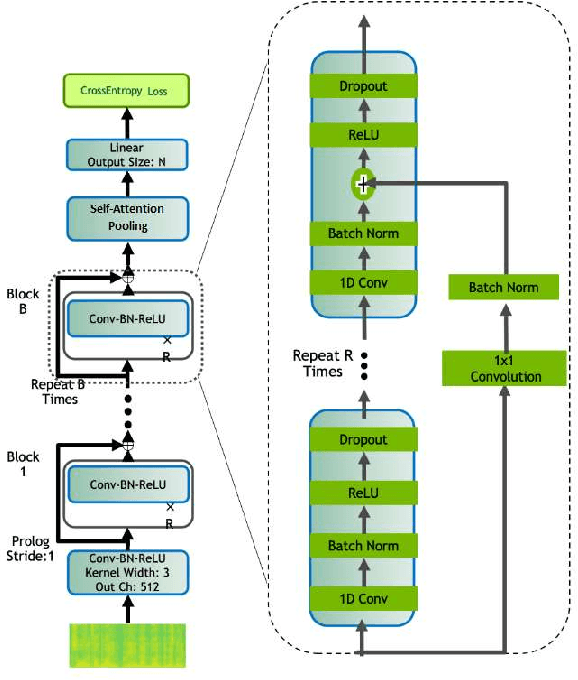

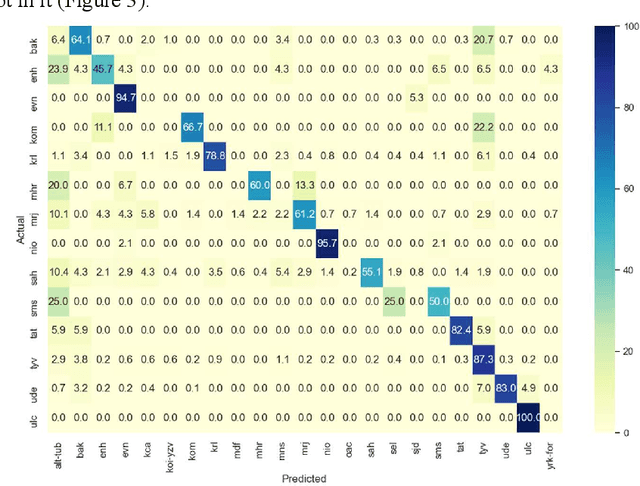
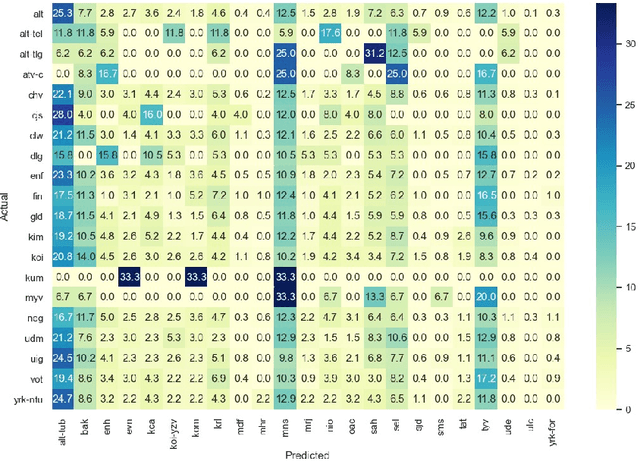
This memo describes NTR/TSU winning submission for Low Resource ASR challenge at Dialog2021 conference, language identification track. Spoken Language Identification (LID) is an important step in a multilingual Automated Speech Recognition (ASR) system pipeline. Traditionally, the ASR task requires large volumes of labeled data that are unattainable for most of the world's languages, including most of the languages of Russia. In this memo, we show that a convolutional neural network with a Self-Attentive Pooling layer shows promising results in low-resource setting for the language identification task and set up a SOTA for the Low Resource ASR challenge dataset. Additionally, we compare the structure of confusion matrices for this and significantly more diverse VoxForge dataset and state and substantiate the hypothesis that whenever the dataset is diverse enough so that the other classification factors, like gender, age etc. are well-averaged, the confusion matrix for LID system bears the language similarity measure.
Language ID Prediction from Speech Using Self-Attentive Pooling and 1D-Convolutions
Apr 24, 2021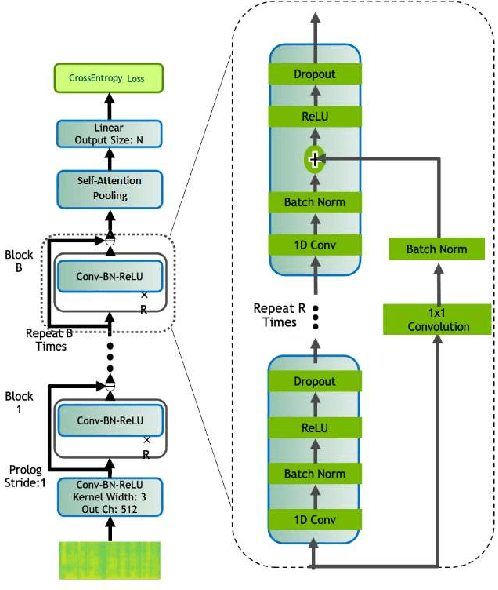
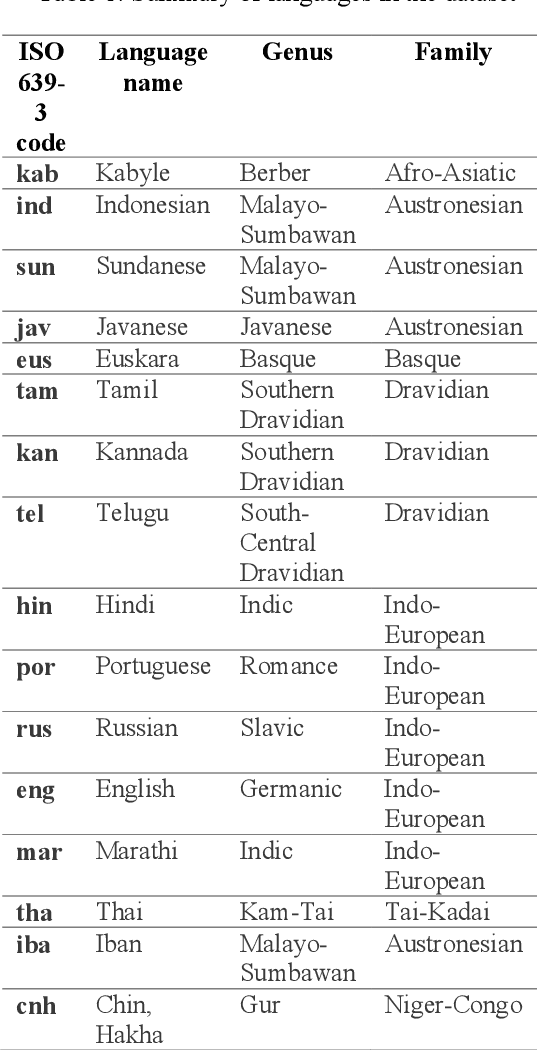
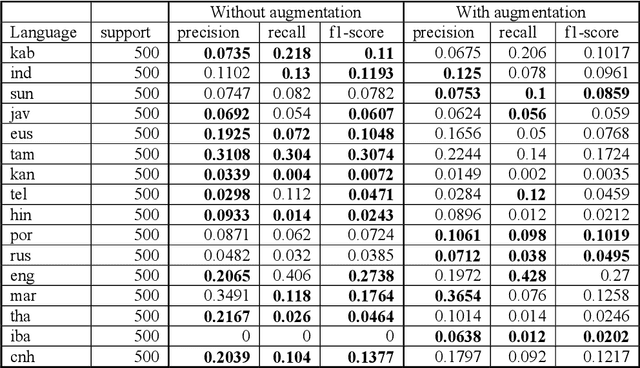
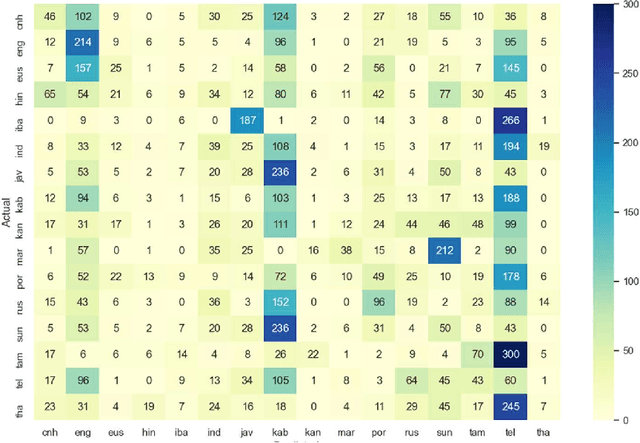
This memo describes NTR-TSU submission for SIGTYP 2021 Shared Task on predicting language IDs from speech. Spoken Language Identification (LID) is an important step in a multilingual Automated Speech Recognition (ASR) system pipeline. For many low-resource and endangered languages, only single-speaker recordings may be available, demanding a need for domain and speaker-invariant language ID systems. In this memo, we show that a convolutional neural network with a Self-Attentive Pooling layer shows promising results for the language identification task.
MediaSpeech: Multilanguage ASR Benchmark and Dataset
Mar 30, 2021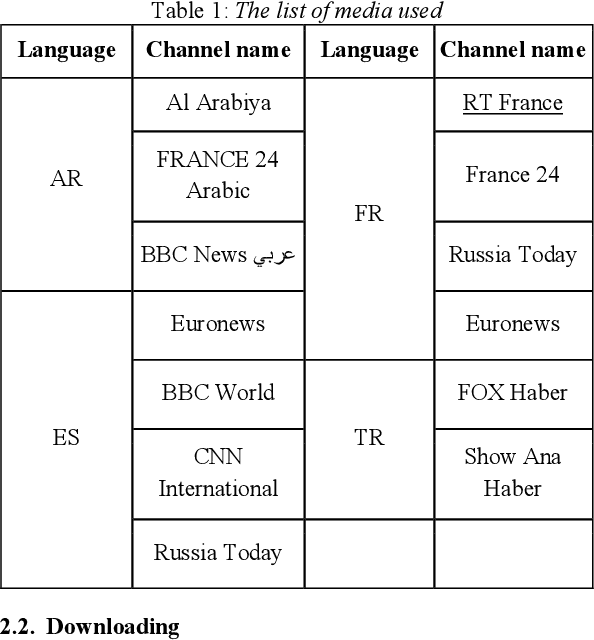
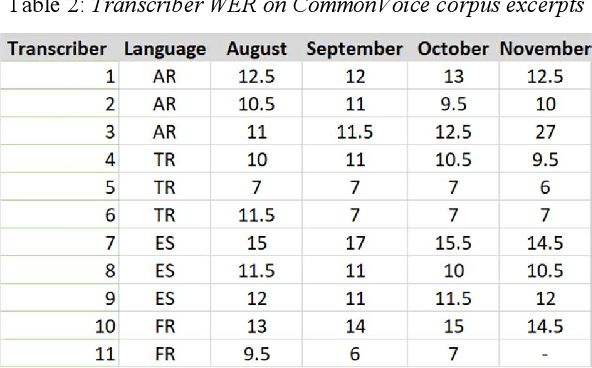
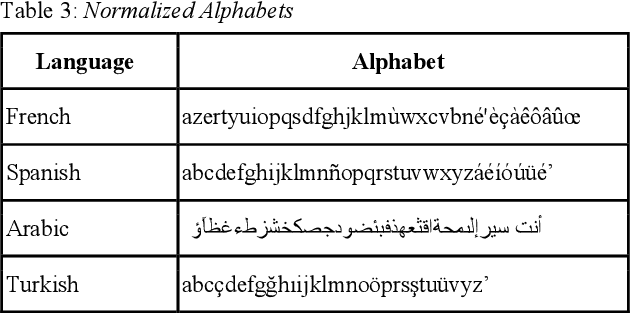
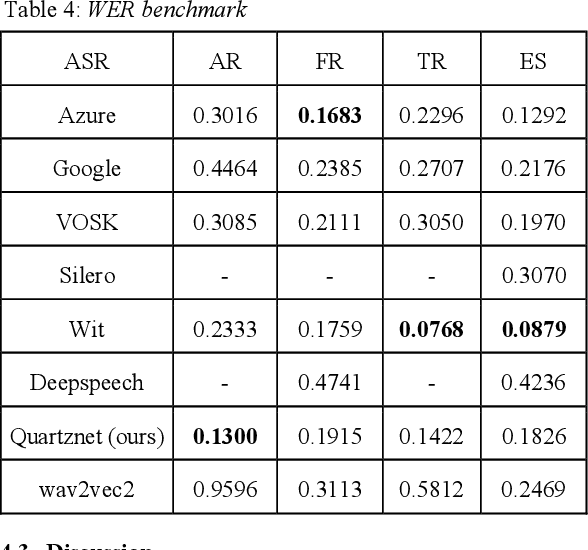
The performance of automated speech recognition (ASR) systems is well known to differ for varied application domains. At the same time, vendors and research groups typically report ASR quality results either for limited use simplistic domains (audiobooks, TED talks), or proprietary datasets. To fill this gap, we provide an open-source 10-hour ASR system evaluation dataset NTR MediaSpeech for 4 languages: Spanish, French, Turkish and Arabic. The dataset was collected from the official youtube channels of media in the respective languages, and manually transcribed. We estimate that the WER of the dataset is under 5%. We have benchmarked many ASR systems available both commercially and freely, and provide the benchmark results. We also open-source baseline QuartzNet models for each language.