 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Finite-time Identification of Stable Linear Systems: Optimality of the Least-Squares Estimator
Mar 17, 2020
We provide a new finite-time analysis of the estimation error of stable linear time-invariant systems under the Ordinary Least Squares (OLS) estimator. Specifically, we characterize the sufficient number of observed samples (the length of the observed trajectory) so that the OLS is $(\varepsilon,\delta)$-PAC, i.e. yields an estimation error less than $\varepsilon$ with probability at least $1-\delta$. We show that this number matches existing sample complexity lower bound [1,2] up to universal multiplicative factors (independent of ($\varepsilon,\delta)$, of the system and of the dimension). This paper hence establishes the optimality of the OLS estimator for stable systems, a result conjectured in [1]. Our analysis of the performance of the OLS estimator is simpler, sharper, and easier to interpret than existing analyses, but is restricted to stable systems. It relies on new concentration results for the covariates matrix.
Turn-to-Diarize: Online Speaker Diarization Constrained by Transformer Transducer Speaker Turn Detection
Oct 05, 2021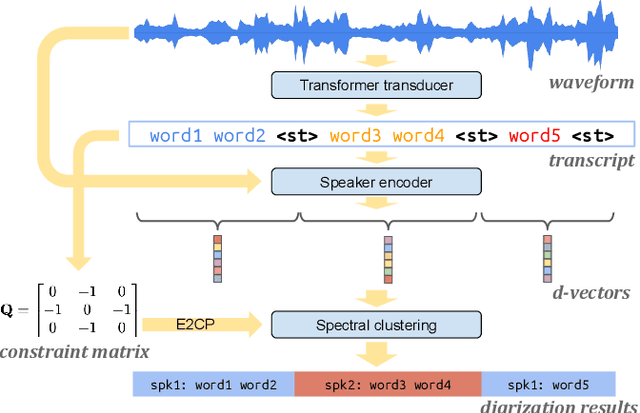

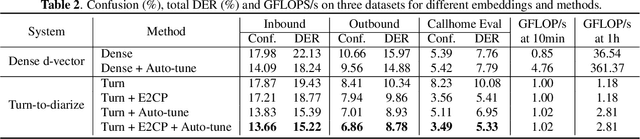
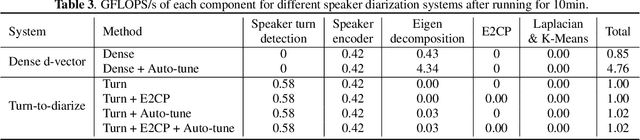
In this paper, we present a novel speaker diarization system for streaming on-device applications. In this system, we use a transformer transducer to detect the speaker turns, represent each speaker turn by a speaker embedding, then cluster these embeddings with constraints from the detected speaker turns. Compared with conventional clustering-based diarization systems, our system largely reduces the computational cost of clustering due to the sparsity of speaker turns. Unlike other supervised speaker diarization systems which require annotations of time-stamped speaker labels for training, our system only requires including speaker turn tokens during the transcribing process, which largely reduces the human efforts involved in data collection.
Wavelet Selection and Employment for Side-Channel Disassembly
Jul 25, 2021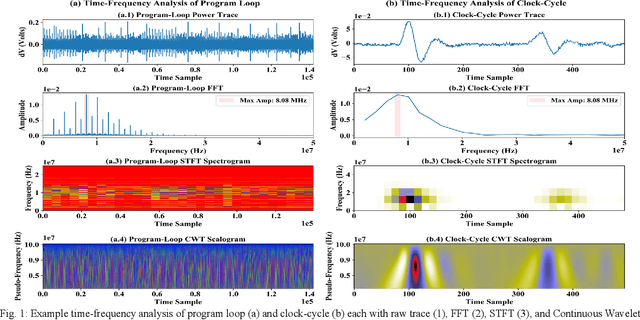
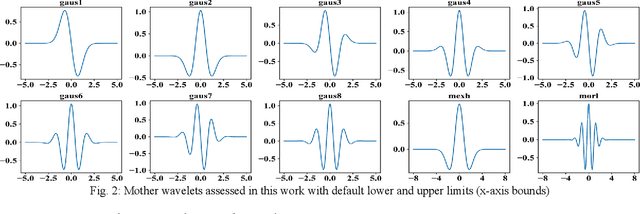
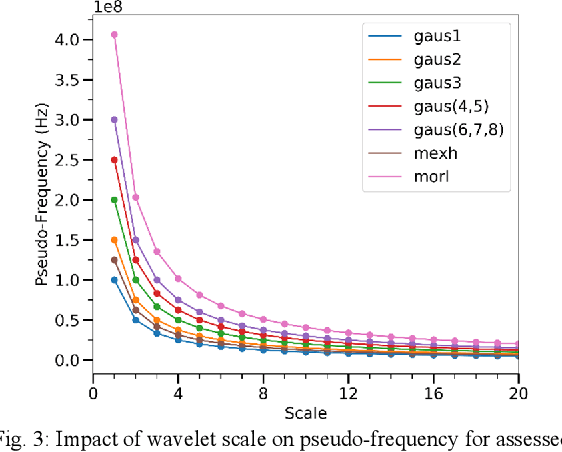
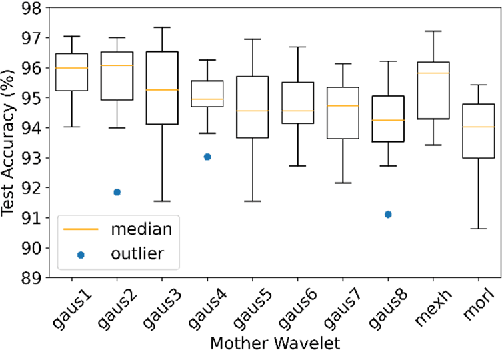
Side-channel analysis, originally used in cryptanalysis is growing in use cases, both offensive and defensive. Wavelet analysis is a commonly employed time-frequency analysis technique used across disciplines, with a variety of purposes, and has shown increasing prevalence within side-channel literature. This paper explores wavelet selection and analysis parameters for use in side-channel analysis, particularly power side-channel-based instruction disassembly and classification. Experiments are conducted on an ATmega328P microcontroller and a subset of the AVR instruction set. Classification performance is evaluated with a time-series convolutional neural network (CNN) at clock-cycle fidelity. This work demonstrates that wavelet selection and employment parameters have meaningful impact on analysis outcomes. Practitioners should make informed decisions and consider optimizing these factors similarly to machine learning architecture and hyperparameters. We conclude that the gaus1 wavelet with scales 1-21 and grayscale colormap provided the best balance of classification performance, time, and memory efficiency in our application.
Neural Human Performer: Learning Generalizable Radiance Fields for Human Performance Rendering
Sep 15, 2021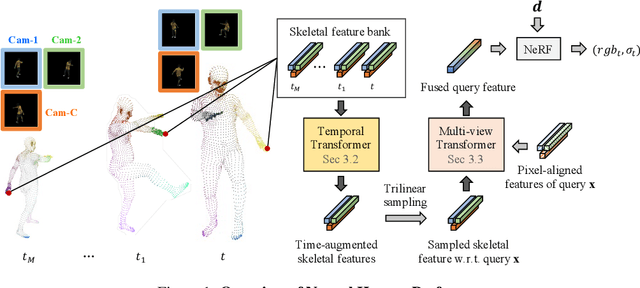
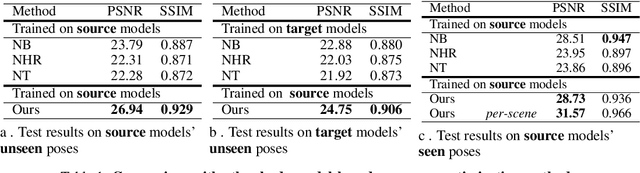


In this paper, we aim at synthesizing a free-viewpoint video of an arbitrary human performance using sparse multi-view cameras. Recently, several works have addressed this problem by learning person-specific neural radiance fields (NeRF) to capture the appearance of a particular human. In parallel, some work proposed to use pixel-aligned features to generalize radiance fields to arbitrary new scenes and objects. Adopting such generalization approaches to humans, however, is highly challenging due to the heavy occlusions and dynamic articulations of body parts. To tackle this, we propose Neural Human Performer, a novel approach that learns generalizable neural radiance fields based on a parametric human body model for robust performance capture. Specifically, we first introduce a temporal transformer that aggregates tracked visual features based on the skeletal body motion over time. Moreover, a multi-view transformer is proposed to perform cross-attention between the temporally-fused features and the pixel-aligned features at each time step to integrate observations on the fly from multiple views. Experiments on the ZJU-MoCap and AIST datasets show that our method significantly outperforms recent generalizable NeRF methods on unseen identities and poses. The video results and code are available at https://youngjoongunc.github.io/nhp.
FAST: Searching for a Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation
Nov 03, 2021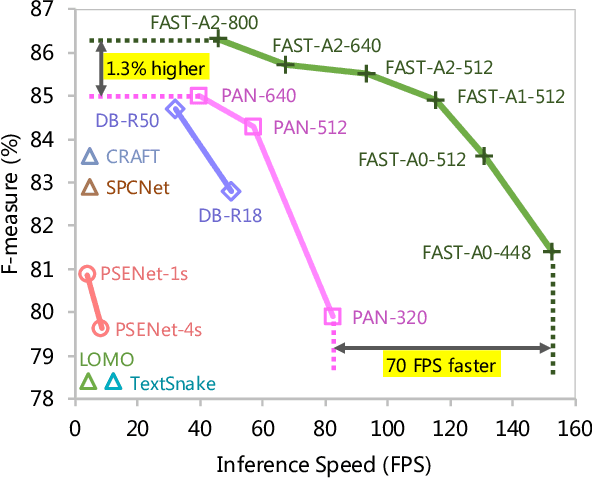
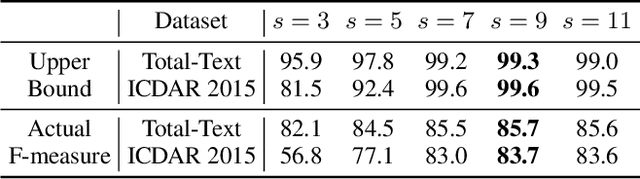
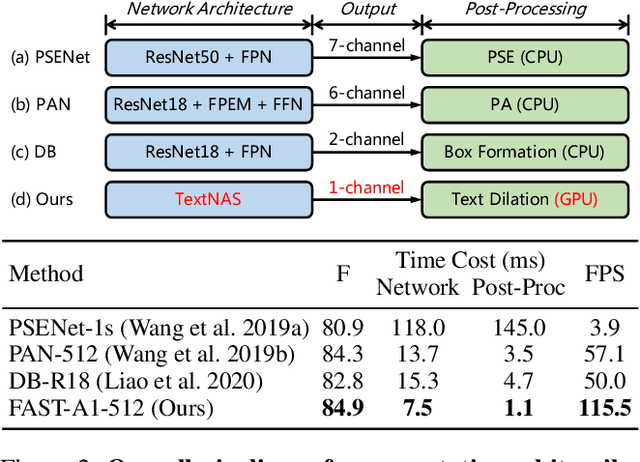
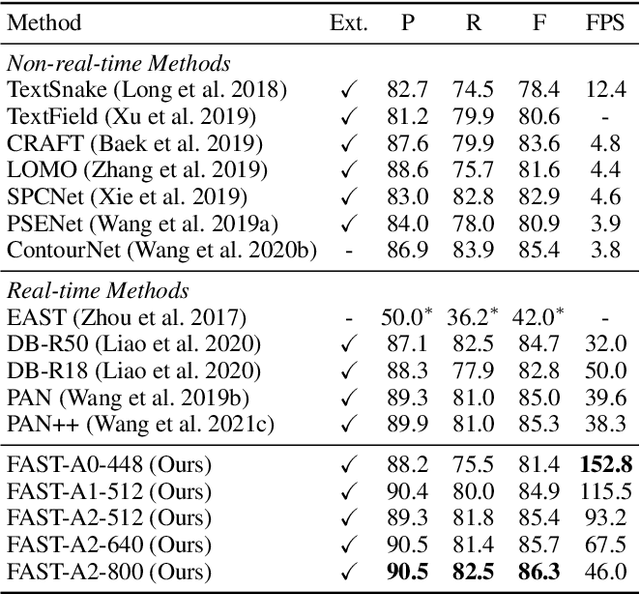
We propose an accurate and efficient scene text detection framework, termed FAST (i.e., faster arbitrarily-shaped text detector). Different from recent advanced text detectors that used hand-crafted network architectures and complicated post-processing, resulting in low inference speed, FAST has two new designs. (1) We search the network architecture by designing a network search space and reward function carefully tailored for text detection, leading to more powerful features than most networks that are searched for image classification. (2) We design a minimalist representation (only has 1-channel output) to model text with arbitrary shape, as well as a GPU-parallel post-processing to efficiently assemble text lines with negligible time overhead. Benefiting from these two designs, FAST achieves an excellent trade-off between accuracy and efficiency on several challenging datasets. For example, FAST-A0 yields 81.4% F-measure at 152 FPS on Total-Text, outperforming the previous fastest method by 1.5 points and 70 FPS in terms of accuracy and speed. With TensorRT optimization, the inference speed can be further accelerated to over 600 FPS.
Quantum Semi-Supervised Learning with Quantum Supremacy
Oct 05, 2021Quantum machine learning promises to efficiently solve important problems. There are two persistent challenges in classical machine learning: the lack of labeled data, and the limit of computational power. We propose a novel framework that resolves both issues: quantum semi-supervised learning. Moreover, we provide a protocol in systematically designing quantum machine learning algorithms with quantum supremacy, which can be extended beyond quantum semi-supervised learning. We showcase two concrete quantum semi-supervised learning algorithms: a quantum self-training algorithm named the propagating nearest-neighbor classifier, and the quantum semi-supervised K-means clustering algorithm. By doing time complexity analysis, we conclude that they indeed possess quantum supremacy.
Common Information based Approximate State Representations in Multi-Agent Reinforcement Learning
Oct 25, 2021Due to information asymmetry, finding optimal policies for Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs) is hard with the complexity growing doubly exponentially in the horizon length. The challenge increases greatly in the multi-agent reinforcement learning (MARL) setting where the transition probabilities, observation kernel, and reward function are unknown. Here, we develop a general compression framework with approximate common and private state representations, based on which decentralized policies can be constructed. We derive the optimality gap of executing dynamic programming (DP) with the approximate states in terms of the approximation error parameters and the remaining time steps. When the compression is exact (no error), the resulting DP is equivalent to the one in existing work. Our general framework generalizes a number of methods proposed in the literature. The results shed light on designing practically useful deep-MARL network structures under the "centralized learning distributed execution" scheme.
Survival Function Matching for Calibrated Time-to-Event Predictions
May 21, 2019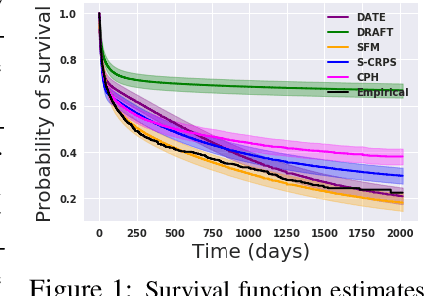
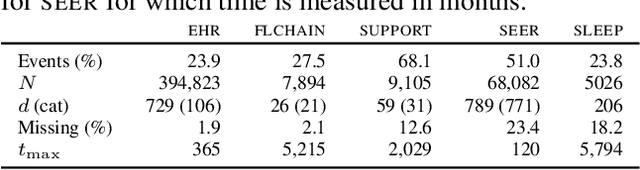
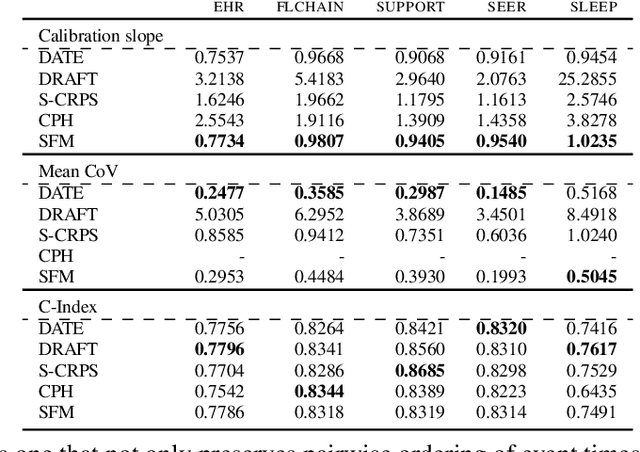
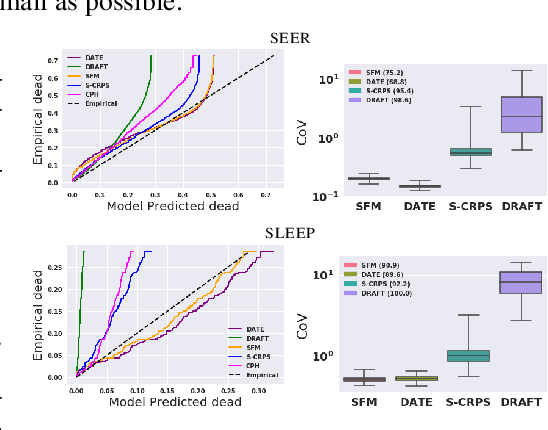
Models for predicting the time of a future event are crucial for risk assessment, across a diverse range of applications. Existing time-to-event (survival) models have focused primarily on preserving pairwise ordering of estimated event times, or relative risk. Model calibration is relatively under explored, despite its critical importance in time-to-event applications. We present a survival function estimator for probabilistic predictions in time-to-event models, based on a neural network model for draws from the distribution of event times, without explicit assumptions on the form of the distribution. This is done like in adversarial learning, but we achieve learning without a discriminator or adversarial objective. The proposed estimator can be used in practice as a means of estimating and comparing conditional survival distributions, while accounting for the predictive uncertainty of probabilistic models. Extensive experiments show that the proposed model outperforms existing approaches, trained both with and without adversarial learning, in terms of both calibration and concentration of time-to-event distributions.
AEGIS: A real-time multimodal augmented reality computer vision based system to assist facial expression recognition for individuals with autism spectrum disorder
Oct 22, 2020The ability to interpret social cues comes naturally for most people, but for those living with Autism Spectrum Disorder (ASD), some experience a deficiency in this area. This paper presents the development of a multimodal augmented reality (AR) system which combines the use of computer vision and deep convolutional neural networks (CNN) in order to assist individuals with the detection and interpretation of facial expressions in social settings. The proposed system, which we call AEGIS (Augmented-reality Expression Guided Interpretation System), is an assistive technology deployable on a variety of user devices including tablets, smartphones, video conference systems, or smartglasses, showcasing its extreme flexibility and wide range of use cases, to allow integration into daily life with ease. Given a streaming video camera source, each real-world frame is passed into AEGIS, processed for facial bounding boxes, and then fed into our novel deep convolutional time windowed neural network (TimeConvNet). We leverage both spatial and temporal information in order to provide an accurate expression prediction, which is then converted into its corresponding visualization and drawn on top of the original video frame. The system runs in real-time, requires minimal set up and is simple to use. With the use of AEGIS, we can assist individuals living with ASD to learn to better identify expressions and thus improve their social experiences.
Deciphering Environmental Air Pollution with Large Scale City Data
Sep 09, 2021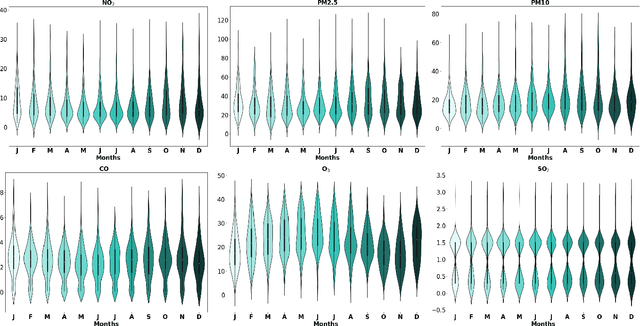
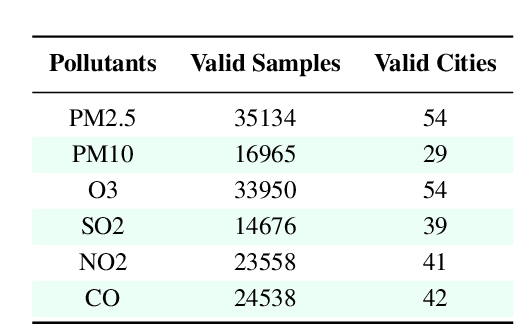
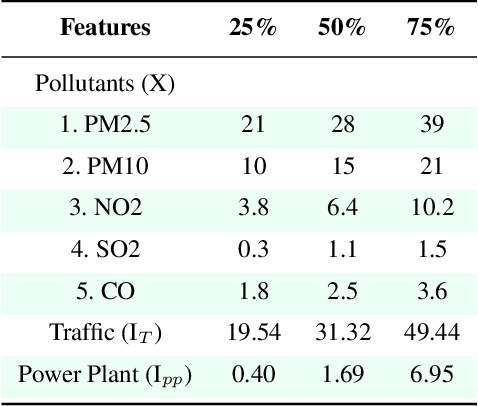
Out of the numerous hazards posing a threat to sustainable environmental conditions in the 21st century, only a few have a graver impact than air pollution. Its importance in determining the health and living standards in urban settings is only expected to increase with time. Various factors ranging from emissions from traffic and power plants, household emissions, natural causes are known to be primary causal agents or influencers behind rising air pollution levels. However, the lack of large scale data involving the major factors has hindered the research on the causes and relations governing the variability of the different air pollutants. Through this work, we introduce a large scale city-wise dataset for exploring the relationships among these agents over a long period of time. We analyze and explore the dataset to bring out inferences which we can derive by modeling the data. Also, we provide a set of benchmarks for the problem of estimating or forecasting pollutant levels with a set of diverse models and methodologies. Through our paper, we seek to provide a ground base for further research into this domain that will demand critical attention of ours in the near future.