 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Average-based Robustness for Continuous-Time Signal Temporal Logic
Sep 03, 2019
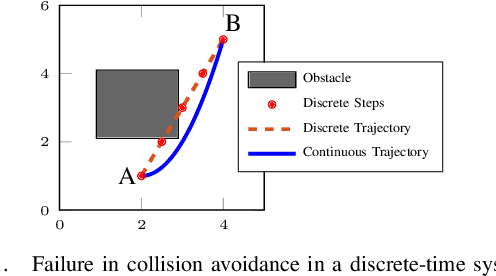
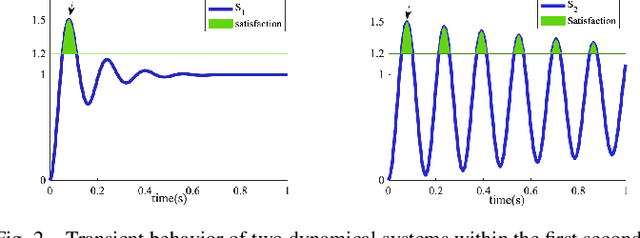
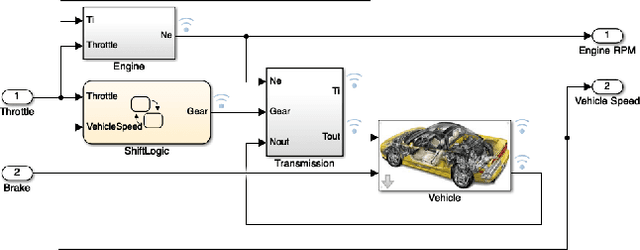
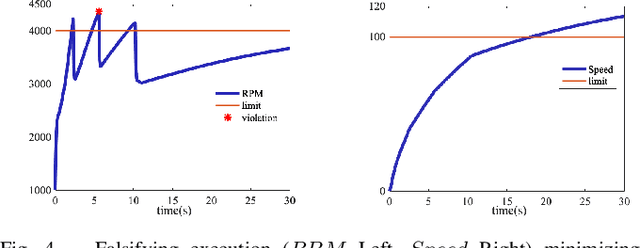
We propose a new robustness score for continuous-time Signal Temporal Logic (STL) specifications. Instead of considering only the most severe point along the evolution of the signal, we use average scores to extract more information from the signal, emphasizing robust satisfaction of all the specifications' subformulae over their entire time interval domains. We demonstrate the advantages of this new score in falsification and control synthesis problems in systems with complex dynamics and multi-agent systems.
Gated2Gated: Self-Supervised Depth Estimation from Gated Images
Dec 04, 2021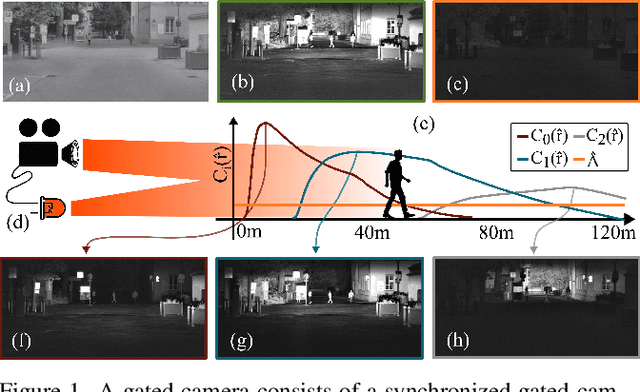
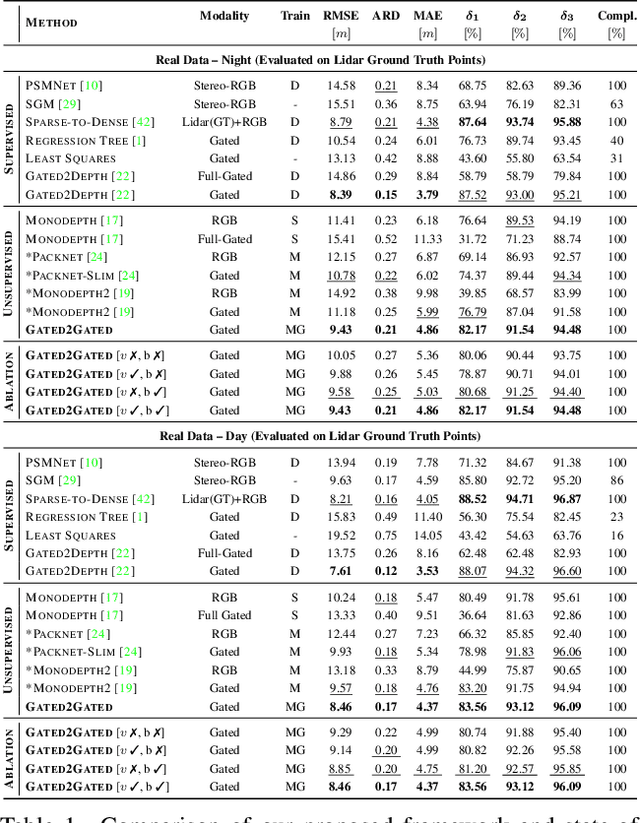
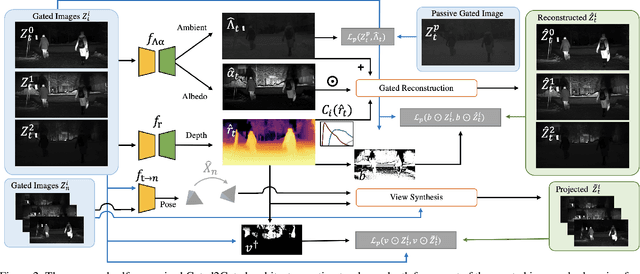
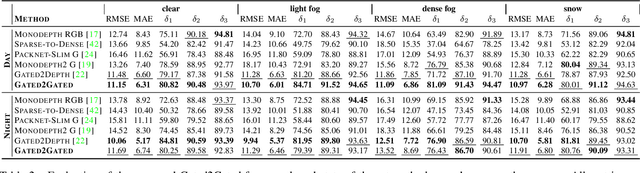
Gated cameras hold promise as an alternative to scanning LiDAR sensors with high-resolution 3D depth that is robust to back-scatter in fog, snow, and rain. Instead of sequentially scanning a scene and directly recording depth via the photon time-of-flight, as in pulsed LiDAR sensors, gated imagers encode depth in the relative intensity of a handful of gated slices, captured at megapixel resolution. Although existing methods have shown that it is possible to decode high-resolution depth from such measurements, these methods require synchronized and calibrated LiDAR to supervise the gated depth decoder -- prohibiting fast adoption across geographies, training on large unpaired datasets, and exploring alternative applications outside of automotive use cases. In this work, we fill this gap and propose an entirely self-supervised depth estimation method that uses gated intensity profiles and temporal consistency as a training signal. The proposed model is trained end-to-end from gated video sequences, does not require LiDAR or RGB data, and learns to estimate absolute depth values. We take gated slices as input and disentangle the estimation of the scene albedo, depth, and ambient light, which are then used to learn to reconstruct the input slices through a cyclic loss. We rely on temporal consistency between a given frame and neighboring gated slices to estimate depth in regions with shadows and reflections. We experimentally validate that the proposed approach outperforms existing supervised and self-supervised depth estimation methods based on monocular RGB and stereo images, as well as supervised methods based on gated images.
Enabling equivariance for arbitrary Lie groups
Nov 16, 2021
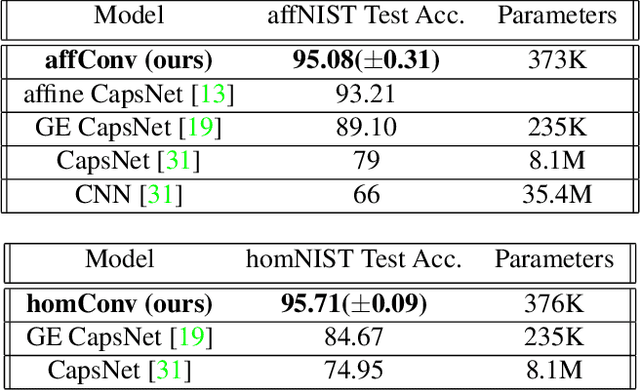
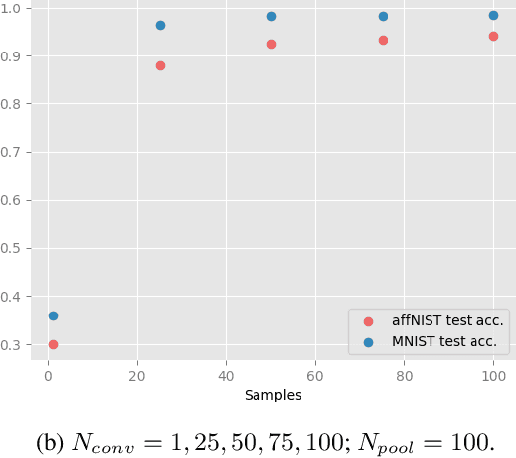
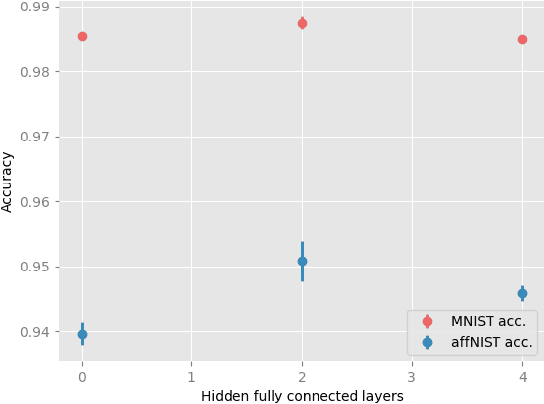
Although provably robust to translational perturbations, convolutional neural networks (CNNs) are known to suffer from extreme performance degradation when presented at test time with more general geometric transformations of inputs. Recently, this limitation has motivated a shift in focus from CNNs to Capsule Networks (CapsNets). However, CapsNets suffer from admitting relatively few theoretical guarantees of invariance. We introduce a rigourous mathematical framework to permit invariance to any Lie group of warps, exclusively using convolutions (over Lie groups), without the need for capsules. Previous work on group convolutions has been hampered by strong assumptions about the group, which precludes the application of such techniques to common warps in computer vision such as affine and homographic. Our framework enables the implementation of group convolutions over \emph{any} finite-dimensional Lie group. We empirically validate our approach on the benchmark affine-invariant classification task, where we achieve $\sim$30\% improvement in accuracy against conventional CNNs while outperforming the state-of-the-art CapsNet. As further illustration of the generality of our framework, we train a homography-convolutional model which achieves superior robustness on a homography-perturbed dataset, where CapsNet results degrade.
Learning Pruned Structure and Weights Simultaneously from Scratch: an Attention based Approach
Nov 01, 2021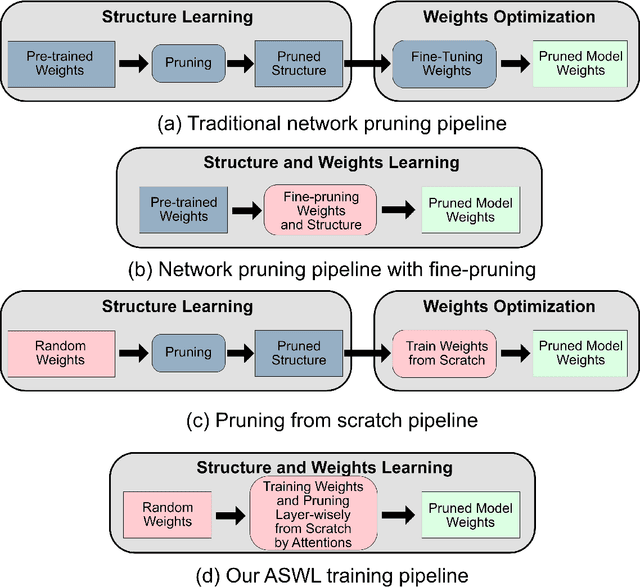
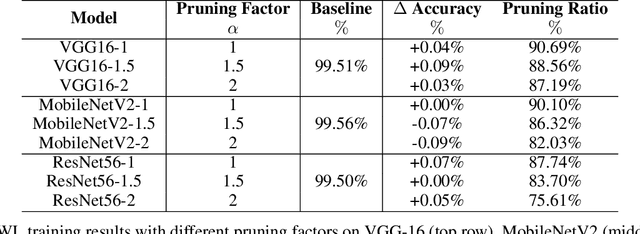
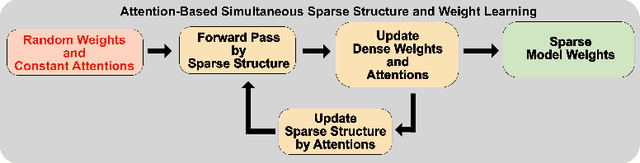
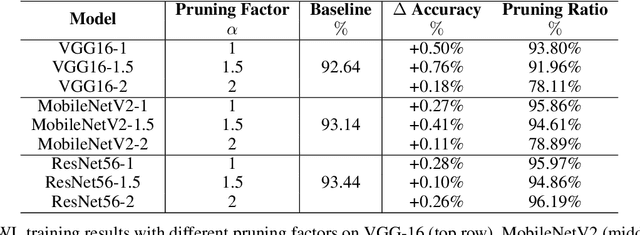
As a deep learning model typically contains millions of trainable weights, there has been a growing demand for a more efficient network structure with reduced storage space and improved run-time efficiency. Pruning is one of the most popular network compression techniques. In this paper, we propose a novel unstructured pruning pipeline, Attention-based Simultaneous sparse structure and Weight Learning (ASWL). Unlike traditional channel-wise or weight-wise attention mechanism, ASWL proposed an efficient algorithm to calculate the pruning ratio through layer-wise attention for each layer, and both weights for the dense network and the sparse network are tracked so that the pruned structure is simultaneously learned from randomly initialized weights. Our experiments on MNIST, Cifar10, and ImageNet show that ASWL achieves superior pruning results in terms of accuracy, pruning ratio and operating efficiency when compared with state-of-the-art network pruning methods.
Deep convolutional generative adversarial networks for traffic data imputation encoding time series as images
May 05, 2020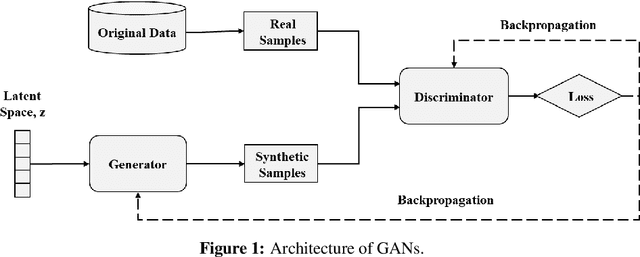
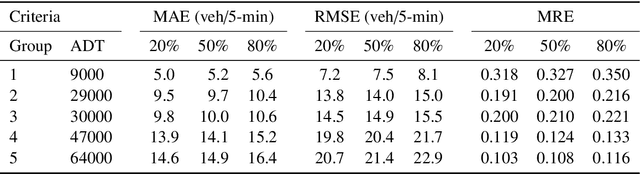
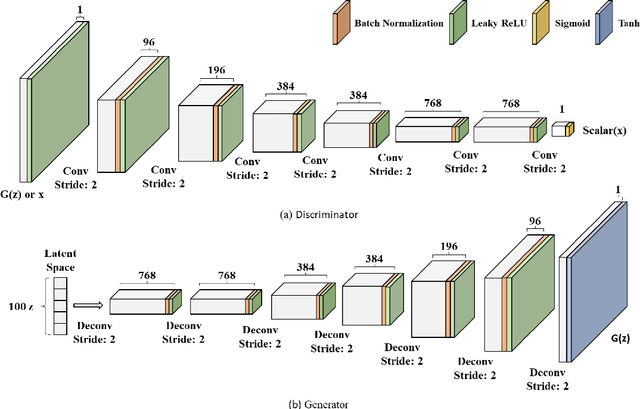
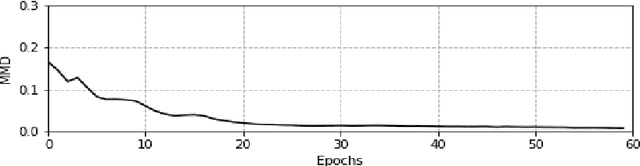
Sufficient high-quality traffic data are a crucial component of various Intelligent Transportation System (ITS) applications and research related to congestion prediction, speed prediction, incident detection, and other traffic operation tasks. Nonetheless, missing traffic data are a common issue in sensor data which is inevitable due to several reasons, such as malfunctioning, poor maintenance or calibration, and intermittent communications. Such missing data issues often make data analysis and decision-making complicated and challenging. In this study, we have developed a generative adversarial network (GAN) based traffic sensor data imputation framework (TSDIGAN) to efficiently reconstruct the missing data by generating realistic synthetic data. In recent years, GANs have shown impressive success in image data generation. However, generating traffic data by taking advantage of GAN based modeling is a challenging task, since traffic data have strong time dependency. To address this problem, we propose a novel time-dependent encoding method called the Gramian Angular Summation Field (GASF) that converts the problem of traffic time-series data generation into that of image generation. We have evaluated and tested our proposed model using the benchmark dataset provided by Caltrans Performance Management Systems (PeMS). This study shows that the proposed model can significantly improve the traffic data imputation accuracy in terms of Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) compared to state-of-the-art models on the benchmark dataset. Further, the model achieves reasonably high accuracy in imputation tasks even under a very high missing data rate ($>$ 50\%), which shows the robustness and efficiency of the proposed model.
OTFS-superimposed PRACH-aided Localization for UAV Safety Applications
Sep 17, 2021
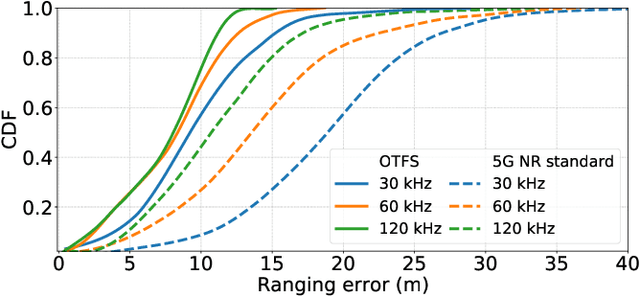
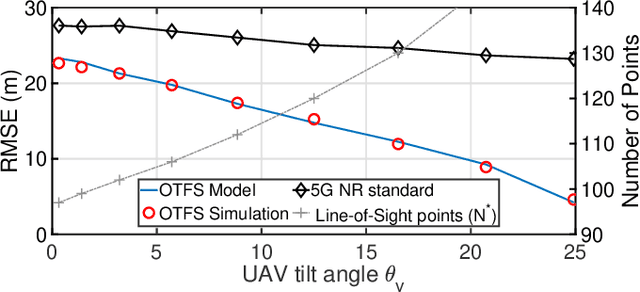
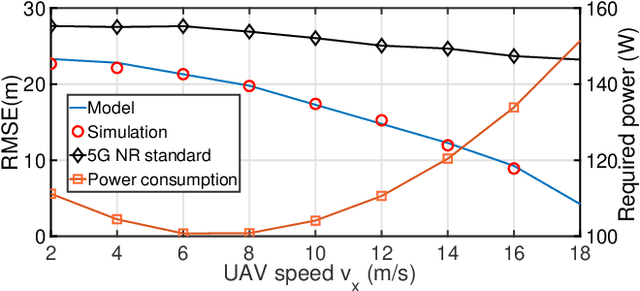
The adoption of Unmanned Aerial Vehicles (UAVs) for public safety applications has skyrocketed in the last years. Leveraging on Physical Random Access Channel (PRACH) preambles, in this paper we pioneer a novel localization technique for UAVs equipped with cellular base stations used in emergency scenarios. We exploit the new concept of Orthogonal Time Frequency Space (OTFS) modulation (tolerant to channel Doppler spread caused by UAVs motion) to build a fully standards-compliant OTFS-modulated PRACH transmission and reception scheme able to perform time-of-arrival (ToA) measurements. First, we analyze such novel ToA ranging technique, both analytically and numerically, to accurately and iteratively derive the distance between localized users and the points traversed by the UAV along its trajectory. Then, we determine the optimal UAV speed as a trade-off between the accuracy of the ranging technique and the power needed by the UAV to reach and keep its speed during emergency operations. Finally, we demonstrate that our solution outperforms standard PRACH-based localization techniques in terms of Root Mean Square Error (RMSE) by about 20% in quasi-static conditions and up to 80% in high-mobility conditions.
Noisy UGC Translation at the Character Level: Revisiting Open-Vocabulary Capabilities and Robustness of Char-Based Models
Oct 24, 2021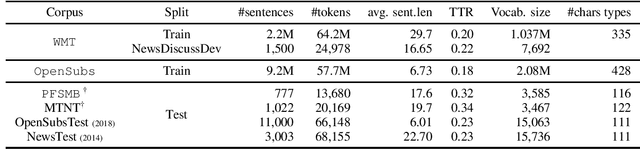
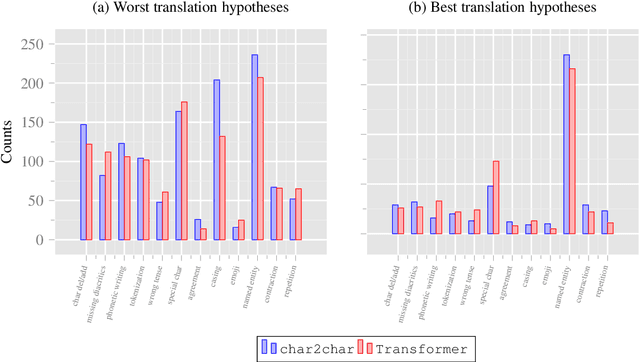
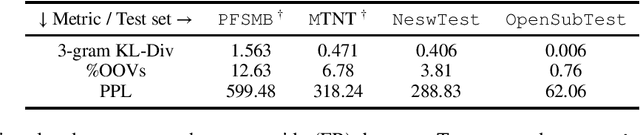
This work explores the capacities of character-based Neural Machine Translation to translate noisy User-Generated Content (UGC) with a strong focus on exploring the limits of such approaches to handle productive UGC phenomena, which almost by definition, cannot be seen at training time. Within a strict zero-shot scenario, we first study the detrimental impact on translation performance of various user-generated content phenomena on a small annotated dataset we developed, and then show that such models are indeed incapable of handling unknown letters, which leads to catastrophic translation failure once such characters are encountered. We further confirm this behavior with a simple, yet insightful, copy task experiment and highlight the importance of reducing the vocabulary size hyper-parameter to increase the robustness of character-based models for machine translation.
Continuous and Discrete-Time Analysis of Stochastic Gradient Descent for Convex and Non-Convex Functions
Apr 08, 2020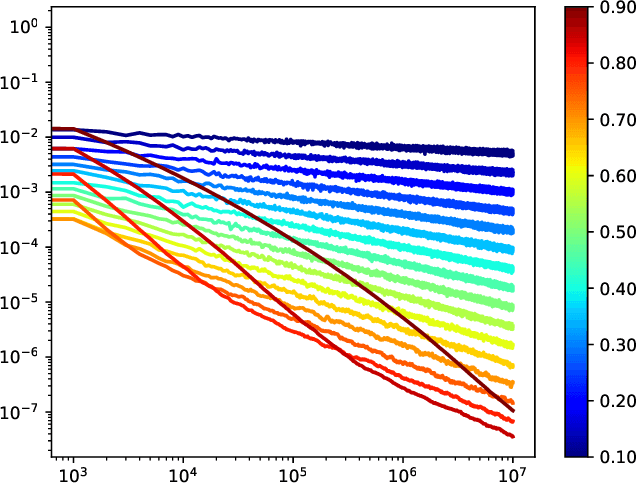

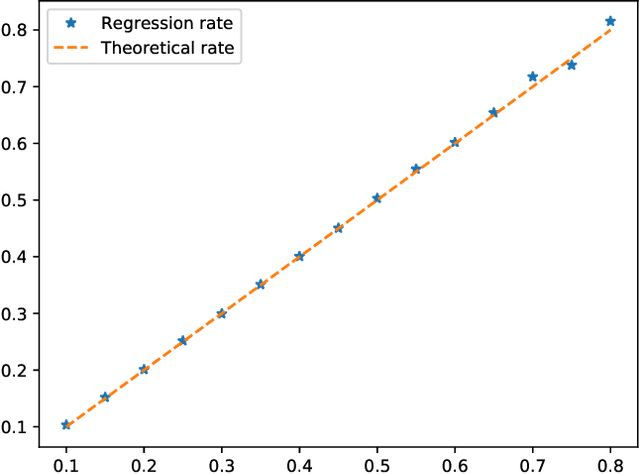

This paper proposes a thorough theoretical analysis of Stochastic Gradient Descent (SGD) with decreasing step sizes. First, we show that the recursion defining SGD can be provably approximated by solutions of a time inhomogeneous Stochastic Differential Equation (SDE) in a weak and strong sense. Then, motivated by recent analyses of deterministic and stochastic optimization methods by their continuous counterpart, we study the long-time convergence of the continuous processes at hand and establish non-asymptotic bounds. To that purpose, we develop new comparison techniques which we think are of independent interest. This continuous analysis allows us to develop an intuition on the convergence of SGD and, adapting the technique to the discrete setting, we show that the same results hold to the corresponding sequences. In our analysis, we notably obtain non-asymptotic bounds in the convex setting for SGD under weaker assumptions than the ones considered in previous works. Finally, we also establish finite time convergence results under various conditions, including relaxations of the famous {\L}ojasiewicz inequality, which can be applied to a class of non-convex functions.
Electro-optical Neural Networks based on Time-stretch Method
Sep 13, 2019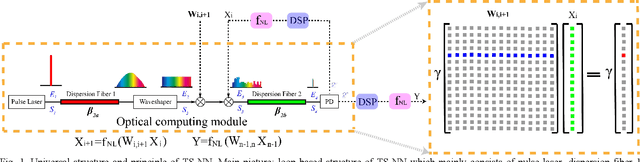
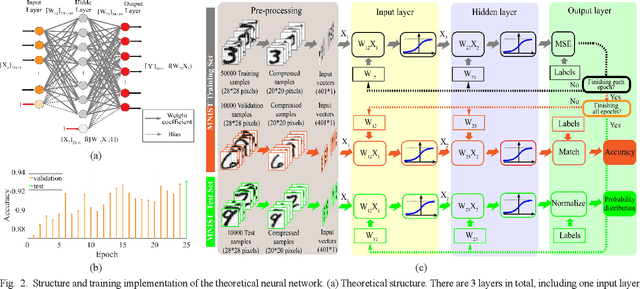
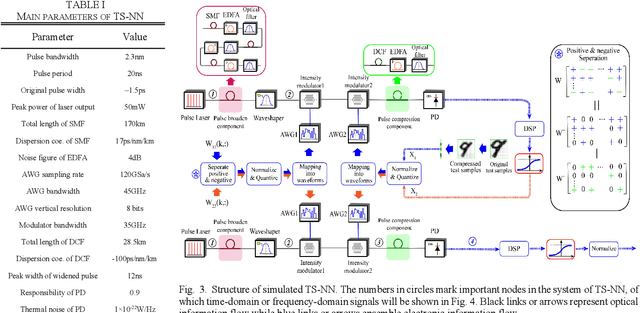
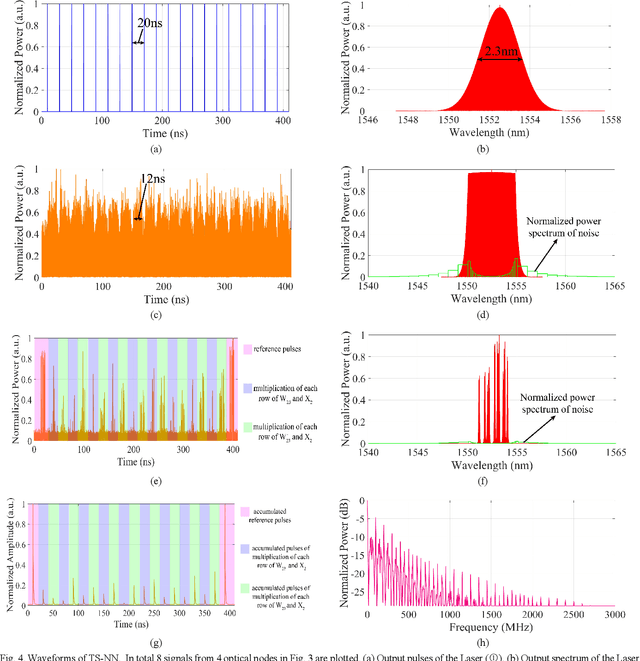
In this paper, a novel architecture of electro-optical neural networks based on the time-stretch method is proposed and numerically simulated. By stretching time-domain ultrashort pulses, multiplications of large scale weight matrices and vectors can be implemented on light and multiple-layer of feedforward neural network operations can be easily implemented with fiber loops. Via simulation, the performance of a three-layer electro-optical neural network is tested by the handwriting digit recognition task and the accuracy reaches 88% under considerable noise.
Once Upon A Time In Visualization: Understanding the Use of Textual Narratives for Causality
Sep 06, 2020
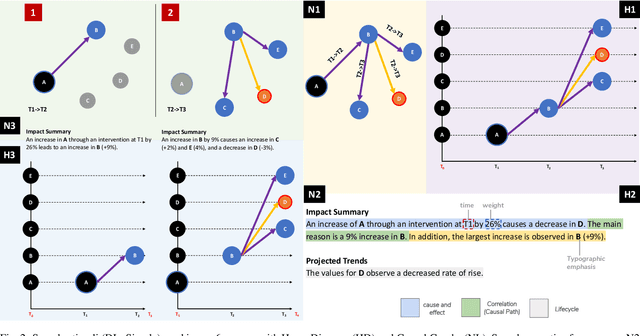

Causality visualization can help people understand temporal chains of events, such as messages sent in a distributed system, cause and effect in a historical conflict, or the interplay between political actors over time. However, as the scale and complexity of these event sequences grows, even these visualizations can become overwhelming to use. In this paper, we propose the use of textual narratives as a data-driven storytelling method to augment causality visualization. We first propose a design space for how textual narratives can be used to describe causal data. We then present results from a crowdsourced user study where participants were asked to recover causality information from two causality visualizations--causal graphs and Hasse diagrams--with and without an associated textual narrative. Finally, we describe CAUSEWORKS, a causality visualization system for understanding how specific interventions influence a causal model. The system incorporates an automatic textual narrative mechanism based on our design space. We validate CAUSEWORKS through interviews with experts who used the system for understanding complex events.