 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic Image-to-Image Translation via Denoising Brownian Bridge Models with Dual Approximators
Dec 29, 2025Image-to-Image (I2I) translation involves converting an image from one domain to another. Deterministic I2I translation, such as in image super-resolution, extends this concept by guaranteeing that each input generates a consistent and predictable output, closely matching the ground truth (GT) with high fidelity. In this paper, we propose a denoising Brownian bridge model with dual approximators (Dual-approx Bridge), a novel generative model that exploits the Brownian bridge dynamics and two neural network-based approximators (one for forward and one for reverse process) to produce faithful output with negligible variance and high image quality in I2I translations. Our extensive experiments on benchmark datasets including image generation and super-resolution demonstrate the consistent and superior performance of Dual-approx Bridge in terms of image quality and faithfulness to GT when compared to both stochastic and deterministic baselines. Project page and code: https://github.com/bohan95/dual-app-bridge
Modality-AGnostic Image Cascade (MAGIC) for Multi-Modality Cardiac Substructure Segmentation
Jun 12, 2025Cardiac substructures are essential in thoracic radiation therapy planning to minimize risk of radiation-induced heart disease. Deep learning (DL) offers efficient methods to reduce contouring burden but lacks generalizability across different modalities and overlapping structures. This work introduces and validates a Modality-AGnostic Image Cascade (MAGIC) for comprehensive and multi-modal cardiac substructure segmentation. MAGIC is implemented through replicated encoding and decoding branches of an nnU-Net-based, U-shaped backbone conserving the function of a single model. Twenty cardiac substructures (heart, chambers, great vessels (GVs), valves, coronary arteries (CAs), and conduction nodes) from simulation CT (Sim-CT), low-field MR-Linac, and cardiac CT angiography (CCTA) modalities were manually delineated and used to train (n=76), validate (n=15), and test (n=30) MAGIC. Twelve comparison models (four segmentation subgroups across three modalities) were equivalently trained. All methods were compared for training efficiency and against reference contours using the Dice Similarity Coefficient (DSC) and two-tailed Wilcoxon Signed-Rank test (threshold, p<0.05). Average DSC scores were 0.75(0.16) for Sim-CT, 0.68(0.21) for MR-Linac, and 0.80(0.16) for CCTA. MAGIC outperforms the comparison in 57% of cases, with limited statistical differences. MAGIC offers an effective and accurate segmentation solution that is lightweight and capable of segmenting multiple modalities and overlapping structures in a single model. MAGIC further enables clinical implementation by simplifying the computational requirements and offering unparalleled flexibility for clinical settings.
Deterministic Medical Image Translation via High-fidelity Brownian Bridges
Mar 28, 2025Recent studies have shown that diffusion models produce superior synthetic images when compared to Generative Adversarial Networks (GANs). However, their outputs are often non-deterministic and lack high fidelity to the ground truth due to the inherent randomness. In this paper, we propose a novel High-fidelity Brownian bridge model (HiFi-BBrg) for deterministic medical image translations. Our model comprises two distinct yet mutually beneficial mappings: a generation mapping and a reconstruction mapping. The Brownian bridge training process is guided by the fidelity loss and adversarial training in the reconstruction mapping. This ensures that translated images can be accurately reversed to their original forms, thereby achieving consistent translations with high fidelity to the ground truth. Our extensive experiments on multiple datasets show HiFi-BBrg outperforms state-of-the-art methods in multi-modal image translation and multi-image super-resolution.
Modality-Agnostic Learning for Medical Image Segmentation Using Multi-modality Self-distillation
Jun 06, 2023Medical image segmentation of tumors and organs at risk is a time-consuming yet critical process in the clinic that utilizes multi-modality imaging (e.g, different acquisitions, data types, and sequences) to increase segmentation precision. In this paper, we propose a novel framework, Modality-Agnostic learning through Multi-modality Self-dist-illation (MAG-MS), to investigate the impact of input modalities on medical image segmentation. MAG-MS distills knowledge from the fusion of multiple modalities and applies it to enhance representation learning for individual modalities. Thus, it provides a versatile and efficient approach to handle limited modalities during testing. Our extensive experiments on benchmark datasets demonstrate the high efficiency of MAG-MS and its superior segmentation performance than current state-of-the-art methods. Furthermore, using MAG-MS, we provide valuable insight and guidance on selecting input modalities for medical image segmentation tasks.
Learning Pruned Structure and Weights Simultaneously from Scratch: an Attention based Approach
Nov 01, 2021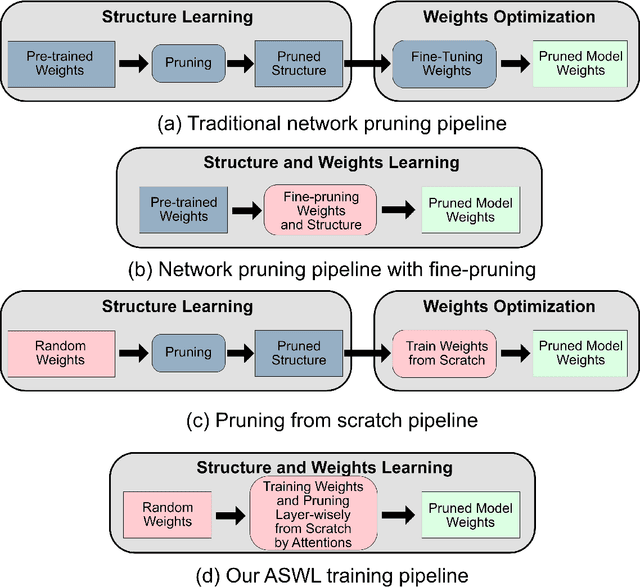
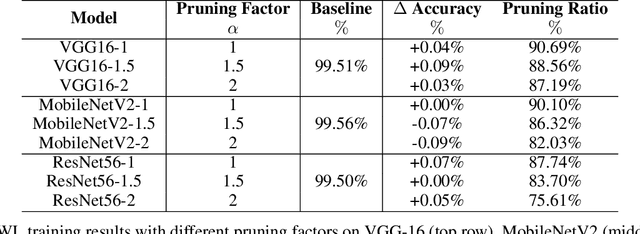
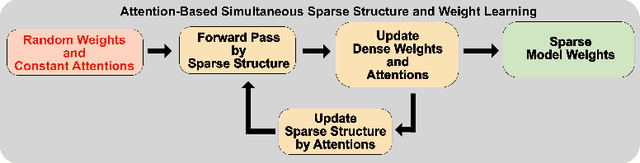
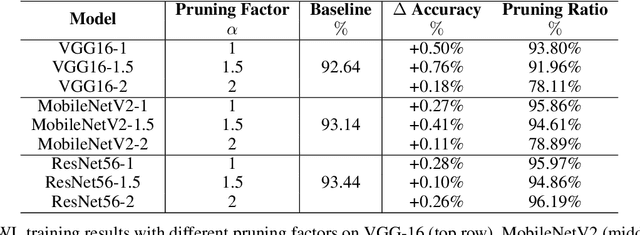
As a deep learning model typically contains millions of trainable weights, there has been a growing demand for a more efficient network structure with reduced storage space and improved run-time efficiency. Pruning is one of the most popular network compression techniques. In this paper, we propose a novel unstructured pruning pipeline, Attention-based Simultaneous sparse structure and Weight Learning (ASWL). Unlike traditional channel-wise or weight-wise attention mechanism, ASWL proposed an efficient algorithm to calculate the pruning ratio through layer-wise attention for each layer, and both weights for the dense network and the sparse network are tracked so that the pruned structure is simultaneously learned from randomly initialized weights. Our experiments on MNIST, Cifar10, and ImageNet show that ASWL achieves superior pruning results in terms of accuracy, pruning ratio and operating efficiency when compared with state-of-the-art network pruning methods.