 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sequential Multivariate Change Detection with Calibrated and Memoryless False Detection Rates
Aug 02, 2021
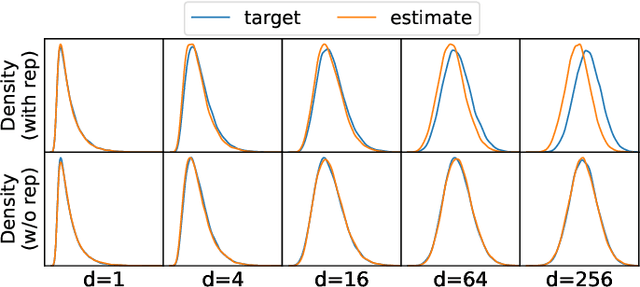

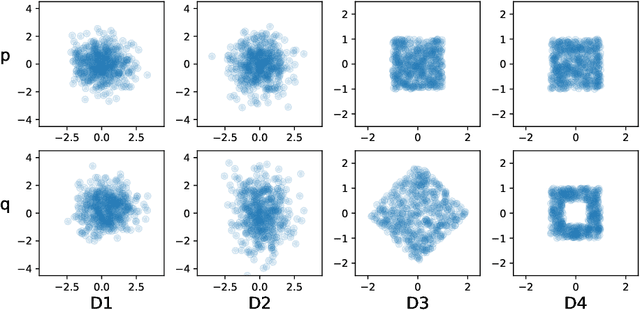
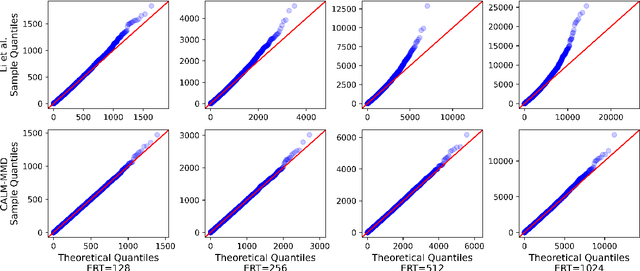
Responding appropriately to the detections of a sequential change detector requires knowledge of the rate at which false positives occur in the absence of change. When the pre-change and post-change distributions are unknown, setting detection thresholds to achieve a desired false positive rate is challenging, even when there exists a large number of samples from the reference distribution. Existing works resort to setting time-invariant thresholds that focus on the expected runtime of the detector in the absence of change, either bounding it loosely from below or targeting it directly but with asymptotic arguments that we show cause significant miscalibration in practice. We present a simulation-based approach to setting time-varying thresholds that allows a desired expected runtime to be targeted with a 20x reduction in miscalibration whilst additionally keeping the false positive rate constant across time steps. Whilst the approach to threshold setting is metric agnostic, we show that when using the popular and powerful quadratic time MMD estimator, thoughtful structuring of the computation can reduce the cost during configuration from $O(N^2B)$ to $O(N^2+NB)$ and during operation from $O(N^2)$ to $O(N)$, where $N$ is the number of reference samples and $B$ the number of bootstrap samples. Code is made available as part of the open-source Python library \texttt{alibi-detect}.
Oracle Teacher: Towards Better Knowledge Distillation
Nov 05, 2021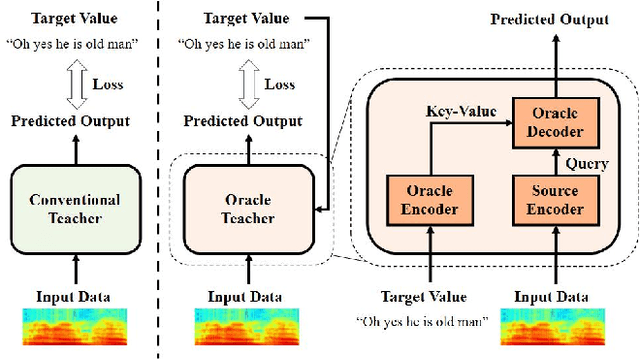
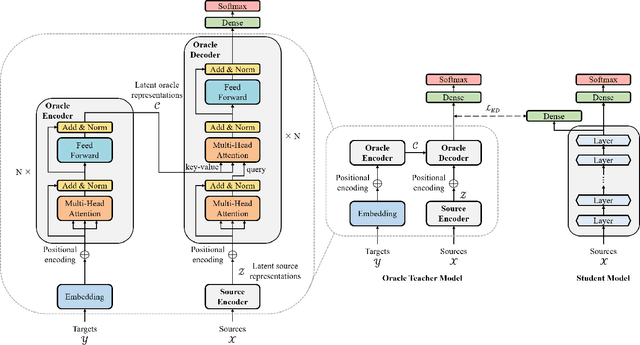
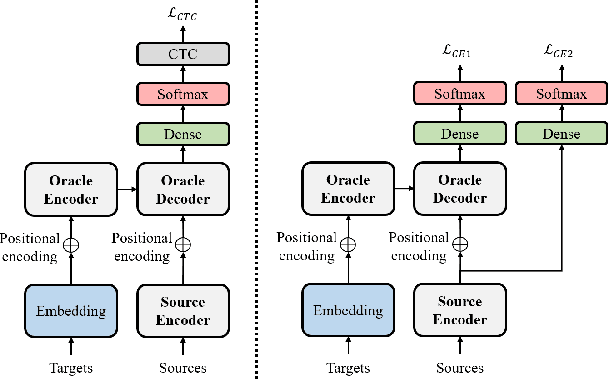

Knowledge distillation (KD), best known as an effective method for model compression, aims at transferring the knowledge of a bigger network (teacher) to a much smaller network (student). Conventional KD methods usually employ the teacher model trained in a supervised manner, where output labels are treated only as targets. Extending this supervised scheme further, we introduce a new type of teacher model for KD, namely Oracle Teacher, that utilizes the embeddings of both the source inputs and the output labels to extract a more accurate knowledge to be transferred to the student. The proposed model follows the encoder-decoder attention structure of the Transformer network, which allows the model to attend to related information from the output labels. Extensive experiments are conducted on three different sequence learning tasks: speech recognition, scene text recognition, and machine translation. From the experimental results, we empirically show that the proposed model improves the students across these tasks while achieving a considerable speed-up in the teacher model's training time.
An empirical evaluation of attention-based multi-head models for improved turbofan engine remaining useful life prediction
Sep 04, 2021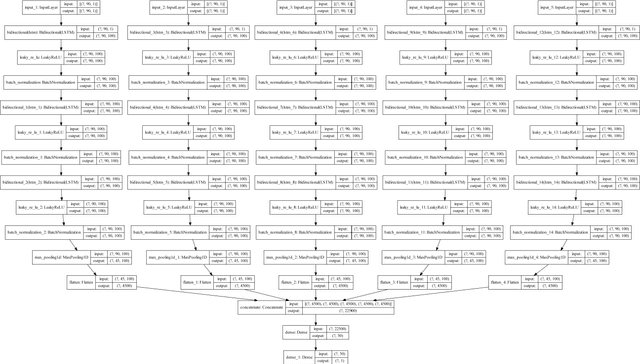
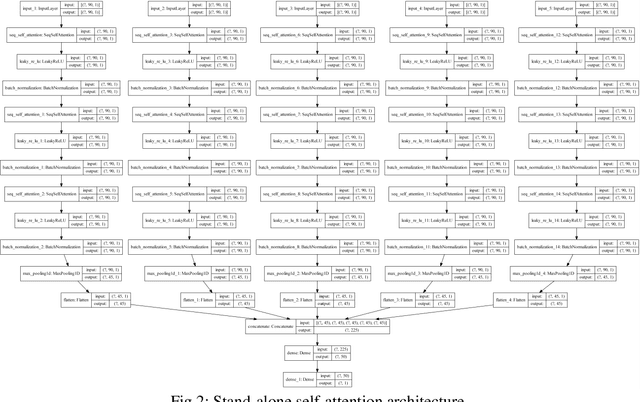

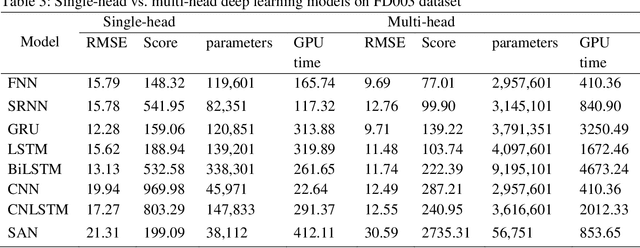
A single unit (head) is the conventional input feature extractor in deep learning architectures trained on multivariate time series signals. The importance of the fixed-dimensional vector representation generated by the single-head network has been demonstrated for industrial machinery condition monitoring and predictive maintenance. However, processing heterogeneous sensor signals with a single head may result in a model that cannot explicitly account for the diversity in time-varying multivariate inputs. This work extends the conventional single-head deep learning models to a more robust form by developing context-specific heads to independently capture the inherent pattern of each sensor reading in multivariate time series signals. Using the turbofan aircraft engine benchmark dataset (CMAPSS), an extensive experiment is performed to verify the effectiveness and benefits of multi-head fully connected neurons, recurrent networks, convolution network, the transformer-style stand-alone attention network, and their variants for remaining useful life estimation. Moreover, the effect of different attention mechanisms on the multi-head models is also evaluated. In addition, each architecture's relative advantage and computational overhead are analyzed. Results show that utilizing the attention layer is task-sensitive and model-dependent, as it does not provide consistent improvement across the models investigated. The result is further compared with five state-of-the-art models, and the comparison shows that a relatively simple multi-head architecture performs better than the state-of-the-art models. The results presented in this study demonstrate the importance of multi-head models and attention mechanisms to improved understanding of the remaining useful life of industrial assets.
Certified Adversarial Defenses Meet Out-of-Distribution Corruptions: Benchmarking Robustness and Simple Baselines
Dec 01, 2021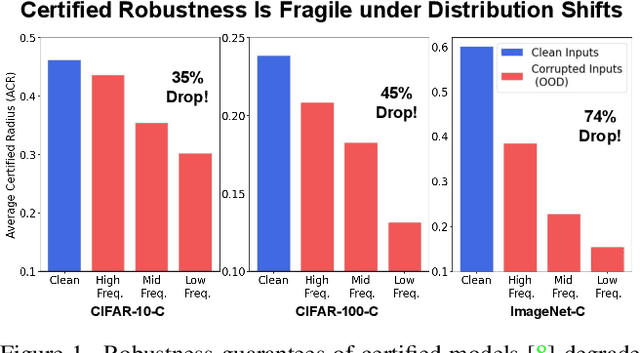
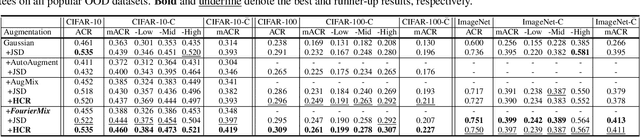
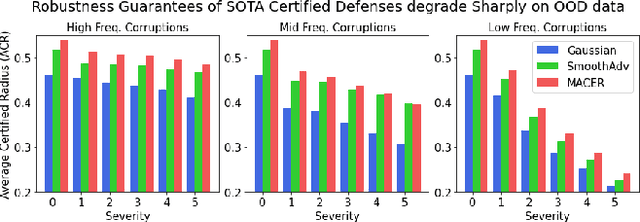
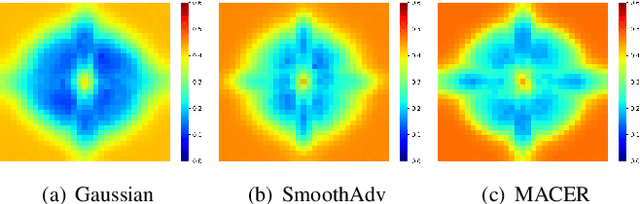
Certified robustness guarantee gauges a model's robustness to test-time attacks and can assess the model's readiness for deployment in the real world. In this work, we critically examine how the adversarial robustness guarantees from randomized smoothing-based certification methods change when state-of-the-art certifiably robust models encounter out-of-distribution (OOD) data. Our analysis demonstrates a previously unknown vulnerability of these models to low-frequency OOD data such as weather-related corruptions, rendering these models unfit for deployment in the wild. To alleviate this issue, we propose a novel data augmentation scheme, FourierMix, that produces augmentations to improve the spectral coverage of the training data. Furthermore, we propose a new regularizer that encourages consistent predictions on noise perturbations of the augmented data to improve the quality of the smoothed models. We find that FourierMix augmentations help eliminate the spectral bias of certifiably robust models enabling them to achieve significantly better robustness guarantees on a range of OOD benchmarks. Our evaluation also uncovers the inability of current OOD benchmarks at highlighting the spectral biases of the models. To this end, we propose a comprehensive benchmarking suite that contains corruptions from different regions in the spectral domain. Evaluation of models trained with popular augmentation methods on the proposed suite highlights their spectral biases and establishes the superiority of FourierMix trained models at achieving better-certified robustness guarantees under OOD shifts over the entire frequency spectrum.
Exploring Multi-dimensional Hierarchical Network Topologies for Efficient Distributed Training of Trillion Parameter DL Models
Sep 24, 2021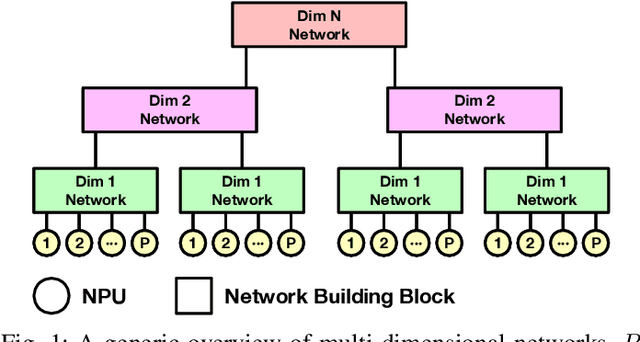
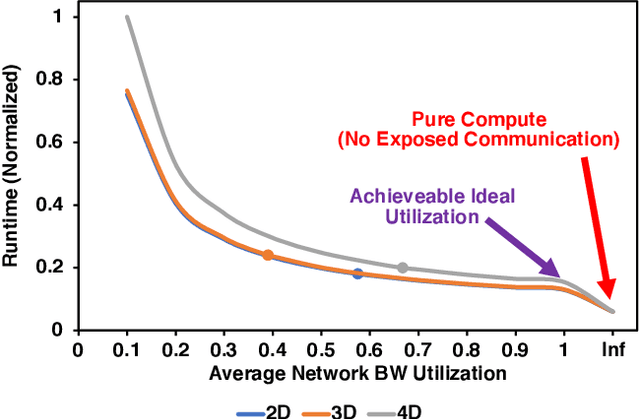
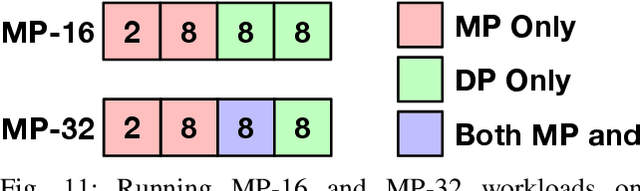
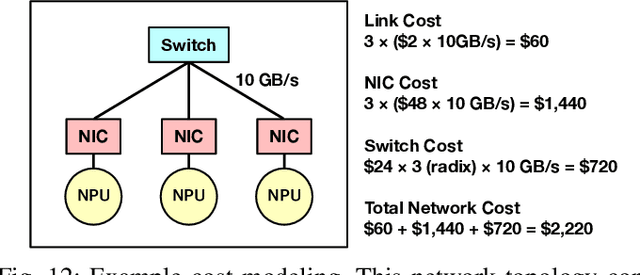
Deep Neural Networks have gained significant attraction due to their wide applicability in different domains. DNN sizes and training samples are constantly growing, making training of such workloads more challenging. Distributed training is a solution to reduce the training time. High-performance distributed training platforms should leverage multi-dimensional hierarchical networks, which interconnect accelerators through different levels of the network, to dramatically reduce expensive NICs required for the scale-out network. However, it comes at the expense of communication overhead between distributed accelerators to exchange gradients or input/output activation. In order to allow for further scaling of the workloads, communication overhead needs to be minimized. In this paper, we motivate the fact that in training platforms, adding more intermediate network dimensions is beneficial for efficiently mitigating the excessive use of expensive NIC resources. Further, we address different challenges of the DNN training on hierarchical networks. We discuss when designing the interconnect, how to distribute network bandwidth resources across different dimensions in order to (i) maximize BW utilization of all dimensions, and (ii) minimizing the overall training time for the target workload. We then implement a framework that, for a given workload, determines the best network configuration that maximizes performance, or performance-per-cost.
Attention-Guided Generative Adversarial Network for Whisper to Normal Speech Conversion
Nov 02, 2021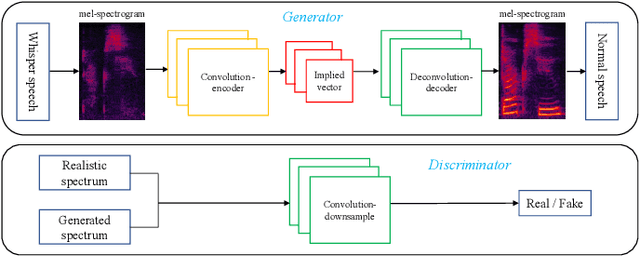
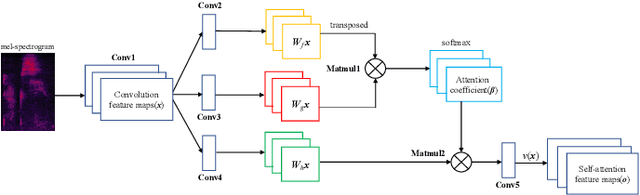
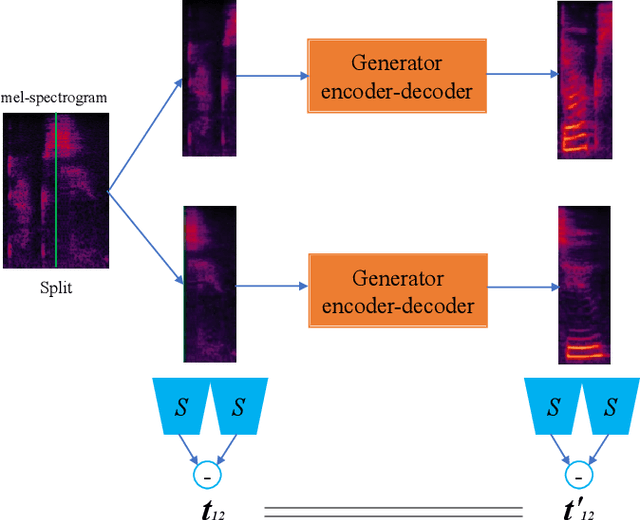
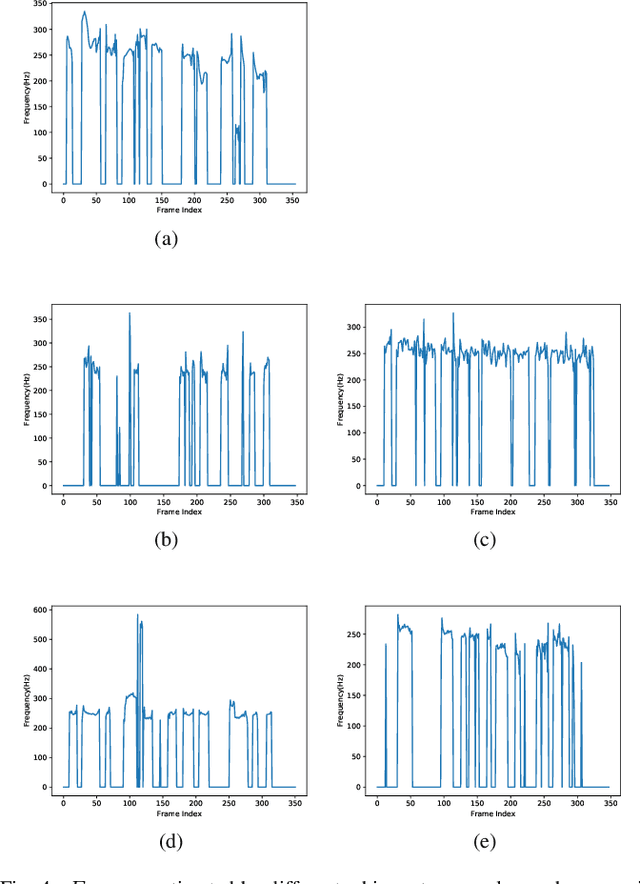
Whispered speech is a special way of pronunciation without using vocal cord vibration. A whispered speech does not contain a fundamental frequency, and its energy is about 20dB lower than that of a normal speech. Converting a whispered speech into a normal speech can improve speech quality and intelligibility. In this paper, a novel attention-guided generative adversarial network model incorporating an autoencoder, a Siamese neural network, and an identity mapping loss function for whisper to normal speech conversion (AGAN-W2SC) is proposed. The proposed method avoids the challenge of estimating the fundamental frequency of the normal voiced speech converted from a whispered speech. Specifically, the proposed model is more amendable to practical applications because it does not need to align speech features for training. Experimental results demonstrate that the proposed AGAN-W2SC can obtain improved speech quality and intelligibility compared with dynamic-time-warping-based methods.
TransPose: Real-time 3D Human Translation and Pose Estimation with Six Inertial Sensors
May 10, 2021

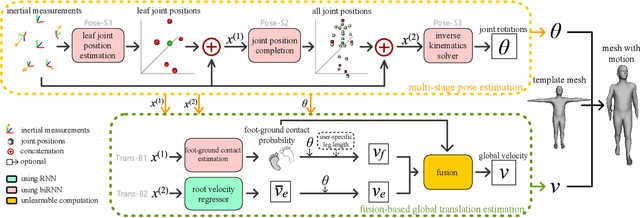

Motion capture is facing some new possibilities brought by the inertial sensing technologies which do not suffer from occlusion or wide-range recordings as vision-based solutions do. However, as the recorded signals are sparse and quite noisy, online performance and global translation estimation turn out to be two key difficulties. In this paper, we present TransPose, a DNN-based approach to perform full motion capture (with both global translations and body poses) from only 6 Inertial Measurement Units (IMUs) at over 90 fps. For body pose estimation, we propose a multi-stage network that estimates leaf-to-full joint positions as intermediate results. This design makes the pose estimation much easier, and thus achieves both better accuracy and lower computation cost. For global translation estimation, we propose a supporting-foot-based method and an RNN-based method to robustly solve for the global translations with a confidence-based fusion technique. Quantitative and qualitative comparisons show that our method outperforms the state-of-the-art learning- and optimization-based methods with a large margin in both accuracy and efficiency. As a purely inertial sensor-based approach, our method is not limited by environmental settings (e.g., fixed cameras), making the capture free from common difficulties such as wide-range motion space and strong occlusion.
Maillard Sampling: Boltzmann Exploration Done Optimally
Nov 05, 2021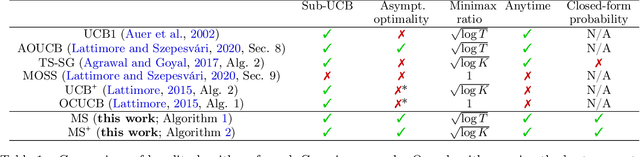
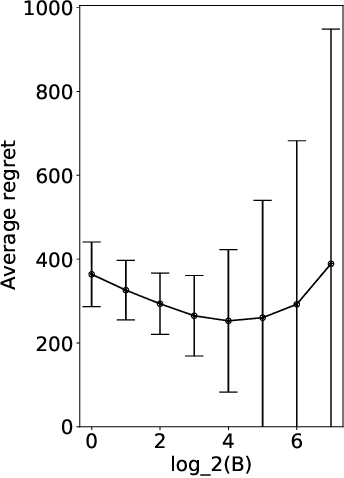

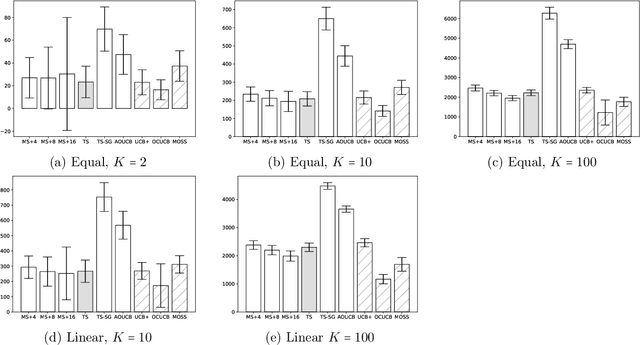
The PhD thesis of Maillard (2013) presents a randomized algorithm for the $K$-armed bandit problem. This less-known algorithm, which we call Maillard sampling (MS), computes the probability of choosing each arm in a closed form, which is useful for counterfactual evaluation from bandit-logged data but was lacking from Thompson sampling, a widely-adopted bandit algorithm in the industry. Motivated by such merit, we revisit MS and perform an improved analysis to show that it achieves both the asymptotical optimality and $\sqrt{KT\log{T}}$ minimax regret bound where $T$ is the time horizon, which matches the standard asymptotically optimal UCB's performance. We then propose a variant of MS called MS$^+$ that improves its minimax bound to $\sqrt{KT\log{K}}$ without losing the asymptotic optimality. MS$^+$ can also be tuned to be aggressive (i.e., less exploration) without losing theoretical guarantees, a unique feature unavailable from existing bandit algorithms. Our numerical evaluation shows the effectiveness of MS$^+$.
Motion Control of Redundant Robots with Generalised Inequality Constraints
Oct 04, 2021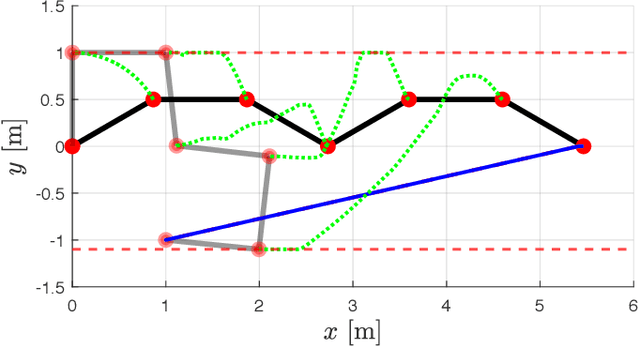
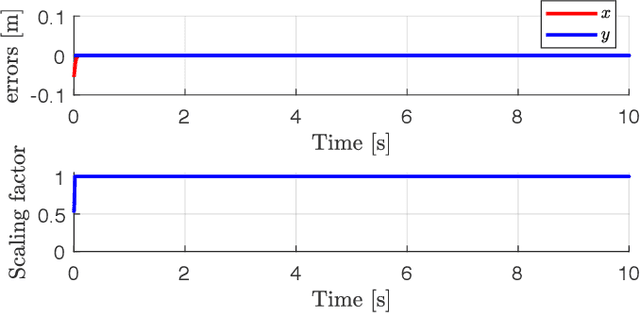
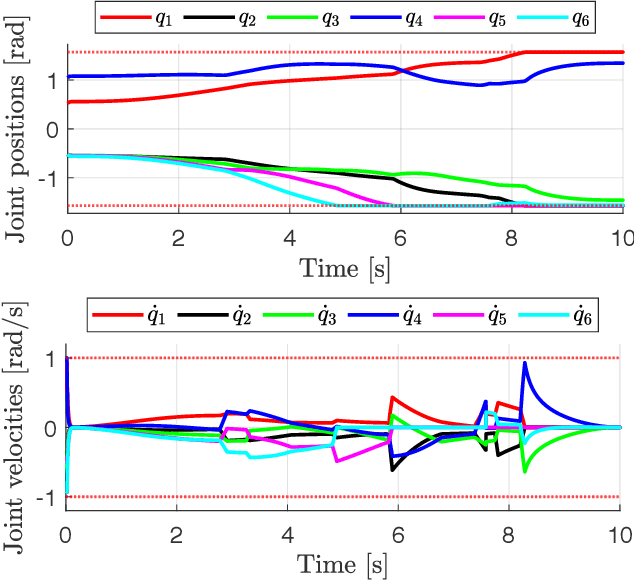
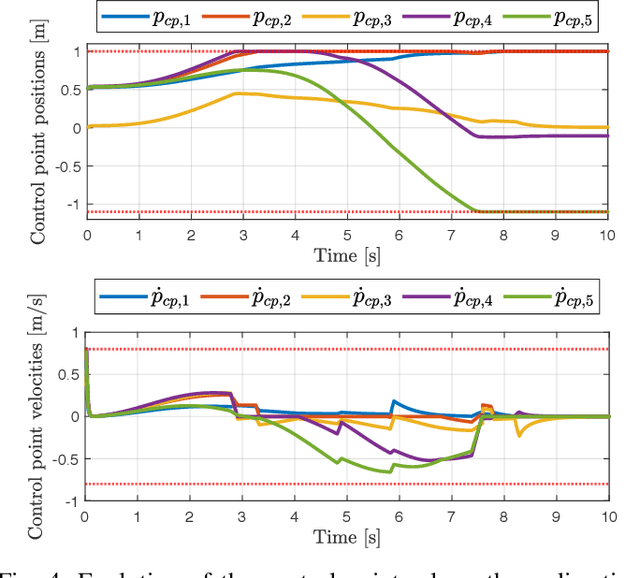
We present an improved version of the Saturation in the Null Space (SNS) algorithm for redundancy resolution at the velocity level. In addition to hard bounds on joint space motion, we consider also Cartesian box constraints that cannot be violated at any time. The modified algorithm combines all bounds into a single augmented generalised vector and gives equal, highest priority to all inequality constraints. When needed, feasibility of the original task is enforced by the SNS task scaling procedure. Simulation results are reported for a 6R planar robot.
Reconstructing High-resolution Turbulent Flows Using Physics-Guided Neural Networks
Sep 06, 2021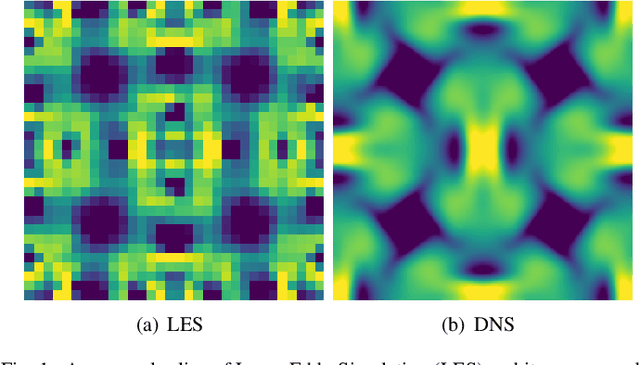
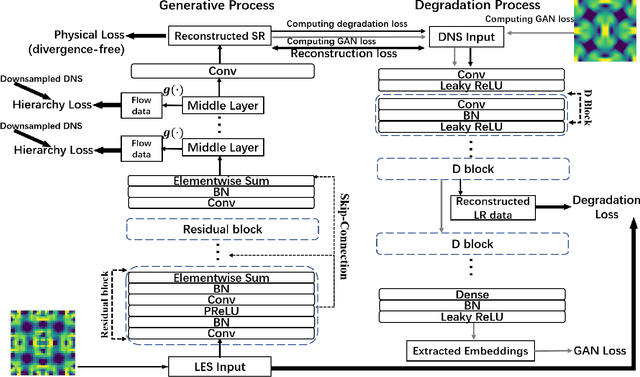
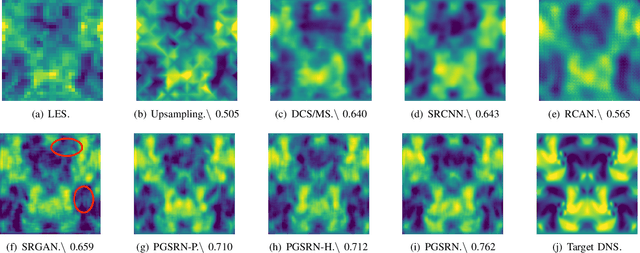
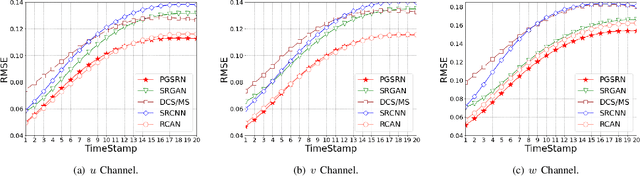
Direct numerical simulation (DNS) of turbulent flows is computationally expensive and cannot be applied to flows with large Reynolds numbers. Large eddy simulation (LES) is an alternative that is computationally less demanding, but is unable to capture all of the scales of turbulent transport accurately. Our goal in this work is to build a new data-driven methodology based on super-resolution techniques to reconstruct DNS data from LES predictions. We leverage the underlying physical relationships to regularize the relationships amongst different physical variables. We also introduce a hierarchical generative process and a reverse degradation process to fully explore the correspondence between DNS and LES data. We demonstrate the effectiveness of our method through a single-snapshot experiment and a cross-time experiment. The results confirm that our method can better reconstruct high-resolution DNS data over space and over time in terms of pixel-wise reconstruction error and structural similarity. Visual comparisons show that our method performs much better in capturing fine-level flow dynamics.