 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning Model for Demodulation Reference Signal based Channel Estimation
Sep 22, 2021
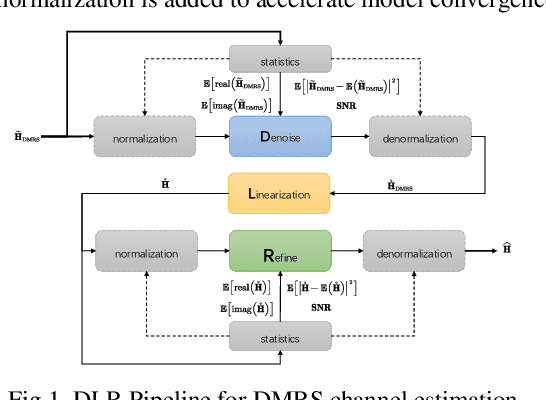
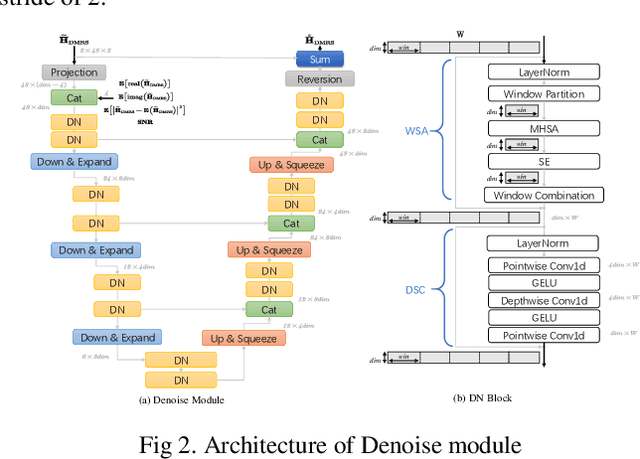
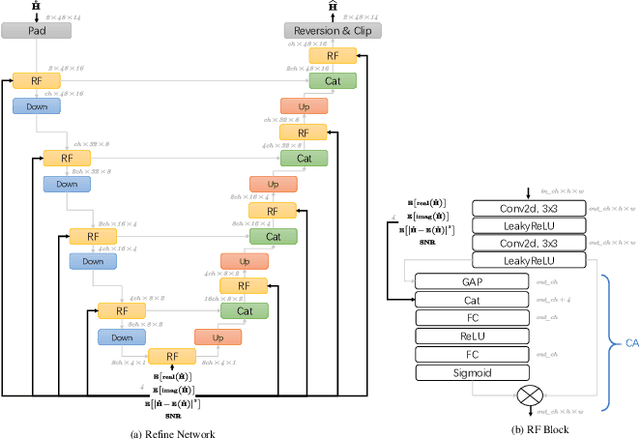
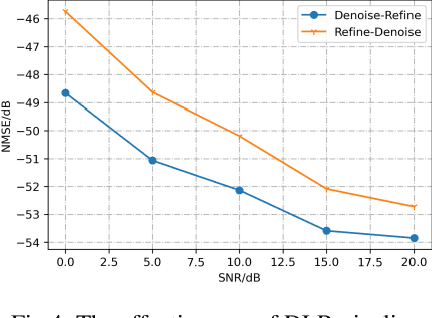
In this paper, we propose a deep learning model for Demodulation Reference Signal (DMRS) based channel estimation task. Specifically, a novel Denoise, Linear interpolation and Refine (DLR) pipeline is proposed to mitigate the noise propagation problem during channel information interpolation and to restore the nonlinear variation of wireless channel over time. At the same time, the Small-norm Sample Cost-sensitive (SSC) learning method is proposed to equalize the qualities of channel estimation under different kinds of wireless environments and improve the channel estimation reliability. The effectiveness of the propose DLR-SSC model is verified on WAIC Dataset. Compared with the well know ChannelNet channel estimation model, our DLR-SSC model reduced normalized mean square error (NMSE) by 27.2dB, 22.4dB and 16.8dB respectively at 0dB, 10dB, and 20dB SNR. The proposed model has won the second place in the 2nd Wireless Communication Artificial Intelligence Competition (WAIC). The code is about to open source.
Light-weight Deformable Registration using Adversarial Learning with Distilling Knowledge
Oct 04, 2021



Deformable registration is a crucial step in many medical procedures such as image-guided surgery and radiation therapy. Most recent learning-based methods focus on improving the accuracy by optimizing the non-linear spatial correspondence between the input images. Therefore, these methods are computationally expensive and require modern graphic cards for real-time deployment. In this paper, we introduce a new Light-weight Deformable Registration network that significantly reduces the computational cost while achieving competitive accuracy. In particular, we propose a new adversarial learning with distilling knowledge algorithm that successfully leverages meaningful information from the effective but expensive teacher network to the student network. We design the student network such as it is light-weight and well suitable for deployment on a typical CPU. The extensively experimental results on different public datasets show that our proposed method achieves state-of-the-art accuracy while significantly faster than recent methods. We further show that the use of our adversarial learning algorithm is essential for a time-efficiency deformable registration method. Finally, our source code and trained models are available at: https://github.com/aioz-ai/LDR_ALDK.
Model-free optimal control of discrete-time systems with additive and multiplicative noises
Aug 20, 2020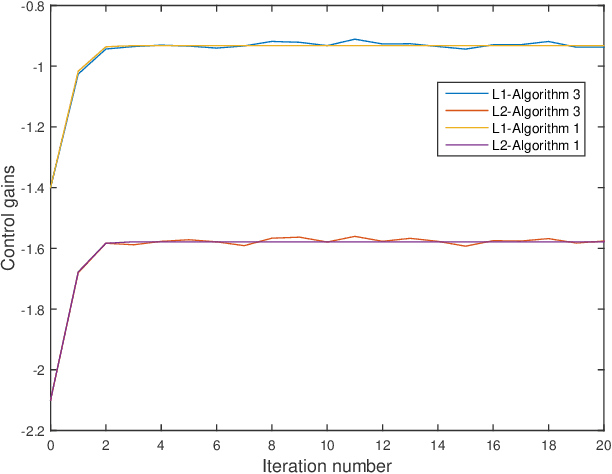
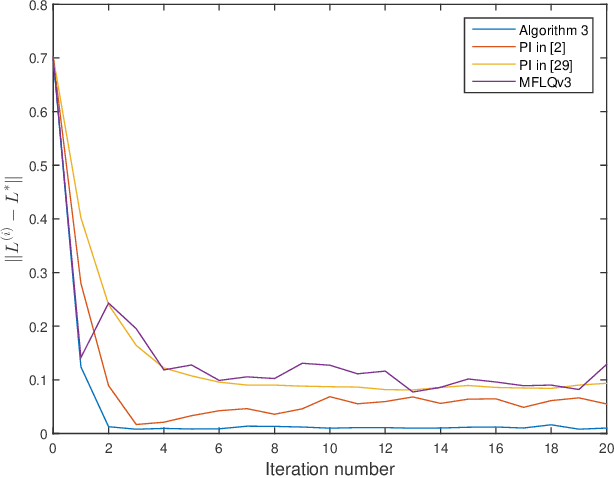
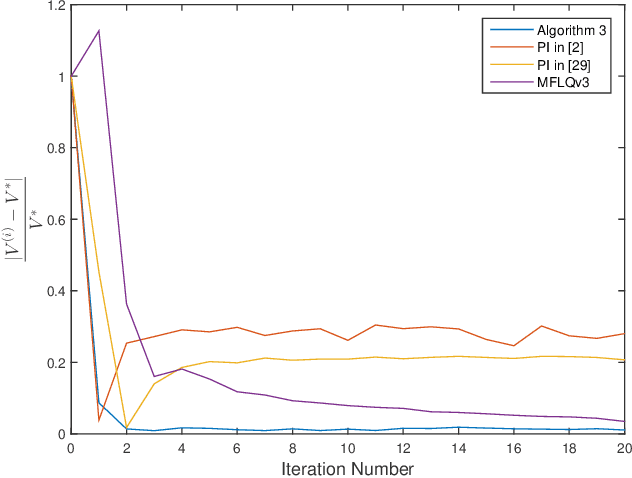
This paper investigates the optimal control problem for a class of discrete-time stochastic systems subject to additive and multiplicative noises. A stochastic Lyapunov equation and a stochastic algebra Riccati equation are established for the existence of the optimal admissible control policy. A model-free reinforcement learning algorithm is proposed to learn the optimal admissible control policy using the data of the system states and inputs without requiring any knowledge of the system matrices. It is proven that the learning algorithm converges to the optimal admissible control policy. The implementation of the model-free algorithm is based on batch least squares and numerical average. The proposed algorithm is illustrated through a numerical example, which shows our algorithm outperforms other policy iteration algorithms.
$\ell_\infty$-Robustness and Beyond: Unleashing Efficient Adversarial Training
Dec 01, 2021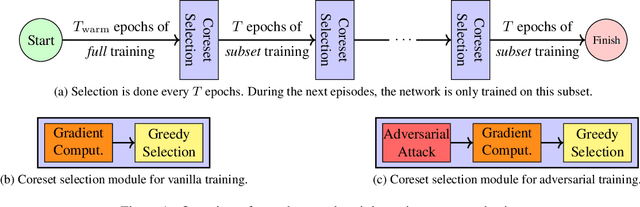

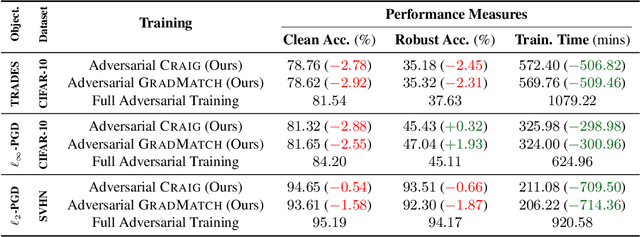
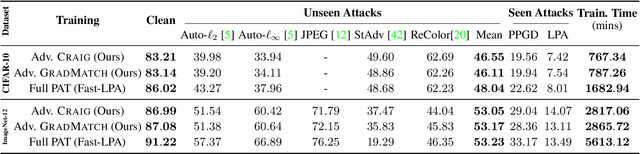
Neural networks are vulnerable to adversarial attacks: adding well-crafted, imperceptible perturbations to their input can modify their output. Adversarial training is one of the most effective approaches in training robust models against such attacks. However, it is much slower than vanilla training of neural networks since it needs to construct adversarial examples for the entire training data at every iteration, which has hampered its effectiveness. Recently, Fast Adversarial Training was proposed that can obtain robust models efficiently. However, the reasons behind its success are not fully understood, and more importantly, it can only train robust models for $\ell_\infty$-bounded attacks as it uses FGSM during training. In this paper, by leveraging the theory of coreset selection we show how selecting a small subset of training data provides a more principled approach towards reducing the time complexity of robust training. Unlike existing methods, our approach can be adapted to a wide variety of training objectives, including TRADES, $\ell_p$-PGD, and Perceptual Adversarial Training. Our experimental results indicate that our approach speeds up adversarial training by 2-3 times, while experiencing a small reduction in the clean and robust accuracy.
Tunable Image Quality Control of 3-D Ultrasound using Switchable CycleGAN
Dec 06, 2021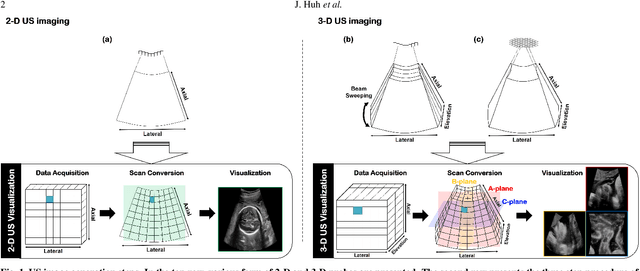
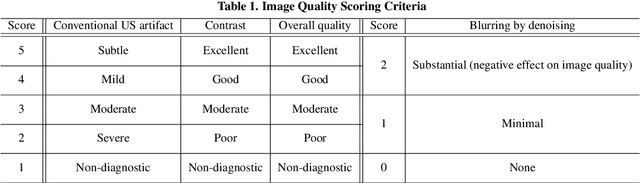
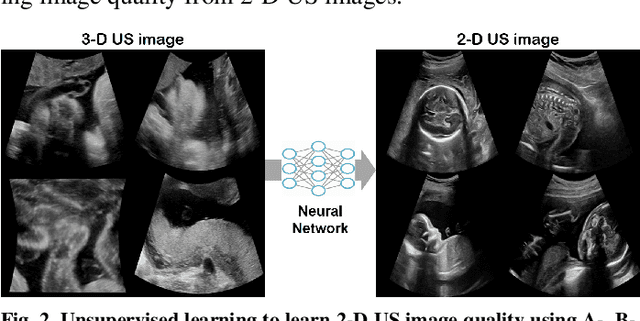
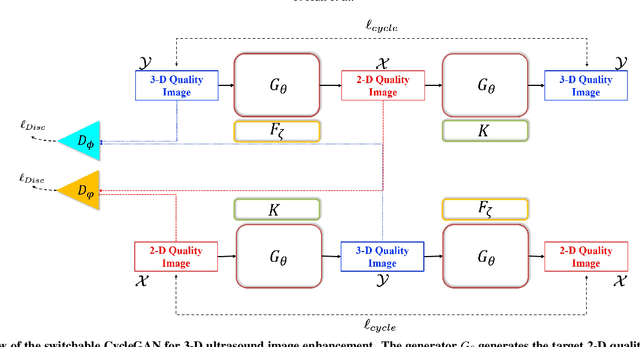
In contrast to 2-D ultrasound (US) for uniaxial plane imaging, a 3-D US imaging system can visualize a volume along three axial planes. This allows for a full view of the anatomy, which is useful for gynecological (GYN) and obstetrical (OB) applications. Unfortunately, the 3-D US has an inherent limitation in resolution compared to the 2-D US. In the case of 3-D US with a 3-D mechanical probe, for example, the image quality is comparable along the beam direction, but significant deterioration in image quality is often observed in the other two axial image planes. To address this, here we propose a novel unsupervised deep learning approach to improve 3-D US image quality. In particular, using {\em unmatched} high-quality 2-D US images as a reference, we trained a recently proposed switchable CycleGAN architecture so that every mapping plane in 3-D US can learn the image quality of 2-D US images. Thanks to the switchable architecture, our network can also provide real-time control of image enhancement level based on user preference, which is ideal for a user-centric scanner setup. Extensive experiments with clinical evaluation confirm that our method offers significantly improved image quality as well user-friendly flexibility.
COVR: A test-bed for Visually Grounded Compositional Generalization with real images
Sep 22, 2021
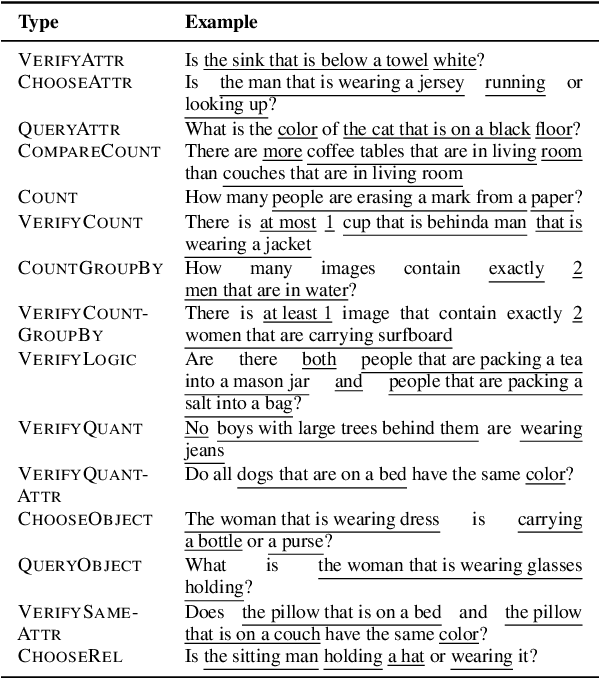
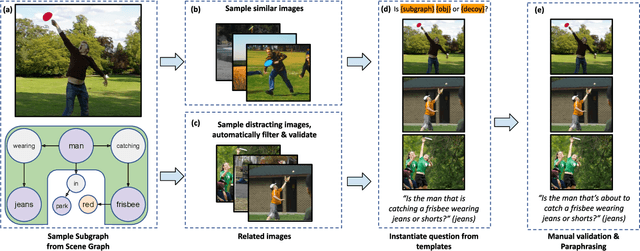
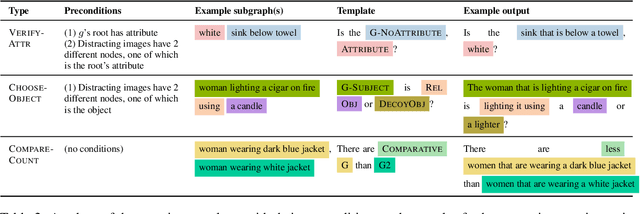
While interest in models that generalize at test time to new compositions has risen in recent years, benchmarks in the visually-grounded domain have thus far been restricted to synthetic images. In this work, we propose COVR, a new test-bed for visually-grounded compositional generalization with real images. To create COVR, we use real images annotated with scene graphs, and propose an almost fully automatic procedure for generating question-answer pairs along with a set of context images. COVR focuses on questions that require complex reasoning, including higher-order operations such as quantification and aggregation. Due to the automatic generation process, COVR facilitates the creation of compositional splits, where models at test time need to generalize to new concepts and compositions in a zero- or few-shot setting. We construct compositional splits using COVR and demonstrate a myriad of cases where state-of-the-art pre-trained language-and-vision models struggle to compositionally generalize.
SenseMag: Enabling Low-Cost Traffic Monitoring using Non-invasive Magnetic Sensing
Oct 24, 2021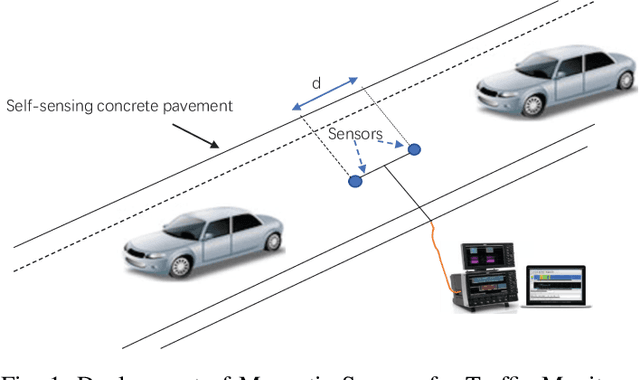

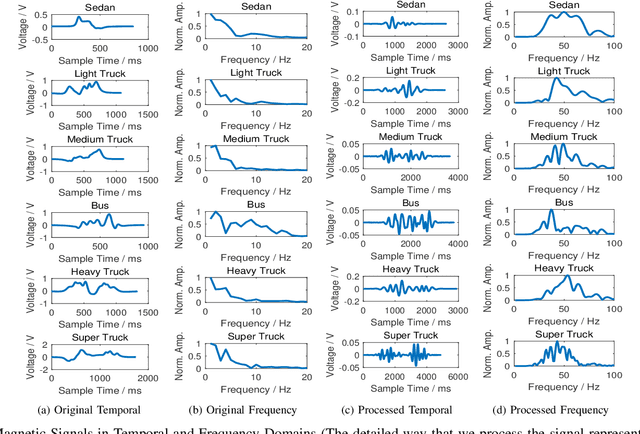
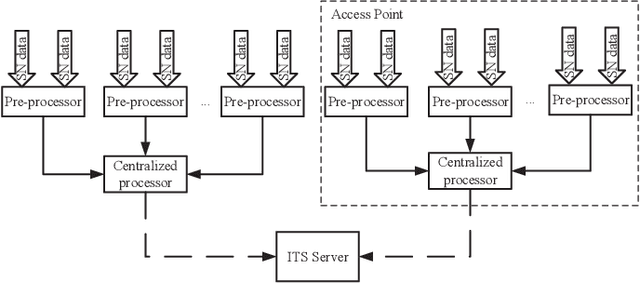
The operation and management of intelligent transportation systems (ITS), such as traffic monitoring, relies on real-time data aggregation of vehicular traffic information, including vehicular types (e.g., cars, trucks, and buses), in the critical roads and highways. While traditional approaches based on vehicular-embedded GPS sensors or camera networks would either invade drivers' privacy or require high deployment cost, this paper introduces a low-cost method, namely SenseMag, to recognize the vehicular type using a pair of non-invasive magnetic sensors deployed on the straight road section. SenseMag filters out noises and segments received magnetic signals by the exact time points that the vehicle arrives or departs from every sensor node. Further, SenseMag adopts a hierarchical recognition model to first estimate the speed/velocity, then identify the length of vehicle using the predicted speed, sampling cycles, and the distance between the sensor nodes. With the vehicle length identified and the temporal/spectral features extracted from the magnetic signals, SenseMag classify the types of vehicles accordingly. Some semi-automated learning techniques have been adopted for the design of filters, features, and the choice of hyper-parameters. Extensive experiment based on real-word field deployment (on the highways in Shenzhen, China) shows that SenseMag significantly outperforms the existing methods in both classification accuracy and the granularity of vehicle types (i.e., 7 types by SenseMag versus 4 types by the existing work in comparisons). To be specific, our field experiment results validate that SenseMag is with at least $90\%$ vehicle type classification accuracy and less than 5\% vehicle length classification error.
A Kernel to Exploit Informative Missingness in Multivariate Time Series from EHRs
Feb 27, 2020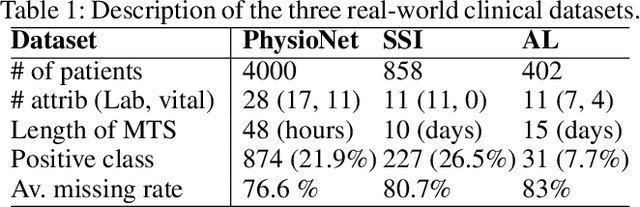
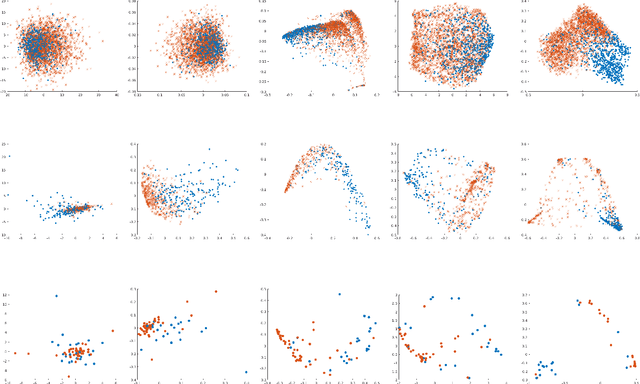
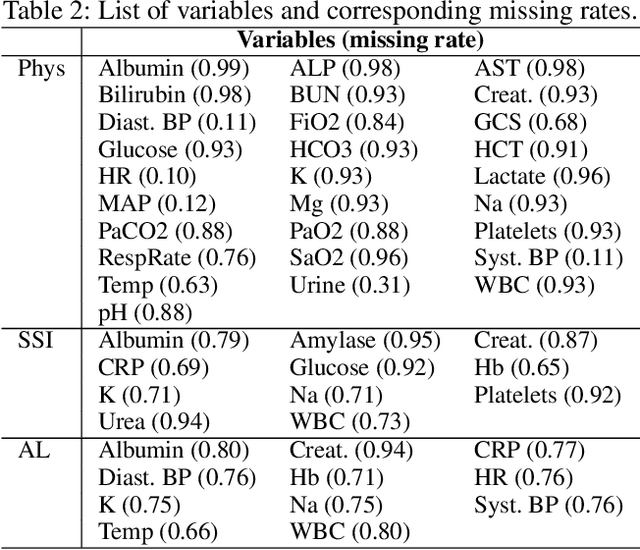
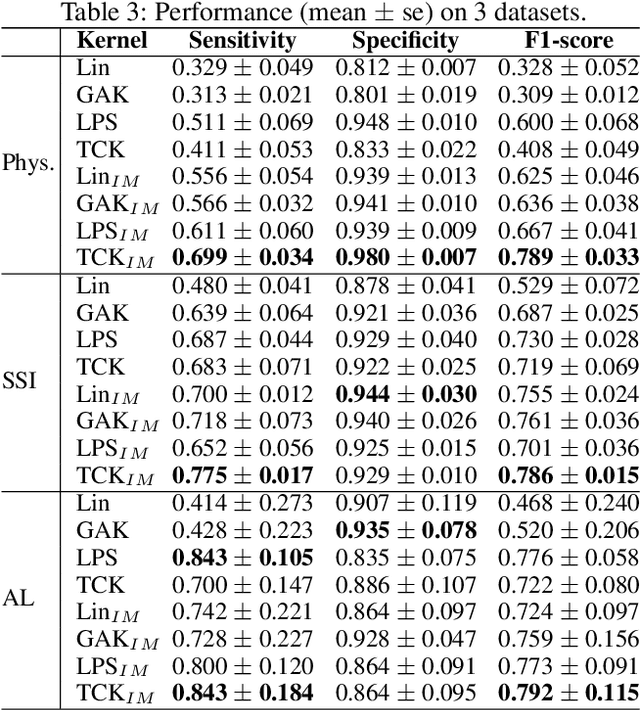
A large fraction of the electronic health records (EHRs) consists of clinical measurements collected over time, such as lab tests and vital signs, which provide important information about a patient's health status. These sequences of clinical measurements are naturally represented as time series, characterized by multiple variables and large amounts of missing data, which complicate the analysis. In this work, we propose a novel kernel which is capable of exploiting both the information from the observed values as well the information hidden in the missing patterns in multivariate time series (MTS) originating e.g. from EHRs. The kernel, called TCK$_{IM}$, is designed using an ensemble learning strategy in which the base models are novel mixed mode Bayesian mixture models which can effectively exploit informative missingness without having to resort to imputation methods. Moreover, the ensemble approach ensures robustness to hyperparameters and therefore TCK$_{IM}$ is particularly well suited if there is a lack of labels - a known challenge in medical applications. Experiments on three real-world clinical datasets demonstrate the effectiveness of the proposed kernel.
An open GPS trajectory dataset and benchmark for travel mode detection
Sep 28, 2021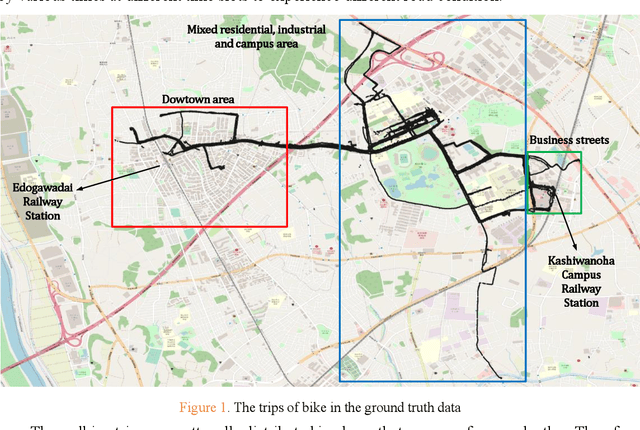
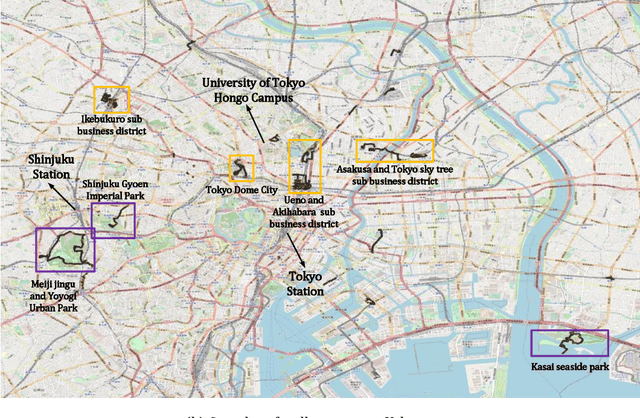
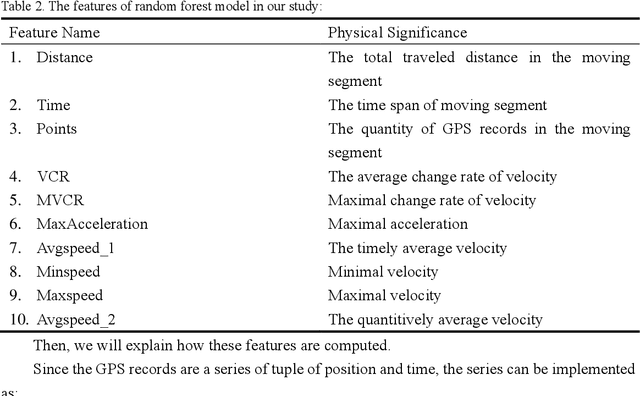
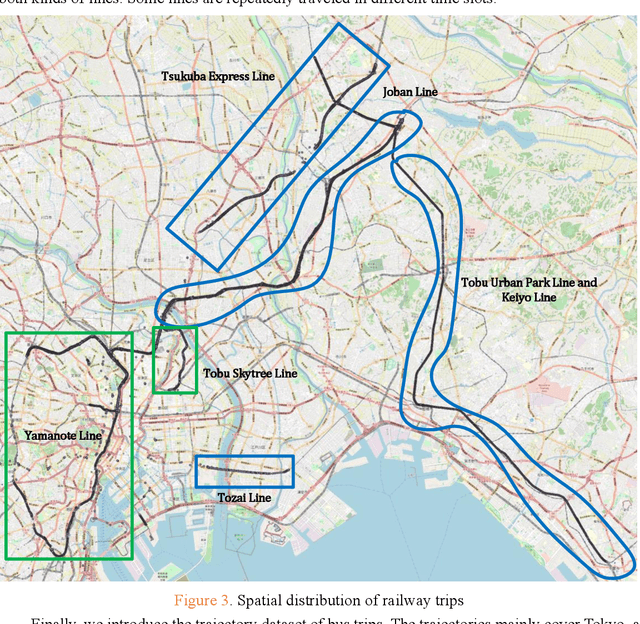
Travel mode detection has been a hot topic in the field of GPS trajectory-related processing. Former scholars have developed many mathematical methods to improve the accuracy of detection. Among these studies, almost all of the methods require ground truth dataset for training. A large amount of the studies choose to collect the GPS trajectory dataset for training by their customized ways. Currently, there is no open GPS dataset marked with travel mode. If there exists one, it will not only save a lot of efforts in model developing, but also help compare the performance of models. In this study, we propose and open GPS trajectory dataset marked with travel mode and benchmark for the travel mode detection. The dataset is collected by 7 independent volunteers in Japan and covers the time period of a complete month. The travel mode ranges from walking to railway. A part of routines are traveled repeatedly in different time slots to experience different road and travel conditions. We also provide a case study to distinguish the walking and bike trips in a massive GPS trajectory dataset.
A Daily Tourism Demand Prediction Framework Based on Multi-head Attention CNN: The Case of The Foreign Entrant in South Korea
Dec 01, 2021
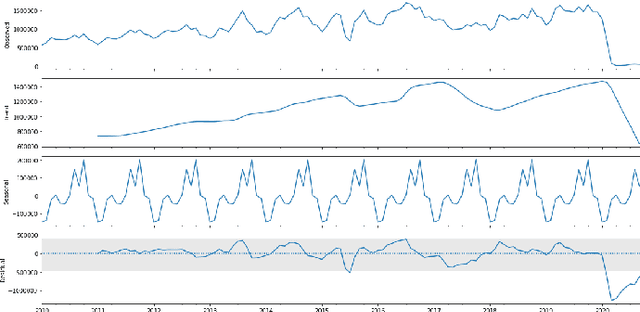
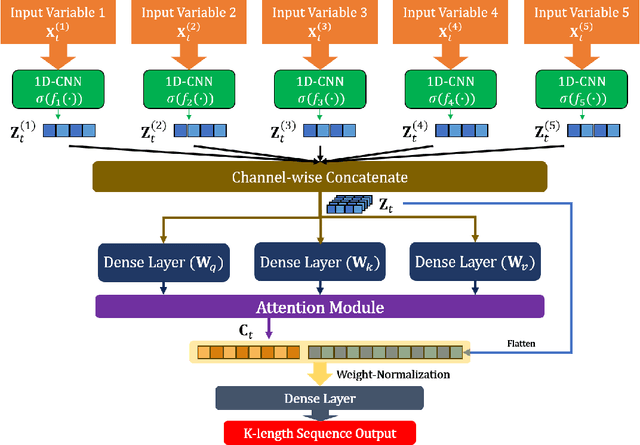
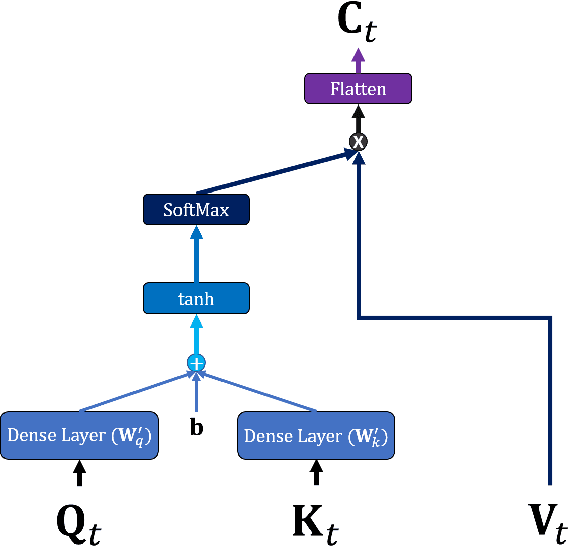
Developing an accurate tourism forecasting model is essential for making desirable policy decisions for tourism management. Early studies on tourism management focus on discovering external factors related to tourism demand. Recent studies utilize deep learning in demand forecasting along with these external factors. They mainly use recursive neural network models such as LSTM and RNN for their frameworks. However, these models are not suitable for use in forecasting tourism demand. This is because tourism demand is strongly affected by changes in various external factors, and recursive neural network models have limitations in handling these multivariate inputs. We propose a multi-head attention CNN model (MHAC) for addressing these limitations. The MHAC uses 1D-convolutional neural network to analyze temporal patterns and the attention mechanism to reflect correlations between input variables. This model makes it possible to extract spatiotemporal characteristics from time-series data of various variables. We apply our forecasting framework to predict inbound tourist changes in South Korea by considering external factors such as politics, disease, season, and attraction of Korean culture. The performance results of extensive experiments show that our method outperforms other deep-learning-based prediction frameworks in South Korea tourism forecasting.