 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MAVE: A Product Dataset for Multi-source Attribute Value Extraction
Dec 16, 2021
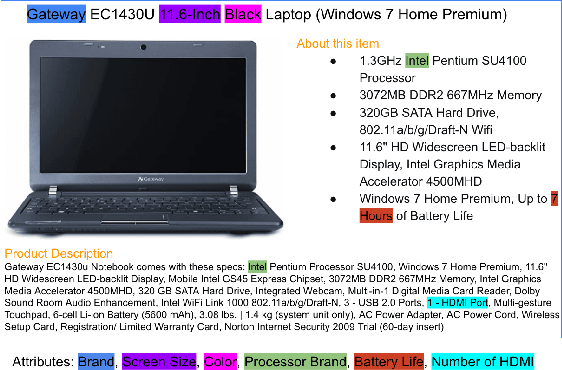
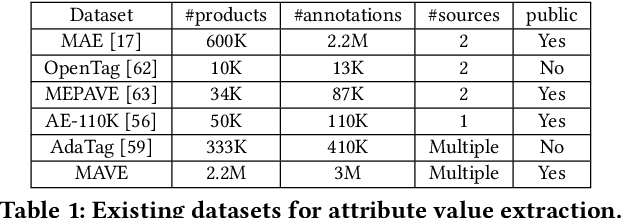

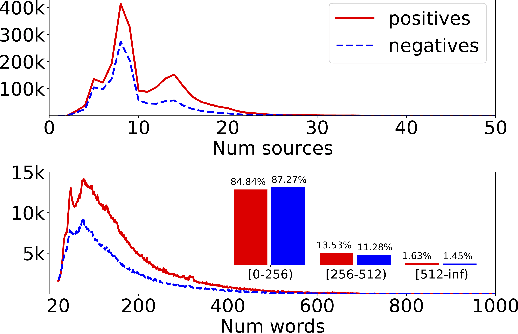
Attribute value extraction refers to the task of identifying values of an attribute of interest from product information. Product attribute values are essential in many e-commerce scenarios, such as customer service robots, product ranking, retrieval and recommendations. While in the real world, the attribute values of a product are usually incomplete and vary over time, which greatly hinders the practical applications. In this paper, we introduce MAVE, a new dataset to better facilitate research on product attribute value extraction. MAVE is composed of a curated set of 2.2 million products from Amazon pages, with 3 million attribute-value annotations across 1257 unique categories. MAVE has four main and unique advantages: First, MAVE is the largest product attribute value extraction dataset by the number of attribute-value examples. Second, MAVE includes multi-source representations from the product, which captures the full product information with high attribute coverage. Third, MAVE represents a more diverse set of attributes and values relative to what previous datasets cover. Lastly, MAVE provides a very challenging zero-shot test set, as we empirically illustrate in the experiments. We further propose a novel approach that effectively extracts the attribute value from the multi-source product information. We conduct extensive experiments with several baselines and show that MAVE is an effective dataset for attribute value extraction task. It is also a very challenging task on zero-shot attribute extraction. Data is available at {\it \url{https://github.com/google-research-datasets/MAVE}}.
Learning Optimal Predictive Checklists
Dec 02, 2021


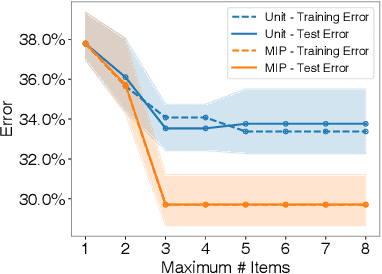
Checklists are simple decision aids that are often used to promote safety and reliability in clinical applications. In this paper, we present a method to learn checklists for clinical decision support. We represent predictive checklists as discrete linear classifiers with binary features and unit weights. We then learn globally optimal predictive checklists from data by solving an integer programming problem. Our method allows users to customize checklists to obey complex constraints, including constraints to enforce group fairness and to binarize real-valued features at training time. In addition, it pairs models with an optimality gap that can inform model development and determine the feasibility of learning sufficiently accurate checklists on a given dataset. We pair our method with specialized techniques that speed up its ability to train a predictive checklist that performs well and has a small optimality gap. We benchmark the performance of our method on seven clinical classification problems, and demonstrate its practical benefits by training a short-form checklist for PTSD screening. Our results show that our method can fit simple predictive checklists that perform well and that can easily be customized to obey a rich class of custom constraints.
Energy-bounded Learning for Robust Models of Code
Dec 20, 2021
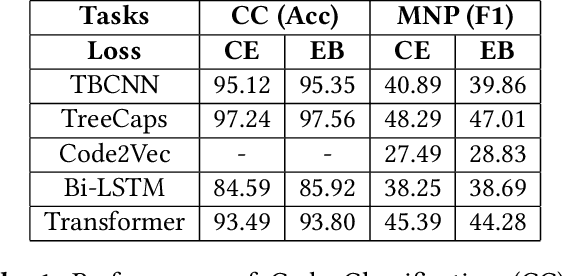
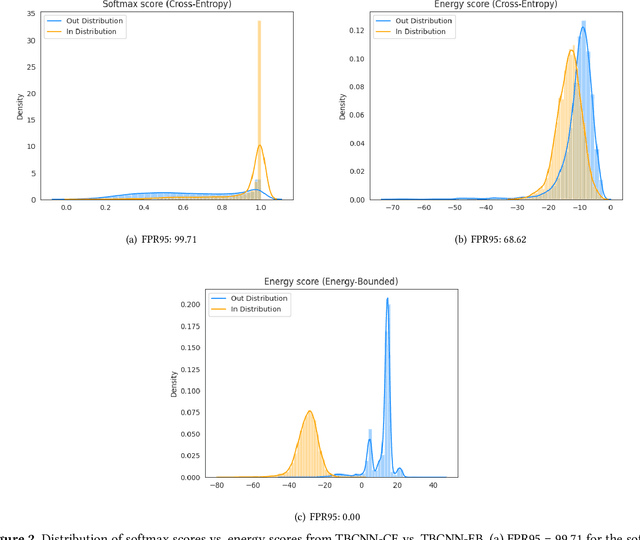

In programming, learning code representations has a variety of applications, including code classification, code search, comment generation, bug prediction, and so on. Various representations of code in terms of tokens, syntax trees, dependency graphs, code navigation paths, or a combination of their variants have been proposed, however, existing vanilla learning techniques have a major limitation in robustness, i.e., it is easy for the models to make incorrect predictions when the inputs are altered in a subtle way. To enhance the robustness, existing approaches focus on recognizing adversarial samples rather than on the valid samples that fall outside a given distribution, which we refer to as out-of-distribution (OOD) samples. Recognizing such OOD samples is the novel problem investigated in this paper. To this end, we propose to first augment the in=distribution datasets with out-of-distribution samples such that, when trained together, they will enhance the model's robustness. We propose the use of an energy-bounded learning objective function to assign a higher score to in-distribution samples and a lower score to out-of-distribution samples in order to incorporate such out-of-distribution samples into the training process of source code models. In terms of OOD detection and adversarial samples detection, our evaluation results demonstrate a greater robustness for existing source code models to become more accurate at recognizing OOD data while being more resistant to adversarial attacks at the same time. Furthermore, the proposed energy-bounded score outperforms all existing OOD detection scores by a large margin, including the softmax confidence score, the Mahalanobis score, and ODIN.
Ground-Truth, Whose Truth? -- Examining the Challenges with Annotating Toxic Text Datasets
Dec 07, 2021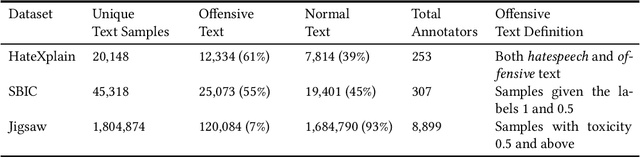
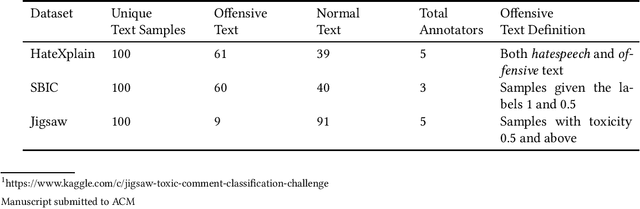
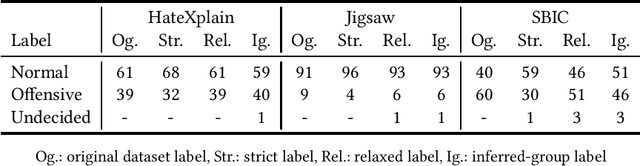

The use of machine learning (ML)-based language models (LMs) to monitor content online is on the rise. For toxic text identification, task-specific fine-tuning of these models are performed using datasets labeled by annotators who provide ground-truth labels in an effort to distinguish between offensive and normal content. These projects have led to the development, improvement, and expansion of large datasets over time, and have contributed immensely to research on natural language. Despite the achievements, existing evidence suggests that ML models built on these datasets do not always result in desirable outcomes. Therefore, using a design science research (DSR) approach, this study examines selected toxic text datasets with the goal of shedding light on some of the inherent issues and contributing to discussions on navigating these challenges for existing and future projects. To achieve the goal of the study, we re-annotate samples from three toxic text datasets and find that a multi-label approach to annotating toxic text samples can help to improve dataset quality. While this approach may not improve the traditional metric of inter-annotator agreement, it may better capture dependence on context and diversity in annotators. We discuss the implications of these results for both theory and practice.
Real-Time Camera Pose Estimation for Sports Fields
Mar 31, 2020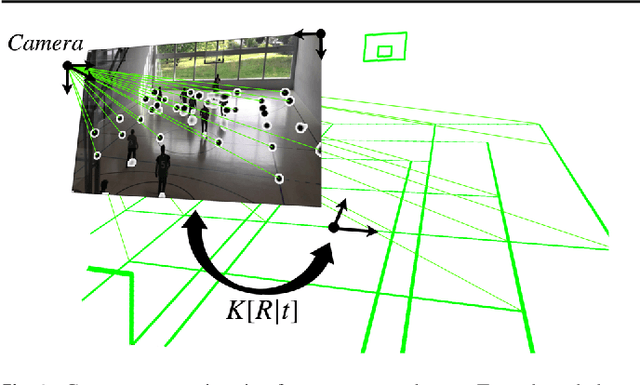
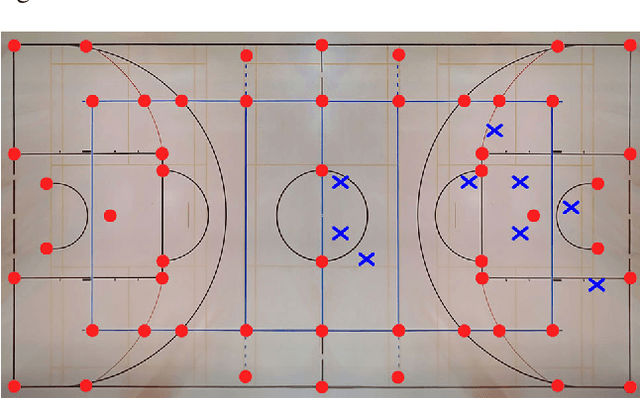
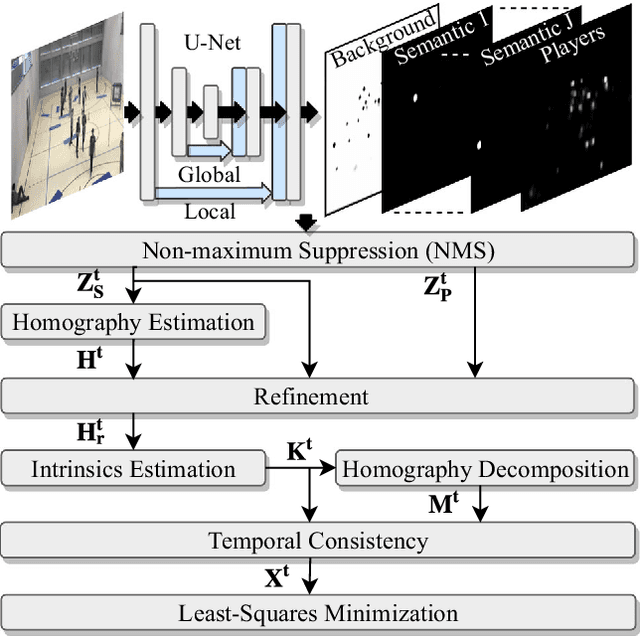
Given an image sequence featuring a portion of a sports field filmed by a moving and uncalibrated camera, such as the one of the smartphones, our goal is to compute automatically in real time the focal length and extrinsic camera parameters for each image in the sequence without using a priori knowledges of the position and orientation of the camera. To this end, we propose a novel framework that combines accurate localization and robust identification of specific keypoints in the image by using a fully convolutional deep architecture. Our algorithm exploits both the field lines and the players' image locations, assuming their ground plane positions to be given, to achieve accuracy and robustness that is beyond the current state of the art. We will demonstrate its effectiveness on challenging soccer, basketball, and volleyball benchmark datasets.
HSPACE: Synthetic Parametric Humans Animated in Complex Environments
Dec 23, 2021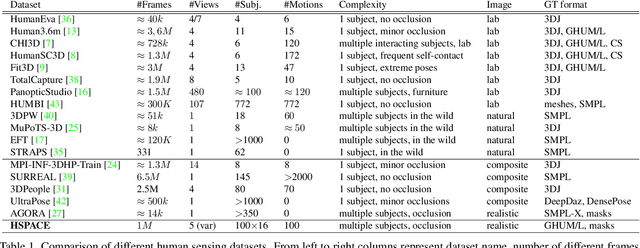
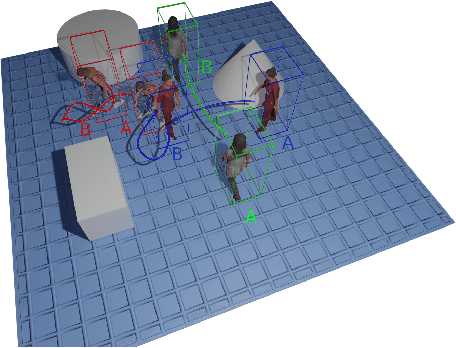
Advances in the state of the art for 3d human sensing are currently limited by the lack of visual datasets with 3d ground truth, including multiple people, in motion, operating in real-world environments, with complex illumination or occlusion, and potentially observed by a moving camera. Sophisticated scene understanding would require estimating human pose and shape as well as gestures, towards representations that ultimately combine useful metric and behavioral signals with free-viewpoint photo-realistic visualisation capabilities. To sustain progress, we build a large-scale photo-realistic dataset, Human-SPACE (HSPACE), of animated humans placed in complex synthetic indoor and outdoor environments. We combine a hundred diverse individuals of varying ages, gender, proportions, and ethnicity, with hundreds of motions and scenes, as well as parametric variations in body shape (for a total of 1,600 different humans), in order to generate an initial dataset of over 1 million frames. Human animations are obtained by fitting an expressive human body model, GHUM, to single scans of people, followed by novel re-targeting and positioning procedures that support the realistic animation of dressed humans, statistical variation of body proportions, and jointly consistent scene placement of multiple moving people. Assets are generated automatically, at scale, and are compatible with existing real time rendering and game engines. The dataset with evaluation server will be made available for research. Our large-scale analysis of the impact of synthetic data, in connection with real data and weak supervision, underlines the considerable potential for continuing quality improvements and limiting the sim-to-real gap, in this practical setting, in connection with increased model capacity.
Self-Attention for Raw Optical Satellite Time Series Classification
Oct 23, 2019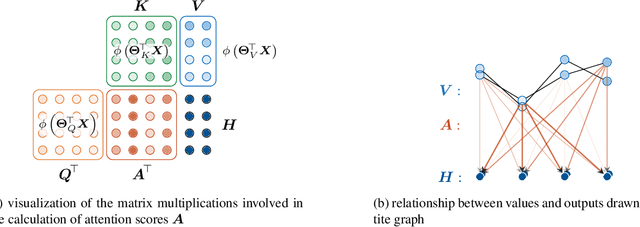
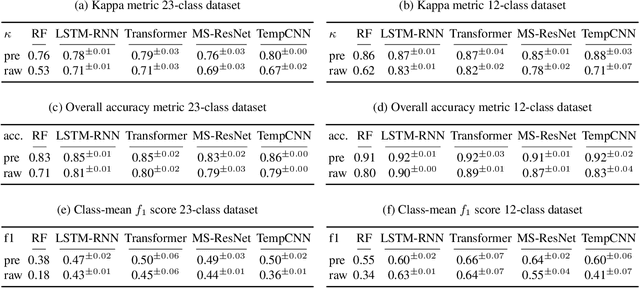
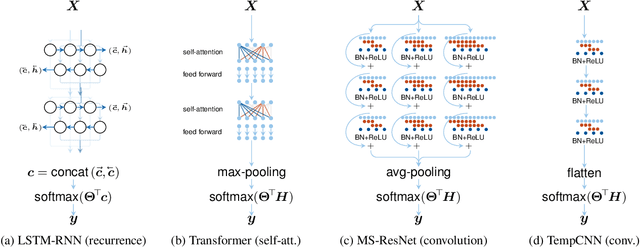
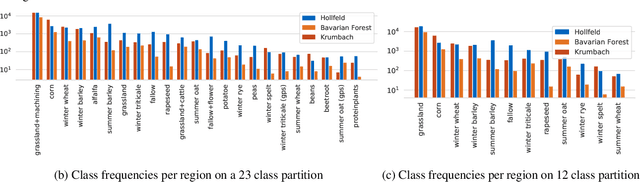
Deep learning methods have received increasing interest by the remote sensing community for multi-temporal land cover classification in recent years. Convolutional Neural networks that elementwise compare a time series with learned kernels, and recurrent neural networks that sequentially process temporal data have dominated the state-of-the-art in the classification of vegetation from satellite time series. Self-attention allows a neural network to selectively extract features from specific times in the input sequence thus suppressing non-classification relevant information. Today, self-attention based neural networks dominate the state-of-the-art in natural language processing but are hardly explored and tested in the remote sensing context. In this work, we embed self-attention in the canon of deep learning mechanisms for satellite time series classification for vegetation modeling and crop type identification. We compare it quantitatively to convolution, and recurrence and test four models that each exclusively relies on one of these mechanisms. The models are trained to identify the type of vegetation on crop parcels using raw and preprocessed Sentinel 2 time series over one entire year. To obtain an objective measure we find the best possible performance for each of the models by a large-scale hyperparameter search with more than 2400 validation runs. Beyond the quantitative comparison, we qualitatively analyze the models by an easy-to-implement, but yet effective feature importance analysis based on gradient back-propagation that exploits the differentiable nature of deep learning models. Finally, we look into the self-attention transformer model and visualize attention scores as bipartite graphs in the context of the input time series and a low-dimensional representation of internal hidden states using t-distributed stochastic neighborhood embedding (t-SNE).
A theoretical and empirical study of new adaptive algorithms with additional momentum steps and shifted updates for stochastic non-convex optimization
Oct 16, 2021
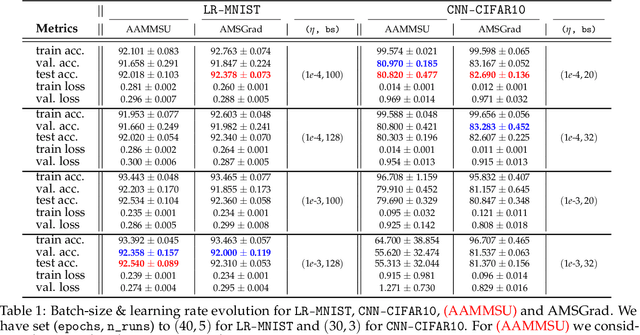
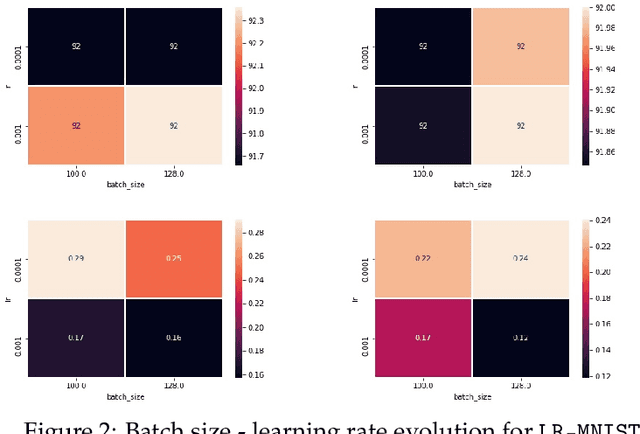
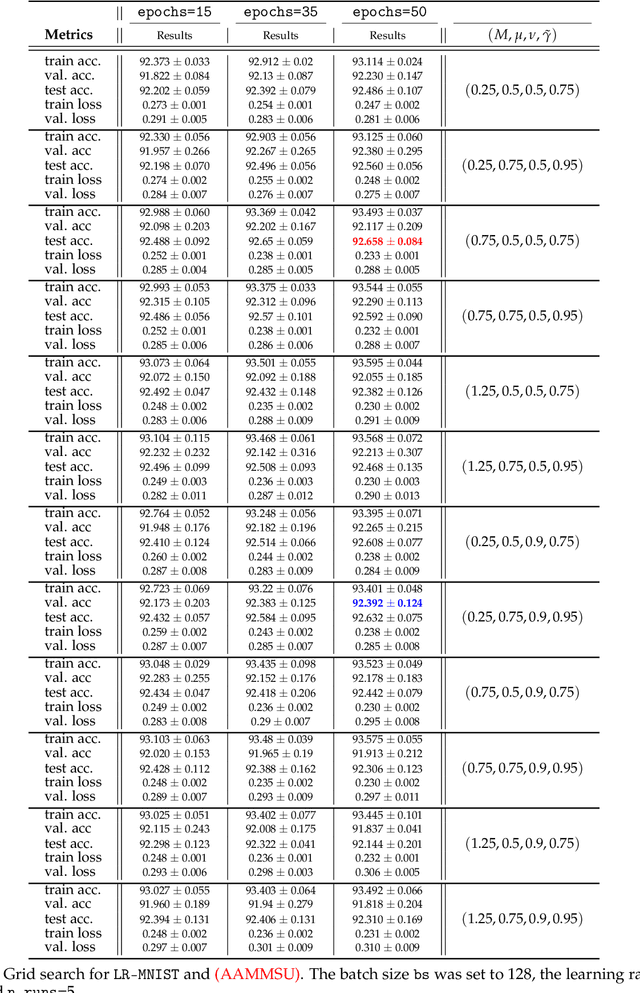
In the following paper we introduce new adaptive algorithms endowed with momentum terms for stochastic non-convex optimization problems. We investigate the almost sure convergence to stationary points, along with a finite-time horizon analysis with respect to a chosen final iteration, and we also inspect the worst-case iteration complexity. An estimate for the expectation of the squared Euclidean norm of the gradient is given and the theoretical analysis that we perform is assisted by various computational simulations for neural network training.
Surrogate Modelling for Injection Molding Processes using Machine Learning
Jul 30, 2021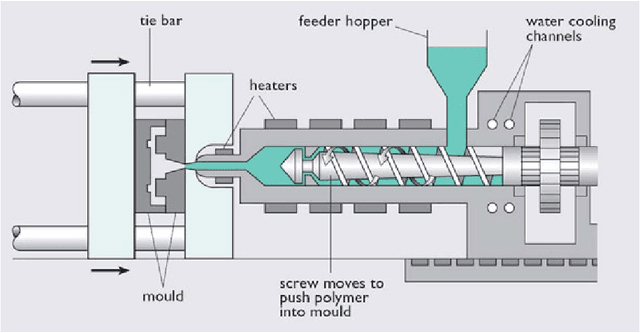
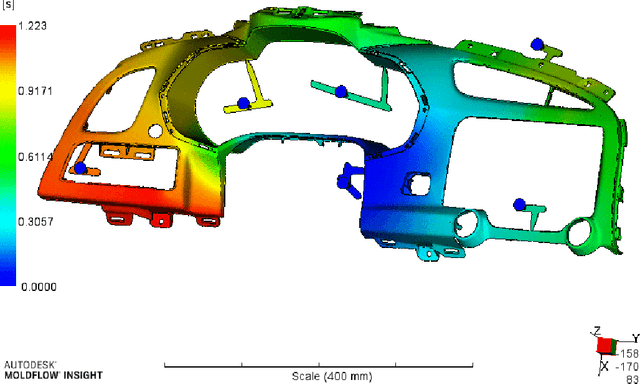

Injection molding is one of the most popular manufacturing methods for the modeling of complex plastic objects. Faster numerical simulation of the technological process would allow for faster and cheaper design cycles of new products. In this work, we propose a baseline for a data processing pipeline that includes the extraction of data from Moldflow simulation projects and the prediction of the fill time and deflection distributions over 3-dimensional surfaces using machine learning models. We propose algorithms for engineering of features, including information of injector gates parameters that will mostly affect the time for plastic to reach the particular point of the form for fill time prediction, and geometrical features for deflection prediction. We propose and evaluate baseline machine learning models for fill time and deflection distribution prediction and provide baseline values of MSE and RMSE metrics. Finally, we measure the execution time of our solution and show that it significantly exceeds the time of simulation with Moldflow software: approximately 17 times and 14 times faster for mean and median total times respectively, comparing the times of all analysis stages for deflection prediction. Our solution has been implemented in a prototype web application that was approved by the management board of Fiat Chrysler Automobiles and Illogic SRL. As one of the promising applications of this surrogate modelling approach, we envision the use of trained models as a fast objective function in the task of optimization of technological parameters of the injection molding process (meaning optimal placement of gates), which could significantly aid engineers in this task, or even automate it.
Fusion of Sensor Measurements and Target-Provided Information in Multitarget Tracking
Nov 26, 2021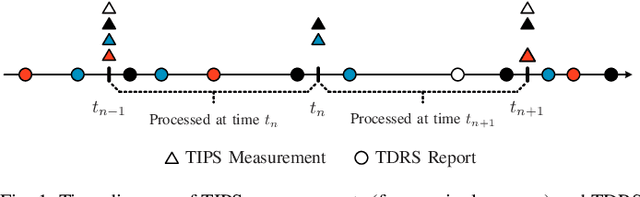
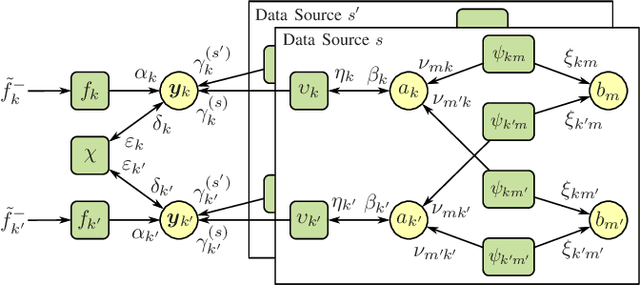
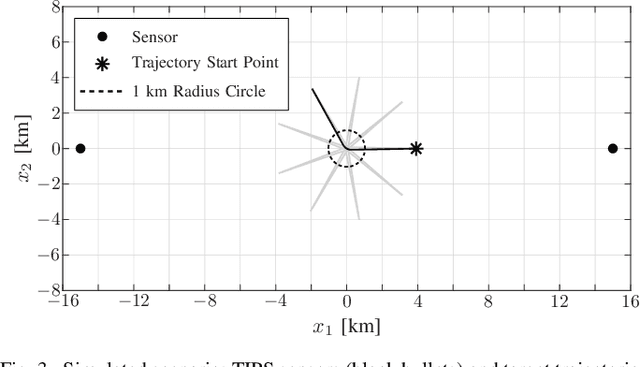
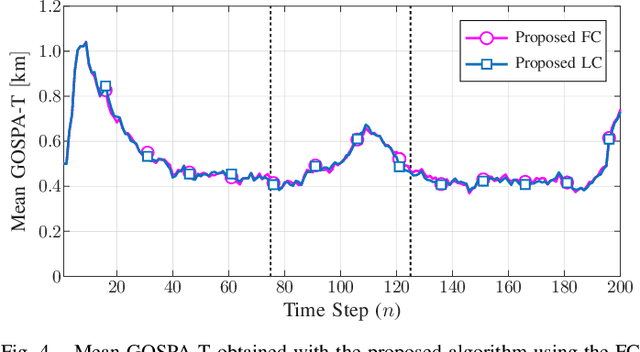
Tracking multiple time-varying states based on heterogeneous observations is a key problem in many applications. Here, we develop a statistical model and algorithm for tracking an unknown number of targets based on the probabilistic fusion of observations from two classes of data sources. The first class, referred to as target-independent perception systems (TIPSs), consists of sensors that periodically produce noisy measurements of targets without requiring target cooperation. The second class, referred to as target-dependent reporting systems (TDRSs), relies on cooperative targets that report noisy measurements of their state and their identity. We present a joint TIPS-TDRS observation model that accounts for observation-origin uncertainty, missed detections, false alarms, and asynchronicity. We then establish a factor graph that represents this observation model along with a state evolution model including target identities. Finally, by executing the sum-product algorithm on that factor graph, we obtain a scalable multitarget tracking algorithm with inherent TIPS-TDRS fusion. The performance of the proposed algorithm is evaluated using simulated data as well as real data from a maritime surveillance experiment.