 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSome notes concerning a generalized KMM-type optimization method for density ratio estimation
Sep 14, 2023In the present paper we introduce new optimization algorithms for the task of density ratio estimation. More precisely, we consider extending the well-known KMM method using the construction of a suitable loss function, in order to encompass more general situations involving the estimation of density ratio with respect to subsets of the training data and test data, respectively. The associated codes can be found at https://github.com/CDAlecsa/Generalized-KMM.
OF-AE: Oblique Forest AutoEncoders
Jan 02, 2023In the present work we propose an unsupervised ensemble method consisting of oblique trees that can address the task of auto-encoding, namely Oblique Forest AutoEncoders (briefly OF-AE). Our method is a natural extension of the eForest encoder introduced in [1]. More precisely, by employing oblique splits consisting in multivariate linear combination of features instead of the axis-parallel ones, we will devise an auto-encoder method through the computation of a sparse solution of a set of linear inequalities consisting of feature values constraints. The code for reproducing our results is available at https://github.com/CDAlecsa/Oblique-Forest-AutoEncoders.
A theoretical and empirical study of new adaptive algorithms with additional momentum steps and shifted updates for stochastic non-convex optimization
Oct 16, 2021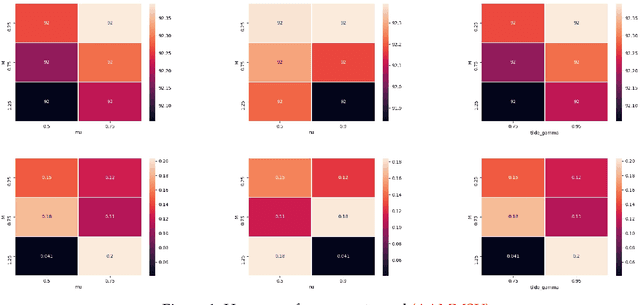
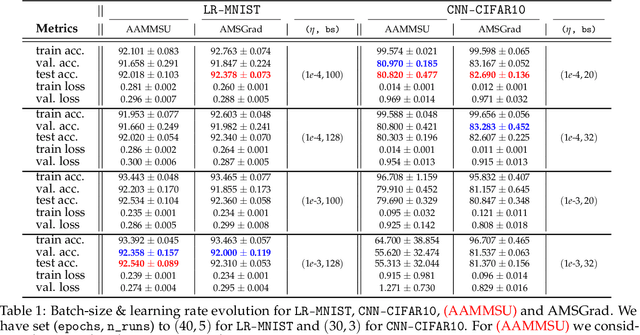
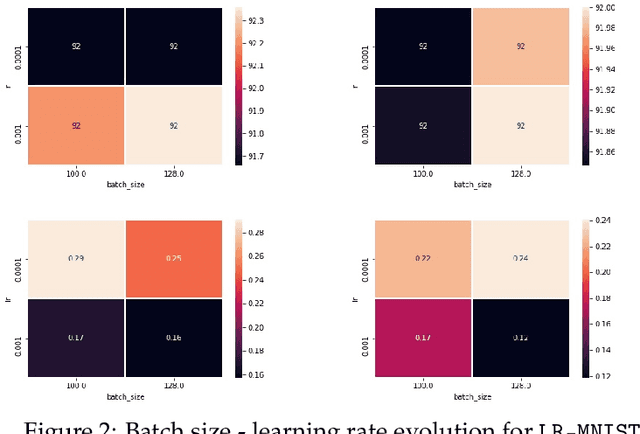
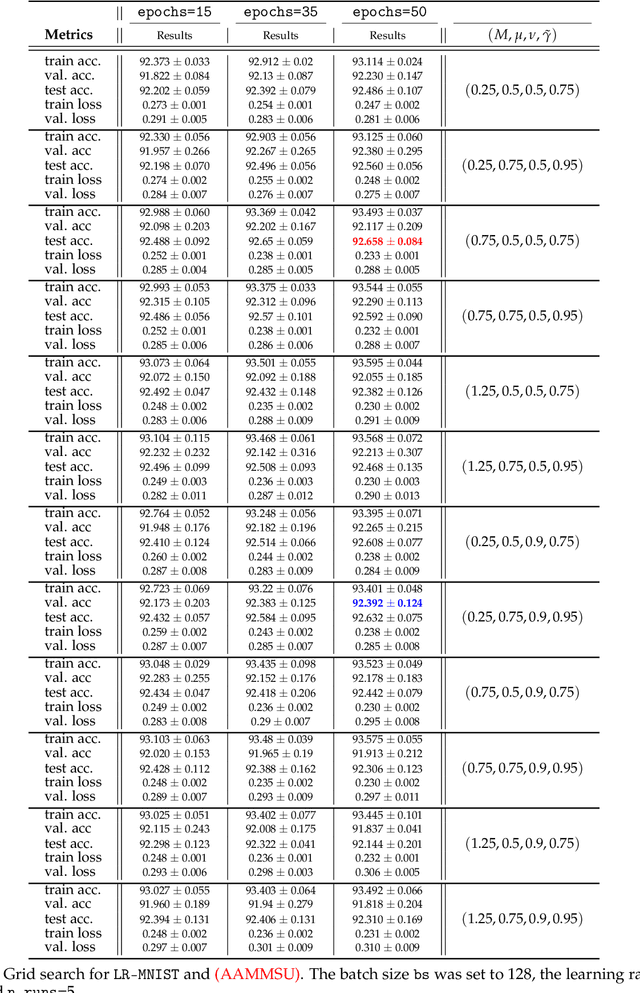
In the following paper we introduce new adaptive algorithms endowed with momentum terms for stochastic non-convex optimization problems. We investigate the almost sure convergence to stationary points, along with a finite-time horizon analysis with respect to a chosen final iteration, and we also inspect the worst-case iteration complexity. An estimate for the expectation of the squared Euclidean norm of the gradient is given and the theoretical analysis that we perform is assisted by various computational simulations for neural network training.
New optimization algorithms for neural network training using operator splitting techniques
Apr 29, 2019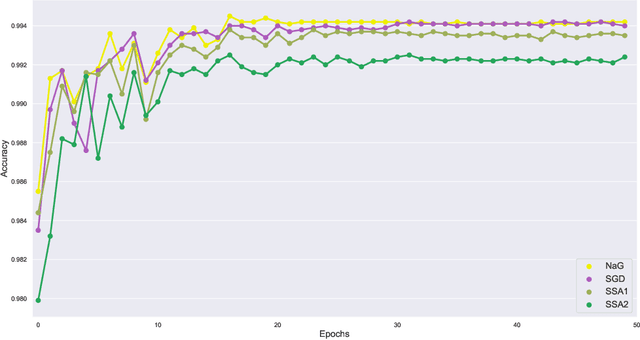
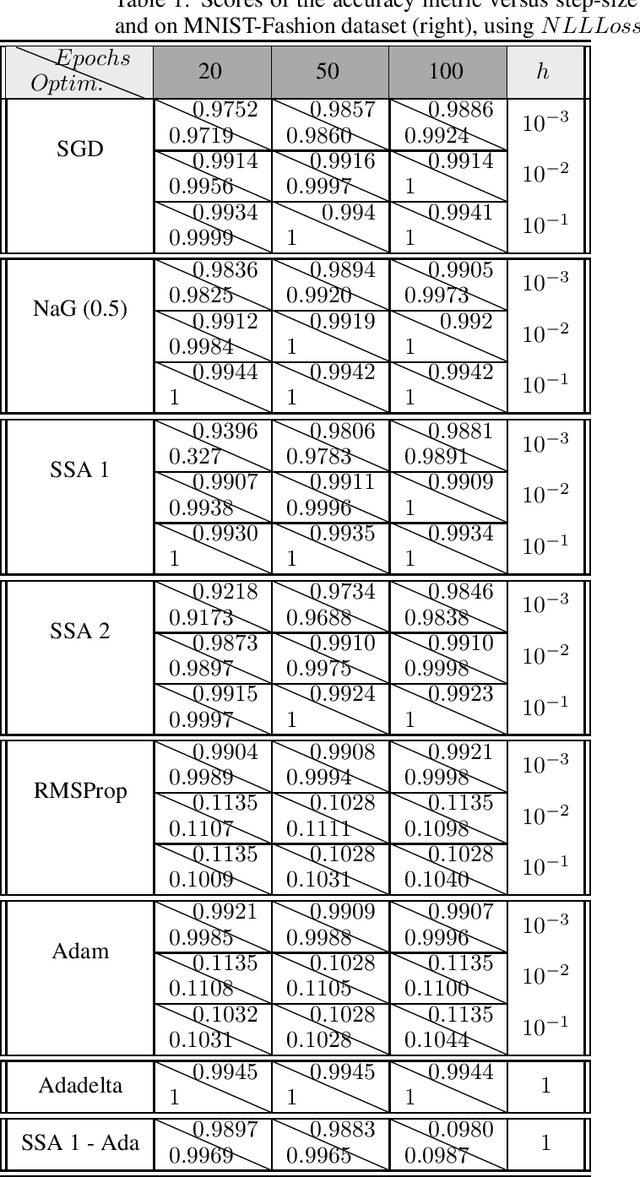
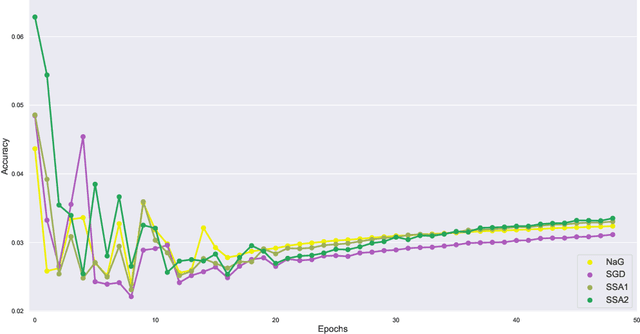
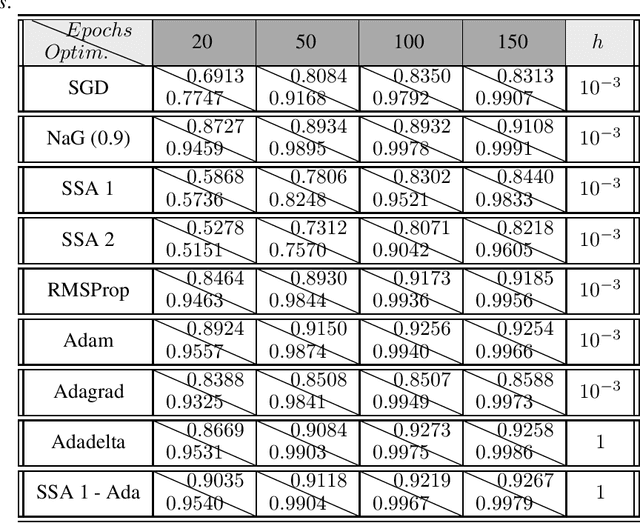
In the following paper we present a new type of optimization algorithms adapted for neural network training. These algorithms are based upon sequential operator splitting technique for some associated dynamical systems. Furthermore, we investigate through numerical simulations the empirical rate of convergence of these iterative schemes toward a local minimum of the loss function, with some suitable choices of the underlying hyper-parameters. We validate the convergence of these optimizers using the results of the accuracy and of the loss function on the MNIST, MNIST-Fashion and CIFAR 10 classification datasets.