 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
E$^2$(GO)MOTION: Motion Augmented Event Stream for Egocentric Action Recognition
Dec 07, 2021

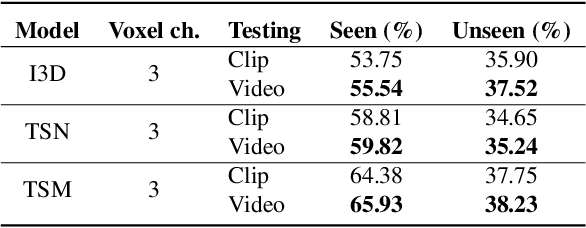


Event cameras are novel bio-inspired sensors, which asynchronously capture pixel-level intensity changes in the form of "events". Due to their sensing mechanism, event cameras have little to no motion blur, a very high temporal resolution and require significantly less power and memory than traditional frame-based cameras. These characteristics make them a perfect fit to several real-world applications such as egocentric action recognition on wearable devices, where fast camera motion and limited power challenge traditional vision sensors. However, the ever-growing field of event-based vision has, to date, overlooked the potential of event cameras in such applications. In this paper, we show that event data is a very valuable modality for egocentric action recognition. To do so, we introduce N-EPIC-Kitchens, the first event-based camera extension of the large-scale EPIC-Kitchens dataset. In this context, we propose two strategies: (i) directly processing event-camera data with traditional video-processing architectures (E$^2$(GO)) and (ii) using event-data to distill optical flow information (E$^2$(GO)MO). On our proposed benchmark, we show that event data provides a comparable performance to RGB and optical flow, yet without any additional flow computation at deploy time, and an improved performance of up to 4% with respect to RGB only information.
META: Mimicking Embedding via oThers' Aggregation for Generalizable Person Re-identification
Dec 16, 2021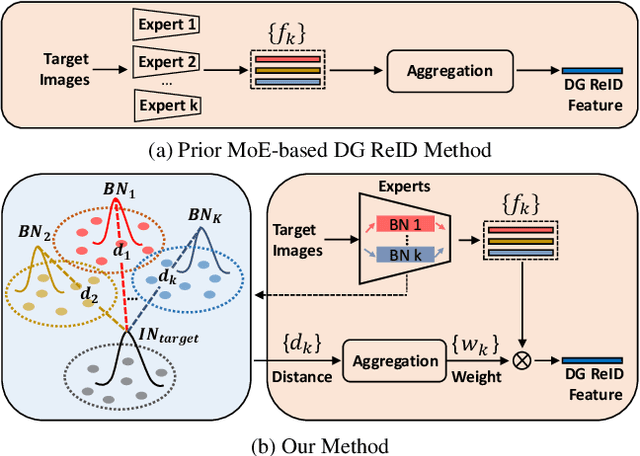
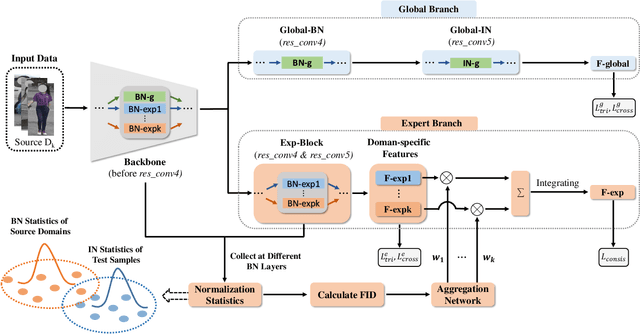
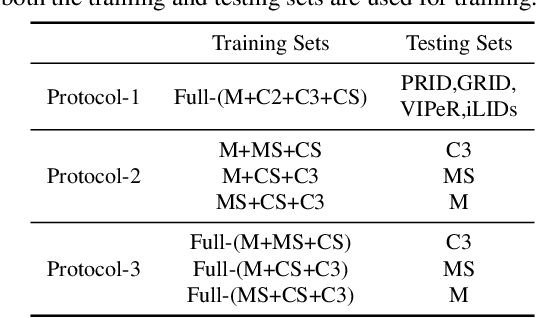
Domain generalizable (DG) person re-identification (ReID) aims to test across unseen domains without access to the target domain data at training time, which is a realistic but challenging problem. In contrast to methods assuming an identical model for different domains, Mixture of Experts (MoE) exploits multiple domain-specific networks for leveraging complementary information between domains, obtaining impressive results. However, prior MoE-based DG ReID methods suffer from a large model size with the increase of the number of source domains, and most of them overlook the exploitation of domain-invariant characteristics. To handle the two issues above, this paper presents a new approach called Mimicking Embedding via oThers' Aggregation (META) for DG ReID. To avoid the large model size, experts in META do not add a branch network for each source domain but share all the parameters except for the batch normalization layers. Besides multiple experts, META leverages Instance Normalization (IN) and introduces it into a global branch to pursue invariant features across domains. Meanwhile, META considers the relevance of an unseen target sample and source domains via normalization statistics and develops an aggregation network to adaptively integrate multiple experts for mimicking unseen target domain. Benefiting from a proposed consistency loss and an episodic training algorithm, we can expect META to mimic embedding for a truly unseen target domain. Extensive experiments verify that META surpasses state-of-the-art DG ReID methods by a large margin.
Data-Driven Interaction Analysis of Line Failure Cascading in Power Grid Networks
Dec 02, 2021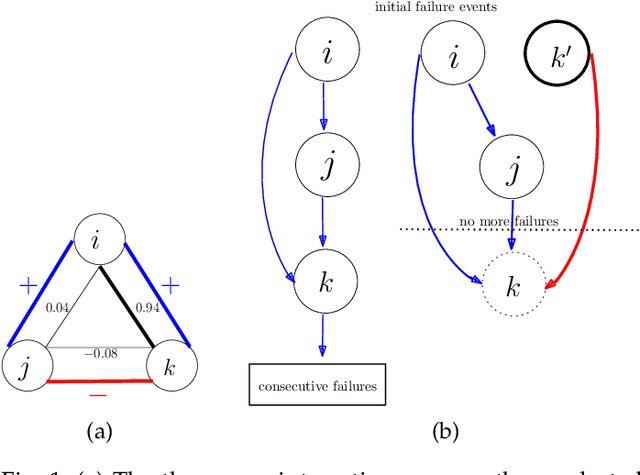
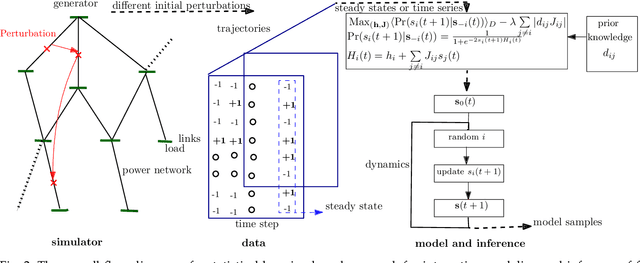
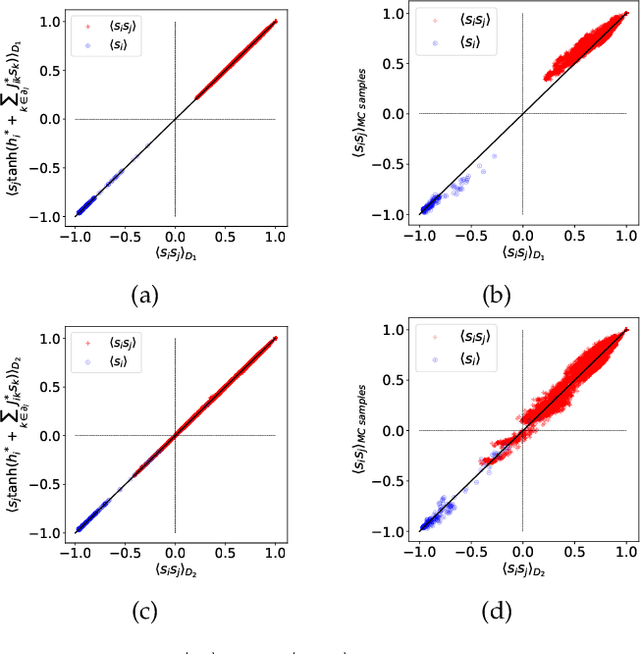
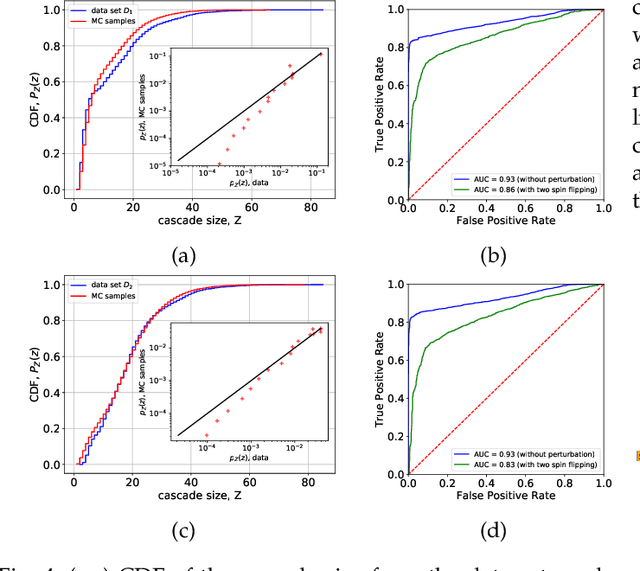
We use machine learning tools to model the line interaction of failure cascading in power grid networks. We first collect data sets of simulated trajectories of possible consecutive line failure following an initial random failure and considering actual constraints in a model power network until the system settles at a steady state. We use weighted $l_1$-regularized logistic regression-based models to find static and dynamic models that capture pairwise and latent higher-order lines' failure interactions using pairwise statistical data. The static model captures the failures' interactions near the steady states of the network, and the dynamic model captures the failure unfolding in a time series of consecutive network states. We test models over independent trajectories of failure unfolding in the network to evaluate their failure predictive power. We observe asymmetric, strongly positive, and negative interactions between different lines' states in the network. We use the static interaction model to estimate the distribution of cascade size and identify groups of lines that tend to fail together, and compare against the data. The dynamic interaction model successfully predicts the network state for long-lasting failure propagation trajectories after an initial failure.
BeautifAI -- A Personalised Occasion-oriented Makeup Recommendation System
Sep 13, 2021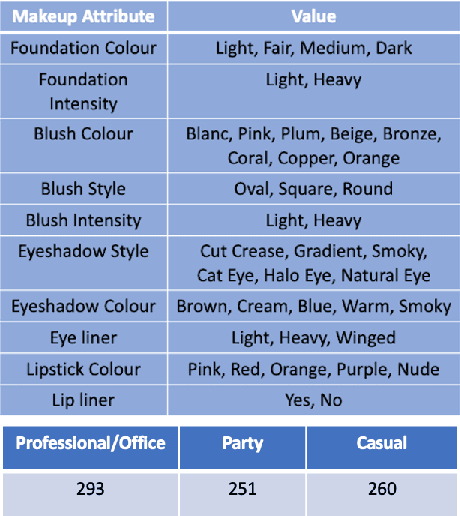
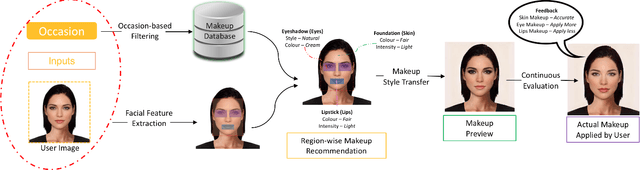
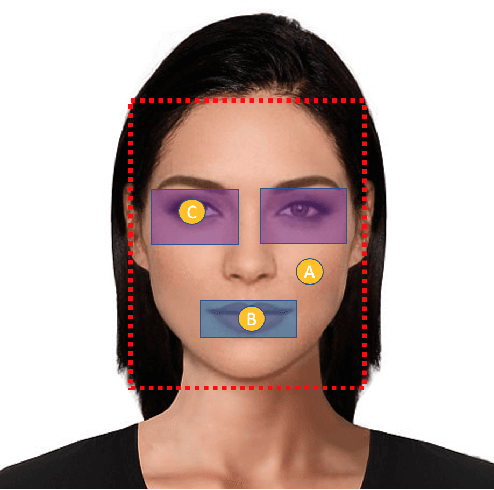

With the global metamorphosis of the beauty industry and the rising demand for beauty products worldwide, the need for an efficacious makeup recommendation system has never been more. Despite the significant advancements made towards personalised makeup recommendation, the current research still falls short of incorporating the context of occasion in makeup recommendation and integrating feedback for users. In this work, we propose BeautifAI, a novel makeup recommendation system, delivering personalised occasion-oriented makeup recommendations to users while providing real-time previews and continuous feedback. The proposed work's novel contributions, including the incorporation of occasion context, region-wise makeup recommendation, real-time makeup previews and continuous makeup feedback, set our system apart from the current work in makeup recommendation. We also demonstrate our proposed system's efficacy in providing personalised makeup recommendation by conducting a user study.
The Impact of Batch Learning in Stochastic Bandits
Nov 03, 2021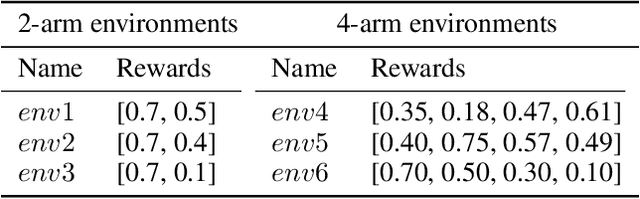
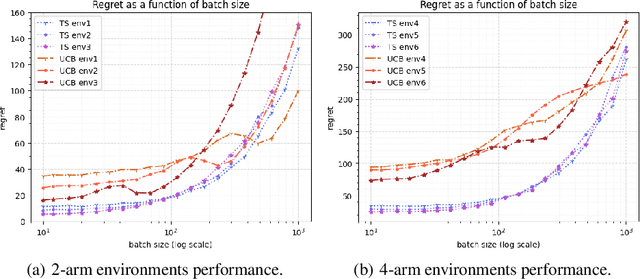
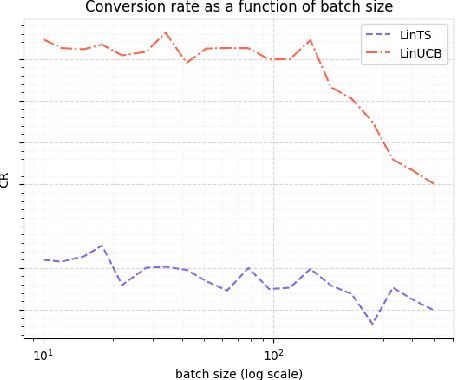
We consider a special case of bandit problems, namely batched bandits. Motivated by natural restrictions of recommender systems and e-commerce platforms, we assume that a learning agent observes responses batched in groups over a certain time period. Unlike previous work, we consider a more practically relevant batch-centric scenario of batch learning. We provide a policy-agnostic regret analysis and demonstrate upper and lower bounds for the regret of a candidate policy. Our main theoretical results show that the impact of batch learning can be measured in terms of online behavior. Finally, we demonstrate the consistency of theoretical results by conducting empirical experiments and reflect on the optimal batch size choice.
Synthetic Map Generation to Provide Unlimited Training Data for Historical Map Text Detection
Dec 12, 2021
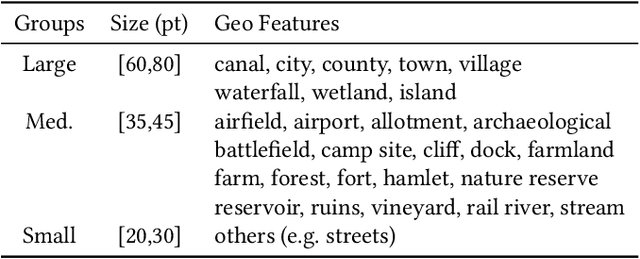

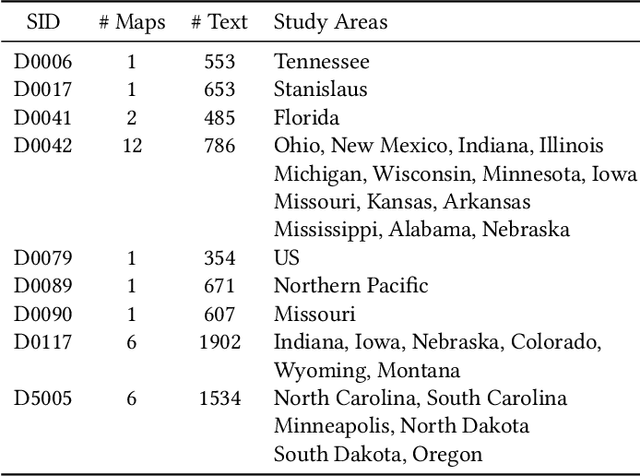
Many historical map sheets are publicly available for studies that require long-term historical geographic data. The cartographic design of these maps includes a combination of map symbols and text labels. Automatically reading text labels from map images could greatly speed up the map interpretation and helps generate rich metadata describing the map content. Many text detection algorithms have been proposed to locate text regions in map images automatically, but most of the algorithms are trained on out-ofdomain datasets (e.g., scenic images). Training data determines the quality of machine learning models, and manually annotating text regions in map images is labor-extensive and time-consuming. On the other hand, existing geographic data sources, such as Open- StreetMap (OSM), contain machine-readable map layers, which allow us to separate out the text layer and obtain text label annotations easily. However, the cartographic styles between OSM map tiles and historical maps are significantly different. This paper proposes a method to automatically generate an unlimited amount of annotated historical map images for training text detection models. We use a style transfer model to convert contemporary map images into historical style and place text labels upon them. We show that the state-of-the-art text detection models (e.g., PSENet) can benefit from the synthetic historical maps and achieve significant improvement for historical map text detection.
MAVE: A Product Dataset for Multi-source Attribute Value Extraction
Dec 16, 2021
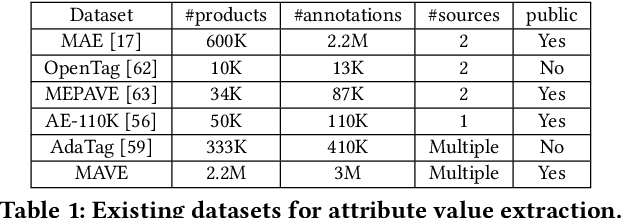

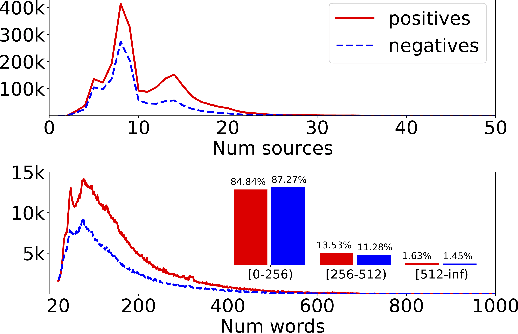
Attribute value extraction refers to the task of identifying values of an attribute of interest from product information. Product attribute values are essential in many e-commerce scenarios, such as customer service robots, product ranking, retrieval and recommendations. While in the real world, the attribute values of a product are usually incomplete and vary over time, which greatly hinders the practical applications. In this paper, we introduce MAVE, a new dataset to better facilitate research on product attribute value extraction. MAVE is composed of a curated set of 2.2 million products from Amazon pages, with 3 million attribute-value annotations across 1257 unique categories. MAVE has four main and unique advantages: First, MAVE is the largest product attribute value extraction dataset by the number of attribute-value examples. Second, MAVE includes multi-source representations from the product, which captures the full product information with high attribute coverage. Third, MAVE represents a more diverse set of attributes and values relative to what previous datasets cover. Lastly, MAVE provides a very challenging zero-shot test set, as we empirically illustrate in the experiments. We further propose a novel approach that effectively extracts the attribute value from the multi-source product information. We conduct extensive experiments with several baselines and show that MAVE is an effective dataset for attribute value extraction task. It is also a very challenging task on zero-shot attribute extraction. Data is available at {\it \url{https://github.com/google-research-datasets/MAVE}}.
Energy-bounded Learning for Robust Models of Code
Dec 20, 2021
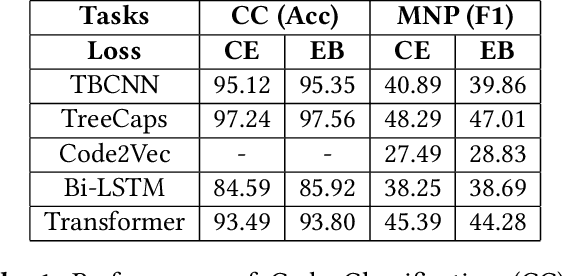
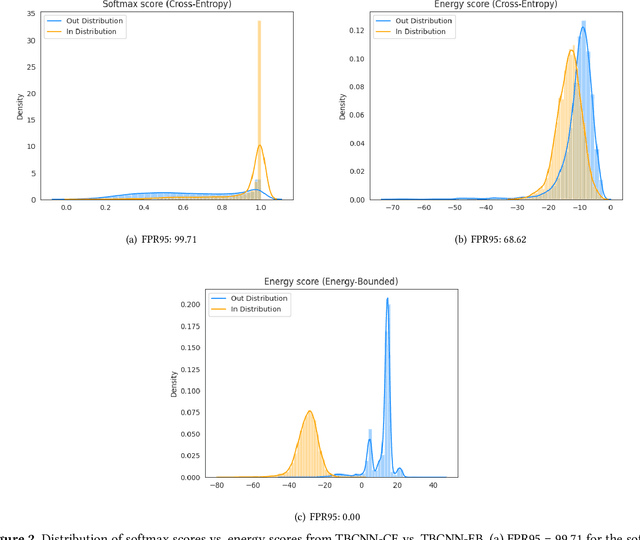

In programming, learning code representations has a variety of applications, including code classification, code search, comment generation, bug prediction, and so on. Various representations of code in terms of tokens, syntax trees, dependency graphs, code navigation paths, or a combination of their variants have been proposed, however, existing vanilla learning techniques have a major limitation in robustness, i.e., it is easy for the models to make incorrect predictions when the inputs are altered in a subtle way. To enhance the robustness, existing approaches focus on recognizing adversarial samples rather than on the valid samples that fall outside a given distribution, which we refer to as out-of-distribution (OOD) samples. Recognizing such OOD samples is the novel problem investigated in this paper. To this end, we propose to first augment the in=distribution datasets with out-of-distribution samples such that, when trained together, they will enhance the model's robustness. We propose the use of an energy-bounded learning objective function to assign a higher score to in-distribution samples and a lower score to out-of-distribution samples in order to incorporate such out-of-distribution samples into the training process of source code models. In terms of OOD detection and adversarial samples detection, our evaluation results demonstrate a greater robustness for existing source code models to become more accurate at recognizing OOD data while being more resistant to adversarial attacks at the same time. Furthermore, the proposed energy-bounded score outperforms all existing OOD detection scores by a large margin, including the softmax confidence score, the Mahalanobis score, and ODIN.
Learning Optimal Predictive Checklists
Dec 02, 2021


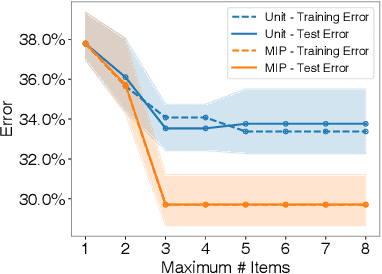
Checklists are simple decision aids that are often used to promote safety and reliability in clinical applications. In this paper, we present a method to learn checklists for clinical decision support. We represent predictive checklists as discrete linear classifiers with binary features and unit weights. We then learn globally optimal predictive checklists from data by solving an integer programming problem. Our method allows users to customize checklists to obey complex constraints, including constraints to enforce group fairness and to binarize real-valued features at training time. In addition, it pairs models with an optimality gap that can inform model development and determine the feasibility of learning sufficiently accurate checklists on a given dataset. We pair our method with specialized techniques that speed up its ability to train a predictive checklist that performs well and has a small optimality gap. We benchmark the performance of our method on seven clinical classification problems, and demonstrate its practical benefits by training a short-form checklist for PTSD screening. Our results show that our method can fit simple predictive checklists that perform well and that can easily be customized to obey a rich class of custom constraints.
HSPACE: Synthetic Parametric Humans Animated in Complex Environments
Dec 23, 2021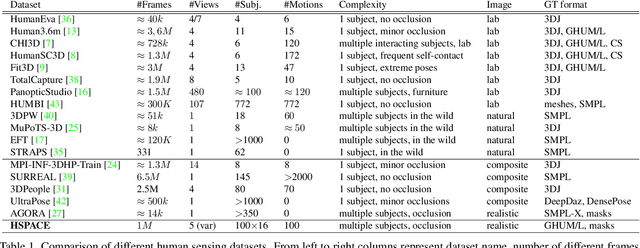
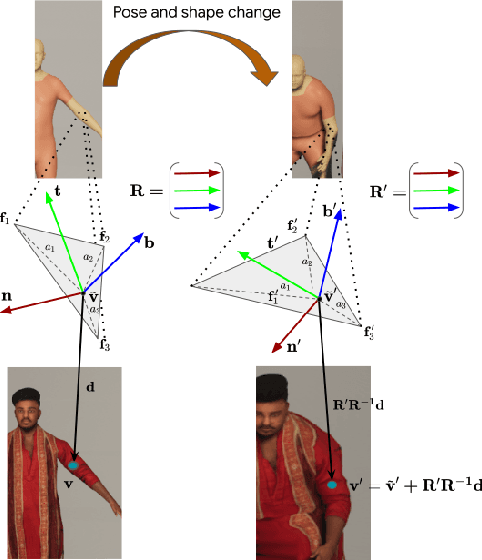
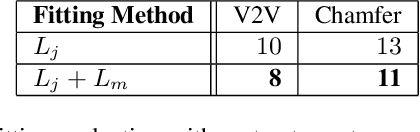
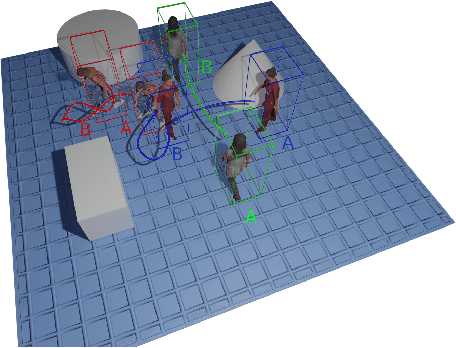
Advances in the state of the art for 3d human sensing are currently limited by the lack of visual datasets with 3d ground truth, including multiple people, in motion, operating in real-world environments, with complex illumination or occlusion, and potentially observed by a moving camera. Sophisticated scene understanding would require estimating human pose and shape as well as gestures, towards representations that ultimately combine useful metric and behavioral signals with free-viewpoint photo-realistic visualisation capabilities. To sustain progress, we build a large-scale photo-realistic dataset, Human-SPACE (HSPACE), of animated humans placed in complex synthetic indoor and outdoor environments. We combine a hundred diverse individuals of varying ages, gender, proportions, and ethnicity, with hundreds of motions and scenes, as well as parametric variations in body shape (for a total of 1,600 different humans), in order to generate an initial dataset of over 1 million frames. Human animations are obtained by fitting an expressive human body model, GHUM, to single scans of people, followed by novel re-targeting and positioning procedures that support the realistic animation of dressed humans, statistical variation of body proportions, and jointly consistent scene placement of multiple moving people. Assets are generated automatically, at scale, and are compatible with existing real time rendering and game engines. The dataset with evaluation server will be made available for research. Our large-scale analysis of the impact of synthetic data, in connection with real data and weak supervision, underlines the considerable potential for continuing quality improvements and limiting the sim-to-real gap, in this practical setting, in connection with increased model capacity.