 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Communication-Efficient TeraByte-Scale Model Training Framework for Online Advertising
Jan 05, 2022
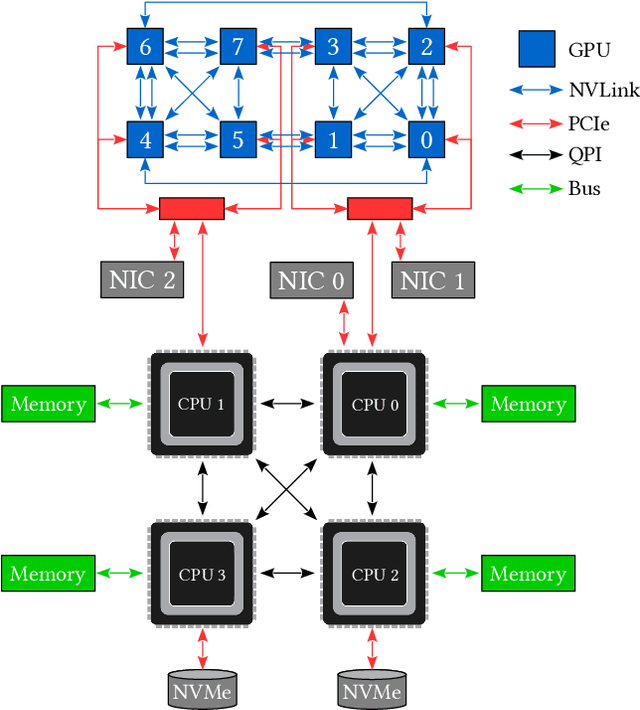
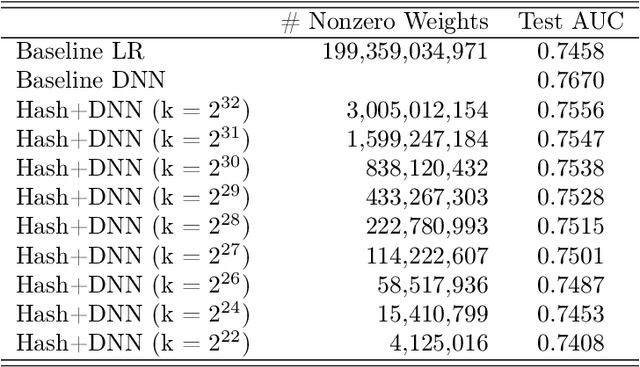
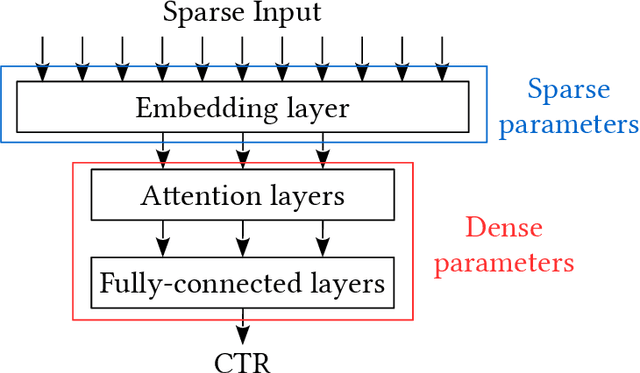
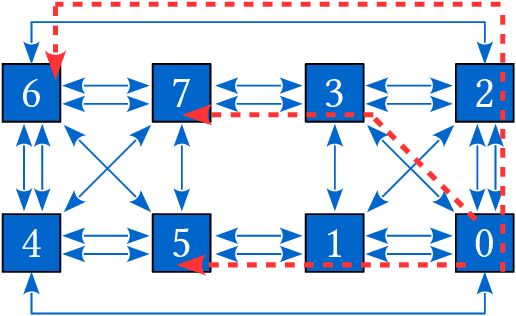
Click-Through Rate (CTR) prediction is a crucial component in the online advertising industry. In order to produce a personalized CTR prediction, an industry-level CTR prediction model commonly takes a high-dimensional (e.g., 100 or 1000 billions of features) sparse vector (that is encoded from query keywords, user portraits, etc.) as input. As a result, the model requires Terabyte scale parameters to embed the high-dimensional input. Hierarchical distributed GPU parameter server has been proposed to enable GPU with limited memory to train the massive network by leveraging CPU main memory and SSDs as secondary storage. We identify two major challenges in the existing GPU training framework for massive-scale ad models and propose a collection of optimizations to tackle these challenges: (a) the GPU, CPU, SSD rapidly communicate with each other during the training. The connections between GPUs and CPUs are non-uniform due to the hardware topology. The data communication route should be optimized according to the hardware topology; (b) GPUs in different computing nodes frequently communicates to synchronize parameters. We are required to optimize the communications so that the distributed system can become scalable. In this paper, we propose a hardware-aware training workflow that couples the hardware topology into the algorithm design. To reduce the extensive communication between computing nodes, we introduce a $k$-step model merging algorithm for the popular Adam optimizer and provide its convergence rate in non-convex optimization. To the best of our knowledge, this is the first application of $k$-step adaptive optimization method in industrial-level CTR model training. The numerical results on real-world data confirm that the optimized system design considerably reduces the training time of the massive model, with essentially no loss in accuracy.
Sequential TOA-Based Moving Target Localization in Multi-Agent Networks
Sep 24, 2021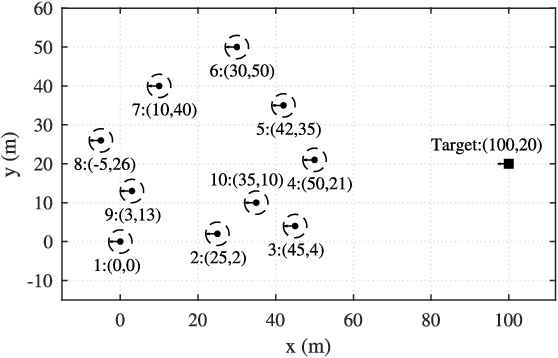
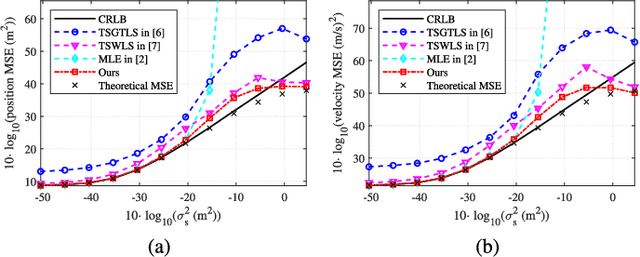
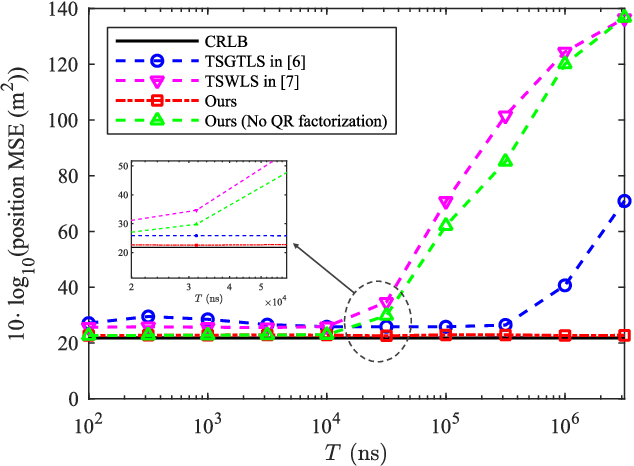
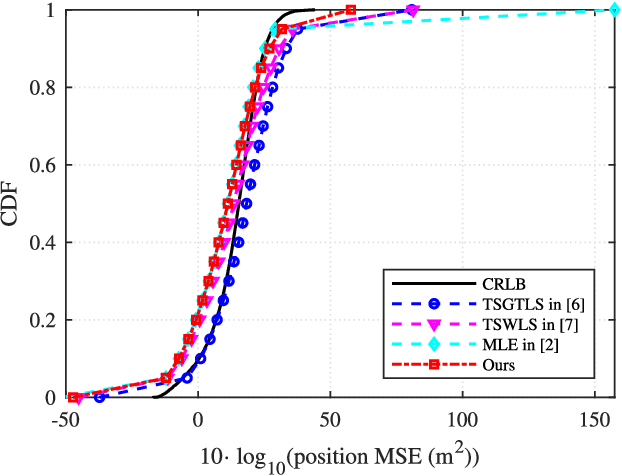
Localizing moving targets in unknown harsh environments has always been a severe challenge. This letter investigates a novel localization system based on multi-agent networks, where multiple agents serve as mobile anchors broadcasting their time-space information to the targets. We study how the moving target can localize itself using the sequential time of arrival (TOA) of the one-way broadcast signals. An extended two-step weighted least squares (TSWLS) method is proposed to jointly estimate the position and velocity of the target in the presence of agent information uncertainties. We also address the large target clock offset (LTCO) problem for numerical stability. Analytical results reveal that our method reaches the Cramer-Rao lower bound (CRLB) under small noises. Numerical results show that the proposed method performs better than the existing algorithms.
NeuroHSMD: Neuromorphic Hybrid Spiking Motion Detector
Dec 12, 2021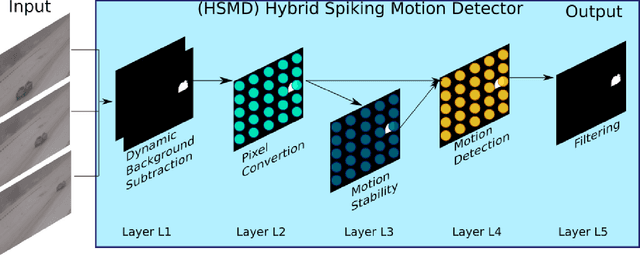

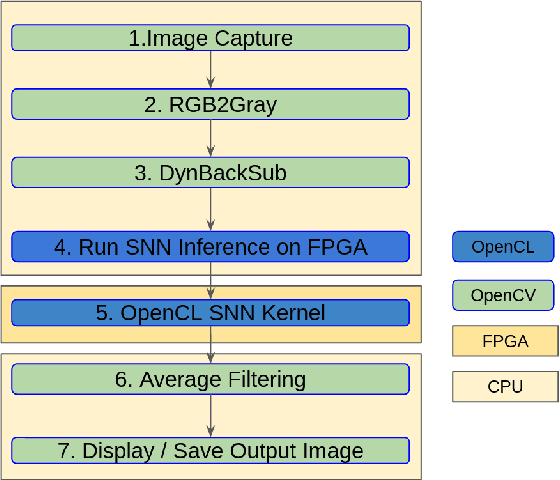
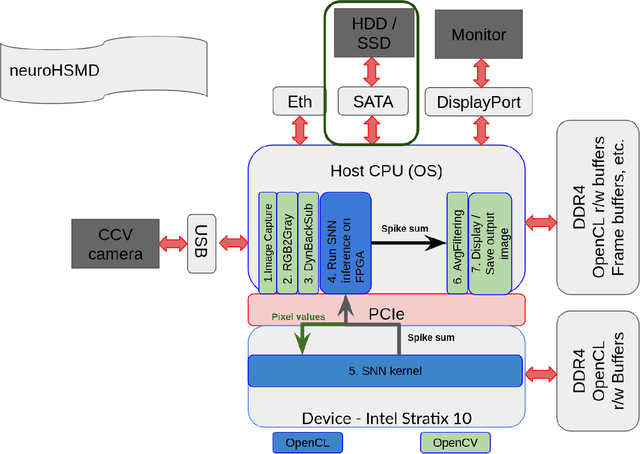
Vertebrate retinas are highly-efficient in processing trivial visual tasks such as detecting moving objects, yet a complex task for modern computers. The detection of object motion is done by specialised retinal ganglion cells named Object-motion-sensitive ganglion cells (OMS-GC). OMS-GC process continuous signals and generate spike patterns that are post-processed by the Visual Cortex. The Neuromorphic Hybrid Spiking Motion Detector (NeuroHSMD) proposed in this work accelerates the HSMD algorithm using Field-Programmable Gate Arrays (FPGAs). The Hybrid Spiking Motion Detector (HSMD) algorithm was the first hybrid algorithm to enhance dynamic background subtraction (DBS) algorithms with a customised 3-layer spiking neural network (SNN) that generates OMS-GC spiking-like responses. The NeuroHSMD algorithm was compared against the HSMD algorithm, using the same 2012 change detection (CDnet2012) and 2014 change detection (CDnet2014) benchmark datasets. The results show that the NeuroHSMD has produced the same results as the HSMD algorithm in real-time without degradation of quality. Moreover, the NeuroHSMD proposed in this paper was completely implemented in Open Computer Language (OpenCL) and therefore is easily replicated in other devices such as Graphical Processor Units (GPUs) and clusters of Central Processor Units (CPUs).
Deep Graphics Encoder for Real-Time Video Makeup Synthesis from Example
May 12, 2021

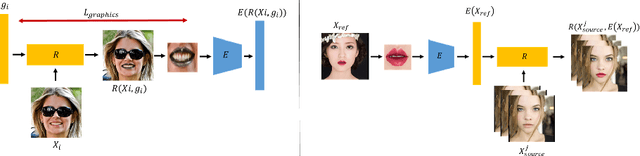
While makeup virtual-try-on is now widespread, parametrizing a computer graphics rendering engine for synthesizing images of a given cosmetics product remains a challenging task. In this paper, we introduce an inverse computer graphics method for automatic makeup synthesis from a reference image, by learning a model that maps an example portrait image with makeup to the space of rendering parameters. This method can be used by artists to automatically create realistic virtual cosmetics image samples, or by consumers, to virtually try-on a makeup extracted from their favorite reference image.
Local Texture Estimator for Implicit Representation Function
Nov 17, 2021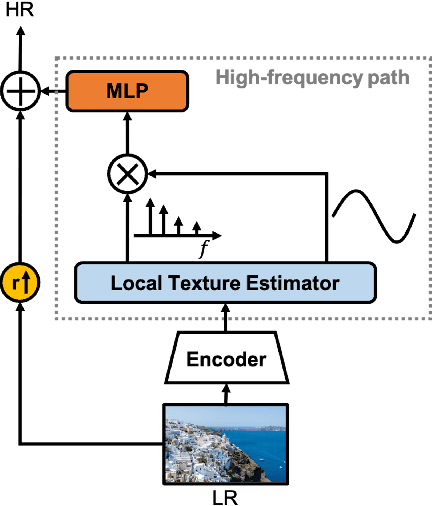
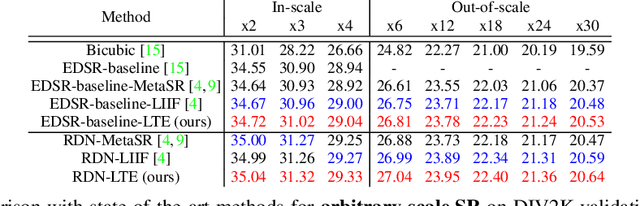
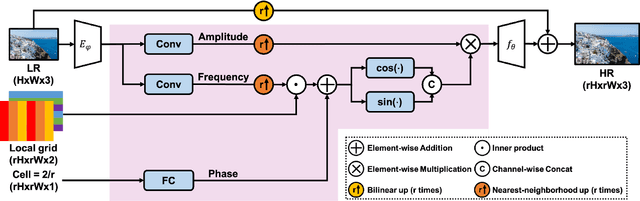

Recent works with an implicit neural function shed light on representing images in arbitrary resolution. However, a standalone multi-layer perceptron (MLP) shows limited performance in learning high-frequency components. In this paper, we propose a Local Texture Estimator (LTE), a dominant-frequency estimator for natural images, enabling an implicit function to capture fine details while reconstructing images in a continuous manner. When jointly trained with a deep super-resolution (SR) architecture, LTE is capable of characterizing image textures in 2D Fourier space. We show that an LTE-based neural function outperforms existing deep SR methods within an arbitrary-scale for all datasets and all scale factors. Furthermore, we demonstrate that our implementation takes the shortest running time compared to previous works. Source code will be open.
BeatNet: CRNN and Particle Filtering for Online Joint Beat Downbeat and Meter Tracking
Aug 08, 2021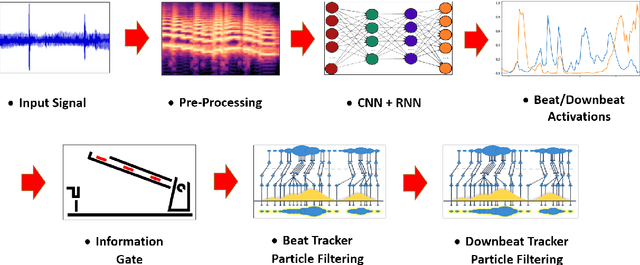
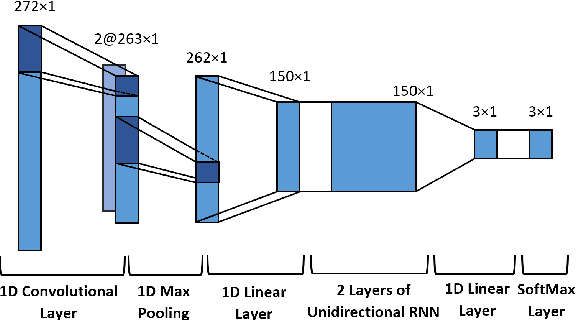
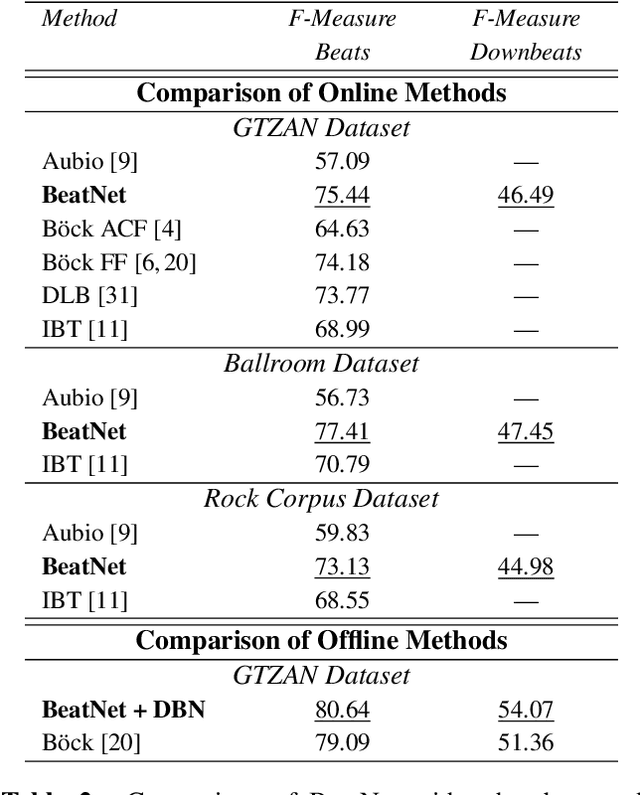
The online estimation of rhythmic information, such as beat positions, downbeat positions, and meter, is critical for many real-time music applications. Musical rhythm comprises complex hierarchical relationships across time, rendering its analysis intrinsically challenging and at times subjective. Furthermore, systems which attempt to estimate rhythmic information in real-time must be causal and must produce estimates quickly and efficiently. In this work, we introduce an online system for joint beat, downbeat, and meter tracking, which utilizes causal convolutional and recurrent layers, followed by a pair of sequential Monte Carlo particle filters applied during inference. The proposed system does not need to be primed with a time signature in order to perform downbeat tracking, and is instead able to estimate meter and adjust the predictions over time. Additionally, we propose an information gate strategy to significantly decrease the computational cost of particle filtering during the inference step, making the system much faster than previous sampling-based methods. Experiments on the GTZAN dataset, which is unseen during training, show that the system outperforms various online beat and downbeat tracking systems and achieves comparable performance to a baseline offline joint method.
YMIR: A Rapid Data-centric Development Platform for Vision Applications
Nov 27, 2021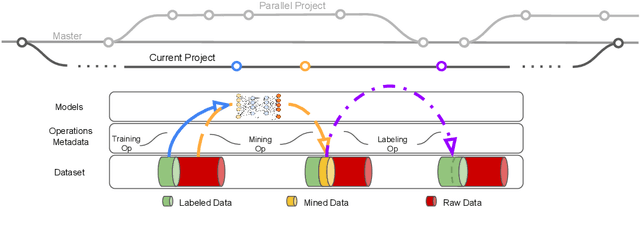
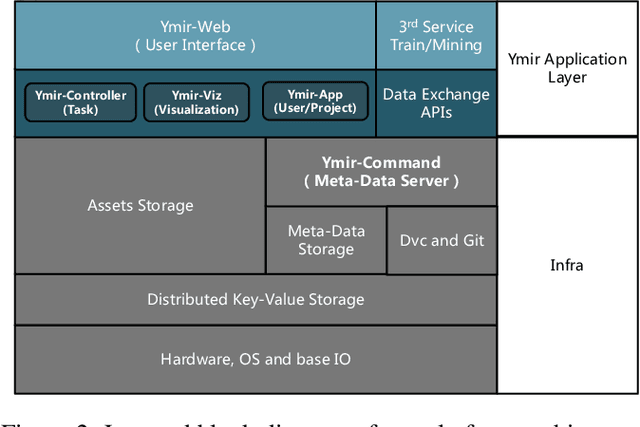
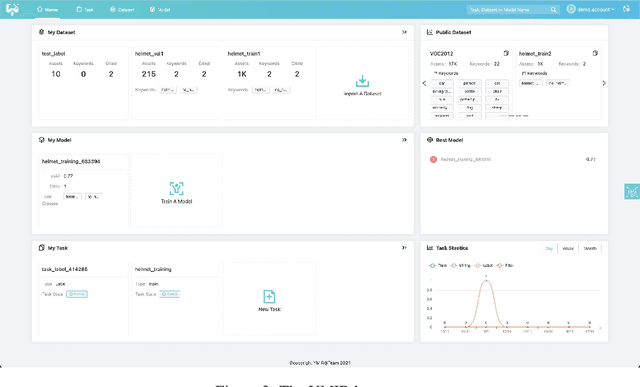
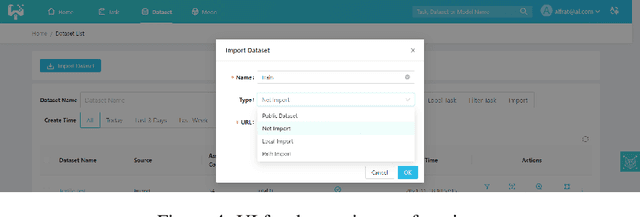
This paper introduces an open source platform to support the rapid development of computer vision applications at scale. The platform puts the efficient data development at the center of the machine learning development process, integrates active learning methods, data and model version control, and uses concepts such as projects to enable fast iterations of multiple task specific datasets in parallel. This platform abstracts the development process into core states and operations, and integrates third party tools via open APIs as implementations of the operations. This open design reduces the development cost and adoption cost for ML teams with existing tools. At the same time, the platform supports recording project development histories, through which successful projects can be shared to further boost model production efficiency on similar tasks. The platform is open source and is already used internally to meet the increasing demand for different real world computer vision applications.
RADU: Ray-Aligned Depth Update Convolutions for ToF Data Denoising
Nov 30, 2021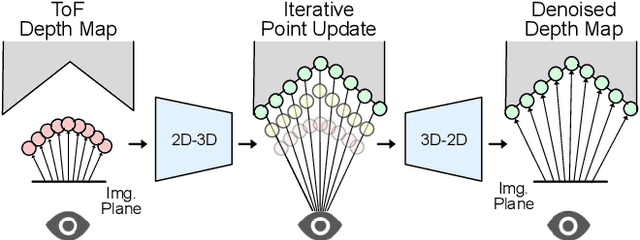
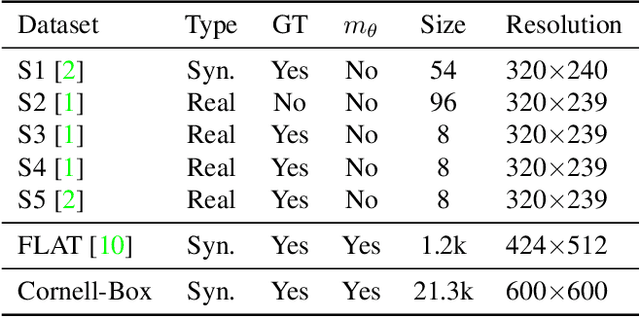
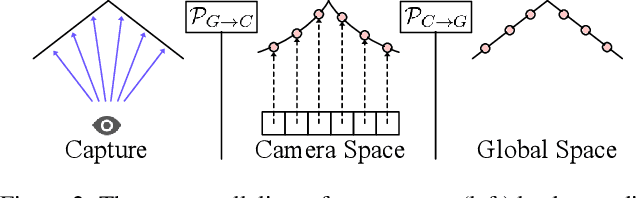
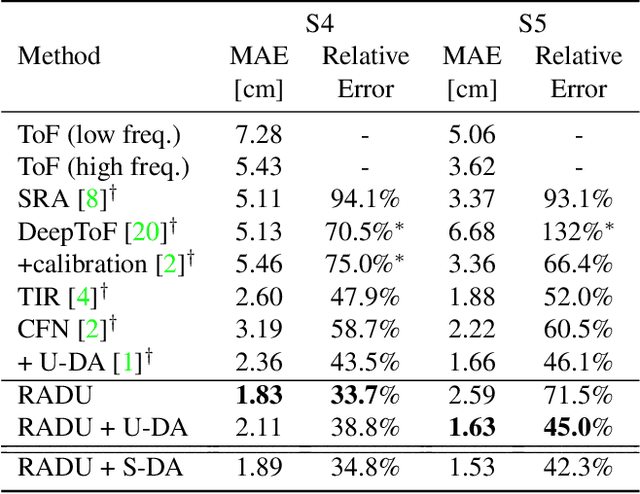
Time-of-Flight (ToF) cameras are subject to high levels of noise and distortions due to Multi-Path-Interference (MPI). While recent research showed that 2D neural networks are able to outperform previous traditional State-of-the-Art (SOTA) methods on denoising ToF-Data, little research on learning-based approaches has been done to make direct use of the 3D information present in depth images. In this paper, we propose an iterative denoising approach operating in 3D space, that is designed to learn on 2.5D data by enabling 3D point convolutions to correct the points' positions along the view direction. As labeled real world data is scarce for this task, we further train our network with a self-training approach on unlabeled real world data to account for real world statistics. We demonstrate that our method is able to outperform SOTA methods on several datasets, including two real world datasets and a new large-scale synthetic data set introduced in this paper.
ESL: Event-based Structured Light
Nov 30, 2021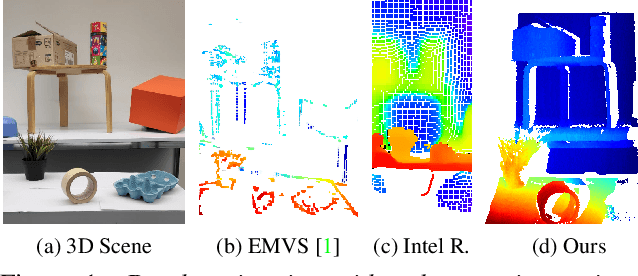

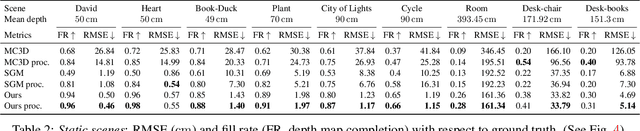
Event cameras are bio-inspired sensors providing significant advantages over standard cameras such as low latency, high temporal resolution, and high dynamic range. We propose a novel structured-light system using an event camera to tackle the problem of accurate and high-speed depth sensing. Our setup consists of an event camera and a laser-point projector that uniformly illuminates the scene in a raster scanning pattern during 16 ms. Previous methods match events independently of each other, and so they deliver noisy depth estimates at high scanning speeds in the presence of signal latency and jitter. In contrast, we optimize an energy function designed to exploit event correlations, called spatio-temporal consistency. The resulting method is robust to event jitter and therefore performs better at higher scanning speeds. Experiments demonstrate that our method can deal with high-speed motion and outperform state-of-the-art 3D reconstruction methods based on event cameras, reducing the RMSE by 83% on average, for the same acquisition time.
On the Generalization of Agricultural Drought Classification from Climate Data
Nov 30, 2021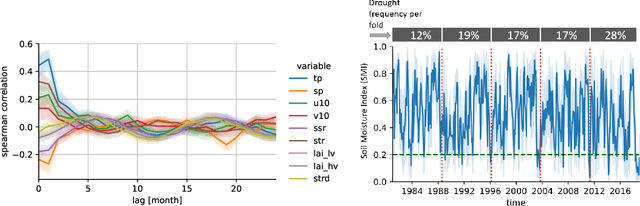
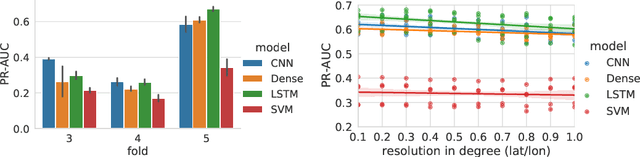
Climate change is expected to increase the likelihood of drought events, with severe implications for food security. Unlike other natural disasters, droughts have a slow onset and depend on various external factors, making drought detection in climate data difficult. In contrast to existing works that rely on simple relative drought indices as ground-truth data, we build upon soil moisture index (SMI) obtained from a hydrological model. This index is directly related to insufficiently available water to vegetation. Given ERA5-Land climate input data of six months with land use information from MODIS satellite observation, we compare different models with and without sequential inductive bias in classifying droughts based on SMI. We use PR-AUC as the evaluation measure to account for the class imbalance and obtain promising results despite a challenging time-based split. We further show in an ablation study that the models retain their predictive capabilities given input data of coarser resolutions, as frequently encountered in climate models.